干货!自动驾驶场景下的多目标追踪与实例分割
点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!

多目标跟踪和分割 (MOTS) 需要将视频中给定的类别的物体进行检测、分类、跟踪和像素级分割。在其重要的应用场景自动驾驶中,复杂的路况、市区内密集且相似的车辆和行人、以及对低功耗低延时的预测需求又给这一任务带来了新的挑战。
本研究提出了一种简单高效地利用视频时序信息的方法PCAN,通过对目标物体及过去帧的外观特征做高斯混合建模,得到数量较少且低秩的representative mixture prototypes, 实现了对历史信息的压缩。这一操作在降低注意力运算复杂度和内存需求的同时, 也提高了视频物体分割的质量和追踪的稳定性。
本期AI TIME PhD直播间,我们邀请到香港科技大学计算机工程系三年级博士生——柯磊,为我们带来报告分享《自动驾驶场景下的多目标追踪与实例分割》。

柯磊:
香港科技大学计算机工程系三年级博士生,导师是Chi-Keung Tang(IEEE Fellow)和Yu-Wing Tai。他目前在苏黎世联邦理工学院计算机视觉实验室(CVL)做访问学者,受Fisher Yu教授和研究员Martin Danelljan的共同指导。他的研究兴趣主要包括视频及图像中的实例分割与目标追踪,希望为机器感知真实世界场景提出更为精确、鲁棒、高效及可泛化的基础算法,并有多篇相关工作以第一作者身份发表于NeurIPS/CVPR/ ICCV/ECCV中。
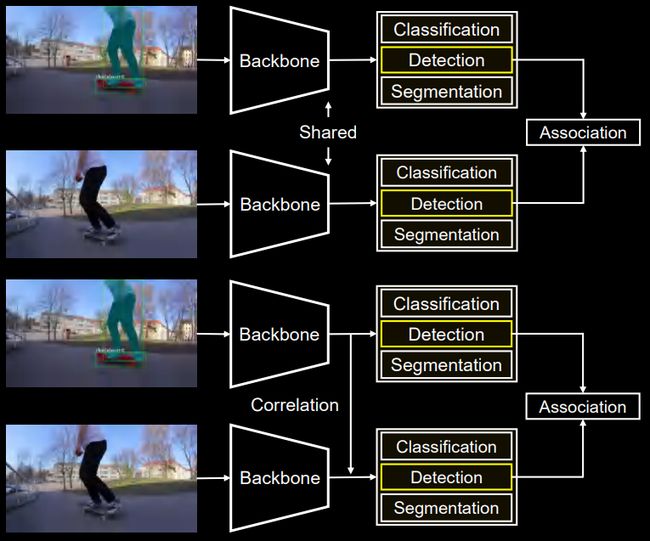
本文提出了一种在自动驾驶场景下,如何通过高效快速的时序建模从而提升多目标追踪与实例分割性能的方法MOTS——Multiple object tracking and segmentation
多目标跟踪与分割是自动驾驶和视频分析等许多实际应用中的重要问题,该任务需要将给定视频中的所有物体进行检测、分类、跟踪以及像素级别的分割。
在自动驾驶的场景中,复杂的路况、市区内密集且行为相似的行人以及对低功耗、低延迟的预测需求都给这一任务带来了新的挑战。由于引入了大规模数据集BDD100K作为深度学习模型训练和测试的基准,这也给MOTS的研究提供了助力。

MOTS的大多数online方法,主要遵循基于检测的跟踪范式,即Tracking by Detection。这一范式首先在单张图片中检测和分割对象,然后是帧之间的关联尽管这些方法已取得较好的结果,但是在时序建模上仅限于物体的关联阶段,并且还是在相邻两帧之间。
另一方面,时间维度包含着丰富的场景信息,它包含着同一物体在不同时间和角度下的多视图。利用这些多视图,我们可以有效提高物体的分割、定位和对类别的预测质量。
然而,高效的利用历史信息是一个挑战。目前已有的方法都是在视频处理中直接对高分辨率的深度特征图进行操作,长时间序列上密集的注意力操作会产生长度的二次复杂性,进而带来大量的计算负担和内存消耗。同时,也抑制了其实际应用。
我们的方法PCAN (Prototypical Cross-Attention Network)首先将历史信息中的高分辨率特征压缩到帧级和实例级的对象,然后通过Prototypical Cross-Attention操提取和利用过去帧中包含的丰富物体appearance、information等。这里是对Prototype的可视化,我们也可以看到不同的Prototype具有不同的focus。
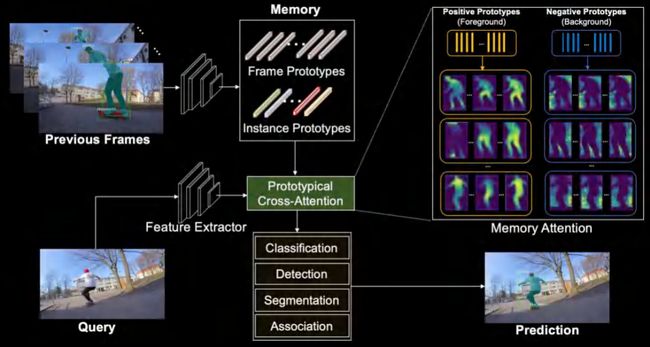
PCAN使用高斯混合模型来进行无监督的特征训练,并选用1M迭代算法得到的高斯分布的拟合训练中心作为prototypes,其中每一个像素点到prototype中心的距离定义为其L2距离。
这一操作在降低attention复杂度和内存需求的同时,我们发现它有效提高了物体分割的质量和追踪的稳定性。
1
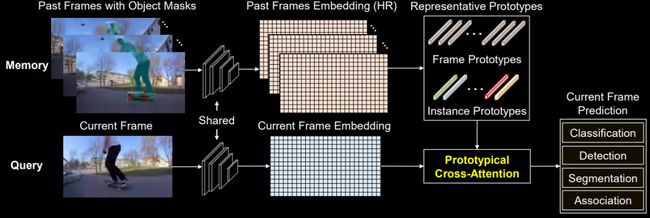
Prototypical Cross-Attention Network
PCAN包括帧集Frame-level和实例集Instance-level两个模块。前者着重于重构过去帧的深度特征并与当前帧对齐,而后者聚焦于视频中被追踪的物体并聚合他们的长时序信息。
Frame-level Cross-Attention Module
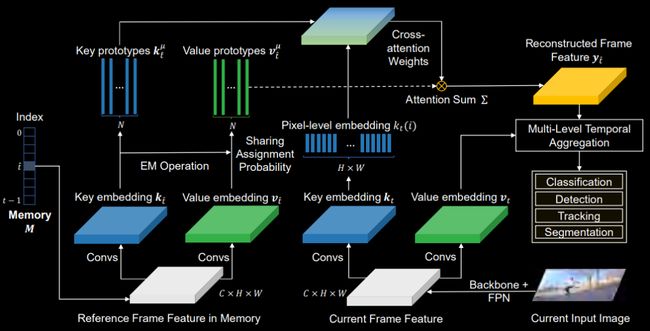
对于帧特征,我们首先进行聚类,用高斯分布来拟合获取其k和value的prototypes embedding,并根据当前帧产生的t由Cross-attention Weights将过去历史帧进行低质重建。
重建的特征与当前帧不仅对齐,还利用有限数量的高斯分布拟合去除了其特征中的冗余信息,达到了降噪的目的。保持像素点特征空间差异的同时,像素点之间内部的差异得到进一步的缩小。
随后,重建特征与当前帧进行加权融合产生的新时序特征将用于后续MOTS任务中的分类、检测、分割和追踪等子任务。
Instance-level Cross-Attention Module
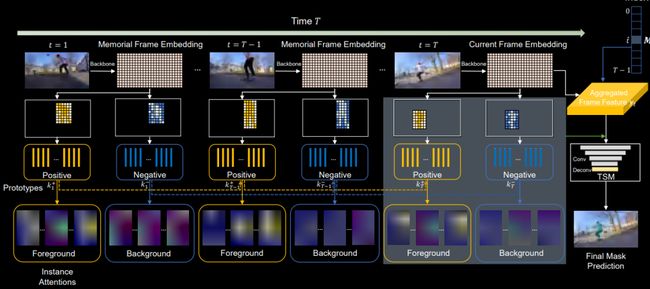
我们进一步根据初始的mask做前后背景的区分,上图中的黄色区域为前景,建模为positive;蓝色区域为背景,建模为negative。
这些instance prototypes随着时间传播而不断更新,我们采用滑动平均机制在第t帧时,这些positive和negative区域分别会产生attention maps。
从中我们也能看到不同的prototype所关注的代表区域,最后我们将初始的目的mask产生的attention map以及融合产生的新时序特征连接到一起,通过一个简单的mc网络,得到最终的mask预测。
值得注意的是,PCAN为了得到物体外观对时间变化的鲁棒性,采取了对比学习的机制使用前景和背景的prototypes来进一步表示每一个对象实例,并且将这些prototypes以在线的方式传播更新。
由于每一个实例或帧集的数量有限,这使得PCAN在视频中具有时间的线性复杂度,能够帮助我们高效的执行远程特征的聚合与传播。接下来是一个对Frame-level prototype的可视化。
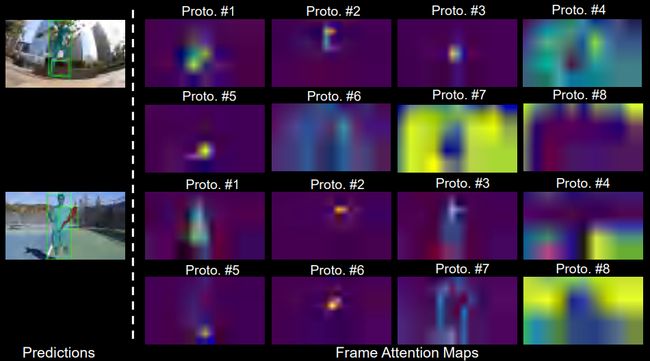
Visualization of Prototypes
● Frame-level Attention
从整张图来看,我们随机选取了8个prototypes并显示了他们的注意力分布。显然,每张prototype都学会了图像的一些语义概念。这些都是通过无监督学习聚类产生的。
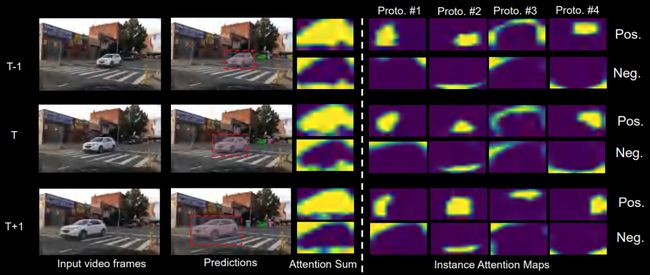
●Instance-level Attention - car
针对下图红框中车的区域,我们选取了4个前景作为示例。每个prototype都专注于特定的汽车子区域。例如,第一个prototype关注车头区域,并且这一attention随着时间的推移具有隐式无监督的一致性。
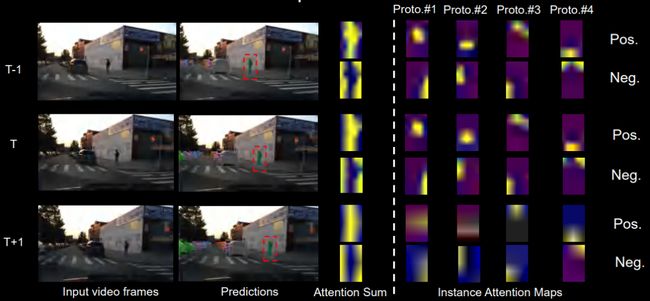
● Instance-level Attention - pedestrian
下图展示了我们对行人的可视化。
2
Quantitative Results
Comparison with State-of-the-art
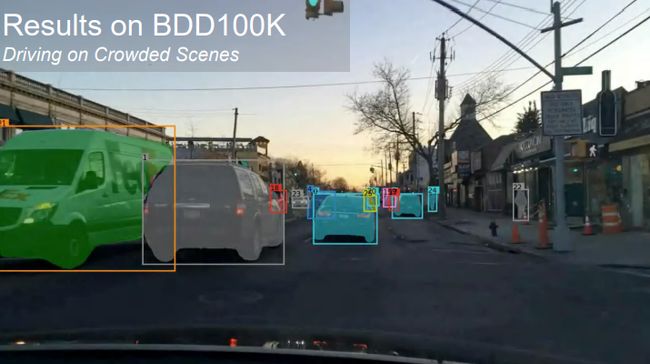
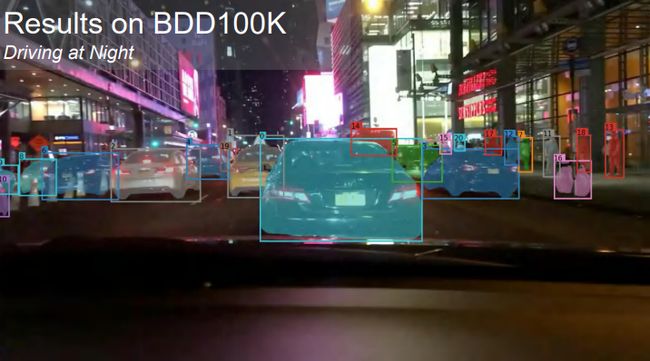
PCAN作为一个online方法,在两个最大规模的MOTS数据集BDD100K和Youtube-VIS上都取得了领先的性能。

Ablation Results on Youtube-VIS
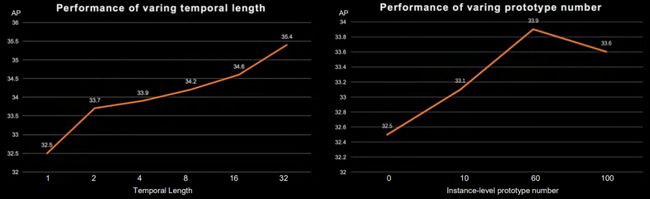
我们发现PCAN在Youtube-VIS上的性能随着temporal-length和prototype的一个变化规律。随着temporal-length的增长,PCAN的性能也有着稳步提升。这说明越丰富的temporal-length所带来的appearance信息可以帮助最终的性能提升。而prototype的数量在超过60以后出现了一些饱和现象。
2
Quantitative Results




Results on Youtube-VIS
Thin tail segmentation

Unstable object tracking and wrong detection

Fast moving bicycle riders

White tennis racket handle and shirt

Contributions
● 我们提出的PCAN主要是是由Frame-level和Instance-level组成,通过对历史帧信息做以高效的聚合时序信息并传播时序内容来用于自动驾驶。值得注意的是,PCAN是一个online方法,因此不能使用未来帧信息,这一点对于自动驾驶尤为重要。
● 此外,foreground and background prototypes在减少计算量的同时有效增加了预测质量的稳定性。
BDD100K Segmentation Tracking Challenge
BDD100K数据集是之前最大数据集的6倍,从5000张训练图片扩展到了30000余张并有着超过480K的instance mask 标注,而且包含了更多的自动驾驶场景。

Future Directions
由于在标注数据时的高昂成本,这对于自动驾驶场景而言所需要的安全性是难以接受的。
● 那么能否使用自监督的方法从更大的规模且无标注的自动驾驶视频中学习,从而帮助已有模型取得更好效果呢?
● 朝着Self-exploring, self-training 和 self-adapting的方向继续发展。
提
醒
论文题目:
Prototypical Cross-Attention Networks for Multiple Object Tracking and Segmentation
论文链接:
https://papers.nips.cc/paper/2021/file/093f65e080a295f8076b1c5722a46aa2-Paper.pdf
点击“阅读原文”,即可观看本场回放
整理:林 则
作者:柯 磊
往期精彩文章推荐

记得关注我们呀!每天都有新知识!
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了700多位海内外讲者,举办了逾350场活动,超280万人次观看。

我知道你
在看
哦
~
![]()
点击 阅读原文 查看回放!