LSTM+attention代码原理详解
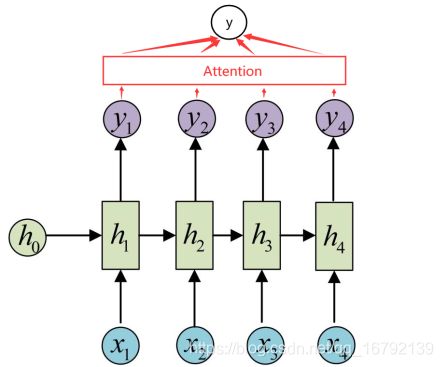
本文将LSTM+attention用于时间序列预测
class lstm(torch.nn.Module):
def __init__(self, output_size, hidden_size, embed_dim, sequence_length):
super(lstm, self).__init__()
self.output_size = output_size
self.hidden_size = hidden_size
#对应特征维度
self.embed_dim = embed_dim
self.dropout = 0.8
#对应时间步长
self.sequence_length = sequence_length
#1层lstm
self.layer_size = 1
self.lstm = nn.LSTM(self.embed_dim,
self.hidden_size,
self.layer_size,
dropout=self.dropout,
)
self.layer_size = self.layer_size
self.attention_size = 30
#(4,30)
self.w_omega = Variable(torch.zeros(self.hidden_size * self.layer_size, self.attention_size))
#(30)
self.u_omega = Variable(torch.zeros(self.attention_size))
#将隐层输入全连接
self.label = nn.Linear(hidden_size * self.layer_size, output_size)
LSTM输入输出说明
1. 输入数据包括input,(h_0,c_0):
input就是shape==(seq_length,batch_size,input_size)的张量
h_0的shape==(num_layers×num_directions,batch,hidden_size)的张量
,它包含了在当前这个batch_size中每个句子的初始隐藏状态,num_layers就是LSTM的层数,如果bidirectional=True,num_directions=2,否则就是1,表示只有一个方向,
c_0和h_0的形状相同,它包含的是在当前这个batch_size中的每个句子的初始细胞状态。
==h_0,c_0如果不提供,那么默认是0==
2. 输出数据包括output,(h_n,c_n):
output的shape==(seq_length,batch_size,num_directions×hidden_size),
它包含的LSTM的最后一层的输出特征(h_t),t是batch_size中每个句子的长度.
h_n.shape==(num_directions × num_layers,batch,hidden_size)
c_n.shape==h_n.shape
h_n包含的是句子的最后一个单词的隐藏状态,c_n包含的是句子的最后一个单词的细胞状态,所以它们都与句子的长度seq_length无关。
output[-1]与h_n是相等的,因为output[-1]包含的正是batch_size个句子中每一个句子的最后一个单词的隐藏状态,注意LSTM中的隐藏状态其实就是输出,cell
state细胞状态才是LSTM中一直隐藏的,记录着信息
def attention_net(self, lstm_output):
#print(lstm_output.size()) = (squence_length, batch_size, hidden_size*layer_size)
output_reshape = torch.Tensor.reshape(lstm_output, [-1, self.hidden_size*self.layer_size])
#print(output_reshape.size()) = (squence_length * batch_size, hidden_size*layer_size)
#tanh(H)
attn_tanh = torch.tanh(torch.mm(output_reshape, self.w_omega))
#print(attn_tanh.size()) = (squence_length * batch_size, attention_size)
#张量相乘
attn_hidden_layer = torch.mm(attn_tanh, torch.Tensor.reshape(self.u_omega, [-1, 1]))
#print(attn_hidden_layer.size()) = (squence_length * batch_size, 1)
exps = torch.Tensor.reshape(torch.exp(attn_hidden_layer), [-1, self.sequence_length])
#print(exps.size()) = (batch_size, squence_length)
alphas = exps / torch.Tensor.reshape(torch.sum(exps, 1), [-1, 1])
#print(alphas.size()) = (batch_size, squence_length)
alphas_reshape = torch.Tensor.reshape(alphas, [-1, self.sequence_length, 1])
#print(alphas_reshape.size()) = (batch_size, squence_length, 1)
state = lstm_output.permute(1, 0, 2)
#print(state.size()) = (batch_size, squence_length, hidden_size*layer_size)
attn_output = torch.sum(state * alphas_reshape, 1)
#print(attn_output.size()) = (batch_size, hidden_size*layer_size)
return attn_output
def forward(self, input):
# input = self.lookup_table(input_sentences)
input = input.permute(1, 0, 2)
# print('input.size():',input.size())
s,b,f=input.size()
h_0 = Variable(torch.zeros(self.layer_size, b, self.hidden_size))
c_0 = Variable(torch.zeros(self.layer_size, b, self.hidden_size))
print('input.size(),h_0.size(),c_0.size()',input.size(),h_0.size(),c_0.size())
lstm_output, (final_hidden_state, final_cell_state) = self.lstm(input, (h_0, c_0))
attn_output = self.attention_net(lstm_output)
logits = self.label(attn_output)
return logits
在计算attention时主要分为三步:
第一步是将query和每个key进行相似度计算得到权重,常用的相似度函数有点积,拼接,感知机等;
第二步一般是使用一个softmax函数对这些权重进行归一化;
最后将权重和相应的键值value进行加权求和得到最后的attention。