YOLOv5代码阅读笔记 - 模型解读
YOLOv5代码阅读笔记 - 模型解读
模型结构概述
yolov5 的几个不同大小的模型结构存储在对应的 .yaml 文件中,这些模型结构的大小由文件名称最后的英文表示,从小到大分别为 s, m, l, x。
这几个模型都分别包含了以下几个重要参数:
- nc: 目标类别的个数
- depth_multiple:控制模型中 C3 模块的串联个数的系数
- width_multiple:控制模型中通道大小的系数
- anchors:锚框的尺寸
- backbone:模型 backbone 部分的结构
- head:模型 head 部分的结构
其中每个结构大小的模型只在 depth_multiple 和 width_multiple 上有区别,这两个参数控制了模型的大小或者复杂程度。
模型解读
以下为 yolov5l.yaml 中的内容与解读。
# parameters
nc: 80 # coco 数据集中包含 80 个类别所以此处为 80
depth_multiple: 1 # yolov5l 模型中的系数为 1
width_multiple: 1
# anchors 此处为预先设置的三组不同尺寸的锚框
# 经过越多倍数的下采样,感受野也越大,也越容易识别尺寸较大的物体
# 所以高倍数下采样时的锚框相对更大
anchors:
- [10,13, 16,30, 33,23] # 8倍下采样的锚框
- [30,61, 62,45, 59,119] # 16倍下采样的锚框
- [116,90, 156,198, 373,326] # 32倍下采样的锚框
# YOLOv5 backbone
backbone:
# 参数分别表示
# 第0个:传入的特征源于第几次 -1 表示为上一层
# 第1个:该模块重复使用几次
# 当模块为 C3 或 BottleneckCSP 时,作为内部的 Bottleneck 数量传入
# 第2个:模块的类名
# 第3个:生成模块所用的参数 其中通道数由 width_multiple 系数决定
[[-1, 1, Focus, [64, 3]], # 第一次下采样 2倍
[-1, 1, Conv, [128, 3, 2]], # 第二次下采样 4倍
[-1, 3, C3, [128]], # C3 模块内部重复 3×depth_multiple 次
[-1, 1, Conv, [256, 3, 2]], # 第三次下采样 8倍
[-1, 9, C3, [256]], # 第 4 层
[-1, 1, Conv, [512, 3, 2]], # 第四次下采样 16倍
[-1, 9, C3, [512]], # 第 6 层
[-1, 1, Conv, [1024, 3, 2]], # 第五次下采样 32倍
[-1, 1, SPP, [1024, [5, 9, 13]]],
[-1, 3, C3, [1024, False]], # backbone 结束 该层位第 9 层
]
# YOLOv5 head
head:
[[-1, 1, Conv, [512, 1, 1]], # 第 10 层
[-1, 1, nn.Upsample, [None, 2, 'nearest']], # 上采样
[[-1, 6], 1, Concat, [1]], # 与第 6 层拼接
[-1, 3, C3, [512, False]],
[-1, 1, Conv, [256, 1, 1]], # 第 14 层
[-1, 1, nn.Upsample, [None, 2, 'nearest']], # 再次上采样
[[-1, 4], 1, Concat, [1]], # 与第 4 层拼接
[-1, 3, C3, [256, False]], # 第 17 层
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # 与第 14 层拼接
[-1, 3, C3, [512, False]], # 第 20 层
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # 与第 10 层拼接
[-1, 3, C3, [1024, False]], # 第 23 层
[[17, 20, 23], 1, Detect, [nc, anchors]], # 由第 17、20、23 层输入后输出
]
图片描述

自定义模块代码
函数 autopad
def autopad(k, p=None): # kernel, padding
# Pad to 'same'
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
return p
该函数用于自动计算 pad 值,传入 kernel 的尺寸与 pad 值 p,kernel 尺寸可以是一个一个整数也可以是一个可迭代对象。若已经设定了 pad 值,则直接按原值返回。
类 Conv
class Conv(nn.Module):
# Standard convolution
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super(Conv, self).__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def fuseforward(self, x):
return self.act(self.conv(x))
该类定义了一个标准的卷积层,其中包含一个 Conv2d ,一个 BN 层,以及一个 SiLU (Swish) 激活函数。

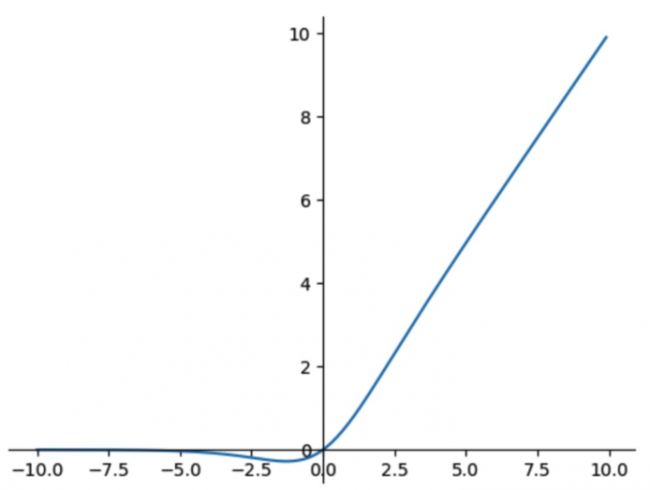
其中,SiLU激活函数为: f ( x ) = x ⋅ σ ( x ) f(x) = x \cdot \sigma(x) f(x)=x⋅σ(x)
导数为: f ′ ( x ) = f ( x ) + σ ( x ) ( 1 − f ( x ) ) f'(x) = f(x)+ \sigma(x)(1-f(x)) f′(x)=f(x)+σ(x)(1−f(x))
图像如下:
类 Bottleneck
class Bottleneck(nn.Module):
# Standard bottleneck
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansion
super(Bottleneck, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_, c2, 3, 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
标准 Bottleneck 模块,先将 channel 数减小再扩大(默认减小到一半),若需要 shortcut 且输入输出的 channel 数量相等,则将输出和输出作为 shortcut 与输出进行相加。

类 C3
class C3(nn.Module):
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super(C3, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1) # act=FReLU(c2)
self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])
# self.m = nn.Sequential(*[CrossConv(c_, c_, 3, 1, g, 1.0, shortcut) for _ in range(n)])
def forward(self, x):
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1))
C3 模块,包含三个标准卷积层和 X 个 Bottleneck 模块。C2 分为两条线路,线路一中先用一个 Conv 层降低 channel 数量,再经过多个 Bottleneck 模块,Bottleneck 的数量由定义模型的 .yaml 文件中该层的第二个参数和 depth_multiple 决定。路线二中只经过一个 Conv 层降低 channel 数量。

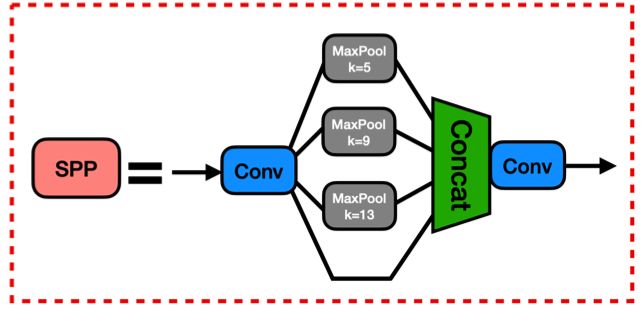
类 SPP
class SPP(nn.Module):
# Spatial pyramid pooling layer used in YOLOv3-SPP
def __init__(self, c1, c2, k=(5, 9, 13)):
super(SPP, self).__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * (len(k) + 1), c2, 1, 1)
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])
def forward(self, x):
x = self.cv1(x)
return self.cv2(torch.cat([x] + [m(x) for m in self.m], 1))
SPP 模块,包含两个标准卷积模块和 X 个最大池化层。先使用一个标准卷积模块将 channel 数减少,然后将其通过 X 个不同尺度最大池化层后,将其他们与未池化的数据 Concat 到一起,再经过一个标准卷积模块将 channel 数还原到输出值 c2。
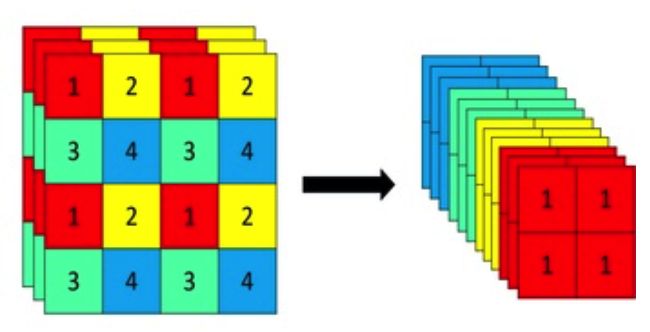
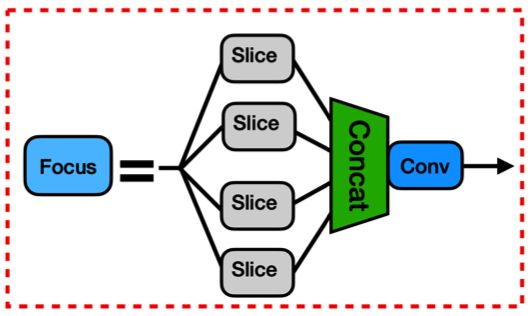
类 Focus
class Focus(nn.Module):
# Focus wh information into c-space
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super(Focus, self).__init__()
self.conv = Conv(c1 * 4, c2, k, s, p, g, act)
# self.contract = Contract(gain=2)
def forward(self, x): # x(b,c,w,h) -> y(b,4c,w/2,h/2)
return self.conv(torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1))
# return self.conv(self.contract(x))
- Detect 放在 Model 类中详解
注意的点
yolo.py 文件中有将 .yaml 转换为模型的函数 parse_model,其中有代码:
# 此处 d 为读取 .yaml 文件得到的的字典
anchors, nc, gd, gw = d['anchors'], d['nc'], d['depth_multiple'], d['width_multiple']
......
# 读取 backbond 和 head 中的每一条信息,其中 n 对应该模块重复几次
for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']):
m = eval(m) if isinstance(m, str) else m # 将字符串转换为类
......
# 若重复次数大于 1 次则需要乘以 depth_multiple 系数才得到最后重复次数
n = max(round(n * gd), 1) if n > 1 else n
if m in [Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, DWConv, MixConv2d, Focus, CrossConv, BottleneckCSP,
C3]:
......
# 当前模块为 C3 或 BottleneckCSP 时,将 n 加入参数中,并将 n 置 1
if m in [BottleneckCSP, C3]:
args.insert(2, n) # number of repeats
n = 1
......
# 若 n>1 则重复添加该模块 n 次,否则添加该模块 1 次。
m_ = nn.Sequential(*[m(*args) for _ in range(n)]) if n > 1 else m(*args)
由此可看出,在 .yaml 文件中有例如 [-1, 3, C3, [128]] 的配置时,并不会重复添加 C3 模块 max(round(n * gd), 1) 次,而是将该值作为参数传入到其初始化方法中,作为参数 n 的值。
而当非 C3 和 BottleneckCSP 模块时,将会重复添加 max(round(n * gd), 1) 次该同一模块。