混合精度训练-Automatic Mixed Precision
目录
双/单/半精度浮点数
比较FP32&FP16
Automatic Mixed Precision(AMP)
AMP如何减少精度损失呢?
为每个权重保存一份FP32的副本
Loss Scaling
改进矩阵运算
为每个OP使用最佳精度
如何应用AMP
TensorFlow
PyTorch
MXNet
PaddlePaddle
双/单/半精度浮点数
以下简单对比双/单/半精度浮点数:

双精度浮点数:FP64(64bits=8bytes)

单精度浮点数:FP32 (32bits=4bytes)
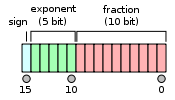
半精度浮点数:FP16 (16bits=4bytes)
可以看到,双/单/半精度浮点数表示的范围不同,因此存储它们所需要的硬件内存也不同了。
其中,一个FP16浮点数占用内存是FP32的一半,但是它所表示的范围也大大减少,因此,纯粹使用FP16进行模型训练,会带来严重的精度损失,甚至造成梯度underflow(下溢出)。
比较FP32&FP16
FP32的动态表示范围更大,在小数累积上有更高的精度;FP16的动态表示范围小,小数累加会丢失精度,但模型训练更快,且内存使用更高效。
某些OP要求有FP32的精度范围,比如:reductions, exponentiation.
对于V100来说,
| FP32 | FP16 with Tensor Cores |
| 1 x compute throughput | 8 x compute throughput |
| 1 x memory throughput | 2 x memory throughput |
| 1 x memory storage | 1/2 x memory storage |
FP16 enables Volta/Turing/Ampere Tensor Cores.也就是说,在Volta/Turing/Ampere上可以使用FP16 with tensor cores.
Automatic Mixed Precision(AMP)
以前深度学习模型都是使用FP32来进行模型训练(loss和梯度的乘加计算与更新),由于模型越来越大,参数越来越多,那么训练成本愈来愈高。
为了更好地利用GPU显存以及加速矩阵的乘法运算,AMP应运而生。
混合精度训练是在尽可能减少精度损失的情况下利用半精度浮点数加速训练。
AMP如何减少精度损失呢?
为每个权重保存一份FP32的副本
模型训练时,前向和反向传播过程中,使用FP16。也就是说训练时,将模型的权重从FP32转换成FP16,然后进行前向传播(FP16),计算得到loss(FP32),然后反向传播(FP16),计算得到梯度(FP16),然后转换成FP32,更新模型权重(FP32)。

用FP32保存权重是为了避免溢出:梯度太小时,FP16会变为0。
Loss Scaling
前向传播,得到FP32的loss后,将其放大n倍并以FP16来保存(相当于下图中将红线左边的小梯度右移,使得FP16能够尽可能还原其梯度大小),然后再进行反向传播。反向传播后,再将梯度数量级还原(即缩小n倍),更新模型网络中的权重时使用FP32。

改进矩阵运算
以GEMM和卷积为例。
对于V100来说,它的throughput是125 TFlops, 8倍于纯FP32运算;
对于A100来说,它的throughput是312 TFlops, 16倍于纯FP32运算;

为每个OP使用最佳精度
| FP16 | FP32 |
| GEMMs+Conv 可使用Tensor Cores | weights更新(accumulation) |
| 大多数pointwise OP(add, multiply):1/2 内存,2倍吞吐 | Loss functions |
| Relu | softmax, norms, etc. |
如何应用AMP
这里有NVIDIA的官方文档在以下framework中应用AMP训练模型:https://developer.nvidia.com/automatic-mixed-precision。
TensorFlow
opt = tf.train.experimental.enable_mixed_precision_graph_rewrite(opt)PyTorch
scaler = GradScaler()
with autocast():
output = model(input)
loss = loss_fn(output, target)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()MXNet
amp.init()
amp.init_trainer(trainer)
with amp.scale_loss(loss, trainer) as scaled_loss:
autograd.backward(scaled_loss)PaddlePaddle
sgd = SGDOptimizer()
mp_sgd = fluid.contrib.mixed_precision.decorator.decorate(sgd)
mp_sgd.minimize(loss)
参考资料
https://fyubang.com/2019/08/26/fp16/
https://developer.nvidia.com/automatic-mixed-precision
http://www.cs.toronto.edu/ecosystem/documents/AMP-Tutorial.pdf
https://zhuanlan.zhihu.com/p/84219777