Pytorch自动混合精度(AMP)训练
相关问题:解决pytorch半精度amp训练nan问题 - 知乎
pytorch模型训练之fp16、apm、多GPU模型、梯度检查点(gradient checkpointing)显存优化等 - 知乎
pytorch从1.6版本开始,已经内置了torch.cuda.amp,采用自动混合精度训练就不需要加载第三方NVIDIA的apex库了。AMP -- (automatic mixed-precision training)
一 什么是自动混合精度训练(AMP)
默认情况下,大多数深度学习框架都采用32位浮点算法进行训练。2017年,NVIDIA研究了一种用于混合精度训练的方法,该方法在训练网络时将单精度(FP32)与半精度(FP16)结合在一起,并使用相同的超参数实现了与FP32几乎相同的精度。
1.1、FP16理论基础:
在介绍AMP之前,先来理解下FP16与FP32,FP16也即半精度是一种计算机使用的二进制浮点数据类型,使用2字节存储。而FLOAT就是FP32。
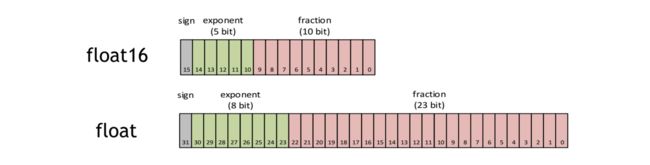
在上图可以看到,与单精度float(32bit,4个字节)相比,半进度float16仅有16bit,2个字节组成。天然的存储空间是float的一半。 其中,float16的组成分为了三个部分:
- 最高位表示符号位,sign 位表示正负
- 有5位表示exponent位, exponent 位表示指数
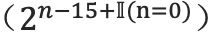
- 有10位表示fraction位, fraction 位表示的是分数
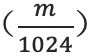
根据 wikipedia 上的介绍,我总结下float16的这几个位置的使用,以及如何从其bitmap计算出表示的数字:
 结合上面的讲解,那么就可以顺利的理解下面的这些半精度例子:
结合上面的讲解,那么就可以顺利的理解下面的这些半精度例子:
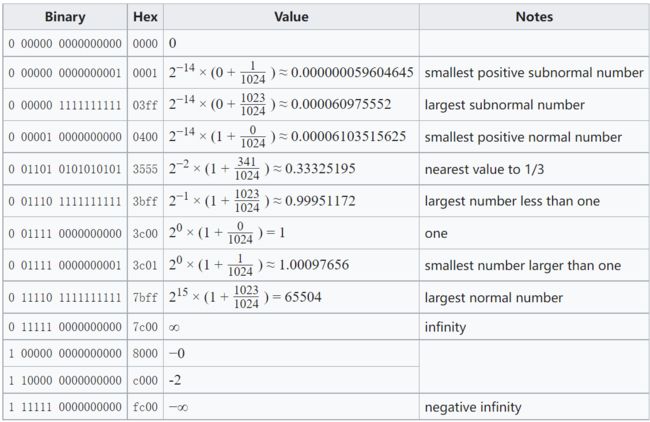 FP16的表示范例
FP16的表示范例
总结:
FP16值动态区间![]()
FP32值动态区间:![]()
float16 最大范围是 [-65504,66504],float16 能表示的精度范围是![]() ,超过这个数值的数字会被直接置0;
,超过这个数值的数字会被直接置0;
Tensor
神经网络框架的计算核心是Tensor,也就是那个从scaler -> array -> matrix -> tensor 维度一路丰富过来的tensor。在PyTorch中,我们可以这样创建一个Tensor:
>>import torch
>>tensor1=torch.zeros(30,20)
>>tensor1.type()
'torch.FloatTensor'
>>tensor2=torch.Tensor([1,2])
>>tensor2.type()
'torch.FlatTensor'torch.FloatTensor(32bit floating point)
torch.DoubleTensor(64bit floating point)
torch.HalfTensor(16bit floating piont1)
torch.BFloat16Tensor(16bit floating piont2)
torch.ByteTensor(8bit integer(unsigned)
torch.CharTensor(8bit integer(signed))
torch.ShortTensor(16bit integer(signed))
torch.IntTensor(32bit integer(signed))
torch.LongTensor(64bit integer(signed))
torch.BoolTensor(Boolean)默认Tensor是32bit floating point,这就是32位浮点型精度的tensor。
AMP(自动混合精度)的关键词有两个:自动,混合精度。这是由PyTorch 1.6的torch.cuda.amp模块带来的:
自动:Tensor的dtype类型会自动变化,框架按需自动调整tensor的dtype,当然有些地方还需手动干预。
混合精度:采用不止一种精度的Tensor,torch.FloatTensor和torch.HalfTensor
pytorch1.6的新包:torch.cuda.amp,torch.cuda.amp 的名字意味着这个功能只能在cuda上使用,是NVIDIA开发人员贡献到pytorch里的。只有支持tensor core的CUDA硬件才能享受到AMP带来的优势(比如2080ti显卡)。
Tensor core是一种矩阵乘累加的计算单元,每个tensor core时针执行64个浮点混合精度操作(FP16矩阵相乘和FP32累加)。英伟达宣称使用Tensor Core进行矩阵运算可以轻易的提速,同时降低一半的显存访问和存储。
因此,在PyTorch中,当我们提到自动混合精度训练,我们说的就是在NVIDIA的支持Tensor core的CUDA设备上使用torch.cuda.amp.autocast (以及torch.cuda.amp.GradScaler)来进行训练。咦?为什么还要有torch.cuda.amp.GradScaler?后面解释
1.2 为什么要使用AMP?
前面已介绍,AMP其实就是Float32与Float16的混合,那为什么不单独使用Float32或Float16,而是两种类型混合呢?原因是:在某些情况下Float32有优势,而在另外一些情况下Float16有优势。而相比于之前的默认的torch.FloatTensor,torch.HalfTensor的劣势不可忽视。这里先介绍下FP16优劣势:
torch.HalfTensor的优势就是存储小、计算快、更好的利用CUDA设备的Tensor Core。因此训练的时候可以减少显存的占用(可以增加batchsize了),同时训练速度更快;
优势有三个:
1、减少显存占用:现在模型越来越大,当你使用 Bert 这一类的预训练模型时,往往模型及模型计算就占去显存的大半,当想要使用更大的 Batch Size 的时候会显得捉襟见肘。由于 FP16 的内存占用只有 FP32 的一半,自然地就可以帮助训练过程节省一半的显存空间,可以增加batchsize了。
2、加快训练和推断的计算:与普通的空间时间 Trade-off 的加速方法不同,FP16 除了能节约内存,还能同时节省模型的训练时间。在大部分的测试中,基于 FP16 的加速方法能够给模型训练能带来多一倍的加速体验。
3、张量核心的普及(NVIDIA Tensor Core),低精度计算是未来深度学习的一个重要趋势。
torch.HalfTensor的劣势就是:溢出错误:数值范围小(更容易Overflow / Underflow)、舍入误差(Rounding Error,导致一些微小的梯度信息达不到16bit精度的最低分辨率,从而丢失)。
1、溢出错误:由于FP16的动态范围比FP32位的狭窄很多,因此,在计算过程中很容易出现上溢出(Overflow)和下溢出(Underflow),溢出之后就会出现"NaN"的问题。在深度学习中,由于激活函数的梯度往往要比权重梯度小,更易出现下溢出的情况。在训练后期,例如激活函数的梯度会非常小, 甚至在梯度乘以学习率后,值会更加小。
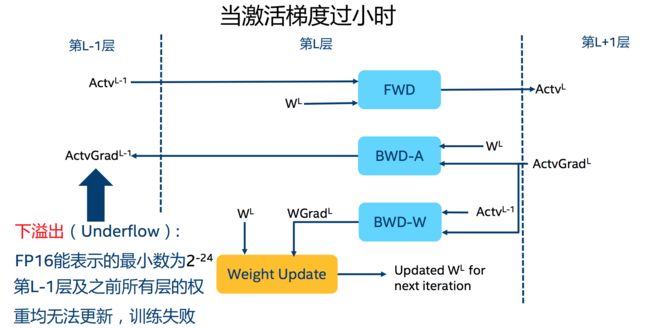 下溢出
下溢出
2、舍入误差
舍入误差指的是当梯度过小时,小于当前区间内的最小间隔时,该次梯度更新可能会失败。
- fp64, 又名双精度或"double" ,最大舍入误差 ~ 2^-52
- fp32, 又名单精度或"single",最大舍入误差 ~ 2 ^-23
- fp16, 又名半精度或"half" ,最大舍入误差 ~ 2 ^-10
注意,浮点数越小,引起的舍入误差就越大。 对“足够小“的浮点数执行的任何操作都会将该值四舍五入到零! 这就是所谓的underflowing,这是一个问题,因为在反向传播中很多甚至大多数梯度更新值都非常小,但不为零。 在反向传播中舍入误差累积可以把这些数字变成0或者 nans; 这会导致不准确的梯度更新或者梯度更新可能会失败,影响你的网络收敛。

由于更新的梯度值超出了FP16能够表示的最小值的范围,因此该数值将会被舍弃,这个权重将不进行更新。这个例子非常直观的阐述了『舍入误差』这个说法。而至于上面提到的,FP16的最小间隔是一个比较玄乎的事,在wikepedia的引用上有这么一张图: 描述了 fp16 各个区间的最小gap。

1.3 解决问题的办法:混合精度训练+动态损失放大
1、混合精度训练
在某些模型中,fp16矩阵乘法的过程中,需要利用 fp32 来进行矩阵乘法中间的累加(accumulated),然后再将 fp32 的值转化为 fp16 进行存储。 换句不太严谨的话来说,也就是在内存中用FP16做储存和乘法从而加速计算,而用FP32做累加避免舍入误差。混合精度训练的策略有效地缓解了舍入误差的问题。
在这里也就引出了,为什么网上大家都说,只有 Nvidia Volta 结构的 拥有 TensorCore 的CPU(例如V100),才能利用 fp16 混合精度来进行加速。 那是因为 TensorCore 能够保证 fp16 的矩阵相乘,利用 fp16 or fp32 来进行累加。在累加阶段能够使用 FP32 大幅减少混合精度训练的精度损失。而其他的GPU 只能支持 fp16 的 multiply-add operation。这里直接贴出原文句子:
Whereas previous GPUs supported only FP16 multiply-add operation, NVIDIA Volta GPUs introduce Tensor Cores that multiply FP16 input matrices andaccumulate products into either FP16 or FP32 outputs
什么时候用torch.FloatTensor,什么时候用torch.HalfTensor呢?这是由pytorch框架决定的,在pytorch1.6的AMP上下文中,以下操作中Tensor会被自动转化为半精度浮点型torch.HalfTensor:
__matmul__
addbmm
addmm
addmv
addr
baddbmm
bmm
chain_matmul
conv1d
conv2d
conv3d
conv_transpose1d
conv_transpose2d
conv_transpose3d
linear
matmul
mm
mv
preluFP32 权重备份
这种方法主要是用于解决舍入误差的问题。其主要思路,可以概括为:weights, activations, gradients 等数据在训练中都利用FP16来存储,同时拷贝一份FP32的weights,用于更新。 在这里,我直接贴一张论文[1]的图片来阐述:
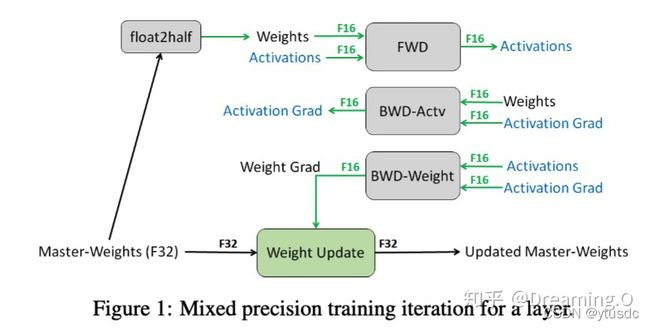
可以看到,其他所有值(weights,activations, gradients)均使用 fp16 来存储,而唯独权重weights需要用 fp32 的格式额外备份一次。 这主要是因为,在更新权重的时候,往往公式: 权重 = 旧权重 + lr * 梯度,而在深度模型中,lr * 梯度 这个值往往是非常小的,如果利用 fp16 来进行相加的话, 则很可能会出现上面所说的『舍入误差』的这个问题,导致更新无效。因此上图中,通过将weights拷贝成 fp32 格式,并且确保整个更新(update)过程是在 fp32 格式下进行的。
看到这里,可能有人提出这种 fp32 拷贝weight的方式,那岂不是使得内存占用反而更高了呢?是的, fp32 额外拷贝一份 weight 的确新增加了训练时候存储的占用。 但是实际上,在训练过程中,内存中占据大部分的基本都是 activations 的值。特别是在batchsize 很大的情况下, activations 更是特别占据空间。 保存 activiations 主要是为了在 back-propogation 的时候进行计算。因此,只要 activation 的值基本都是使用 fp16 来进行存储的话,则最终模型与 fp32 相比起来, 内存占用也基本能够减半。
2、损失放大(Loss scaling)
即使了混合精度训练,还是存在无法收敛的情况,原因是激活梯度的值太小,造成了下溢出(Underflow)。Loss Scale 主要是为了解决 fp16 underflow 的问题。刚才提到,训练到了后期,梯度(特别是激活函数平滑段的梯度)会特别小,如果用 fp16 来表示,则这些梯度都会变成0,因此导致fp16 表示容易产生 underflow 现象。
为了解决梯度过小的问题,论文中对计算出来的loss值进行scale,由于链式法则的存在,loss上的scale会作用,同时也会作用在梯度上。这样比起对每个梯度进行scale更加划算。 scaled 过后的梯度,就会平移到 fp16 有效的展示范围内。
这样,scaled-gradient 就可以一直使用 fp16 进行存储了。只有在进行更新的时候,才会将 scaled-gradient 转化为 fp32,同时将scale抹去。论文指出, scale 并非对于所有网络而言都是必须的。而scale的取值为也会特别大,论文给出在 8 - 32k 之间皆可。
Pytorch可以通过使用torch.cuda.amp.GradScaler,通过放大loss的值来防止梯度的underflow(只在BP时传递梯度信息使用,真正更新权重时还是要把放大的梯度再unscale回去)
损失放大的思路是:
- 反向传播前,将损失变化手动增大2^k倍,因此反向传播时得到的中间变量(激活函数梯度)则不会溢出;
- 反向传播后,将权重梯度缩小2^k倍,恢复正常值。
二 如何在PyTorch中使用自动混合精度?
pytorch1.6及以上版本自带的torch.cuda.amp,有两个接口:autocast和Gradscaler
pytorch1.5之前使用的NVIDIA的三方包apex.amp,pytorch1.5具体参考:Pytorch自动混合精度(AMP)介绍与使用 - jimchen1218 - 博客园
2.1 autocast
导入pytorch中模块torch.cuda.amp的类autocast
可以使用autocast的context managers语义(如上),也可以使用decorators语义。当进入autocast上下文后,在这之后的cuda ops会把tensor的数据类型转换为半精度浮点型,从而在不损失训练精度的情况下加快运算。而不需要手动调用.half(),框架会自动完成转换。
不过,autocast上下文只能包含网络的前向过程(包括loss的计算),不能包含反向传播,因为BP的op会使用和前向op相同的类型。
当然,有时在autocast中的代码会报错:
Traceback (most recent call last):
......
File "/opt/conda/lib/python3.7/site-packages/torch/nn/modules/module.py", line 722, in _call_impl
result = self.forward(*input, **kwargs)
......
RuntimeError: expected scalar type float but found c10::Half对于RuntimeError:expected scaler type float but found c10:Half,应该是个bug,可在tensor上手动调用.float()来让type匹配。
2.2 GradScaler
使用前,需要在训练最开始前实例化一个GradScaler对象,例程如下:
from torch.cuda.amp import autocast, GradScaler
# 创建model,默认是torch.FloatTensor
model = Net().cuda()
optimizer = optim.SGD(model.parameters(), ...)
# 在训练最开始之前实例化一个GradScaler对象
scaler = GradScaler()
for epoch in epochs:
for input, target in data:
optimizer.zero_grad()
# 前向过程(model + loss)开启 autocast
with autocast():
output = model(input)
loss = loss_fn(output, target)
# Scales loss. 为了梯度放大.
scaler.scale(loss).backward()
# scaler.step() 首先把梯度的值unscale回来.
# 如果梯度的值不是 infs 或者 NaNs, 那么调用optimizer.step()来更新权重,
# 否则,忽略step调用,从而保证权重不更新(不被破坏)
scaler.step(optimizer)
# 准备着,查看是否要增大scaler
scaler.update()scaler的大小在每次迭代中动态估计,为了尽可能减少梯度underflow,scaler应该更大;但是如果太大的话,半精度浮点型又容易overflow(变成inf或NaN)。所以,动态估计原理就是在不出现inf或NaN梯度的情况下,尽可能的增大scaler值。在每次scaler.step(optimizer)中,都会检查是否有inf或NaN的梯度出现:
1.如果出现inf或NaN,scaler.step(optimizer)会忽略此次权重更新(optimizer.step()),并将scaler的大小缩小(乘上backoff_factor);
2.如果没有出现inf或NaN,那么权重正常更新,并且当连续多次(growth_interval指定)没有出现inf或NaN,则scaler.update()会将scaler的大小增加(乘上growth_factor)。
参考文章:Pytorch自动混合精度(AMP)介绍与使用 - jimchen1218 - 博客园
训练提速60%!只需5行代码,PyTorch 1.6即将原生支持自动混合精度训练。 - 知乎
混合精度训练-Pytorch_WZZ18191171661的博客-CSDN博客_混合精度训练