mmsegmentation自定义数据集
目录
1.mmsegmentation之model
2.mmsegformer之datasets
2.1 data config
2.2 data class
2.3 total config
3.运行
1.mmsegmentation之model
mmsegmentation中有很多已经发布的模型供我们使用,这些模型可以在configs/models中找到。关于config的描述也在之前的博文中进行了描述。
2.mmsegformer之datasets
这里主要是讲述如何定义自己的数据集。主要包含三个文件①data config ② data class ③ total config。其中config文件就是Total config(顶层设置文件),也是train.py文件直接调用的config文件;Dataset Class文件是用来定义数据集的类别数和标签名称的;Dataset Config文件则是用来定义数据集目录、数据集信息(例如图片大小)、数据增强操作以及pipeline的。
2.1 data config
Dataset Config文件在 configs/__base__/ datasets目录下,需要自己新建一个xxx.py文件。我们以group_voc2012.py,我的数据格式是VOC的格式;
具体内容如下
# dataset settings
dataset_type = 'GroupVOCDataset'
data_root = '/data/dataset_VOC/VOC2012'
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
crop_size = (512, 512)
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations'),
dict(type='Resize', img_scale=(2048, 512), ratio_range=(0.5, 2.0)),
dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),
dict(type='RandomFlip', prob=0.5),
dict(type='PhotoMetricDistortion'),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size=crop_size, pad_val=0, seg_pad_val=255),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_semantic_seg']),
]
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(2048, 512),
# img_ratios=[0.5, 0.75, 1.0, 1.25, 1.5, 1.75],
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(type='Normalize', **img_norm_cfg),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img']),
])
]
data = dict(
samples_per_gpu=4,
workers_per_gpu=4,
train=dict(
type=dataset_type,
data_root=data_root,
img_dir='/datadataset_VOC/VOC2012/JPEGImages',
ann_dir='/data/dataset_VOC/VOC2012/SegmentationClass',
split='/data/dataset_VOC/VOC2012/ImageSets/Segmentation/train.txt',
pipeline=train_pipeline),
val=dict(
type=dataset_type,
data_root=data_root,
img_dir='/data/dataset_VOC/VOC2012/JPEGImages',
ann_dir='/data/dataset_VOC/VOC2012/SegmentationClass',
split='/data//dataset_VOC/VOC2012/ImageSets/Segmentation/val.txt',
pipeline=test_pipeline),
test=dict(
type=dataset_type,
data_root=data_root,
img_dir='/data/dataset_VOC/VOC2012/JPEGImages',
ann_dir='/data/dataset_VOC/VOC2012/SegmentationClass',
split='/data/dataset_VOC/VOC2012/ImageSets/Segmentation/val.txt',
pipeline=test_pipeline))
需要做以下修改:
dataset_type:更改为自己数据集的类型,可以自己命名,也可以不动;
data_root:更改为自己数据集的路径;
img_dir:更改为自己数据集图片路径;
ann_dir:更改为自己数据集标签的路径;
split:更改为自己的train.txt路径。
其他参数的含义:
img_norm_cfg:数据集的方差与均差
crop_size:数据增强时裁剪的大小
image_scale:原始图像大小
sample_per_gpu: batch size
works_per_gpu: dataloader的线程数目,一般设置为2,4,8
photoMetricDistortion:数据增强操作。分贝是亮度、对比度、饱和度喝色调。
2.2 data class
Dataset Class文件存放在 mmseg/datasets/ 目录下,需要自己新建一个xxx.py文件。我们以groupvoc.py,我的数据格式是VOC的格式;
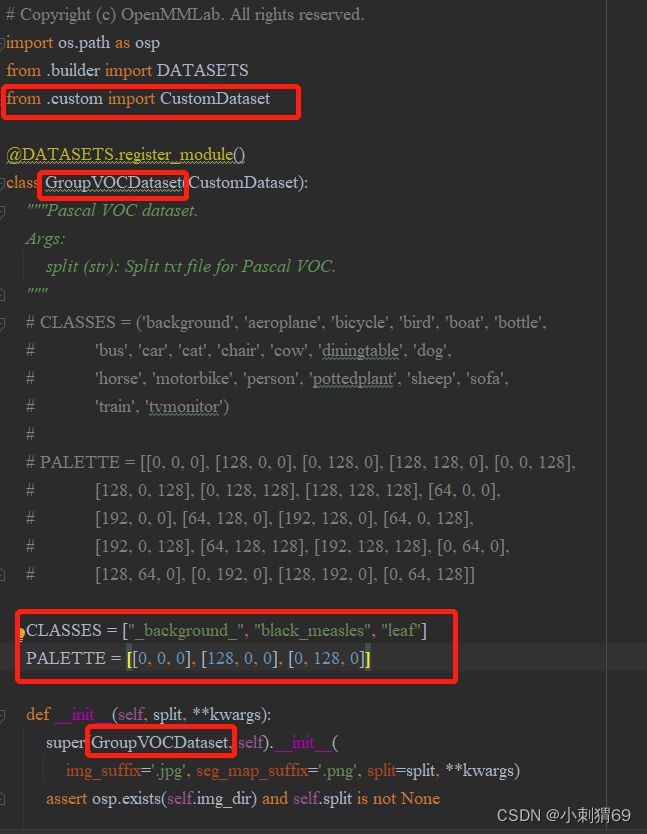
config文件实际上是继承该目录下custom.py当中的CustomDataset父类。
修改的参数如下:
1.class GroupVOCDataset(类名,数据格式):这个类名可以更改为自己容易识别的,且与configs/__base__/ datasets/group_voc2012.py中dataset_type的名称一致;
2.CLASS:类型标签,更改为自己的类别种类标签;
3.PALETTE:色盘,更改为自己想要的的色盘颜色;色盘个数与标签个数一致;
4.super (GroupVOCDateset.self):调用父类的时候更改为自己的数据格式,与类名一致。
设置好之后,还需要设置一下该目录下的__init__文件:
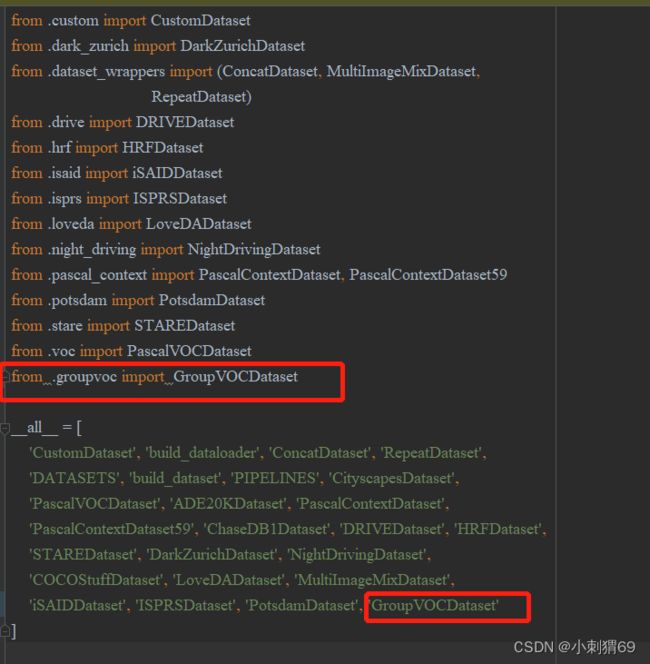
修改部分如下:
import的时候要把自己的Dataset加载进来
__all__数组里面需要加入自己的Dataset类名称
2.3 total config
文件在 configs/目录下,以segformer为例,打开segformer/segformer_mit-b0_512x512_160k_ade20k.py的文件。
注意:
记住一件事,对于mmsegmentation来说,如果你向快速使用的话。config文件几乎是你唯一需要改动的东西。mmseg的模型使用,训练配置,数据地址都是靠config指明的。在mmseg的官网中,有关config的资料很清晰,但是细节并不到位。config是有继承关系的,根文件就是_base_中的一个个文件。虽如此,但我仍然不建议初次使用的小白按照官网提供简略写法。在mmsegmentation的configs下,存放了各式各样的模型的配置文件,这些配置文件大多数都是针对的大型开源数据集。我们需要改的不是网络结构,主要是你的数据集地址,你定义的类别数,以及必要的训练设置。
继承base数据集的文件,model=dict(修改自己修改的参数),例子是修改了预训练权重位置。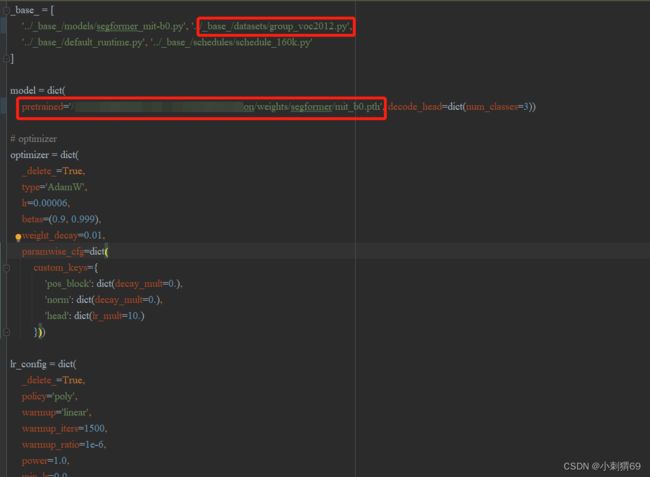
3.运行
运行文件在tools/train.py中,
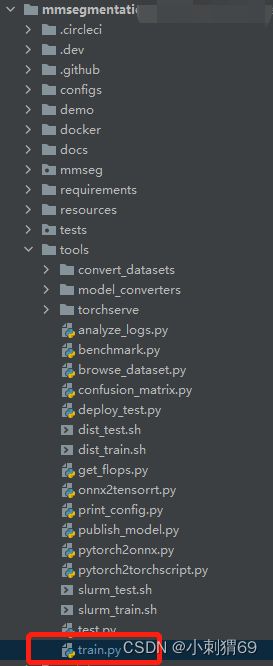
修改的位置如下:
--config:模型的配置文件路径;
--work-dir:工作日志的保存路径;全部都更改自己想要的路径。
然后运行此文件就可以了。如果出错可能是环境配置的问题。