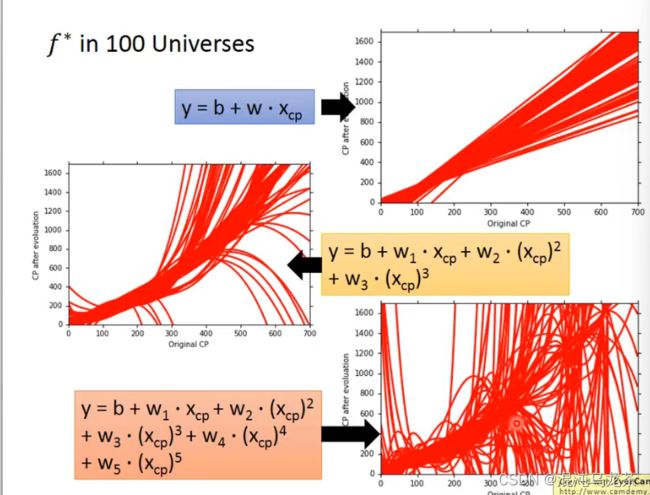
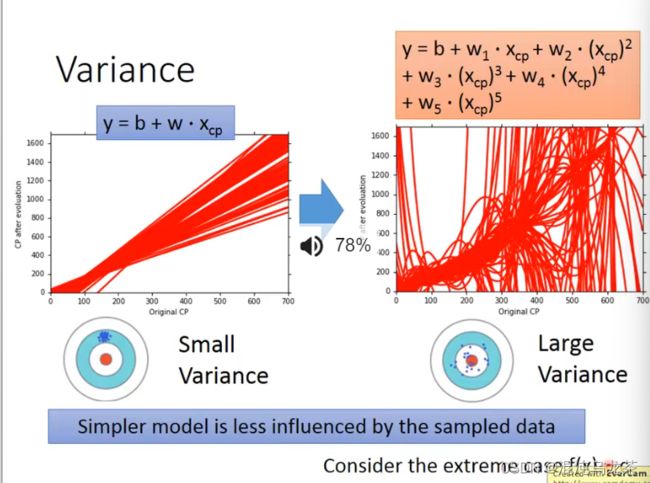
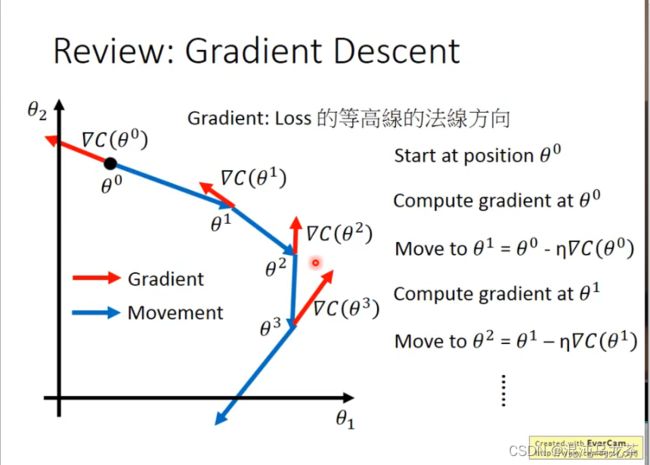
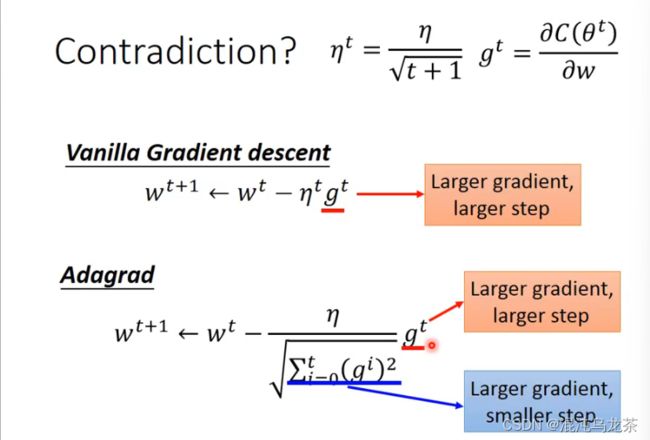
- 2019-11-13晨间日记
ZYHJ
今天是什么日子起床:清晨6::00就寝:夜晚:22:30天气:风和日丽心情:愉快纪念日:任务清单昨日完成的任务,最重要的三件事:改进:习惯养成:生活规律周目标·完成进度学习·信息·阅读早读英语健康·饮食·锻炼晚餐散步人际·家人·朋友陪伴家人工作·思考继续努力最美好的三件事1.每天都有小进步2.3.思考·创意·未来保持原有节奏,继续努力
- 2020-03-31
眸若含秋水丶
今天学习冒泡排序,通过双重for循环来实现数组有序排列。定义变量名要求:1数字字母下划线组成。2不能以关键字命名(int,printf,if,else等)。3不能以数字开头。作业1#includeintmain(){inti;intb;inta[8]={1,2,3,4,5,6,7,8};for(i=1;iintmain(){floata[10]={1,2,3,4,5,6,7,8,9,10};int
- 主流编程语言全景图:从Python到Rust的深度解析
万能小贤哥
pythonrust开发语言
2024年编程语言生态报告显示,全球开发者使用的语言数量已达260+,但真正主导行业的不到20种。本文带你穿透技术迷雾,掌握8大核心语言的本质差异。一、选择编程语言的黄金标准图表代码二、八大主流语言对比解析1.Python-通用胶水语言特性:动态类型+缩进语法丰富的库生态(20万+包)GIL全局锁限制并发适用场景:python#机器学习示例(TensorFlow)importtensorflowa
- 边缘智能革命:嵌入式机器学习如何让万物“思考”
万能小贤哥
机器学习人工智能
当智能手表精准识别你的健身动作,工业传感器预测设备故障于毫秒之间,农业传感器自动调节灌溉水量——这些并非科幻场景,而是嵌入式机器学习(EmbeddedMachineLearning,或TinyML)正在悄然重塑的现实。这场发生在设备边缘的智能革命,正将AI从云端的数据中心拉近到我们指尖的每一台设备中。一、嵌入式机器学习:定义与核心价值嵌入式机器学习是指在资源极端受限的微控制器(MCU)、微处理器(
- 感恩日记2021/02/28总1591
喜羊羊_43e1
感恩爱人早起煮饺子。感恩营养美味的早餐对我身体的滋养。随喜爱人种下健康、时间、满愿、和谐的种子。感恩和爱人一起看望婆婆。感恩婆婆在弟弟弟媳的精心照顾下状态良好,看到婆婆早上吃了一碗多的米粥非常开心。感恩金钱宝宝支持我们夫妇支付弟媳照顾婆婆的费用。1月份、2月份是由小侄女照顾的,小侄女作为一个大学生,作为家族里的第三代,能够尽心尽力照顾奶奶两个月,实属难得。小侄女是我们这些长辈学习的榜样。多少的语言
- 青春里重要的你!
靖然呐
图片发自App青春里能够遇见你真好!每个人的青春只有一回,我应该珍惜我们仅有的青春时光,可能这份珍惜是在学习上,但更多的应该是青春里的那个他(她)因为她(他)而努力奋斗。喜欢又不敢开口,只能默默的在背后跟随,直至青春结束,步入职场,默默守护!鼓起勇气去告白吧,不要在以后的某个时刻,而后悔此生没有选择对她(他)说,直到她(他)从你的身边永远走远。
- 远方文学二级要开课了
洮南远方文学
图片发自App近几日有家长不断咨询二级课程。二级课程开始正式学习小说和戏剧。像《红楼梦》、《巴黎圣母院》这些长篇小说是世界文学精粹!二级与一级不同,背诵比较少,主要是理解小说人物和情节。我们希望能够基于语文这个平台,让孩子从情感上从人性上得到更健康的影响,同时,我们真正的让孩子能够运用语言文字提升作品理解能力。人生路漫漫,好多东西是需要用投入时间和精力才能完成的!图片发自App
- 良心高效的记单词软件
d6863d4a4904
墨墨背单词(名字千万别弄错了!)这款帮助大家学习英语单词的软件,相信很多学习党小伙伴们或者身边的同学都会有使用过的,尤其是在加深单词记忆方面,根据同学们每天对所学单词的熟练或者模糊程度,结合了艾宾浩斯的遗忘曲线,根据时间长短来不断复现,坚持使用的话效果很不错噢!以下内容均为本人(一名不知名的考研党)亲测。大家要是想加强英语词汇量一定要试试啊!强推背单词软件!!首先是app签到页面,这个页面只有你每
- 2021-06-04 不吼不叫如何调动孩子的主动性
天下谁人不读书
爸爸妈妈都有过这样的经验,叫孩子吃饭,三请四请都不动;让他去洗澡,东摸摸西看看,就是不去洗;要他去读书学习,更是这翻翻那弄弄,导致父母不得不靠吼叫的高压手段才会起点作用。父母和孩子的目标有着巨大的差距,当他不饿,不想洗澡,不愿读书写字的时候,内心是抗拒的,因为他只会想那是父母要他去做,而不是自己想去做的事。日常对孩子教育,就像推一个木偶,推一下动一下,每天的生活就是父母一直在重复吼叫、催促、唠叨教
- 红场
小霞老师mn
曼宁妈妈,晚上好。⊙∀⊙!这节课主要学习了红场,介绍了俄罗斯的首都莫斯科的中心广场红场及一些著名的建筑,如克里姆林宫等,用线描去表现装饰。这幅画还没有结束,曼宁说很喜欢俄罗斯的天空,下节课还会抽半小时,带着她把颜色上了。曼宁的学习状态很好,整节课都很认真,速度也很快。下次要注意一下画面的整洁性,线条再干净一点点就完美了。继续加油(^ω^)
- 讚(232-0857)|智能方法练习王羲之的《圣教序》(硬笔)|每日精进
开心练字
所谓取法乎上,学习行书自然要学习书圣王羲之,而学书圣行书的最佳入门途径是学习和练习《圣教序》,毛笔如此,硬笔亦如此。几种常见形态比较image《圣教序》的特色言字旁极度夸张的拉开上下距离为全字增加了一丝“动感”。开心指数欣赏指数:★★★★☆易写指数:★★★☆☆实用指数:★★☆☆☆行笔路线(笔顺)image行笔路线如图:行楷的结构特征image形体(整体视野)左右视角——左低右高:整体呈斜的“行”书
- 2020-12-30
c5d317597ea8
20201230智慧父母课堂李艳坚持分享第4天今天我们学习了《古人谈读书》这篇文章,古人就告诉我们了读书的方法及读书的三到,即心到、眼到、口到。难怪一些学生读书爱加字,缺字主要是没有用心,今后要告诉他们读书的时候一定要用心。在今后的学习中三到都要用到,这样才能提高成绩。
- 2019-03-12
黄侠_美兮妈
【美兮修能】20190312识字营009期D110(学习力践行记录D499)早上读了《民国老课本》第121课,看了《森林里的小房子》,读了一本牛津树《Thejourey》。图片发自App下午从幼儿园回来的路上背了《望庐山瀑布》《瀑布》。晚饭后上外教课,玩得很开心。图片发自App然后和小伙伴一起做实验,熔岩大爆发、颜色变变变和彩虹糖水。图片发自App然后他们一起玩颜色。又拼了小猪佩奇的拼图。图片发自
- 我的90天PPT修行历程
舞动_Echo
大家好,我是PPT营销力50期超越梦想最666组的黄玉丽看到我的名字你们应该能感受到我本是软妹子But,你们知道吗~提前嘚瑟一下我居然打卡了一次线下演讲秀的总统筹这其中的飞跃让我忍不住回过头看看自己究竟做了什么起源自工作以来,一直在修炼自己负责公司对外分享的PPT一次成功的商业分享不仅需要演讲者本身的能力更需要ppt视觉传达力的冲击在PPT学习道路上一直孤军奋战自学过程中水平持续保持稳定因此一直在
- 微服务网站开发学习路线与RuoYi-Cloud实战指南
你喜欢喝可乐吗?
ruoyi-cloudmicroservicesjavaweb微服务学习运维
微服务网站开发学习路线与RuoYi-Cloud实战指南微服务架构已成为现代网站开发的主流选择,它通过将大型应用拆分为小型自治服务,实现了系统的高内聚、低耦合、独立部署和扩展。掌握微服务开发技能需要系统性学习,从基础概念到技术栈再到实战应用。本文将为您提供从零开始学习微服务的完整路线图,并结合RuoYi-Cloud开源框架进行详细举例,帮助您快速上手微服务网站开发。一、微服务基础概念与架构特点微服务
- 我明明是老师,“病毒”把我变成了主播。
顾若_
我明明是老师,“病毒”把我变成了主播。或许这是资历较深的老师们第一次成为“主播”;或许这是刚刚步入教师职位的年轻教师第一次网上授课;或许都有所不习惯,甚至家长也可能不适应学生在家中学习。早有很多的app都有线上教学,如小猿搜题、作业帮、线上名师讲课E网通等等。这次的疫情,使得全国中小学、高中、乃至大学生都是在网上开展教学工作,还有一些企业也将在网上进行办公~~对于学生网上学习、教师网上办公、授课、
- 学习中
田慧婷
坚持打卡记录第98天今天期中考试成绩全部出来,孩子们考的不太理想,不过高分的还是可以的,全校前200名占了6个,好了太多!两级分化太严重!
- 初见:冬天开的猫印象
繁星月影
跟随着八月的雨的足迹,邂逅了一只优秀博学的猫。于辛丑年甲午月壬辰日晚,与友冬天开的猫初见,缘于友八月的雨文理解是一门艺术中的评论。由于这段对话,我也很好奇啊,于是我也去见识见识这脑洞大开想象力丰富的人儿,悄悄的关注一下,向优秀的友学习,打算悄悄的去膜拜友的文。猫姐姐,在这看不出年龄距离,看大家都这样称呼,感觉比较亲切。之前猫的签名“你好,我这有些故事”,正好我也是喜欢看故事的人,喜欢听故事。后来签
- 精进打卡1209
我怕我忘记你_6e63
【每日精进打卡第319天】姓名:张晓雪公司:淮安市金鸡喜满堂食品有限公司349期六项精进(南京)乐观二组学员一.【知-学习】10.《活法》9.诵读《六项精进》通篇1遍,共230遍;8.诵读《大学》1遍,共230遍;7.诵读《六项精进》大纲共101遍;6.诵读《大学》开篇译文共95遍;5.诵读《王门四句教》共89遍;4.诵读《立志篇》共91遍;3.诵读《经营与会计》共3遍;2.诵读《京瓷哲学》共2遍
- 日精进109天
金八力韩英雪
敬爱的老师,智慧的班主任,亲爱的跃友们:大家好!我是来自山峰教外教育的韩英雪,今天是我的日精进行动第109天,给大家分享我今天的进步,我们互相勉励,携手前行。每天进步一点点,距离成功便不远。1、比学习:教育的人口功能:一,减少人口数量,控制人口增长。二,改善人口素质提高人口质量。三是人口结构趋向合理化。四有利于人口迁移。社会政治经济制度对教育的影响和制约,决定教育的领导权,决定受教育权决定教育目的
- 我喜欢你,像风走了八百里,不问归期
简冉的生活日记
1缘分来源于他的撩骚和我的一见钟情我们认识的时候完全是两种性格的人,在和沙沙在一起前,我觉得我和这样的人是一辈子都不会有交集。那年我刚上大一,对大学生活充满好奇。沙沙大二,已经开始厌倦学校。我虽然学习不太好,可是还是乖乖的在上课。沙沙也学习不好,可是整天往学校外面跑。我妆画的有点浓,爱穿漂亮衣服,可是从不乱处朋友。沙沙打扮社会,爱穿热血高校那样的外套,乱七八糟的朋友一大堆。我会去酒吧,会喝点酒,可
- 私信回复 | 非英专翻译新手如何入行?有多难?
福州翻译Ivy
收到了一条写得清清楚楚的私信:我是今年的应届毕业生,本科经济学跨考了语言学,毕业前跟你一样签了一家大公司的市场岗,实习了几个月,也纠结了几个月,最终在签劳动合同前离职了。一是觉得公司带教机制不完善不利职业成长,二是纠结于千辛万苦为了热爱而跨考的语言专业会逐渐丢弃(日日加班打破了我业余做点翻译的幻想)。过去的整个七月,我想了很多也看了很多资料,最终还是决定做口笔译。但我研究生学习的是偏理论的语言学,
- 2022-12-26
胡诌文学
今天看到一个人发了文章说不再买书了,这是时代的悲哀,也是时代的幸运,以前,知识就像是一个象牙塔,虽说事事洞明皆学问,但躲不过黄金屋的书籍,但是现在,知识扩散越来越明显,我们只要有心,就可学习,不必纠结于书
- Kubernetes学习笔记(四)--Pod 状态与生命周期管理
Mr小三
Kubernetes云原生kubernetes
文章目录四、Pod状态与生命周期管理1.Pod概念网络存储用法pod的终止2.Init容器init模板用途3.Pause容器4.Pod的生命周期Podphase(阶段)Pod状态5.Pod健康-容器探针(Probe)概念EXEC探针HTTP探针TCPSocket探针四、Pod状态与生命周期管理Pod是kubernetes中最重要的基本概念,在kubernetes中最小的管理元素不是一个个独立的容器
- 仓库货物检测:基于YOLOv5的深度学习应用与UI界面开发
YOLO实战营
YOLO深度学习ui目标跟踪目标检测人工智能
一、引言随着电商和物流行业的快速发展,仓库货物管理已经成为企业运营中至关重要的环节。为了提高仓库管理的效率和准确性,越来越多的企业开始应用自动化技术来完成货物的盘点、分类、分拣等任务。传统的货物管理方式通常依赖人工检查,不仅效率低下,而且容易出现误差。为了克服这些问题,利用计算机视觉和深度学习技术来实现仓库货物的自动化检测成为了一种有效的解决方案。本博客将介绍如何使用YOLOv5进行仓库货物检测,
- 2021-5-11晨间日记
飞翔_8019
今天是什么日子起床:7:05就寝:23:32天气:晴天心情:好纪念日:昨天跟闺蜜聊天一个多小时叫我起床的不是闹钟是梦想年度目标及关键点:财富自由本月重要成果:理财投资学习今日三只青蛙/番茄钟1.读书2.日更文章成功日志-记录三五件有收获的事务1.不能自己欺骗自己,要实事求是能做多少,不能做多少,为什么做不了,要分析原因。不能太迁就自己。2.自己最近做事效率不高。要想办法提高效率。3.规定自己什么时
- KL散度:信息差异的量化标尺 | 从概率分布对齐到模型优化的核心度量
不对称性、计算本质与机器学习的普适应用本文由「大千AI助手」原创发布,专注用真话讲AI,回归技术本质。拒绝神话或妖魔化。搜索「大千AI助手」关注我,一起撕掉过度包装,学习真实的AI技术!一、核心定义与数学本质KL散度(Kullback-LeiblerDivergence)用于衡量两个概率分布PPP和QQQ的差异程度,定义为:DKL(P∥Q)=∑x∈XP(x)logP(x)Q(x)(离散形式)D_
- 亲子日记第九天
康靖祺姑姑
2018年4月6日星期五天气阴转多云今天晚上吃过饭,问了康靖祺一些昨天作业上的知识,掌握的不是很好。这个学期开学以后数学学习直接下降了,两次都是80多,按理来说不应该这样。放假前发了一张试卷,出错率很高,有的直接没看懂题直接乱写,还有就是直接不会。今晚我问了一个15+15都答错了。他二姑姑还说早上说话口气太不行了,直接让他二姑姑闭嘴,我一听这话我就想起他妈妈训他的时候,除了闭嘴就是滚一边。家长是孩
- Transformer:自注意力驱动的神经网络革命引擎
大千AI助手
人工智能Python#OTHERtransformer神经网络深度学习google人工智能机器学习大模型
本文由「大千AI助手」原创发布,专注用真话讲AI,回归技术本质。拒绝神话或妖魔化。搜索「大千AI助手」关注我,一起撕掉过度包装,学习真实的AI技术!从语言理解到多模态智能的通用架构基石⚙️一、核心定义与历史意义Transformer是由Google团队在2017年论文《AttentionIsAllYouNeed》中提出的深度学习架构,其颠覆性创新在于:完全摒弃RNN/CNN:仅依赖自注意力机制(S
- [特殊字符] LLM(大型语言模型):智能时代的语言引擎与通用推理基座
大千AI助手
人工智能Python#OTHER语言模型人工智能自然语言处理LLM大模型Transformer
本文由「大千AI助手」原创发布,专注用真话讲AI,回归技术本质。拒绝神话或妖魔化。搜索「大千AI助手」关注我,一起撕掉过度包装,学习真实的AI技术!从千亿参数到人类认知的AI革命一、核心定义与核心特征LLM(LargeLanguageModel)是基于海量文本数据训练的深度学习模型,通过神经网络架构(尤其是Transformer)模拟人类语言的复杂规律,实现文本理解、生成与推理任务。其核心特征可概
- JAVA基础
灵静志远
位运算加载Date字符串池覆盖
一、类的初始化顺序
1 (静态变量,静态代码块)-->(变量,初始化块)--> 构造器
同一括号里的,根据它们在程序中的顺序来决定。上面所述是同一类中。如果是继承的情况,那就在父类到子类交替初始化。
二、String
1 String a = "abc";
JAVA虚拟机首先在字符串池中查找是否已经存在了值为"abc"的对象,根
- keepalived实现redis主从高可用
bylijinnan
redis
方案说明
两台机器(称为A和B),以统一的VIP对外提供服务
1.正常情况下,A和B都启动,B会把A的数据同步过来(B is slave of A)
2.当A挂了后,VIP漂移到B;B的keepalived 通知redis 执行:slaveof no one,由B提供服务
3.当A起来后,VIP不切换,仍在B上面;而A的keepalived 通知redis 执行slaveof B,开始
- java文件操作大全
0624chenhong
java
最近在博客园看到一篇比较全面的文件操作文章,转过来留着。
http://www.cnblogs.com/zhuocheng/archive/2011/12/12/2285290.html
转自http://blog.sina.com.cn/s/blog_4a9f789a0100ik3p.html
一.获得控制台用户输入的信息
&nbs
- android学习任务
不懂事的小屁孩
工作
任务
完成情况 搞清楚带箭头的pupupwindows和不带的使用 已完成 熟练使用pupupwindows和alertdialog,并搞清楚两者的区别 已完成 熟练使用android的线程handler,并敲示例代码 进行中 了解游戏2048的流程,并完成其代码工作 进行中-差几个actionbar 研究一下android的动画效果,写一个实例 已完成 复习fragem
- zoom.js
换个号韩国红果果
oom
它的基于bootstrap 的
https://raw.github.com/twbs/bootstrap/master/js/transition.js transition.js模块引用顺序
<link rel="stylesheet" href="style/zoom.css">
<script src=&q
- 详解Oracle云操作系统Solaris 11.2
蓝儿唯美
Solaris
当Oracle发布Solaris 11时,它将自己的操作系统称为第一个面向云的操作系统。Oracle在发布Solaris 11.2时继续它以云为中心的基调。但是,这些说法没有告诉我们为什么Solaris是配得上云的。幸好,我们不需要等太久。Solaris11.2有4个重要的技术可以在一个有效的云实现中发挥重要作用:OpenStack、内核域、统一存档(UA)和弹性虚拟交换(EVS)。
- spring学习——springmvc(一)
a-john
springMVC
Spring MVC基于模型-视图-控制器(Model-View-Controller,MVC)实现,能够帮助我们构建像Spring框架那样灵活和松耦合的Web应用程序。
1,跟踪Spring MVC的请求
请求的第一站是Spring的DispatcherServlet。与大多数基于Java的Web框架一样,Spring MVC所有的请求都会通过一个前端控制器Servlet。前
- hdu4342 History repeat itself-------多校联合五
aijuans
数论
水题就不多说什么了。
#include<iostream>#include<cstdlib>#include<stdio.h>#define ll __int64using namespace std;int main(){ int t; ll n; scanf("%d",&t); while(t--)
- EJB和javabean的区别
asia007
beanejb
EJB不是一般的JavaBean,EJB是企业级JavaBean,EJB一共分为3种,实体Bean,消息Bean,会话Bean,书写EJB是需要遵循一定的规范的,具体规范你可以参考相关的资料.另外,要运行EJB,你需要相应的EJB容器,比如Weblogic,Jboss等,而JavaBean不需要,只需要安装Tomcat就可以了
1.EJB用于服务端应用开发, 而JavaBeans
- Struts的action和Result总结
百合不是茶
strutsAction配置Result配置
一:Action的配置详解:
下面是一个Struts中一个空的Struts.xml的配置文件
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE struts PUBLIC
&quo
- 如何带好自已的团队
bijian1013
项目管理团队管理团队
在网上看到博客"
怎么才能让团队成员好好干活"的评论,觉得写的比较好。 原文如下: 我做团队管理有几年了吧,我和你分享一下我认为带好团队的几点:
1.诚信
对团队内成员,无论是技术研究、交流、问题探讨,要尽可能的保持一种诚信的态度,用心去做好,你的团队会感觉得到。 2.努力提
- Java代码混淆工具
sunjing
ProGuard
Open Source Obfuscators
ProGuard
http://java-source.net/open-source/obfuscators/proguardProGuard is a free Java class file shrinker and obfuscator. It can detect and remove unused classes, fields, m
- 【Redis三】基于Redis sentinel的自动failover主从复制
bit1129
redis
在第二篇中使用2.8.17搭建了主从复制,但是它存在Master单点问题,为了解决这个问题,Redis从2.6开始引入sentinel,用于监控和管理Redis的主从复制环境,进行自动failover,即Master挂了后,sentinel自动从从服务器选出一个Master使主从复制集群仍然可以工作,如果Master醒来再次加入集群,只能以从服务器的形式工作。
什么是Sentine
- 使用代理实现Hibernate Dao层自动事务
白糖_
DAOspringAOP框架Hibernate
都说spring利用AOP实现自动事务处理机制非常好,但在只有hibernate这个框架情况下,我们开启session、管理事务就往往很麻烦。
public void save(Object obj){
Session session = this.getSession();
Transaction tran = session.beginTransaction();
try
- maven3实战读书笔记
braveCS
maven3
Maven简介
是什么?
Is a software project management and comprehension tool.项目管理工具
是基于POM概念(工程对象模型)
[设计重复、编码重复、文档重复、构建重复,maven最大化消除了构建的重复]
[与XP:简单、交流与反馈;测试驱动开发、十分钟构建、持续集成、富有信息的工作区]
功能:
- 编程之美-子数组的最大乘积
bylijinnan
编程之美
public class MaxProduct {
/**
* 编程之美 子数组的最大乘积
* 题目: 给定一个长度为N的整数数组,只允许使用乘法,不能用除法,计算任意N-1个数的组合中乘积中最大的一组,并写出算法的时间复杂度。
* 以下程序对应书上两种方法,求得“乘积中最大的一组”的乘积——都是有溢出的可能的。
* 但按题目的意思,是要求得这个子数组,而不
- 读书笔记-2
chengxuyuancsdn
读书笔记
1、反射
2、oracle年-月-日 时-分-秒
3、oracle创建有参、无参函数
4、oracle行转列
5、Struts2拦截器
6、Filter过滤器(web.xml)
1、反射
(1)检查类的结构
在java.lang.reflect包里有3个类Field,Method,Constructor分别用于描述类的域、方法和构造器。
2、oracle年月日时分秒
s
- [求学与房地产]慎重选择IT培训学校
comsci
it
关于培训学校的教学和教师的问题,我们就不讨论了,我主要关心的是这个问题
培训学校的教学楼和宿舍的环境和稳定性问题
我们大家都知道,房子是一个比较昂贵的东西,特别是那种能够当教室的房子...
&nb
- RMAN配置中通道(CHANNEL)相关参数 PARALLELISM 、FILESPERSET的关系
daizj
oraclermanfilespersetPARALLELISM
RMAN配置中通道(CHANNEL)相关参数 PARALLELISM 、FILESPERSET的关系 转
PARALLELISM ---
我们还可以通过parallelism参数来指定同时"自动"创建多少个通道:
RMAN > configure device type disk parallelism 3 ;
表示启动三个通道,可以加快备份恢复的速度。
- 简单排序:冒泡排序
dieslrae
冒泡排序
public void bubbleSort(int[] array){
for(int i=1;i<array.length;i++){
for(int k=0;k<array.length-i;k++){
if(array[k] > array[k+1]){
- 初二上学期难记单词三
dcj3sjt126com
sciet
concert 音乐会
tonight 今晚
famous 有名的;著名的
song 歌曲
thousand 千
accident 事故;灾难
careless 粗心的,大意的
break 折断;断裂;破碎
heart 心(脏)
happen 偶尔发生,碰巧
tourist 旅游者;观光者
science (自然)科学
marry 结婚
subject 题目;
- I.安装Memcahce 1. 安装依赖包libevent Memcache需要安装libevent,所以安装前可能需要执行 Shell代码 收藏代码
dcj3sjt126com
redis
wget http://download.redis.io/redis-stable.tar.gz
tar xvzf redis-stable.tar.gz
cd redis-stable
make
前面3步应该没有问题,主要的问题是执行make的时候,出现了异常。
异常一:
make[2]: cc: Command not found
异常原因:没有安装g
- 并发容器
shuizhaosi888
并发容器
通过并发容器来改善同步容器的性能,同步容器将所有对容器状态的访问都串行化,来实现线程安全,这种方式严重降低并发性,当多个线程访问时,吞吐量严重降低。
并发容器ConcurrentHashMap
替代同步基于散列的Map,通过Lock控制。
&nb
- Spring Security(12)——Remember-Me功能
234390216
Spring SecurityRemember Me记住我
Remember-Me功能
目录
1.1 概述
1.2 基于简单加密token的方法
1.3 基于持久化token的方法
1.4 Remember-Me相关接口和实现
- 位运算
焦志广
位运算
一、位运算符C语言提供了六种位运算符:
& 按位与
| 按位或
^ 按位异或
~ 取反
<< 左移
>> 右移
1. 按位与运算 按位与运算符"&"是双目运算符。其功能是参与运算的两数各对应的二进位相与。只有对应的两个二进位均为1时,结果位才为1 ,否则为0。参与运算的数以补码方式出现。
例如:9&am
- nodejs 数据库连接 mongodb mysql
liguangsong
mongodbmysqlnode数据库连接
1.mysql 连接
package.json中dependencies加入
"mysql":"~2.7.0"
执行 npm install
在config 下创建文件 database.js
- java动态编译
olive6615
javaHotSpotjvm动态编译
在HotSpot虚拟机中,有两个技术是至关重要的,即动态编译(Dynamic compilation)和Profiling。
HotSpot是如何动态编译Javad的bytecode呢?Java bytecode是以解释方式被load到虚拟机的。HotSpot里有一个运行监视器,即Profile Monitor,专门监视
- Storm0.9.5的集群部署配置优化
roadrunners
优化storm.yaml
nimbus结点配置(storm.yaml)信息:
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional inf
- 101个MySQL 的调节和优化的提示
tomcat_oracle
mysql
1. 拥有足够的物理内存来把整个InnoDB文件加载到内存中——在内存中访问文件时的速度要比在硬盘中访问时快的多。 2. 不惜一切代价避免使用Swap交换分区 – 交换时是从硬盘读取的,它的速度很慢。 3. 使用电池供电的RAM(注:RAM即随机存储器)。 4. 使用高级的RAID(注:Redundant Arrays of Inexpensive Disks,即磁盘阵列
- zoj 3829 Known Notation(贪心)
阿尔萨斯
ZOJ
题目链接:zoj 3829 Known Notation
题目大意:给定一个不完整的后缀表达式,要求有2种不同操作,用尽量少的操作使得表达式完整。
解题思路:贪心,数字的个数要要保证比∗的个数多1,不够的话优先补在开头是最优的。然后遍历一遍字符串,碰到数字+1,碰到∗-1,保证数字的个数大于等1,如果不够减的话,可以和最后面的一个数字交换位置(用栈维护十分方便),因为添加和交换代价都是1