机器学习指南_机器学习-快速指南

机器学习指南
机器学习-快速指南 (Machine Learning - Quick Guide)
机器学习-简介 (Machine Learning - Introduction)
Today’s Artificial Intelligence (AI) has far surpassed the hype of blockchain and quantum computing. This is due to the fact that huge computing resources are easily available to the common man. The developers now take advantage of this in creating new Machine Learning models and to re-train the existing models for better performance and results. The easy availability of High Performance Computing (HPC) has resulted in a sudden increased demand for IT professionals having Machine Learning skills.
当今的人工智能(AI)远远超过了区块链和量子计算的炒作。 这是因为事实是,普通人很容易获得大量的计算资源。 开发人员现在可以利用此优势来创建新的机器学习模型,并对现有模型进行重新训练,以获得更好的性能和结果。 高性能计算(HPC)的便捷可用性导致对具有机器学习技能的IT专业人员的需求突然增加。
In this tutorial, you will learn in detail about −
在本教程中,您将详细了解-
What is the crux of machine learning?
机器学习的关键是什么?
What are the different types in machine learning?
机器学习有哪些不同类型?
What are the different algorithms available for developing machine learning models?
开发机器学习模型有哪些不同的算法?
What tools are available for developing these models?
有哪些工具可用于开发这些模型?
What are the programming language choices?
编程语言有哪些选择?
What platforms support development and deployment of Machine Learning applications?
哪些平台支持机器学习应用程序的开发和部署?
What IDEs (Integrated Development Environment) are available?
有哪些可用的IDE(集成开发环境)?
How to quickly upgrade your skills in this important area?
如何快速提升您在这一重要领域的技能?
机器学习-当今的AI可以做什么? (Machine Learning - What Today’s AI Can Do?)
When you tag a face in a Facebook photo, it is AI that is running behind the scenes and identifying faces in a picture. Face tagging is now omnipresent in several applications that display pictures with human faces. Why just human faces? There are several applications that detect objects such as cats, dogs, bottles, cars, etc. We have autonomous cars running on our roads that detect objects in real time to steer the car. When you travel, you use Google Directions to learn the real-time traffic situations and follow the best path suggested by Google at that point of time. This is yet another implementation of object detection technique in real time.
当您在Facebook照片中标记面部时,是AI在幕后运行并识别图片中的面部。 现在,在显示带有人脸图片的多个应用程序中,人脸标签已不存在。 为什么只是人脸? 有几种检测物体的应用程序,例如猫,狗,瓶子,汽车等。我们的自动驾驶汽车在道路上行驶,可以实时检测物体以操纵汽车。 旅途中,您可以使用Google 路线来了解实时路况,并遵循Google在该时间点建议的最佳路线。 这是对象检测技术的另一种实时实现。
Let us consider the example of Google Translate application that we typically use while visiting foreign countries. Google’s online translator app on your mobile helps you communicate with the local people speaking a language that is foreign to you.
让我们考虑在国外旅行时通常使用的Google Translate应用程序示例。 您的移动设备上的Google在线翻译应用可帮助您与说当地语言的当地人交流。
There are several applications of AI that we use practically today. In fact, each one of us use AI in many parts of our lives, even without our knowledge. Today’s AI can perform extremely complex jobs with a great accuracy and speed. Let us discuss an example of complex task to understand what capabilities are expected in an AI application that you would be developing today for your clients.
我们今天实际使用了AI的几种应用程序。 实际上,即使没有我们的知识,我们每个人在生活的许多部分中都使用AI。 当今的AI可以以极高的准确性和速度执行极其复杂的工作。 让我们讨论一个复杂任务的示例,以了解您今天将为客户开发的AI应用程序中期望具有哪些功能。
例 (Example)
We all use Google Directions during our trip anywhere in the city for a daily commute or even for inter-city travels. Google Directions application suggests the fastest path to our destination at that time instance. When we follow this path, we have observed that Google is almost 100% right in its suggestions and we save our valuable time on the trip.
在旅途中,我们所有人都会在城市中的任何地方使用Google 路线来进行日常通勤,甚至进行城市间旅行。 Google路线指示应用程序会建议您在该时间段到达我们目的地的最快路径。 当我们沿着这条路走时,我们发现Google的建议几乎是100%正确,并且节省了旅途中的宝贵时间。
You can imagine the complexity involved in developing this kind of application considering that there are multiple paths to your destination and the application has to judge the traffic situation in every possible path to give you a travel time estimate for each such path. Besides, consider the fact that Google Directions covers the entire globe. Undoubtedly, lots of AI and Machine Learning techniques are in-use under the hoods of such applications.
您可以想象开发此类应用程序所涉及的复杂性,考虑到到目的地有多条路径,并且该应用程序必须判断每个可能路径中的交通状况,才能为每个此类路径提供行驶时间估计。 此外,考虑一下Google Directions覆盖全球的事实。 毫无疑问,许多AI和机器学习技术正在此类应用的后台使用。
Considering the continuous demand for the development of such applications, you will now appreciate why there is a sudden demand for IT professionals with AI skills.
考虑到对此类应用程序开发的持续需求,您现在将理解为什么突然需要具有AI技能的IT专业人员。
In our next chapter, we will learn what it takes to develop AI programs.
在下一章中,我们将学习开发AI程序的过程。
机器学习-传统AI (Machine Learning - Traditional AI)
The journey of AI began in the 1950's when the computing power was a fraction of what it is today. AI started out with the predictions made by the machine in a fashion a statistician does predictions using his calculator. Thus, the initial entire AI development was based mainly on statistical techniques.
人工智能的旅程始于1950年代,当时计算能力只是今天的一小部分。 AI首先由机器做出的预测以统计学家使用计算器进行预测的方式进行。 因此,最初的整个AI开发主要基于统计技术。
In this chapter, let us discuss in detail what these statistical techniques are.
在本章中,让我们详细讨论什么是统计技术。
统计技术 (Statistical Techniques)
The development of today’s AI applications started with using the age-old traditional statistical techniques. You must have used straight-line interpolation in schools to predict a future value. There are several other such statistical techniques which are successfully applied in developing so-called AI programs. We say “so-called” because the AI programs that we have today are much more complex and use techniques far beyond the statistical techniques used by the early AI programs.
当今的AI应用程序的开发始于使用古老的传统统计技术。 您必须在学校中使用直线插值法来预测未来价值。 还有其他几种此类统计技术已成功应用于开发所谓的AI程序。 我们之所以说“所谓的”,是因为我们今天拥有的AI程序要复杂得多,并且所使用的技术远远超出了早期AI程序所使用的统计技术。
Some of the examples of statistical techniques that are used for developing AI applications in those days and are still in practice are listed here −
此处列出了当时用于开发AI应用且仍在实践中的一些统计技术示例-
- Regression 回归
- Classification 分类
- Clustering 聚类
- Probability Theories 概率论
- Decision Trees 决策树
Here we have listed only some primary techniques that are enough to get you started on AI without scaring you of the vastness that AI demands. If you are developing AI applications based on limited data, you would be using these statistical techniques.
在这里,我们仅列出了一些基本技术,这些技术足以使您开始使用AI,而又不会吓到AI所需的广阔空间。 如果您要基于有限的数据开发AI应用程序,则将使用这些统计技术。
However, today the data is abundant. To analyze the kind of huge data that we possess statistical techniques are of not much help as they have some limitations of their own. More advanced methods such as deep learning are hence developed to solve many complex problems.
但是,今天的数据非常丰富。 分析拥有统计技术的海量数据的种类并没有太大帮助,因为它们有其自身的局限性。 因此,开发了诸如深度学习之类的更高级的方法来解决许多复杂的问题。
As we move ahead in this tutorial, we will understand what Machine Learning is and how it is used for developing such complex AI applications.
在本教程中,我们将了解什么是机器学习以及如何将其用于开发此类复杂的AI应用程序。
机器学习-什么是机器学习? (Machine Learning - What is Machine Learning?)
Consider the following figure that shows a plot of house prices versus its size in sq. ft.
考虑下图,该图显示了房价与平方英尺之间的关系图。
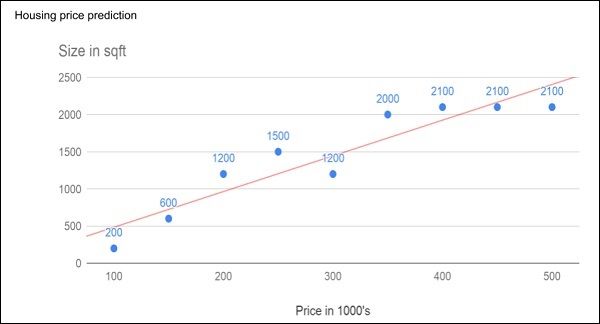
After plotting various data points on the XY plot, we draw a best-fit line to do our predictions for any other house given its size. You will feed the known data to the machine and ask it to find the best fit line. Once the best fit line is found by the machine, you will test its suitability by feeding in a known house size, i.e. the Y-value in the above curve. The machine will now return the estimated X-value, i.e. the expected price of the house. The diagram can be extrapolated to find out the price of a house which is 3000 sq. ft. or even larger. This is called regression in statistics. Particularly, this kind of regression is called linear regression as the relationship between X & Y data points is linear.
在XY绘图上绘制各种数据点之后,我们绘制一条最适合的线来对给定尺寸的其他房屋进行预测。 您将已知数据输入机器,并要求其找到最合适的线。 一旦机器找到最合适的线,您将通过输入已知的房屋大小(即上述曲线中的Y值)来测试其适用性。 机器现在将返回估计的X值,即房屋的预期价格。 可以对该图进行推断,以找出3000平方英尺甚至更大的房屋价格。 这称为统计回归。 特别是,由于X和Y数据点之间的关系是线性的,因此这种回归称为线性回归。
In many cases, the relationship between the X & Y data points may not be a straight line, and it may be a curve with a complex equation. Your task would be now to find out the best fitting curve which can be extrapolated to predict the future values. One such application plot is shown in the figure below.
在许多情况下,X和Y数据点之间的关系可能不是直线,而可能是具有复杂方程式的曲线。 您现在的任务是找出最佳拟合曲线,可以将其外推以预测未来值。 下图显示了一个这样的应用程序图。

Source:
资源:
https://upload.wikimedia.org/wikipedia/commons/c/c9/
https://upload.wikimedia.org/wikipedia/commons/c/c9/
You will use the statistical optimization techniques to find out the equation for the best fit curve here. And this is what exactly Machine Learning is about. You use known optimization techniques to find the best solution to your problem.
您将在此处使用统计优化技术来找到最佳拟合曲线的方程式。 这正是机器学习的目的。 您使用已知的优化技术来找到问题的最佳解决方案。
Next, let us look at the different categories of Machine Learning.
接下来,让我们看一下机器学习的不同类别。
机器学习-类别 (Machine Learning - Categories)
Machine Learning is broadly categorized under the following headings −
机器学习大致分为以下几类:

Machine learning evolved from left to right as shown in the above diagram.
如上图所示,机器学习从左到右发展。
Initially, researchers started out with Supervised Learning. This is the case of housing price prediction discussed earlier.
最初,研究人员从监督学习开始。 前面讨论过的房价预测就是这种情况。
This was followed by unsupervised learning, where the machine is made to learn on its own without any supervision.
随后是无监督学习,使机器无需任何监督即可自行学习。
Scientists discovered further that it may be a good idea to reward the machine when it does the job the expected way and there came the Reinforcement Learning.
科学家进一步发现,当机器按预期方式完成工作时,对机器进行奖励可能是个好主意,然后出现了强化学习。
Very soon, the data that is available these days has become so humongous that the conventional techniques developed so far failed to analyze the big data and provide us the predictions.
很快,这些天可用的数据变得如此庞大,以至于迄今为止开发的常规技术未能分析大数据并无法为我们提供预测。
Thus, came the deep learning where the human brain is simulated in the Artificial Neural Networks (ANN) created in our binary computers.
因此,出现了深度学习,其中在我们的二进制计算机中创建的人工神经网络(ANN)中模拟了人的大脑。
The machine now learns on its own using the high computing power and huge memory resources that are available today.
该机器现在可以利用当今可用的强大计算能力和巨大的内存资源自行学习。
It is now observed that Deep Learning has solved many of the previously unsolvable problems.
现在可以看到,深度学习解决了许多以前无法解决的问题。
The technique is now further advanced by giving incentives to Deep Learning networks as awards and there finally comes Deep Reinforcement Learning.
现在,通过奖励深度学习网络作为奖励,该技术得到了进一步的发展,最终出现了深度强化学习。
Let us now study each of these categories in more detail.
现在让我们更详细地研究每个类别。
监督学习 (Supervised Learning)
Supervised learning is analogous to training a child to walk. You will hold the child’s hand, show him how to take his foot forward, walk yourself for a demonstration and so on, until the child learns to walk on his own.
监督学习类似于训练孩子走路。 您将握住孩子的手,向他展示如何使自己的脚向前走,自己示范自己,等等,直到孩子学会自己走路。
回归 (Regression)
Similarly, in the case of supervised learning, you give concrete known examples to the computer. You say that for given feature value x1 the output is y1, for x2 it is y2, for x3 it is y3, and so on. Based on this data, you let the computer figure out an empirical relationship between x and y.
同样,在监督学习的情况下,您可以给计算机提供具体的已知示例。 您说对于给定的特征值x1,输出为y1,对于x2为y2,对于x3为y3,依此类推。 根据这些数据,您可以让计算机找出x和y之间的经验关系。
Once the machine is trained in this way with a sufficient number of data points, now you would ask the machine to predict Y for a given X. Assuming that you know the real value of Y for this given X, you will be able to deduce whether the machine’s prediction is correct.
用足够数量的数据点以这种方式训练机器之后,现在您将要求机器为给定的X预测Y。假设您知道给定X的Y的实际值,则可以得出机器的预测是否正确。
Thus, you will test whether the machine has learned by using the known test data. Once you are satisfied that the machine is able to do the predictions with a desired level of accuracy (say 80 to 90%) you can stop further training the machine.
因此,您将使用已知的测试数据来测试机器是否已学习。 一旦您对机器能够以所需的准确度(例如80%到90%)进行预测感到满意,就可以停止进一步训练机器。
Now, you can safely use the machine to do the predictions on unknown data points, or ask the machine to predict Y for a given X for which you do not know the real value of Y. This training comes under the regression that we talked about earlier.
现在,您可以安全地使用机器对未知数据点进行预测,或要求机器针对您不知道Y实际值的给定X预测Y。此训练来自我们所讨论的回归较早。
分类 (Classification)
You may also use machine learning techniques for classification problems. In classification problems, you classify objects of similar nature into a single group. For example, in a set of 100 students say, you may like to group them into three groups based on their heights - short, medium and long. Measuring the height of each student, you will place them in a proper group.
您也可以使用机器学习技术来解决分类问题。 在分类问题中,您将相似性质的对象分类为一个组。 例如,假设有一组100名学生说,您可能希望根据身高将他们分为三类-矮,中和长。 测量每个学生的身高,您可以将他们放在适当的组中。
Now, when a new student comes in, you will put him in an appropriate group by measuring his height. By following the principles in regression training, you will train the machine to classify a student based on his feature – the height. When the machine learns how the groups are formed, it will be able to classify any unknown new student correctly. Once again, you would use the test data to verify that the machine has learned your technique of classification before putting the developed model in production.
现在,当一个新学生进来时,您可以通过测量他的身高将他分成合适的组。 通过遵循回归训练中的原理,您将训练机器以根据学生的特征(身高)对学生进行分类。 当机器学习如何形成组时,它将能够正确地对任何未知的新学生进行分类。 再一次,您将使用测试数据来验证机器在将开发的模型投入生产之前已经学习了您的分类技术。
Supervised Learning is where the AI really began its journey. This technique was applied successfully in several cases. You have used this model while doing the hand-written recognition on your machine. Several algorithms have been developed for supervised learning. You will learn about them in the following chapters.
监督学习是AI真正开始其旅程的地方。 该技术已成功应用于多种情况。 您在机器上进行手写识别时使用了此模型。 已经开发了几种用于监督学习的算法。 您将在以下各章中了解它们。
无监督学习 (Unsupervised Learning)
In unsupervised learning, we do not specify a target variable to the machine, rather we ask machine “What can you tell me about X?”. More specifically, we may ask questions such as given a huge data set X, “What are the five best groups we can make out of X?” or “What features occur together most frequently in X?”. To arrive at the answers to such questions, you can understand that the number of data points that the machine would require to deduce a strategy would be very large. In case of supervised learning, the machine can be trained with even about few thousands of data points. However, in case of unsupervised learning, the number of data points that is reasonably accepted for learning starts in a few millions. These days, the data is generally abundantly available. The data ideally requires curating. However, the amount of data that is continuously flowing in a social area network, in most cases data curation is an impossible task.
在无监督学习中,我们没有为机器指定目标变量,而是询问机器“您能告诉我有关X的什么信息?”。 更具体地说,我们可能会问一些问题,例如给定一个庞大的数据集X,“我们可以从X得出的五个最佳分组是什么?” 或“哪些功能在X中最常同时出现?”。 为了得到这些问题的答案,您可以理解,机器推导出策略所需的数据点数量将非常大。 在监督学习的情况下,甚至可以用数千个数据点来训练机器。 但是,在无监督学习的情况下,为学习而合理接受的数据点的数量从几百万开始。 这些天,数据通常非常丰富。 理想情况下,数据需要整理。 但是,在大多数情况下,社交区域网络中不断流动的数据量是一项不可能的任务。
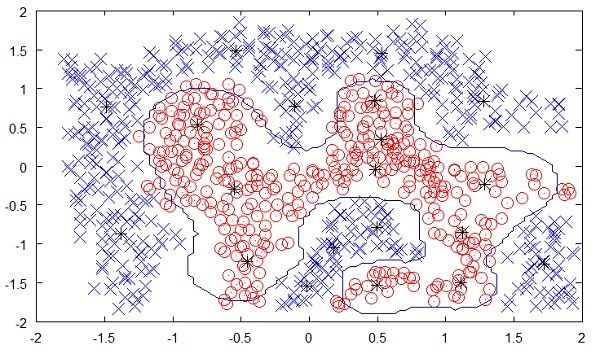
The following figure shows the boundary between the yellow and red dots as determined by unsupervised machine learning. You can see it clearly that the machine would be able to determine the class of each of the black dots with a fairly good accuracy.
下图显示了由无监督机器学习确定的黄点和红点之间的边界。 您可以清楚地看到,该机器将能够以相当好的精度确定每个黑点的类别。
Source:
资源:
https://chrisjmccormick.files.wordpress.com/2013/08/approx_decision_boun dary.png
https://chrisjmccormick.files.wordpress.com/2013/08/approx_decision_boun dary.png
The unsupervised learning has shown a great success in many modern AI applications, such as face detection, object detection, and so on.
无监督学习已在许多现代AI应用程序中取得了巨大的成功,例如人脸检测,对象检测等。
强化学习 (Reinforcement Learning)
Consider training a pet dog, we train our pet to bring a ball to us. We throw the ball at a certain distance and ask the dog to fetch it back to us. Every time the dog does this right, we reward the dog. Slowly, the dog learns that doing the job rightly gives him a reward and then the dog starts doing the job right way every time in future. Exactly, this concept is applied in “Reinforcement” type of learning. The technique was initially developed for machines to play games. The machine is given an algorithm to analyze all possible moves at each stage of the game. The machine may select one of the moves at random. If the move is right, the machine is rewarded, otherwise it may be penalized. Slowly, the machine will start differentiating between right and wrong moves and after several iterations would learn to solve the game puzzle with a better accuracy. The accuracy of winning the game would improve as the machine plays more and more games.
考虑训练宠物狗,我们训练宠物将球带给我们。 我们将球扔到一定距离,然后请狗把它取回给我们。 每当狗做这件事时,我们都会奖励狗。 慢慢地,狗知道正确地做这项工作会给他奖励,然后狗以后每次都会以正确的方式开始做这项工作。 确实,此概念适用于“强化”类型的学习。 该技术最初是为玩游戏的机器开发的。 为机器提供了一种算法,可以分析游戏每个阶段的所有可能动作。 机器可以随机选择其中一个动作。 如果移动正确,则将奖励该机器,否则可能会受到处罚。 慢慢地,机器将开始区分对与错步,经过多次迭代将学会更好地解决游戏难题。 随着机器玩越来越多的游戏,赢得比赛的准确性将会提高。
The entire process may be depicted in the following diagram −
下图描述了整个过程-
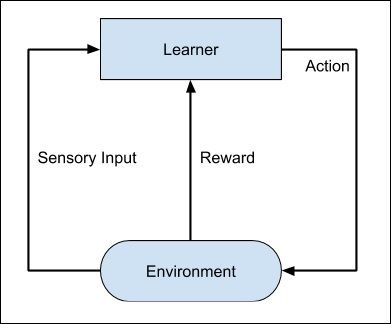
This technique of machine learning differs from the supervised learning in that you need not supply the labelled input/output pairs. The focus is on finding the balance between exploring the new solutions versus exploiting the learned solutions.
这种机器学习技术与监督学习的不同之处在于,您无需提供标记的输入/输出对。 重点是在探索新解决方案与利用学习到的解决方案之间找到平衡。
深度学习 (Deep Learning)
The deep learning is a model based on Artificial Neural Networks (ANN), more specifically Convolutional Neural Networks (CNN)s. There are several architectures used in deep learning such as deep neural networks, deep belief networks, recurrent neural networks, and convolutional neural networks.
深度学习是基于人工神经网络(ANN),更具体地说是卷积神经网络(CNN)的模型。 深度学习中使用了多种架构,例如深度神经网络,深度置信网络,递归神经网络和卷积神经网络。
These networks have been successfully applied in solving the problems of computer vision, speech recognition, natural language processing, bioinformatics, drug design, medical image analysis, and games. There are several other fields in which deep learning is proactively applied. The deep learning requires huge processing power and humongous data, which is generally easily available these days.
这些网络已成功应用于解决计算机视觉,语音识别,自然语言处理,生物信息学,药物设计,医学图像分析和游戏等问题。 积极应用深度学习还有其他几个领域。 深度学习需要强大的处理能力和庞大的数据,这些天通常很容易获得。
We will talk about deep learning more in detail in the coming chapters.
在接下来的章节中,我们将更详细地讨论深度学习。
深度强化学习 (Deep Reinforcement Learning)
The Deep Reinforcement Learning (DRL) combines the techniques of both deep and reinforcement learning. The reinforcement learning algorithms like Q-learning are now combined with deep learning to create a powerful DRL model. The technique has been with a great success in the fields of robotics, video games, finance and healthcare. Many previously unsolvable problems are now solved by creating DRL models. There is lots of research going on in this area and this is very actively pursued by the industries.
深度强化学习(DRL)结合了深度学习和强化学习的技术。 现在,像Q学习这样的强化学习算法与深度学习相结合,以创建强大的DRL模型。 该技术在机器人技术,视频游戏,金融和医疗保健领域取得了巨大的成功。 现在,通过创建DRL模型可以解决许多以前无法解决的问题。 在这个领域有很多研究正在进行,并且行业非常积极地追求这一点。
So far, you have got a brief introduction to various machine learning models, now let us explore slightly deeper into various algorithms that are available under these models.
到目前为止,您已经对各种机器学习模型进行了简要介绍,现在让我们更深入地探索这些模型下可用的各种算法。
机器学习-监督 (Machine Learning - Supervised)
Supervised learning is one of the important models of learning involved in training machines. This chapter talks in detail about the same.
监督学习是培训机器中涉及的重要学习模型之一。 本章将详细讨论。
监督学习算法 (Algorithms for Supervised Learning)
There are several algorithms available for supervised learning. Some of the widely used algorithms of supervised learning are as shown below −
有几种可用于监督学习的算法。 一些广泛使用的监督学习算法如下所示-
- k-Nearest Neighbours k最近邻居
- Decision Trees 决策树
- Naive Bayes 朴素贝叶斯
- Logistic Regression 逻辑回归
- Support Vector Machines 支持向量机
As we move ahead in this chapter, let us discuss in detail about each of the algorithms.
随着本章的深入,让我们详细讨论每种算法。
k最近邻居 (k-Nearest Neighbours)
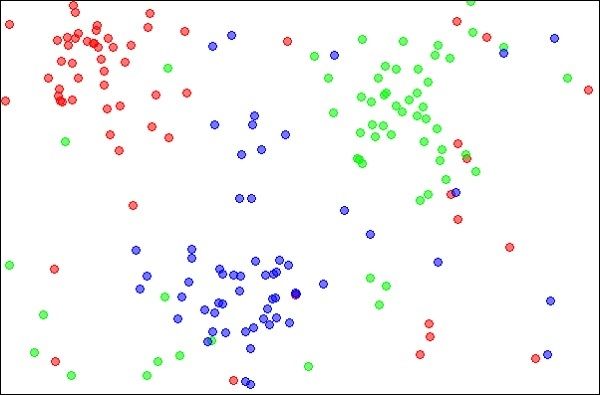
The k-Nearest Neighbours, which is simply called kNN is a statistical technique that can be used for solving for classification and regression problems. Let us discuss the case of classifying an unknown object using kNN. Consider the distribution of objects as shown in the image given below −
k最近邻居,简称为kNN,是一种统计技术,可用于解决分类和回归问题。 让我们讨论使用kNN对未知对象进行分类的情况。 考虑对象的分布,如下图所示-
Source:
资源:
https://en.wikipedia.org/wiki/K-nearest_neighbors_algorithm
https://zh.wikipedia.org/wiki/K-nearest_neighbors_algorithm
The diagram shows three types of objects, marked in red, blue and green colors. When you run the kNN classifier on the above dataset, the boundaries for each type of object will be marked as shown below −
该图显示了三种类型的对象,分别用红色,蓝色和绿色标记。 在上述数据集上运行kNN分类器时,每种类型的对象的边界都将被标记,如下所示-

Source:
资源:
https://en.wikipedia.org/wiki/K-nearest_neighbors_algorithm
https://zh.wikipedia.org/wiki/K-nearest_neighbors_algorithm
Now, consider a new unknown object that you want to classify as red, green or blue. This is depicted in the figure below.
现在,考虑要分类为红色,绿色或蓝色的新未知对象。 如下图所示。
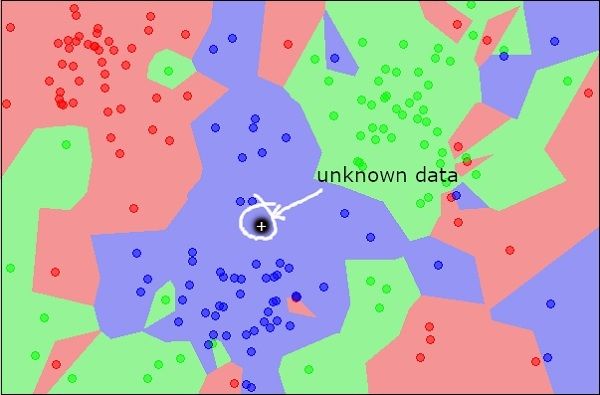
As you see it visually, the unknown data point belongs to a class of blue objects. Mathematically, this can be concluded by measuring the distance of this unknown point with every other point in the data set. When you do so, you will know that most of its neighbours are of blue color. The average distance to red and green objects would be definitely more than the average distance to blue objects. Thus, this unknown object can be classified as belonging to blue class.
从视觉上看,未知数据点属于一类蓝色对象。 从数学上讲,这可以通过测量此未知点与数据集中其他每个点的距离来得出结论。 当您这样做时,您将知道它的大多数邻居都是蓝色的。 到红色和绿色物体的平均距离肯定会比到蓝色物体的平均距离大。 因此,该未知物体可以被分类为属于蓝色类别。
The kNN algorithm can also be used for regression problems. The kNN algorithm is available as ready-to-use in most of the ML libraries.
kNN算法也可以用于回归问题。 在大多数ML库中,都可以立即使用kNN算法。
决策树 (Decision Trees)
A simple decision tree in a flowchart format is shown below −
下面显示了流程图格式的简单决策树-
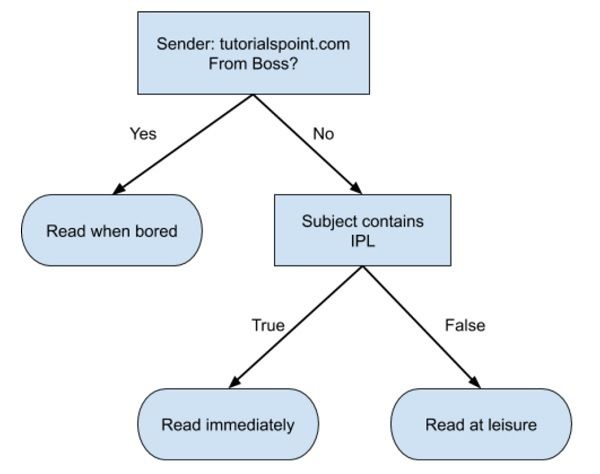
You would write a code to classify your input data based on this flowchart. The flowchart is self-explanatory and trivial. In this scenario, you are trying to classify an incoming email to decide when to read it.
您将根据此流程图编写代码以对输入数据进行分类。 流程图是不言而喻的,琐碎的。 在这种情况下,您尝试对传入的电子邮件进行分类,以决定何时阅读。
In reality, the decision trees can be large and complex. There are several algorithms available to create and traverse these trees. As a Machine Learning enthusiast, you need to understand and master these techniques of creating and traversing decision trees.
实际上,决策树可能很大而且很复杂。 有几种可用于创建和遍历这些树的算法。 作为机器学习爱好者,您需要了解和掌握创建和遍历决策树的这些技术。
朴素贝叶斯 (Naive Bayes)
Naive Bayes is used for creating classifiers. Suppose you want to sort out (classify) fruits of different kinds from a fruit basket. You may use features such as color, size and shape of a fruit, For example, any fruit that is red in color, is round in shape and is about 10 cm in diameter may be considered as Apple. So to train the model, you would use these features and test the probability that a given feature matches the desired constraints. The probabilities of different features are then combined to arrive at a probability that a given fruit is an Apple. Naive Bayes generally requires a small number of training data for classification.
朴素贝叶斯用于创建分类器。 假设您要从水果篮中分类(分类)不同种类的水果。 您可以使用诸如水果的颜色,大小和形状之类的功能,例如,任何红色,圆形,直径约10厘米的水果都可以视为Apple。 因此,要训练模型,您将使用这些功能并测试给定功能与所需约束匹配的可能性。 然后将不同特征的概率合并,得出给定水果是苹果的概率。 朴素贝叶斯通常需要少量的训练数据进行分类。
逻辑回归 (Logistic Regression)
Look at the following diagram. It shows the distribution of data points in XY plane.
看下图。 它显示了数据点在XY平面中的分布。

From the diagram, we can visually inspect the separation of red dots from green dots. You may draw a boundary line to separate out these dots. Now, to classify a new data point, you will just need to determine on which side of the line the point lies.
从图中,我们可以直观地检查红点与绿点的分离。 您可以绘制边界线以分离出这些点。 现在,要分类一个新的数据点,您只需确定该点位于线的哪一边。
支持向量机 (Support Vector Machines)
Look at the following distribution of data. Here the three classes of data cannot be linearly separated. The boundary curves are non-linear. In such a case, finding the equation of the curve becomes a complex job.
查看以下数据分布。 这里,这三类数据无法线性分离。 边界曲线是非线性的。 在这种情况下,找到曲线的方程变得很复杂。

Source: http://uc-r.github.io/svm
资料来源: http : //uc-r.github.io/svm
The Support Vector Machines (SVM) comes handy in determining the separation boundaries in such situations.
支持向量机(SVM)在确定这种情况下的分离边界时非常方便。
机器学习-Scikit学习算法 (Machine Learning - Scikit-learn Algorithm)
Fortunately, most of the time you do not have to code the algorithms mentioned in the previous lesson. There are many standard libraries which provide the ready-to-use implementation of these algorithms. One such toolkit that is popularly used is scikit-learn. The figure below illustrates the kind of algorithms which are available for your use in this library.
幸运的是,大多数时候您不必编写上一课中提到的算法。 有许多标准库提供了这些算法的即用型实现。 scikit-learn是一种常用的工具包。 下图说明了该库中可使用的算法类型。

Source: https://scikit-learn.org/stable/tutorial/machine_learning_map/index.html
资料来源: https : //scikit-learn.org/stable/tutorial/machine_learning_map/index.html
The use of these algorithms is trivial and since these are well and field tested, you can safely use them in your AI applications. Most of these libraries are free to use even for commercial purposes.
这些算法的使用很简单,并且由于它们已经过现场测试,因此可以在AI应用程序中安全地使用它们。 这些库大多数都可以免费使用,甚至用于商业目的。
机器学习-无监督 (Machine Learning - Unsupervised)
So far what you have seen is making the machine learn to find out the solution to our target. In regression, we train the machine to predict a future value. In classification, we train the machine to classify an unknown object in one of the categories defined by us. In short, we have been training machines so that it can predict Y for our data X. Given a huge data set and not estimating the categories, it would be difficult for us to train the machine using supervised learning. What if the machine can look up and analyze the big data running into several Gigabytes and Terabytes and tell us that this data contains so many distinct categories?
到目前为止,您所看到的是使机器学习找出解决我们目标的方法。 在回归中,我们训练机器以预测未来价值。 在分类中,我们训练机器将未知对象分类为我们定义的类别之一。 简而言之,我们一直在训练机器,以便它可以为我们的数据X预测Y。给定庞大的数据集且未估计类别,对于我们而言,使用监督学习来训练机器将非常困难。 如果机器可以查找并分析运行到数GB和TB的大数据,并告诉我们该数据包含许多不同的类别,该怎么办?
As an example, consider the voter’s data. By considering some inputs from each voter (these are called features in AI terminology), let the machine predict that there are so many voters who would vote for X political party and so many would vote for Y, and so on. Thus, in general, we are asking the machine given a huge set of data points X, “What can you tell me about X?”. Or it may be a question like “What are the five best groups we can make out of X?”. Or it could be even like “What three features occur together most frequently in X?”.
例如,考虑选民的数据。 通过考虑每个选民的一些输入(在AI术语中称为特征),让机器预测有太多选民将为X政党投票,而有很多选民为Y政党投票,依此类推。 因此,总的来说,我们要求机器给定大量的数据点X,“关于X,您能告诉我什么?”。 或可能有一个问题,例如“我们可以从X中选出五个最好的小组?”。 甚至可能就像“在X中哪三个功能最常同时出现?”一样。
This is exactly the Unsupervised Learning is all about.
这正是无监督学习的全部内容。
无监督学习算法 (Algorithms for Unsupervised Learning)
Let us now discuss one of the widely used algorithms for classification in unsupervised machine learning.
现在让我们讨论一种在无监督机器学习中广泛使用的分类算法。
k均值聚类 (k-means clustering)
The 2000 and 2004 Presidential elections in the United States were close — very close. The largest percentage of the popular vote that any candidate received was 50.7% and the lowest was 47.9%. If a percentage of the voters were to have switched sides, the outcome of the election would have been different. There are small groups of voters who, when properly appealed to, will switch sides. These groups may not be huge, but with such close races, they may be big enough to change the outcome of the election. How do you find these groups of people? How do you appeal to them with a limited budget? The answer is clustering.
美国的2000年和2004年总统大选已经接近,非常接近。 在所有候选人中,获得最高票数的民众投票是50.7%,而最低的是47.9%。 如果一定比例的选民要换面,选举的结果将是不同的。 有几小组选民,如果受到适当的呼吁,将改变立场。 这些团体可能并不庞大,但由于种族如此亲密,它们可能足以改变选举结果。 您如何找到这些人? 在预算有限的情况下,您如何吸引他们? 答案是集群。
Let us understand how it is done.
让我们了解它是如何完成的。
First, you collect information on people either with or without their consent: any sort of information that might give some clue about what is important to them and what will influence how they vote.
首先,您收集有关经过或未经过他们同意的人的信息:可能提供一些线索的信息,这些线索对他们来说很重要,什么会影响他们的投票方式。
Then you put this information into some sort of clustering algorithm.
然后,您将此信息放入某种聚类算法中。
Next, for each cluster (it would be smart to choose the largest one first) you craft a message that will appeal to these voters.
接下来,对于每个集群(首先选择最大的集群是明智的),您将制作出一条吸引这些选民的信息。
Finally, you deliver the campaign and measure to see if it’s working.
最后,您交付广告活动并进行衡量以查看其是否有效。
Clustering is a type of unsupervised learning that automatically forms clusters of similar things. It is like automatic classification. You can cluster almost anything, and the more similar the items are in the cluster, the better the clusters are. In this chapter, we are going to study one type of clustering algorithm called k-means. It is called k-means because it finds ‘k’ unique clusters, and the center of each cluster is the mean of the values in that cluster.
聚类是一种无监督学习,可自动形成相似事物的聚类。 就像自动分类一样。 您几乎可以对任何事物进行聚类,并且聚类中的项目越相似,聚类就越好。 在本章中,我们将研究一种称为k-means的聚类算法。 之所以称为k-均值,是因为它找到“ k”个唯一的簇,并且每个簇的中心是该簇中值的平均值。
集群识别 (Cluster Identification)
Cluster identification tells an algorithm, “Here’s some data. Now group similar things together and tell me about those groups.” The key difference from classification is that in classification you know what you are looking for. While that is not the case in clustering.
集群识别告诉一种算法,“这里有一些数据。 现在将类似的事物归为一类,并向我介绍这些分组。” 分类的主要区别在于分类中您知道要查找的内容。 虽然在集群中不是这种情况。
Clustering is sometimes called unsupervised classification because it produces the same result as classification does but without having predefined classes.
聚类有时称为无监督分类,因为它产生与分类相同的结果,但是没有预定义的类。
Now, we are comfortable with both supervised and unsupervised learning. To understand the rest of the machine learning categories, we must first understand Artificial Neural Networks (ANN), which we will learn in the next chapter.
现在,我们对有监督和无监督学习都感到满意。 要了解其余的机器学习类别,我们必须首先了解人工神经网络(ANN),我们将在下一章中学习。
机器学习-人工神经网络 (Machine Learning - Artificial Neural Networks)
The idea of artificial neural networks was derived from the neural networks in the human brain. The human brain is really complex. Carefully studying the brain, the scientists and engineers came up with an architecture that could fit in our digital world of binary computers. One such typical architecture is shown in the diagram below −
人工神经网络的思想源于人脑中的神经网络。 人脑真的很复杂。 科学家和工程师仔细研究了大脑,提出了一种适合我们二进制计算机数字世界的架构。 下图显示了一种这样的典型架构-
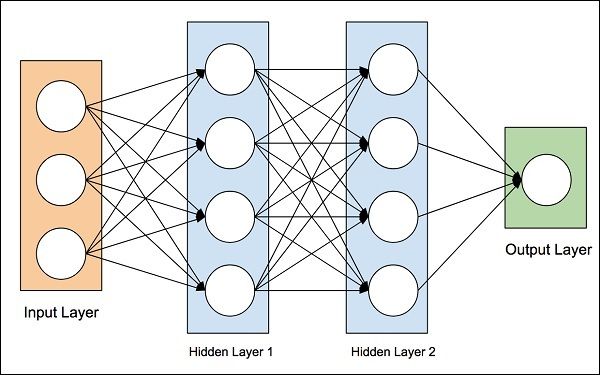
There is an input layer which has many sensors to collect data from the outside world. On the right hand side, we have an output layer that gives us the result predicted by the network. In between these two, several layers are hidden. Each additional layer adds further complexity in training the network, but would provide better results in most of the situations. There are several types of architectures designed which we will discuss now.
有一个输入层,其中有许多传感器来收集来自外界的数据。 在右侧,我们有一个输出层,可为我们提供网络预测的结果。 在这两者之间,隐藏了几层。 每增加一层,都会增加网络训练的复杂性,但在大多数情况下会提供更好的结果。 我们现在将讨论几种设计的体系结构。
人工神经网络架构 (ANN Architectures)
The diagram below shows several ANN architectures developed over a period of time and are in practice today.
下图显示了一段时间内开发的几种ANN架构,目前已在实践中。
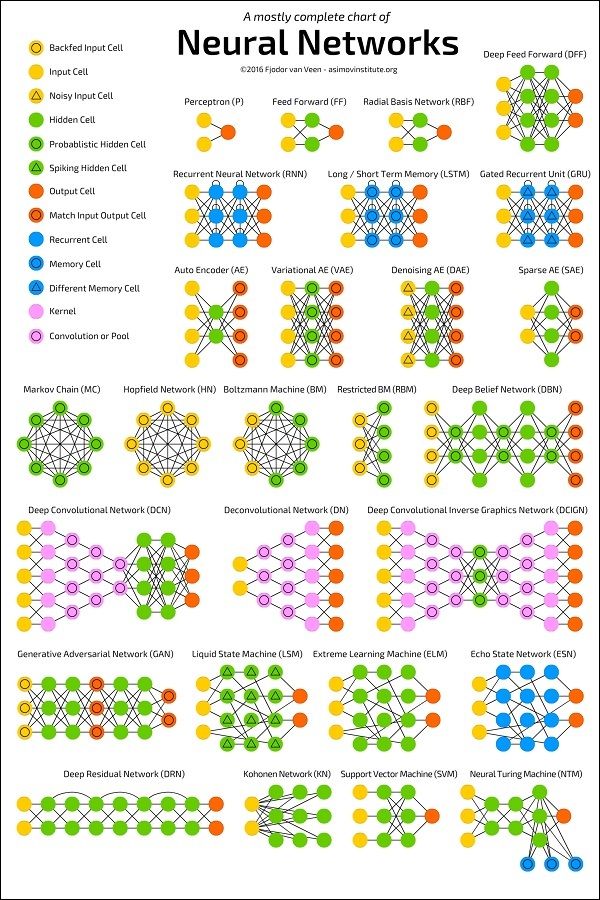
Source:
资源:
https://towardsdatascience.com/the-mostly-complete-chart-of-neural-networks-explained-3fb6f2367464
https://towardsdatascience.com/the-mostly-complete-chart-of-neural-networks-explained-3fb6f2367464
Each architecture is developed for a specific type of application. Thus, when you use a neural network for your machine learning application, you will have to use either one of the existing architecture or design your own. The type of application that you finally decide upon depends on your application needs. There is no single guideline that tells you to use a specific network architecture.
每种体系结构都是针对特定类型的应用程序开发的。 因此,当您将神经网络用于您的机器学习应用程序时,您将必须使用现有架构之一或自行设计。 您最终决定使用的应用程序类型取决于您的应用程序需求。 没有单一的准则可以告诉您使用特定的网络体系结构。
机器学习-深度学习 (Machine Learning - Deep Learning)
Deep Learning uses ANN. First we will look at a few deep learning applications that will give you an idea of its power.
深度学习使用ANN。 首先,我们将研究一些深度学习应用程序,这些应用程序将使您对其功能有所了解。
应用领域 (Applications)
Deep Learning has shown a lot of success in several areas of machine learning applications.
深度学习在机器学习应用程序的多个领域显示出了许多成功。
Self-driving Cars − The autonomous self-driving cars use deep learning techniques. They generally adapt to the ever changing traffic situations and get better and better at driving over a period of time.
自动驾驶汽车 -自动驾驶汽车使用深度学习技术。 它们通常会适应不断变化的交通状况,并且在一段时间内会越来越好。
Speech Recognition − Another interesting application of Deep Learning is speech recognition. All of us use several mobile apps today that are capable of recognizing our speech. Apple’s Siri, Amazon’s Alexa, Microsoft’s Cortena and Google’s Assistant – all these use deep learning techniques.
语音识别 -深度学习的另一个有趣的应用是语音识别。 今天我们所有人都使用能够识别我们语音的几个移动应用程序。 苹果的Siri,亚马逊的Alexa,微软的Cortena和Google的助手-所有这些都使用深度学习技术。
Mobile Apps − We use several web-based and mobile apps for organizing our photos. Face detection, face ID, face tagging, identifying objects in an image – all these use deep learning.
移动应用程序 -我们使用多个基于Web的移动应用程序来组织照片。 人脸检测,人脸ID,人脸标记,识别图像中的对象–所有这些都使用深度学习。
深度学习的未开发机会 (Untapped Opportunities of Deep Learning)
After looking at the great success deep learning applications have achieved in many domains, people started exploring other domains where machine learning was not so far applied. There are several domains in which deep learning techniques are successfully applied and there are many other domains which can be exploited. Some of these are discussed here.
在研究了深度学习应用在许多领域取得的巨大成功之后,人们开始探索到目前为止尚未应用机器学习的其他领域。 深度学习技术在多个领域得到成功应用,其他许多领域也可以被利用。 其中一些在这里讨论。
Agriculture is one such industry where people can apply deep learning techniques to improve the crop yield.
农业就是这样一种行业,人们可以应用深度学习技术来提高农作物的产量。
Consumer finance is another area where machine learning can greatly help in providing early detection on frauds and analyzing customer’s ability to pay.
消费金融是机器学习可以极大地帮助提供欺诈的早期检测并分析客户的支付能力的另一个领域。
Deep learning techniques are also applied to the field of medicine to create new drugs and provide a personalized prescription to a patient.
深度学习技术还应用于医学领域,以开发新药并向患者提供个性化处方。
The possibilities are endless and one has to keep watching as the new ideas and developments pop up frequently.
可能性是无止境的,随着新思想和新发展的频繁出现,人们必须不断观察。
使用深度学习实现更多要求 (What is Required for Achieving More Using Deep Learning)
To use deep learning, supercomputing power is a mandatory requirement. You need both memory as well as the CPU to develop deep learning models. Fortunately, today we have an easy availability of HPC – High Performance Computing. Due to this, the development of the deep learning applications that we mentioned above became a reality today and in the future too we can see the applications in those untapped areas that we discussed earlier.
要使用深度学习,超级计算能力是强制性要求。 您需要内存和CPU来开发深度学习模型。 幸运的是,今天我们可以轻松获得高性能计算(HPC)。 因此,上面提到的深度学习应用程序的开发在今天已经成为现实,在将来,我们也可以在我们前面讨论的那些尚未开发的领域中看到这些应用程序。
Now, we will look at some of the limitations of deep learning that we must consider before using it in our machine learning application.
现在,我们将研究在机器学习应用程序中使用深度学习之前必须考虑的一些局限性。
深度学习的缺点 (Deep Learning Disadvantages)
Some of the important points that you need to consider before using deep learning are listed below −
下面列出了在使用深度学习之前需要考虑的一些重要点-
- Black Box approach 黑匣子方法
- Duration of Development 开发时间
- Amount of Data 数据量
- Computationally Expensive 计算昂贵
We will now study each one of these limitations in detail.
现在,我们将详细研究这些限制中的每一个。
黑匣子方法 (Black Box approach)
An ANN is like a blackbox. You give it a certain input and it will provide you a specific output. The following diagram shows you one such application where you feed an animal image to a neural network and it tells you that the image is of a dog.
一个人工神经网络就像一个黑匣子。 您给它一个特定的输入,它将为您提供一个特定的输出。 下图显示了一个这样的应用程序,在该应用程序中,您将动物图像输入神经网络,并告诉您该图像是狗的。
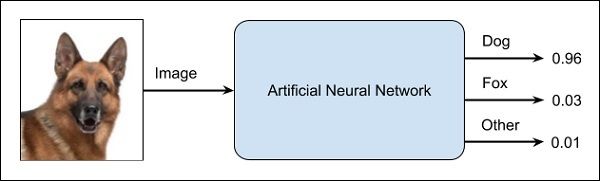
Why this is called a black-box approach is that you do not know why the network came up with a certain result. You do not know how the network concluded that it is a dog? Now consider a banking application where the bank wants to decide the creditworthiness of a client. The network will definitely provide you an answer to this question. However, will you be able to justify it to a client? Banks need to explain it to their customers why the loan is not sanctioned?
为什么将其称为黑盒方法,是因为您不知道为什么网络得出了一定的结果。 您不知道网络如何断定那是狗吗? 现在考虑银行想要确定客户信誉的银行应用程序。 该网络肯定会为您提供该问题的答案。 但是,您可以向客户证明它的合理性吗? 银行需要向客户解释为什么不批准贷款?
开发时间 (Duration of Development)
The process of training a neural network is depicted in the diagram below −
下图描述了训练神经网络的过程-
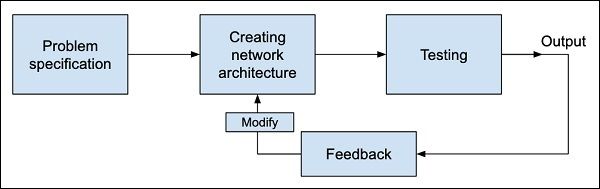
You first define the problem that you want to solve, create a specification for it, decide on the input features, design a network, deploy it and test the output. If the output is not as expected, take this as a feedback to restructure your network. This is an iterative process and may require several iterations until the time network is fully trained to produce desired outputs.
首先,您要定义要解决的问题,为其创建一个规范,确定输入功能,设计网络,进行部署并测试输出。 如果输出与预期不符,请以此作为重组网络的反馈。 这是一个反复的过程,可能需要多次迭代,直到时间网络经过充分训练以产生所需的输出为止。
数据量 (Amount of Data)
The deep learning networks usually require a huge amount of data for training, while the traditional machine learning algorithms can be used with a great success even with just a few thousands of data points. Fortunately, the data abundance is growing at 40% per year and CPU processing power is growing at 20% per year as seen in the diagram given below −
深度学习网络通常需要大量的数据来进行训练,而即使只有数千个数据点,传统的机器学习算法也可以非常成功地使用。 幸运的是,如下图所示,数据量以每年40%的速度增长,CPU处理能力以每年20%的速度增长-

计算昂贵 (Computationally Expensive)
Training a neural network requires several times more computational power than the one required in running traditional algorithms. Successful training of deep Neural Networks may require several weeks of training time.
训练神经网络所需的计算能力是运行传统算法所需的计算能力的几倍。 深度神经网络的成功培训可能需要数周的培训时间。
In contrast to this, traditional machine learning algorithms take only a few minutes/hours to train. Also, the amount of computational power needed for training deep neural network heavily depends on the size of your data and how deep and complex the network is?
与此相反,传统的机器学习算法只需要花费几分钟/几小时即可进行训练。 此外,训练深度神经网络所需的计算能力在很大程度上取决于数据的大小以及网络的深度和复杂程度?
After having an overview of what Machine Learning is, its capabilities, limitations, and applications, let us now dive into learning “Machine Learning”.
在概述了什么是机器学习,其功能,局限性和应用之后,让我们现在开始学习“机器学习”。
机器学习-技能 (Machine Learning - Skills)
Machine Learning has a very large width and requires skills across several domains. The skills that you need to acquire for becoming an expert in Machine Learning are listed below −
机器学习的范围非常广,需要跨多个领域的技能。 下面列出了成为机器学习专家所需的技能-
- Statistics 统计
- Probability Theories 概率论
- Calculus 结石
- Optimization techniques 优化技术
- Visualization 可视化
各种机器学习技能的必要性 (Necessity of Various Skills of Machine Learning)
To give you a brief idea of what skills you need to acquire, let us discuss some examples −
为了让您简要了解您需要掌握哪些技能,让我们讨论一些示例-
数学符号 (Mathematical Notation)
Most of the machine learning algorithms are heavily based on mathematics. The level of mathematics that you need to know is probably just a beginner level. What is important is that you should be able to read the notation that mathematicians use in their equations. For example - if you are able to read the notation and comprehend what it means, you are ready for learning machine learning. If not, you may need to brush up your mathematics knowledge.
大多数机器学习算法都很大程度上基于数学。 您需要了解的数学水平可能仅仅是初学者。 重要的是您应该能够阅读数学家在方程式中使用的表示法。 例如,如果您能够阅读该符号并理解其含义,那么您就可以学习机器学习了。 如果没有,您可能需要复习数学知识。
$$f_{AN}(net-\theta)=\begin{cases}\gamma & if\:net-\theta \geq \epsilon\\net-\theta & if - \epsilon< net-\theta
$$ f_ {AN}(net- \ theta)= \ begin {cases} \ gamma&if \:net- \ theta \ geq \ epsilon \\ net- \ theta&if-\ epsilon $$\displaystyle\\\max\limits_{\alpha}\begin{bmatrix}\displaystyle\sum\limits_{i=1}^m \alpha-\frac{1}{2}\displaystyle\sum\limits_{i,j=1}^m label^\left(\begin{array}{c}i\\ \end{array}\right)\cdot\:label^\left(\begin{array}{c}j\\ \end{array}\right)\cdot\:a_{i}\cdot\:a_{j}\langle x^\left(\begin{array}{c}i\\ \end{array}\right),x^\left(\begin{array}{c}j\\ \end{array}\right)\rangle \end{bmatrix}$$ $$ \ displaystyle \\\ max \ limits _ {\ alpha} \ begin {bmatrix} \ displaystyle \ sum \ limits_ {i = 1} ^ m \ alpha- \ frac {1} {2} \ displaystyle \ sum \ limits_ { i,j = 1} ^ m label ^ \ left(\ begin {array} {c} i \\ \ end {array} \ right)\ cdot \:label ^ \ left(\ begin {array} {c} j \\ \ end {array} \ right)\ cdot \:a_ {i} \ cdot \:a_ {j} \ langle x ^ \ left(\ begin {array} {c} i \\ \ end {array} \ right),x ^ \ left(\ begin {array} {c} j \\ \ end {array} \ right)\ rangle \ end {bmatrix} $$ $$f_{AN}(net-\theta)=\left(\frac{e^{\lambda(net-\theta)}-e^{-\lambda(net-\theta)}}{e^{\lambda(net-\theta)}+e^{-\lambda(net-\theta)}}\right)\;$$ $$ f_ {AN}(net- \ theta)= \ left(\ frac {e ^ {\ lambda(net- \ theta)}-e ^ {-\ lambda(net- \ theta)}} {e ^ { \ lambda(net- \ theta)} + e ^ {-\ lambda(net- \ theta)}} \ right)\; $$ Here is an example to test your current knowledge of probability theory: Classifying with conditional probabilities. 这是一个示例,用于测试您当前对概率论的了解:使用条件概率进行分类。 $$p(c_{i}|x,y)\;=\frac{p(x,y|c_{i})\;p(c_{i})\;}{p(x,y)\;}$$ $$ p(c_ {i} | x,y)\; = \ frac {p(x,y | c_ {i})\; p(c_ {i})\;} {p(x,y)\ ;} $$ With these definitions, we can define the Bayesian classification rule − 有了这些定义,我们可以定义贝叶斯分类规则- Here is an optimization function 这是一个优化功能 $$\displaystyle\\\max\limits_{\alpha}\begin{bmatrix}\displaystyle\sum\limits_{i=1}^m \alpha-\frac{1}{2}\displaystyle\sum\limits_{i,j=1}^m label^\left(\begin{array}{c}i\\ \end{array}\right)\cdot\:label^\left(\begin{array}{c}j\\ \end{array}\right)\cdot\:a_{i}\cdot\:a_{j}\langle x^\left(\begin{array}{c}i\\ \end{array}\right),x^\left(\begin{array}{c}j\\ \end{array}\right)\rangle \end{bmatrix}$$ $$ \ displaystyle \\\ max \ limits _ {\ alpha} \ begin {bmatrix} \ displaystyle \ sum \ limits_ {i = 1} ^ m \ alpha- \ frac {1} {2} \ displaystyle \ sum \ limits_ { i,j = 1} ^ m label ^ \ left(\ begin {array} {c} i \\ \ end {array} \ right)\ cdot \:label ^ \ left(\ begin {array} {c} j \\ \ end {array} \ right)\ cdot \:a_ {i} \ cdot \:a_ {j} \ langle x ^ \ left(\ begin {array} {c} i \\ \ end {array} \ right),x ^ \ left(\ begin {array} {c} j \\ \ end {array} \ right)\ rangle \ end {bmatrix} $$ Subject to the following constraints − 受到以下约束- $$\alpha\geq0,and\:\displaystyle\sum\limits_{i-1}^m \alpha_{i}\cdot\:label^\left(\begin{array}{c}i\\ \end{array}\right)=0$$ $$ \ alpha \ geq0和\:\ displaystyle \ sum \ limits_ {i-1} ^ m \ alpha_ {i} \ cdot \:label ^ \ left(\ begin {array} {c} i \\ \ end {array} \ right)= 0 $$ If you can read and understand the above, you are all set. 如果您能阅读和理解以上内容,那么您已经准备就绪。 In many cases, you will need to understand the various types of visualization plots to understand your data distribution and interpret the results of the algorithm’s output. 在许多情况下,您将需要了解各种类型的可视化图,以了解数据分布并解释算法输出的结果。 Besides the above theoretical aspects of machine learning, you need good programming skills to code those algorithms. 除了上述机器学习的理论方面之外,您还需要良好的编程技能才能对这些算法进行编码。 So what does it take to implement ML? Let us look into this in the next chapter. 那么实现ML需要做什么呢? 让我们在下一章对此进行研究。 To develop ML applications, you will have to decide on the platform, the IDE and the language for development. There are several choices available. Most of these would meet your requirements easily as all of them provide the implementation of AI algorithms discussed so far. 要开发ML应用程序,您必须决定平台,IDE和开发语言。 有几种选择。 其中大多数将轻松满足您的要求,因为它们全部都提供了到目前为止讨论的AI算法的实现。 If you are developing the ML algorithm on your own, the following aspects need to be understood carefully − 如果您自己开发ML算法,则需要仔细理解以下方面- The language of your choice − this essentially is your proficiency in one of the languages supported in ML development. 您选择的语言-本质上就是您精通ML开发支持的一种语言。 The IDE that you use − This would depend on your familiarity with the existing IDEs and your comfort level. 您使用的IDE-这取决于您对现有IDE的熟悉程度和舒适度。 Development platform − There are several platforms available for development and deployment. Most of these are free-to-use. In some cases, you may have to incur a license fee beyond a certain amount of usage. Here is a brief list of choice of languages, IDEs and platforms for your ready reference. 开发平台 -有几种可用于开发和部署的平台。 其中大多数都是免费使用。 在某些情况下,您可能需要支付超出一定使用量的许可费。 以下是可供选择的语言,IDE和平台的简要列表,供您随时参考。 Here is a list of languages that support ML development − 这是支持ML开发的语言列表- This list is not essentially comprehensive; however, it covers many popular languages used in machine learning development. Depending upon your comfort level, select a language for the development, develop your models and test. 该清单本质上并不全面; 但是,它涵盖了机器学习开发中使用的许多流行语言。 根据您的舒适程度,选择用于开发的语言,开发模型并进行测试。 Here is a list of IDEs which support ML development − 这是支持ML开发的IDE列表- The above list is not essentially comprehensive. Each one has its own merits and demerits. The reader is encouraged to try out these different IDEs before narrowing down to a single one. 上面的列表实际上并不全面。 每个人都有其优点和缺点。 鼓励读者在缩小范围到一个之前尝试这些不同的IDE。 Here is a list of platforms on which ML applications can be deployed − 这是可以部署ML应用程序的平台列表- Once again this list is not exhaustive. The reader is encouraged to sign-up for the abovementioned services and try them out themselves. 再次,此列表并不详尽。 鼓励读者注册上述服务并自己尝试。 This tutorial has introduced you to Machine Learning. Now, you know that Machine Learning is a technique of training machines to perform the activities a human brain can do, albeit bit faster and better than an average human-being. Today we have seen that the machines can beat human champions in games such as Chess, AlphaGO, which are considered very complex. You have seen that machines can be trained to perform human activities in several areas and can aid humans in living better lives. 本教程向您介绍了机器学习。 现在,您知道机器学习是一种训练机器以执行人脑可以执行的活动的技术,尽管它比普通人更快,更好。 今天,我们已经看到,这些机器可以在国际象棋,AlphaGO等游戏中击败人类冠军,这些游戏被认为非常复杂。 您已经看到,可以训练机器在多个区域执行人类活动,并且可以帮助人类过上更好的生活。 Machine Learning can be a Supervised or Unsupervised. If you have lesser amount of data and clearly labelled data for training, opt for Supervised Learning. Unsupervised Learning would generally give better performance and results for large data sets. If you have a huge data set easily available, go for deep learning techniques. You also have learned Reinforcement Learning and Deep Reinforcement Learning. You now know what Neural Networks are, their applications and limitations. 机器学习可以是有监督的也可以是无监督的。 如果您的数据量较少且需要明确标记的数据用于培训,请选择“监督学习”。 对于大数据集,无监督学习通常可以提供更好的性能和结果。 如果您拥有容易获得的庞大数据集,请使用深度学习技术。 您还已经学习了强化学习和深度强化学习。 您现在知道了神经网络是什么,它们的应用和局限性。 Finally, when it comes to the development of machine learning models of your own, you looked at the choices of various development languages, IDEs and Platforms. Next thing that you need to do is start learning and practicing each machine learning technique. The subject is vast, it means that there is width, but if you consider the depth, each topic can be learned in a few hours. Each topic is independent of each other. You need to take into consideration one topic at a time, learn it, practice it and implement the algorithm/s in it using a language choice of yours. This is the best way to start studying Machine Learning. Practicing one topic at a time, very soon you would acquire the width that is eventually required of a Machine Learning expert. 最后,在开发自己的机器学习模型时,您研究了各种开发语言,IDE和平台的选择。 接下来需要做的是开始学习和练习每种机器学习技术。 主题很广泛,这意味着宽度很大,但是如果您考虑深度,则可以在几个小时内学习每个主题。 每个主题彼此独立。 您需要一次考虑一个主题,对其进行学习,实践并使用您选择的语言在其中实现算法。 这是开始学习机器学习的最佳方法。 一次练习一个主题,很快您将获得机器学习专家最终所需的宽度。 Good Luck! 祝好运! 翻译自: https://www.tutorialspoint.com/machine_learning/machine_learning_quick_guide.htm 机器学习指南 概率论 (Probability Theory)
优化问题 (Optimization Problem)
可视化 (Visualization)

机器学习-实施 (Machine Learning - Implementing)
语言选择 (Language Choice)
集成开发环境 (IDEs)
平台类 (Platforms)
机器学习-结论 (Machine Learning - Conclusion)