Diffusion Models - 扩散模型(一)
常见的生成模型(Generative Models)如 GAN、VAE 和基于流( Flow-based )的模型。他们在生成高质量样本方面取得了巨大成功,但每个都有其自身的局限性。 GAN 因其对抗性训练性质,其训练过程难以收敛以及生成多样性欠佳。 VAE 依赖于替代损失(surrogate loss)。流模型必须使用专门的架构来构建可逆变换。
扩散模型( Diffusion Models )的灵感来自非平衡热力学。定义了扩散步骤的马尔可夫链,以缓慢地将随机噪声添加到数据中,然后学习逆向扩散过程以从噪声中构造所需的数据样本。与 VAE 或流模型不同,扩散模型是通过固定过程学习的,并且潜在变量具有高维度(与原始数据相同)。
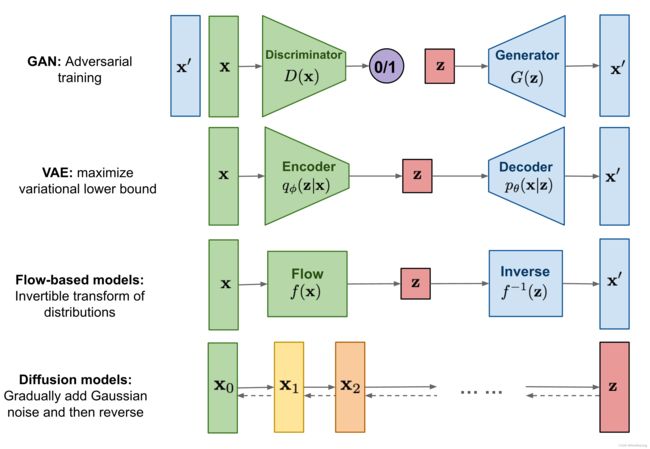
图 1. 不同类型的生成模型概述。
1. Diffusion Models
已经提出了几种基于扩散的生成模型,其中包含类似的思想,包括
- 扩散概率模型(diffusion probabilistic models):https://arxiv.org/abs/1503.03585
- 噪声条件评分网络(noise-conditioned score network): https://arxiv.org/abs/1907.05600
- 去噪扩散概率模型(denoising diffusion probabilistic models): https://arxiv.org/abs/2006.11239
1.1 Forward diffusion process
给定从真实数据分布中采样的数据点 x 0 ∼ q ( x ) \mathbf{x}_0 \sim q(\mathbf{x}) x0∼q(x) ,定义一个前向扩散过程,其中在 T T T 步中向样本添加少量高斯噪声,产生一系列噪声样本 x 1 , … , x T \mathbf{x}_1, \dots, \mathbf{x}_T x1,…,xT 。步长由方差表控制 { β t ∈ ( 0 , 1 ) } t = 1 T \{\beta_t \in (0, 1)\}_{t=1}^T {βt∈(0,1)}t=1T
q ( x t ∣ x t − 1 ) = N ( x t ; 1 − β t x t − 1 , β t I ) q ( x 1 : T ∣ x 0 ) = ∏ t = 1 T q ( x t ∣ x t − 1 ) q(\mathbf{x}_t \vert \mathbf{x}_{t-1}) = \mathcal{N}(\mathbf{x}_t; \sqrt{1 - \beta_t} \mathbf{x}_{t-1}, \beta_t\mathbf{I}) \quad q(\mathbf{x}_{1:T} \vert \mathbf{x}_0) = \prod^T_{t=1} q(\mathbf{x}_t \vert \mathbf{x}_{t-1}) q(xt∣xt−1)=N(xt;1−βtxt−1,βtI)q(x1:T∣x0)=t=1∏Tq(xt∣xt−1)
随着步长 t t t 变大,数据样本 x 0 \mathbf{x}_0 x0 逐渐失去其可区分的特征。最终当 T → ∞ T \to \infty T→∞ 时, x T \mathbf{x}_T xT 等价于各向同性高斯分布
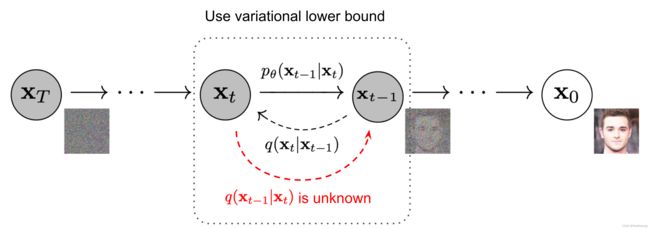
图 2. 通过缓慢添加(去除)噪声生成样本的正向(反向)扩散过程的马尔可夫链。
通过缓慢添加(去除)噪声生成样本的马尔可夫链的正向(反向)扩散过程
上述过程的一个很好的特性是,可以用重新参数化技巧在任何任意时间步长 t t t 的封闭形式下对 x t \mathbf{x}_t xt 进行采样
使得 α t = 1 − β t \alpha_t = 1 - \beta_t αt=1−βt 以及 α ˉ t = ∏ i = 1 T α i \bar{\alpha}_t = \prod_{i=1}^T \alpha_i αˉt=∏i=1Tαi:
x t = α t x t − 1 + 1 − α t z t − 1 ;where z t − 1 , z t − 2 , ⋯ ∼ N ( 0 , I ) = α t α t − 1 x t − 2 + 1 − α t α t − 1 z ˉ t − 2 ;where z ˉ t − 2 merges two Gaussians (*). = … = α ˉ t x 0 + 1 − α ˉ t z q ( x t ∣ x 0 ) = N ( x t ; α ˉ t x 0 , ( 1 − α ˉ t ) I ) \begin{aligned} \mathbf{x}_t &= \sqrt{\alpha_t}\mathbf{x}_{t-1} + \sqrt{1 - \alpha_t}\mathbf{z}_{t-1} & \text{ ;where } \mathbf{z}_{t-1}, \mathbf{z}_{t-2}, \dots \sim \mathcal{N}(\mathbf{0}, \mathbf{I}) \\ &= \sqrt{\alpha_t \alpha_{t-1}} \mathbf{x}_{t-2} + \sqrt{1 - \alpha_t \alpha_{t-1}} \bar{\mathbf{z}}_{t-2} & \text{ ;where } \bar{\mathbf{z}}_{t-2} \text{ merges two Gaussians (*).} \\ &= \dots \\ &= \sqrt{\bar{\alpha}_t}\mathbf{x}_0 + \sqrt{1 - \bar{\alpha}_t}\mathbf{z} \\ q(\mathbf{x}_t \vert \mathbf{x}_0) &= \mathcal{N}(\mathbf{x}_t; \sqrt{\bar{\alpha}_t} \mathbf{x}_0, (1 - \bar{\alpha}_t)\mathbf{I}) \end{aligned} xtq(xt∣x0)=αtxt−1+1−αtzt−1=αtαt−1xt−2+1−αtαt−1zˉt−2=…=αˉtx0+1−αˉtz=N(xt;αˉtx0,(1−αˉt)I) ;where zt−1,zt−2,⋯∼N(0,I) ;where zˉt−2 merges two Gaussians (*).
(*) **当合并两个具有不同方差的高斯时, N ( 0 , σ 1 2 I ) \mathcal{N}(\mathbf{0}, \sigma_1^2\mathbf{I}) N(0,σ12I) 和 N ( 0 , σ 2 2 I ) \mathcal{N}(\mathbf{0}, \sigma_2^2\mathbf{I}) N(0,σ22I),新分布为 N ( 0 , ( σ 1 2 + σ 2 2 ) I ) \mathcal{N}(\mathbf{0}, (\sigma_1^2 + \sigma_2^2)\mathbf{I}) N(0,(σ12+σ22)I) 。这里合并的标准差是 **
( 1 − α t ) + α t ( 1 − α t − 1 ) = 1 − α t α t − 1 \sqrt{(1 - \alpha_t) + \alpha_t (1-\alpha_{t-1})} = \sqrt{1 - \alpha_t\alpha_{t-1}} (1−αt)+αt(1−αt−1)=1−αtαt−1
通常,当样本变得更嘈杂时,可以承受更大的更新步长,所以 β 1 < β 2 < ⋯ < β T \beta_1 < \beta_2 < \dots < \beta_T β1<β2<⋯<βT 因此 α ˉ 1 > ⋯ > α ˉ T \bar{\alpha}_1 > \dots > \bar{\alpha}_T αˉ1>⋯>αˉT
Connection with stochastic gradient Langevin dynamics
Langevin dynamics 是物理学中的一个概念,用于对分子系统进行统计建模。结合随机梯度下降,stochastic gradient Langevin dynamics (http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.226.363) 可以仅使用马尔可夫更新链中的梯度 ∇ x log p ( x ) \nabla_\mathbf{x} \log p(\mathbf{x}) ∇xlogp(x) 从概率密度 p ( x ) p(\mathbf{x}) p(x) 生成样本:
x t = x t − 1 + ϵ 2 ∇ x log p ( x t − 1 ) + ϵ z t , where z t ∼ N ( 0 , I ) \mathbf{x}_t = \mathbf{x}_{t-1} + \frac{\epsilon}{2} \nabla_\mathbf{x} \log p(\mathbf{x}_{t-1}) + \sqrt{\epsilon} \mathbf{z}_t ,\quad\text{where } \mathbf{z}_t \sim \mathcal{N}(\mathbf{0}, \mathbf{I}) xt=xt−1+2ϵ∇xlogp(xt−1)+ϵzt,where zt∼N(0,I)
其中 ϵ \epsilon ϵ 为步长,当 T → ∞ , ϵ → 0 T \to \infty, \epsilon \to 0 T→∞,ϵ→0 , x T \mathbf{x}_T xT 等于真实概率密度 p ( x ) p(\mathbf{x}) p(x)。
与标准 SGD 相比,stochastic gradient Langevin dynamics 将高斯噪声注入到参数更新中,以避免陷入局部最小值。
1.2 Reverse diffusion process
如果可以反转上述过程并从 q ( x t − 1 ∣ x t ) q(\mathbf{x}_{t-1} \vert \mathbf{x}_t) q(xt−1∣xt) 中采样,将能够从高斯噪声输入 x T ∼ N ( 0 , I ) \mathbf{x}_T \sim \mathcal{N}(\mathbf{0}, \mathbf{I}) xT∼N(0,I) 中重新创建真实样本。值得一提的是,如果 β t β_t βt 足够小, q ( x t − 1 ∣ x t ) q(\mathbf{x}_{t-1} \vert \mathbf{x}_t) q(xt−1∣xt) 也将是高斯分布的。不过估计 q ( x t − 1 ∣ x t ) q(\mathbf{x}_{t-1} \vert \mathbf{x}_t) q(xt−1∣xt) 是不可行的,因为它需要使用整个数据集,因此需要学习一个模型 p θ p_θ pθ 来逼近这些条件概率,以便运行反向扩散过程。
p θ ( x 0 : T ) = p ( x T ) ∏ t = 1 T p θ ( x t − 1 ∣ x t ) p θ ( x t − 1 ∣ x t ) = N ( x t − 1 ; μ θ ( x t , t ) , Σ θ ( x t , t ) ) p_\theta(\mathbf{x}_{0:T}) = p(\mathbf{x}_T) \prod^T_{t=1} p_\theta(\mathbf{x}_{t-1} \vert \mathbf{x}_t) \quad p_\theta(\mathbf{x}_{t-1} \vert \mathbf{x}_t) = \mathcal{N}(\mathbf{x}_{t-1}; \boldsymbol{\mu}_\theta(\mathbf{x}_t, t), \boldsymbol{\Sigma}_\theta(\mathbf{x}_t, t)) pθ(x0:T)=p(xT)t=1∏Tpθ(xt−1∣xt)pθ(xt−1∣xt)=N(xt−1;μθ(xt,t),Σθ(xt,t))
图 3. 数据建模的扩散模型训练示例。
值得注意的是,当以 x 0 \mathbf{x}_0 x0 为条件时,反向条件概率是易于处理的:
q ( x t − 1 ∣ x t , x 0 ) = N ( x t − 1 ; μ ~ ( x t , x 0 ) , β ~ t I ) q(\mathbf{x}_{t-1} \vert \mathbf{x}_t, \mathbf{x}_0) = \mathcal{N}(\mathbf{x}_{t-1}; \color{blue}{\tilde{\boldsymbol{\mu}}}(\mathbf{x}_t, \mathbf{x}_0), \color{red}{\tilde{\beta}_t} \mathbf{I}) q(xt−1∣xt,x0)=N(xt−1;μ~(xt,x0),β~tI)
使用贝叶斯定理,则有:
q ( x t − 1 ∣ x t , x 0 ) = q ( x t ∣ x t − 1 , x 0 ) q ( x t − 1 ∣ x 0 ) q ( x t ∣ x 0 ) ∝ exp ( − 1 2 ( ( x t − α t x t − 1 ) 2 β t + ( x t − 1 − α ˉ t − 1 x 0 ) 2 1 − α ˉ t − 1 − ( x t − α ˉ t x 0 ) 2 1 − α ˉ t ) ) = exp ( − 1 2 ( x t 2 − 2 α t x t x t − 1 + α t x t − 1 2 β t + x t − 1 2 − 2 α ˉ t − 1 x 0 x t − 1 + α ˉ t − 1 x 0 2 1 − α ˉ t − 1 − ( x t − α ˉ t x 0 ) 2 1 − α ˉ t ) ) = exp ( − 1 2 ( ( α t β t + 1 1 − α ˉ t − 1 ) x t − 1 2 − ( 2 α t β t x t + 2 α ˉ t − 1 1 − α ˉ t − 1 x 0 ) x t − 1 + C ( x t , x 0 ) ) ) \begin{aligned} q(\mathbf{x}_{t-1} \vert \mathbf{x}_t, \mathbf{x}_0) &= q(\mathbf{x}_t \vert \mathbf{x}_{t-1}, \mathbf{x}_0) \frac{ q(\mathbf{x}_{t-1} \vert \mathbf{x}_0) }{ q(\mathbf{x}_t \vert \mathbf{x}_0) } \\ &\propto \exp \Big(-\frac{1}{2} \big(\frac{(\mathbf{x}_t - \sqrt{\alpha_t} \mathbf{x}_{t-1})^2}{\beta_t} + \frac{(\mathbf{x}_{t-1} - \sqrt{\bar{\alpha}_{t-1}} \mathbf{x}_0)^2}{1-\bar{\alpha}_{t-1}} - \frac{(\mathbf{x}_t - \sqrt{\bar{\alpha}_t} \mathbf{x}_0)^2}{1-\bar{\alpha}_t} \big) \Big) \\ &= \exp \Big(-\frac{1}{2} \big(\frac{\mathbf{x}_t^2 - 2\sqrt{\alpha_t} \mathbf{x}_t \color{blue}{\mathbf{x}_{t-1}} \color{black}{+ \alpha_t} \color{red}{\mathbf{x}_{t-1}^2} }{\beta_t} + \frac{ \color{red}{\mathbf{x}_{t-1}^2} \color{black}{- 2 \sqrt{\bar{\alpha}_{t-1}} \mathbf{x}_0} \color{blue}{\mathbf{x}_{t-1}} \color{black}{+ \bar{\alpha}_{t-1} \mathbf{x}_0^2} }{1-\bar{\alpha}_{t-1}} - \frac{(\mathbf{x}_t - \sqrt{\bar{\alpha}_t} \mathbf{x}_0)^2}{1-\bar{\alpha}_t} \big) \Big) \\ &= \exp\Big( -\frac{1}{2} \big( \color{red}{(\frac{\alpha_t}{\beta_t} + \frac{1}{1 - \bar{\alpha}_{t-1}})} \mathbf{x}_{t-1}^2 - \color{blue}{(\frac{2\sqrt{\alpha_t}}{\beta_t} \mathbf{x}_t + \frac{2\sqrt{\bar{\alpha}_{t-1}}}{1 - \bar{\alpha}_{t-1}} \mathbf{x}_0)} \mathbf{x}_{t-1} \color{black}{ + C(\mathbf{x}_t, \mathbf{x}_0) \big) \Big)} \end{aligned} q(xt−1∣xt,x0)=q(xt∣xt−1,x0)q(xt∣x0)q(xt−1∣x0)∝exp(−21(βt(xt−αtxt−1)2+1−αˉt−1(xt−1−αˉt−1x0)2−1−αˉt(xt−αˉtx0)2))=exp(−21(βtxt2−2αtxtxt−1+αtxt−12+1−αˉt−1xt−12−2αˉt−1x0xt−1+αˉt−1x02−1−αˉt(xt−αˉtx0)2))=exp(−21((βtαt+1−αˉt−11)xt−12−(βt2αtxt+1−αˉt−12αˉt−1x0)xt−1+C(xt,x0)))
其中 C ( x t , x 0 ) C(\mathbf{x}_t, \mathbf{x}_0) C(xt,x0) 是一些不涉及 x t − 1 \mathbf{x}_{t-1} xt−1 的函数,省略了细节。按照标准的高斯密度函数,均值和方差可以参数化如下(回顾一下, α t = 1 − β t \alpha_t = 1 - \beta_t αt=1−βt 和 α ˉ t = ∏ i = 1 T α i \bar{\alpha}_t = \prod_{i=1}^T \alpha_i αˉt=∏i=1Tαi):
β ~ t = 1 / ( α t β t + 1 1 − α ˉ t − 1 ) = 1 / ( α t − α ˉ t + β t β t ( 1 − α ˉ t − 1 ) ) = 1 − α ˉ t − 1 1 − α ˉ t ⋅ β t μ ~ t ( x t , x 0 ) = ( α t β t x t + α ˉ t − 1 1 − α ˉ t − 1 x 0 ) / ( α t β t + 1 1 − α ˉ t − 1 ) = ( α t β t x t + α ˉ t − 1 1 − α ˉ t − 1 x 0 ) 1 − α ˉ t − 1 1 − α ˉ t ⋅ β t = α t ( 1 − α ˉ t − 1 ) 1 − α ˉ t x t + α ˉ t − 1 β t 1 − α ˉ t x 0 \begin{aligned} \tilde{\beta}_t &= 1/(\frac{\alpha_t}{\beta_t} + \frac{1}{1 - \bar{\alpha}_{t-1}}) = 1/(\frac{\alpha_t - \bar{\alpha}_t + \beta_t}{\beta_t(1 - \bar{\alpha}_{t-1})}) = \color{green}{\frac{1 - \bar{\alpha}_{t-1}}{1 - \bar{\alpha}_t} \cdot \beta_t} \\ \tilde{\boldsymbol{\mu}}_t (\mathbf{x}_t, \mathbf{x}_0) &= (\frac{\sqrt{\alpha_t}}{\beta_t} \mathbf{x}_t + \frac{\sqrt{\bar{\alpha}_{t-1} }}{1 - \bar{\alpha}_{t-1}} \mathbf{x}_0)/(\frac{\alpha_t}{\beta_t} + \frac{1}{1 - \bar{\alpha}_{t-1}}) \\ &= (\frac{\sqrt{\alpha_t}}{\beta_t} \mathbf{x}_t + \frac{\sqrt{\bar{\alpha}_{t-1} }}{1 - \bar{\alpha}_{t-1}} \mathbf{x}_0) \color{green}{\frac{1 - \bar{\alpha}_{t-1}}{1 - \bar{\alpha}_t} \cdot \beta_t} \\ &= \frac{\sqrt{\alpha_t}(1 - \bar{\alpha}_{t-1})}{1 - \bar{\alpha}_t} \mathbf{x}_t + \frac{\sqrt{\bar{\alpha}_{t-1}}\beta_t}{1 - \bar{\alpha}_t} \mathbf{x}_0\\ \end{aligned} β~tμ~t(xt,x0)=1/(βtαt+1−αˉt−11)=1/(βt(1−αˉt−1)αt−αˉt+βt)=1−αˉt1−αˉt−1⋅βt=(βtαtxt+1−αˉt−1αˉt−1x0)/(βtαt+1−αˉt−11)=(βtαtxt+1−αˉt−1αˉt−1x0)1−αˉt1−αˉt−1⋅βt=1−αˉtαt(1−αˉt−1)xt+1−αˉtαˉt−1βtx0
由于不错的属性,可以代表 x 0 = 1 α ˉ t ( x t − 1 − α ˉ t z t ) \mathbf{x}_0 = \frac{1}{\sqrt{\bar{\alpha}_t}}(\mathbf{x}_t - \sqrt{1 - \bar{\alpha}_t}\mathbf{z}_t) x0=αˉt1(xt−1−αˉtzt) 并将其代入上式得到:
μ ~ t = α t ( 1 − α ˉ t − 1 ) 1 − α ˉ t x t + α ˉ t − 1 β t 1 − α ˉ t 1 α ˉ t ( x t − 1 − α ˉ t z t ) = 1 α t ( x t − β t 1 − α ˉ t z t ) \begin{aligned} \tilde{\boldsymbol{\mu}}_t &= \frac{\sqrt{\alpha_t}(1 - \bar{\alpha}_{t-1})}{1 - \bar{\alpha}_t} \mathbf{x}_t + \frac{\sqrt{\bar{\alpha}_{t-1}}\beta_t}{1 - \bar{\alpha}_t} \frac{1}{\sqrt{\bar{\alpha}_t}}(\mathbf{x}_t - \sqrt{1 - \bar{\alpha}_t}\mathbf{z}_t) \\ &= \color{cyan}{\frac{1}{\sqrt{\alpha_t}} \Big( \mathbf{x}_t - \frac{\beta_t}{\sqrt{1 - \bar{\alpha}_t}} \mathbf{z}_t \Big)} \end{aligned} μ~t=1−αˉtαt(1−αˉt−1)xt+1−αˉtαˉt−1βtαˉt1(xt−1−αˉtzt)=αt1(xt−1−αˉtβtzt)
如图 2 所示,这种设置与 VAE 非常相似,因此可以使用变分下限来优化负对数似然。
variational lower bound 变分下限(也叫 evidence lower bound, ELBO)
为了衡量两个分布 q ( Z ) q(Z) q(Z) 和 p ( Z ∣ X ) p(Z|X) p(Z∣X) 的相似程度,常用的度量标准是 Kullback-Leibler (KL) 散度。变分推理的 KL 散度为:
K L [ q ( Z ) ∥ p ( Z ∣ X ) ] = ∫ Z q ( Z ) log q ( Z ) p ( Z ∣ X ) = − ∫ Z q ( Z ) log p ( Z ∣ X ) q ( Z ) = − ( ∫ Z q ( Z ) log p ( X , Z ) q ( Z ) − ∫ Z q ( Z ) log p ( X ) ) = − ∫ Z q ( Z ) log p ( X , Z ) q ( Z ) + log p ( X ) ∫ Z q ( Z ) = − L + log p ( X ) \begin{aligned} KL\left[q(Z) \| p(Z|X)\right] &= \int_Z q(Z) \log \frac{q(Z)}{p(Z|X)} \\ &= -\int_Z q(Z) \log \frac{p(Z|X)}{q(Z)} \\ &= - \left(\int_Z q(Z) \log \frac{p(X,Z)}{q(Z)} - \int_Z q(Z) \log p(X)\right) \\ &= -\int_Z q(Z) \log \frac{p(X,Z)}{q(Z)} + \log p(X) \int_Z q(Z) \\ &= -L + \log p(X) \end{aligned} KL[q(Z)∥p(Z∣X)]=∫Zq(Z)logp(Z∣X)q(Z)=−∫Zq(Z)logq(Z)p(Z∣X)=−(∫Zq(Z)logq(Z)p(X,Z)−∫Zq(Z)logp(X))=−∫Zq(Z)logq(Z)p(X,Z)+logp(X)∫Zq(Z)=−L+logp(X)
其中 L L L 为上述的变分下限。又由 ∫ Z q ( Z ) = 1 \int_Z q(Z) = 1 ∫Zq(Z)=1 可得:
L = log p ( X ) − K L [ q ( Z ) ∥ p ( Z ∣ X ) ] L = \log p(X) - KL\left[q(Z) \| p(Z|X)\right] L=logp(X)−KL[q(Z)∥p(Z∣X)]
因为 KL 散度总是大于等于 0,可以推导出:
L ≤ log p ( X ) L \leq \log p(X) L≤logp(X)
− log p θ ( x 0 ) ≤ − log p θ ( x 0 ) + D KL ( q ( x 1 : T ∣ x 0 ) ∥ p θ ( x 1 : T ∣ x 0 ) ) = − log p θ ( x 0 ) + E x 1 : T ∼ q ( x 1 : T ∣ x 0 ) [ log q ( x 1 : T ∣ x 0 ) p θ ( x 0 : T ) / p θ ( x 0 ) ] = − log p θ ( x 0 ) + E q [ log q ( x 1 : T ∣ x 0 ) p θ ( x 0 : T ) + log p θ ( x 0 ) ] = E q [ log q ( x 1 : T ∣ x 0 ) p θ ( x 0 : T ) ] Let L VLB = E q ( x 0 : T ) [ log q ( x 1 : T ∣ x 0 ) p θ ( x 0 : T ) ] ≥ − E q ( x 0 ) log p θ ( x 0 ) \begin{aligned} - \log p_\theta(\mathbf{x}_0) &\leq - \log p_\theta(\mathbf{x}_0) + D_\text{KL}(q(\mathbf{x}_{1:T}\vert\mathbf{x}_0) \| p_\theta(\mathbf{x}_{1:T}\vert\mathbf{x}_0) ) \\ &= -\log p_\theta(\mathbf{x}_0) + \mathbb{E}_{\mathbf{x}_{1:T}\sim q(\mathbf{x}_{1:T} \vert \mathbf{x}_0)} \Big[ \log\frac{q(\mathbf{x}_{1:T}\vert\mathbf{x}_0)}{p_\theta(\mathbf{x}_{0:T}) / p_\theta(\mathbf{x}_0)} \Big] \\ &= -\log p_\theta(\mathbf{x}_0) + \mathbb{E}_q \Big[ \log\frac{q(\mathbf{x}_{1:T}\vert\mathbf{x}_0)}{p_\theta(\mathbf{x}_{0:T})} + \log p_\theta(\mathbf{x}_0) \Big] \\ &= \mathbb{E}_q \Big[ \log \frac{q(\mathbf{x}_{1:T}\vert\mathbf{x}_0)}{p_\theta(\mathbf{x}_{0:T})} \Big] \\ \text{Let }L_\text{VLB} &= \mathbb{E}_{q(\mathbf{x}_{0:T})} \Big[ \log \frac{q(\mathbf{x}_{1:T}\vert\mathbf{x}_0)}{p_\theta(\mathbf{x}_{0:T})} \Big] \geq - \mathbb{E}_{q(\mathbf{x}_0)} \log p_\theta(\mathbf{x}_0) \end{aligned} −logpθ(x0)Let LVLB≤−logpθ(x0)+DKL(q(x1:T∣x0)∥pθ(x1:T∣x0))=−logpθ(x0)+Ex1:T∼q(x1:T∣x0)[logpθ(x0:T)/pθ(x0)q(x1:T∣x0)]=−logpθ(x0)+Eq[logpθ(x0:T)q(x1:T∣x0)+logpθ(x0)]=Eq[logpθ(x0:T)q(x1:T∣x0)]=Eq(x0:T)[logpθ(x0:T)q(x1:T∣x0)]≥−Eq(x0)logpθ(x0)
使用 Jensen 不等式也很容易得到相同的结果。假设我们想最小化交叉熵作为学习目标,
Jensen 不等式:
过一个下凸函数上任意两点所作割线一定在这两点间的函数图象的上方,即:
t f ( x 1 ) + ( 1 − t ) f ( x 2 ) ≥ f ( t x 1 + ( 1 − t ) x 2 ) , 0 ≤ t ≤ 1. t f(x_1) + (1-t) f(x_2) \geq f \left (t x_1 + (1-t) x_2 \right ), 0 \leq t \leq 1. tf(x1)+(1−t)f(x2)≥f(tx1+(1−t)x2),0≤t≤1.
概率论版本μ \mu μ 是个概率测度。函数 g g g 换作实值随机变量 X X X。在 Ω \Omega Ω 空间上,任何函数相对于概率测度 μ \mu μ 的积分就成了期望值。这不等式就说,若 φ \varphi φ 是任一凸函数,则:
φ ( E ( X ) ) ≤ E ( φ ( X ) ) \varphi(\mathbb{E}(X)) \leq \mathbb{E}(\varphi(X)) φ(E(X))≤E(φ(X))
L CE = − E q ( x 0 ) log p θ ( x 0 ) = − E q ( x 0 ) log ( ∫ p θ ( x 0 : T ) d x 1 : T ) = − E q ( x 0 ) log ( ∫ q ( x 1 : T ∣ x 0 ) p θ ( x 0 : T ) q ( x 1 : T ∣ x 0 ) d x 1 : T ) = − E q ( x 0 ) log ( E q ( x 1 : T ∣ x 0 ) p θ ( x 0 : T ) q ( x 1 : T ∣ x 0 ) ) ≤ − E q ( x 0 : T ) log p θ ( x 0 : T ) q ( x 1 : T ∣ x 0 ) = E q ( x 0 : T ) [ log q ( x 1 : T ∣ x 0 ) p θ ( x 0 : T ) ] = L VLB \begin{aligned} L_\text{CE} &= - \mathbb{E}_{q(\mathbf{x}_0)} \log p_\theta(\mathbf{x}_0) \\ &= - \mathbb{E}_{q(\mathbf{x}_0)} \log \Big( \int p_\theta(\mathbf{x}_{0:T}) d\mathbf{x}_{1:T} \Big) \\ &= - \mathbb{E}_{q(\mathbf{x}_0)} \log \Big( \int q(\mathbf{x}_{1:T} \vert \mathbf{x}_0) \frac{p_\theta(\mathbf{x}_{0:T})}{q(\mathbf{x}_{1:T} \vert \mathbf{x}_{0})} d\mathbf{x}_{1:T} \Big) \\ &= - \mathbb{E}_{q(\mathbf{x}_0)} \log \Big( \mathbb{E}_{q(\mathbf{x}_{1:T} \vert \mathbf{x}_0)} \frac{p_\theta(\mathbf{x}_{0:T})}{q(\mathbf{x}_{1:T} \vert \mathbf{x}_{0})} \Big) \\ &\leq - \mathbb{E}_{q(\mathbf{x}_{0:T})} \log \frac{p_\theta(\mathbf{x}_{0:T})}{q(\mathbf{x}_{1:T} \vert \mathbf{x}_{0})} \\ &= \mathbb{E}_{q(\mathbf{x}_{0:T})}\Big[\log \frac{q(\mathbf{x}_{1:T} \vert \mathbf{x}_{0})}{p_\theta(\mathbf{x}_{0:T})} \Big] = L_\text{VLB} \end{aligned} LCE=−Eq(x0)logpθ(x0)=−Eq(x0)log(∫pθ(x0:T)dx1:T)=−Eq(x0)log(∫q(x1:T∣x0)q(x1:T∣x0)pθ(x0:T)dx1:T)=−Eq(x0)log(Eq(x1:T∣x0)q(x1:T∣x0)pθ(x0:T))≤−Eq(x0:T)logq(x1:T∣x0)pθ(x0:T)=Eq(x0:T)[logpθ(x0:T)q(x1:T∣x0)]=LVLB
为了将方程中的每个项转换为可分析计算的,可以将目标进一步重写为几个 KL 散度和熵项的组合:
L VLB = E q ( x 0 : T ) [ log q ( x 1 : T ∣ x 0 ) p θ ( x 0 : T ) ] = E q [ log ∏ t = 1 T q ( x t ∣ x t − 1 ) p θ ( x T ) ∏ t = 1 T p θ ( x t − 1 ∣ x t ) ] = E q [ − log p θ ( x T ) + ∑ t = 1 T log q ( x t ∣ x t − 1 ) p θ ( x t − 1 ∣ x t ) ] = E q [ − log p θ ( x T ) + ∑ t = 2 T log q ( x t ∣ x t − 1 ) p θ ( x t − 1 ∣ x t ) + log q ( x 1 ∣ x 0 ) p θ ( x 0 ∣ x 1 ) ] = E q [ − log p θ ( x T ) + ∑ t = 2 T log ( q ( x t − 1 ∣ x t , x 0 ) p θ ( x t − 1 ∣ x t ) ⋅ q ( x t ∣ x 0 ) q ( x t − 1 ∣ x 0 ) ) + log q ( x 1 ∣ x 0 ) p θ ( x 0 ∣ x 1 ) ] = E q [ − log p θ ( x T ) + ∑ t = 2 T log q ( x t − 1 ∣ x t , x 0 ) p θ ( x t − 1 ∣ x t ) + ∑ t = 2 T log q ( x t ∣ x 0 ) q ( x t − 1 ∣ x 0 ) + log q ( x 1 ∣ x 0 ) p θ ( x 0 ∣ x 1 ) ] = E q [ − log p θ ( x T ) + ∑ t = 2 T log q ( x t − 1 ∣ x t , x 0 ) p θ ( x t − 1 ∣ x t ) + log q ( x T ∣ x 0 ) q ( x 1 ∣ x 0 ) + log q ( x 1 ∣ x 0 ) p θ ( x 0 ∣ x 1 ) ] = E q [ log q ( x T ∣ x 0 ) p θ ( x T ) + ∑ t = 2 T log q ( x t − 1 ∣ x t , x 0 ) p θ ( x t − 1 ∣ x t ) − log p θ ( x 0 ∣ x 1 ) ] = E q [ D KL ( q ( x T ∣ x 0 ) ∥ p θ ( x T ) ) ⏟ L T + ∑ t = 2 T D KL ( q ( x t − 1 ∣ x t , x 0 ) ∥ p θ ( x t − 1 ∣ x t ) ) ⏟ L t − 1 − log p θ ( x 0 ∣ x 1 ) ⏟ L 0 ] \begin{aligned} L_\text{VLB} &= \mathbb{E}_{q(\mathbf{x}_{0:T})} \Big[ \log\frac{q(\mathbf{x}_{1:T}\vert\mathbf{x}_0)}{p_\theta(\mathbf{x}_{0:T})} \Big] \\ &= \mathbb{E}_q \Big[ \log\frac{\prod_{t=1}^T q(\mathbf{x}_t\vert\mathbf{x}_{t-1})}{ p_\theta(\mathbf{x}_T) \prod_{t=1}^T p_\theta(\mathbf{x}_{t-1} \vert\mathbf{x}_t) } \Big] \\ &= \mathbb{E}_q \Big[ -\log p_\theta(\mathbf{x}_T) + \sum_{t=1}^T \log \frac{q(\mathbf{x}_t\vert\mathbf{x}_{t-1})}{p_\theta(\mathbf{x}_{t-1} \vert\mathbf{x}_t)} \Big] \\ &= \mathbb{E}_q \Big[ -\log p_\theta(\mathbf{x}_T) + \sum_{t=2}^T \log \frac{q(\mathbf{x}_t\vert\mathbf{x}_{t-1})}{p_\theta(\mathbf{x}_{t-1} \vert\mathbf{x}_t)} + \log\frac{q(\mathbf{x}_1 \vert \mathbf{x}_0)}{p_\theta(\mathbf{x}_0 \vert \mathbf{x}_1)} \Big] \\ &= \mathbb{E}_q \Big[ -\log p_\theta(\mathbf{x}_T) + \sum_{t=2}^T \log \Big( \frac{q(\mathbf{x}_{t-1} \vert \mathbf{x}_t, \mathbf{x}_0)}{p_\theta(\mathbf{x}_{t-1} \vert\mathbf{x}_t)}\cdot \frac{q(\mathbf{x}_t \vert \mathbf{x}_0)}{q(\mathbf{x}_{t-1}\vert\mathbf{x}_0)} \Big) + \log \frac{q(\mathbf{x}_1 \vert \mathbf{x}_0)}{p_\theta(\mathbf{x}_0 \vert \mathbf{x}_1)} \Big] \\ &= \mathbb{E}_q \Big[ -\log p_\theta(\mathbf{x}_T) + \sum_{t=2}^T \log \frac{q(\mathbf{x}_{t-1} \vert \mathbf{x}_t, \mathbf{x}_0)}{p_\theta(\mathbf{x}_{t-1} \vert\mathbf{x}_t)} + \sum_{t=2}^T \log \frac{q(\mathbf{x}_t \vert \mathbf{x}_0)}{q(\mathbf{x}_{t-1} \vert \mathbf{x}_0)} + \log\frac{q(\mathbf{x}_1 \vert \mathbf{x}_0)}{p_\theta(\mathbf{x}_0 \vert \mathbf{x}_1)} \Big] \\ &= \mathbb{E}_q \Big[ -\log p_\theta(\mathbf{x}_T) + \sum_{t=2}^T \log \frac{q(\mathbf{x}_{t-1} \vert \mathbf{x}_t, \mathbf{x}_0)}{p_\theta(\mathbf{x}_{t-1} \vert\mathbf{x}_t)} + \log\frac{q(\mathbf{x}_T \vert \mathbf{x}_0)}{q(\mathbf{x}_1 \vert \mathbf{x}_0)} + \log \frac{q(\mathbf{x}_1 \vert \mathbf{x}_0)}{p_\theta(\mathbf{x}_0 \vert \mathbf{x}_1)} \Big]\\ &= \mathbb{E}_q \Big[ \log\frac{q(\mathbf{x}_T \vert \mathbf{x}_0)}{p_\theta(\mathbf{x}_T)} + \sum_{t=2}^T \log \frac{q(\mathbf{x}_{t-1} \vert \mathbf{x}_t, \mathbf{x}_0)}{p_\theta(\mathbf{x}_{t-1} \vert\mathbf{x}_t)} - \log p_\theta(\mathbf{x}_0 \vert \mathbf{x}_1) \Big] \\ &= \mathbb{E}_q [\underbrace{D_\text{KL}(q(\mathbf{x}_T \vert \mathbf{x}_0) \parallel p_\theta(\mathbf{x}_T))}_{L_T} + \sum_{t=2}^T \underbrace{D_\text{KL}(q(\mathbf{x}_{t-1} \vert \mathbf{x}_t, \mathbf{x}_0) \parallel p_\theta(\mathbf{x}_{t-1} \vert\mathbf{x}_t))}_{L_{t-1}} \underbrace{- \log p_\theta(\mathbf{x}_0 \vert \mathbf{x}_1)}_{L_0} ] \end{aligned} LVLB=Eq(x0:T)[logpθ(x0:T)q(x1:T∣x0)]=Eq[logpθ(xT)∏t=1Tpθ(xt−1∣xt)∏t=1Tq(xt∣xt−1)]=Eq[−logpθ(xT)+t=1∑Tlogpθ(xt−1∣xt)q(xt∣xt−1)]=Eq[−logpθ(xT)+t=2∑Tlogpθ(xt−1∣xt)q(xt∣xt−1)+logpθ(x0∣x1)q(x1∣x0)]=Eq[−logpθ(xT)+t=2∑Tlog(pθ(xt−1∣xt)q(xt−1∣xt,x0)⋅q(xt−1∣x0)q(xt∣x0))+logpθ(x0∣x1)q(x1∣x0)]=Eq[−logpθ(xT)+t=2∑Tlogpθ(xt−1∣xt)q(xt−1∣xt,x0)+t=2∑Tlogq(xt−1∣x0)q(xt∣x0)+logpθ(x0∣x1)q(x1∣x0)]=Eq[−logpθ(xT)+t=2∑Tlogpθ(xt−1∣xt)q(xt−1∣xt,x0)+logq(x1∣x0)q(xT∣x0)+logpθ(x0∣x1)q(x1∣x0)]=Eq[logpθ(xT)q(xT∣x0)+t=2∑Tlogpθ(xt−1∣xt)q(xt−1∣xt,x0)−logpθ(x0∣x1)]=Eq[LT DKL(q(xT∣x0)∥pθ(xT))+t=2∑TLt−1 DKL(q(xt−1∣xt,x0)∥pθ(xt−1∣xt))L0 −logpθ(x0∣x1)]
分别标记变分下界损失中的每个分量:
L VLB = L T + L T − 1 + ⋯ + L 0 where L T = D KL ( q ( x T ∣ x 0 ) ∥ p θ ( x T ) ) L t = D KL ( q ( x t ∣ x t + 1 , x 0 ) ∥ p θ ( x t ∣ x t + 1 ) ) for 1 ≤ t ≤ T − 1 L 0 = − log p θ ( x 0 ∣ x 1 ) \begin{aligned} L_\text{VLB} &= L_T + L_{T-1} + \dots + L_0 \\ \text{where } L_T &= D_\text{KL}(q(\mathbf{x}_T \vert \mathbf{x}_0) \parallel p_\theta(\mathbf{x}_T)) \\ L_t &= D_\text{KL}(q(\mathbf{x}_t \vert \mathbf{x}_{t+1}, \mathbf{x}_0) \parallel p_\theta(\mathbf{x}_t \vert\mathbf{x}_{t+1})) \text{ for }1 \leq t \leq T-1 \\ L_0 &= - \log p_\theta(\mathbf{x}_0 \vert \mathbf{x}_1) \end{aligned} LVLBwhere LTLtL0=LT+LT−1+⋯+L0=DKL(q(xT∣x0)∥pθ(xT))=DKL(q(xt∣xt+1,x0)∥pθ(xt∣xt+1)) for 1≤t≤T−1=−logpθ(x0∣x1)
L V L B L_{VLB} LVLB 中的每个 KL 项( L 0 L_0 L0 除外)比较两个高斯分布,因此可以以封闭形式计算它们。 L T L_T LT 是常数,在训练期间可以忽略,因为 q q q 没有可学习的参数,而 x T x_T xT 是高斯噪声。 L 0 L_0 L0 使用从 N ( x 0 ; μ θ ( x 1 , 1 ) , Σ θ ( x 1 , 1 ) ) \mathcal{N}(x_0;μ_θ(x_1,1),Σ_θ(x_1,1)) N(x0;μθ(x1,1),Σθ(x1,1)) 派生的单独离散解码器。
1.3 Parameterization of L t L_t Lt for Training Loss
我们需要学习一个神经网络来逼近反向扩散过程中的条件概率分布 p θ ( x t − 1 ∣ x t ) = N ( x t − 1 ; μ θ ( x t , t ) , Σ θ ( x t , t ) ) p_\theta(\mathbf{x}_{t-1} \vert \mathbf{x}_t) = \mathcal{N}(\mathbf{x}_{t-1}; \boldsymbol{\mu}_\theta(\mathbf{x}_t, t), \boldsymbol{\Sigma}_\theta(\mathbf{x}_t, t)) pθ(xt−1∣xt)=N(xt−1;μθ(xt,t),Σθ(xt,t)) ,通过训练 μ θ \mu_\theta μθ 来预测 μ ~ t = 1 α t ( x t − β t 1 − α ˉ t z t ) \tilde{\boldsymbol{\mu}}_t = \frac{1}{\sqrt{\alpha_t}} \Big( \mathbf{x}_t - \frac{\beta_t}{\sqrt{1 - \bar{\alpha}_t}} \mathbf{z}_t \Big) μ~t=αt1(xt−1−αˉtβtzt) 。因为 x t x_t xt 在训练时可用作输入,可以重新参数化高斯噪声项,以使其在时间步 t t t 从输入 x t x_t xt 预测 z t z_t zt:
μ θ ( x t , t ) = 1 α t ( x t − β t 1 − α ˉ t z θ ( x t , t ) ) Thus x t − 1 = N ( x t − 1 ; 1 α t ( x t − β t 1 − α ˉ t z θ ( x t , t ) ) , Σ θ ( x t , t ) ) \begin{aligned} \boldsymbol{\mu}_\theta(\mathbf{x}_t, t) &= \color{cyan}{\frac{1}{\sqrt{\alpha_t}} \Big( \mathbf{x}_t - \frac{\beta_t}{\sqrt{1 - \bar{\alpha}_t}} \mathbf{z}_\theta(\mathbf{x}_t, t) \Big)} \\ \text{Thus }\mathbf{x}_{t-1} &= \mathcal{N}(\mathbf{x}_{t-1}; \frac{1}{\sqrt{\alpha_t}} \Big( \mathbf{x}_t - \frac{\beta_t}{\sqrt{1 - \bar{\alpha}_t}} \mathbf{z}_\theta(\mathbf{x}_t, t) \Big), \boldsymbol{\Sigma}_\theta(\mathbf{x}_t, t)) \end{aligned} μθ(xt,t)Thus xt−1=αt1(xt−1−αˉtβtzθ(xt,t))=N(xt−1;αt1(xt−1−αˉtβtzθ(xt,t)),Σθ(xt,t))
损失项 L t L_t Lt 被参数化以最小化与 μ ~ \tilde{\boldsymbol{\mu}} μ~
L t = E x 0 , z [ 1 2 ∥ Σ θ ( x t , t ) ∥ 2 2 ∥ μ ~ t ( x t , x 0 ) − μ θ ( x t , t ) ∥ 2 ] = E x 0 , z [ 1 2 ∥ Σ θ ∥ 2 2 ∥ 1 α t ( x t − β t 1 − α ˉ t z t ) − 1 α t ( x t − β t 1 − α ˉ t z θ ( x t , t ) ) ∥ 2 ] = E x 0 , z [ β t 2 2 α t ( 1 − α ˉ t ) ∥ Σ θ ∥ 2 2 ∥ z t − z θ ( x t , t ) ∥ 2 ] = E x 0 , z [ β t 2 2 α t ( 1 − α ˉ t ) ∥ Σ θ ∥ 2 2 ∥ z t − z θ ( α ˉ t x 0 + 1 − α ˉ t z t , t ) ∥ 2 ] \begin{aligned} L_t &= \mathbb{E}_{\mathbf{x}_0, \mathbf{z}} \Big[\frac{1}{2 \| \boldsymbol{\Sigma}_\theta(\mathbf{x}_t, t) \|^2_2} \| \color{blue}{\tilde{\boldsymbol{\mu}}_t(\mathbf{x}_t, \mathbf{x}_0)} - \color{green}{\boldsymbol{\mu}_\theta(\mathbf{x}_t, t)} \|^2 \Big] \\ &= \mathbb{E}_{\mathbf{x}_0, \mathbf{z}} \Big[\frac{1}{2 \|\boldsymbol{\Sigma}_\theta \|^2_2} \| \color{blue}{\frac{1}{\sqrt{\alpha_t}} \Big( \mathbf{x}_t - \frac{\beta_t}{\sqrt{1 - \bar{\alpha}_t}} \mathbf{z}_t \Big)} - \color{green}{\frac{1}{\sqrt{\alpha_t}} \Big( \mathbf{x}_t - \frac{\beta_t}{\sqrt{1 - \bar{\alpha}_t}} \boldsymbol{\mathbf{z}}_\theta(\mathbf{x}_t, t) \Big)} \|^2 \Big] \\ &= \mathbb{E}_{\mathbf{x}_0, \mathbf{z}} \Big[\frac{ \beta_t^2 }{2 \alpha_t (1 - \bar{\alpha}_t) \| \boldsymbol{\Sigma}_\theta \|^2_2} \|\mathbf{z}_t - \mathbf{z}_\theta(\mathbf{x}_t, t)\|^2 \Big] \\ &= \mathbb{E}_{\mathbf{x}_0, \mathbf{z}} \Big[\frac{ \beta_t^2 }{2 \alpha_t (1 - \bar{\alpha}_t) \| \boldsymbol{\Sigma}_\theta \|^2_2} \|\mathbf{z}_t - \mathbf{z}_\theta(\sqrt{\bar{\alpha}_t}\mathbf{x}_0 + \sqrt{1 - \bar{\alpha}_t}\mathbf{z}_t, t)\|^2 \Big] \end{aligned} Lt=Ex0,z[2∥Σθ(xt,t)∥221∥μ~t(xt,x0)−μθ(xt,t)∥2]=Ex0,z[2∥Σθ∥221∥αt1(xt−1−αˉtβtzt)−αt1(xt−1−αˉtβtzθ(xt,t))∥2]=Ex0,z[2αt(1−αˉt)∥Σθ∥22βt2∥zt−zθ(xt,t)∥2]=Ex0,z[2αt(1−αˉt)∥Σθ∥22βt2∥zt−zθ(αˉtx0+1−αˉtzt,t)∥2]
Simplification
在忽略加权项的简化目标下,训练扩散模型效果更好:
L t simple = E x 0 , z t [ ∥ z t − z θ ( α ˉ t x 0 + 1 − α ˉ t z t , t ) ∥ 2 ] L_t^\text{simple} = \mathbb{E}_{\mathbf{x}_0, \mathbf{z}_t} \Big[\|\mathbf{z}_t - \mathbf{z}_\theta(\sqrt{\bar{\alpha}_t}\mathbf{x}_0 + \sqrt{1 - \bar{\alpha}_t}\mathbf{z}_t, t)\|^2 \Big] Ltsimple=Ex0,zt[∥zt−zθ(αˉtx0+1−αˉtzt,t)∥2]
最后一个简单的目标是:
L simple = L t simple + C L_\text{simple} = L_t^\text{simple} + C Lsimple=Ltsimple+C
其中 C C C 是一个不依赖于 θ θ θ 的常数。

图 4 DDPM 中的训练和采样算法
参考资料
- What are Diffusion Models? | Lil’Log (lilianweng.github.io)
- Understanding the Variational Lower Bound (xyang35.github.io)
- [2006.11239] Denoising Diffusion Probabilistic Models (arxiv.org)