yolov2 损失函数_深度学习计算机视觉之YOLO,YOLOv2和YOLOv3算法(超详细解析)
您只看一次(YOLO)是针对实时处理的对象检测系统。我们将在本文中介绍YOLO,YOLOv2和YOLOv3。这是YOLO官网提供各种模型的准确性和速度比较。

让我们从下面的测试图像开始
YOLO检测到的对象:
网格单元
为了便于讨论,我们裁剪了原始照片。YOLO将输入图像划分为S × S网格。每个网格单元仅预测一个对象。例如,下面的黄色网格单元试图预测其中心(蓝色点)落在网格单元内的“人”对象。

每个网格单元都预测固定数量的边界框。在此示例中,黄色网格单元格进行两个边界框预测(蓝色框)以定位人的位置。

但是,单对象规则限制了所检测对象的接近程度。为此,YOLO在对象近距离上确实有一些限制。对于下图,左下角有9个圣诞老人,但YOLO只能检测到5个。
对于每个网格单元:
它预测B个边界框,每个框都有一个框置信度得分
它只检测一个物体,而与盒子B的数量无关
它可以预测C个 条件类的概率(对于对象类的可能性,每个类一个)
为了评估PASCAL VOC,YOLO使用7×7网格(S×S),2个边界框(B)和20个类(C)
让我们来了解更多细节。每个边界框包含5个元素:(x,y,w,h)和一个框的置信度得分。置信度得分反映了框包含一个对象的可能性(objectness)以及边界框的准确性。我们通过图像的宽度和高度对边界框的宽度w和高度h进行归一化。x和y是对应
单元格的偏移量。因此,x,y,w和h都在0和1之间。每个像元都有20个条件类概率。该条件类概率是检测到的对象属于特定类别的概率(每个单元格每个类别一个概率)。因此,YOLO的预测形状为(S,S,B×5 + C)=(7,7,2×5 + 20)=(7,
7,30)。

YOLO的主要概念是建立一个CNN网络以预测(7,7,30)张量。它使用CNN网络将空间尺寸减小到7×7,每个位置都有1024个输出通道。YOLO使用两个完全连接的层执行线性回归,以进行7×7×2边界框预测(下图为中间图)。为了做出最终预测,我们将框置信度得分高(大于0.25)的那些作为我们的最终预测(右图)。

每个预测框的分类置信度得分计算如下:

它测量对分类和定位(对象所在的位置)的置信度。
我们可以轻松地将那些计分和概率项混合在一起。以下是数学定义:

网络设计
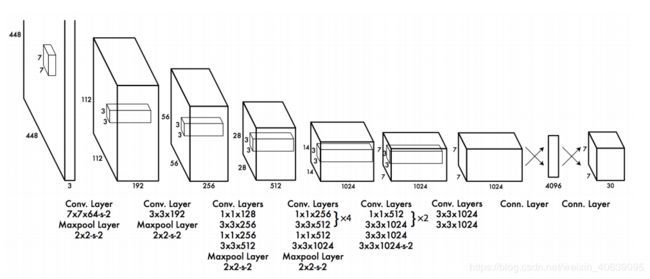
YOLO具有24个卷积层,其后是2个全连接层(FC)。一些卷积层可替代地使用1×1缩小层来减少特征图的深度。对于最后一个卷积层,它输出形状为(7,7,1024)的张量。然后将张量展平。使用2个完全连接的层作为线性回归的形式,它输出7×7×30个参数,然后重塑为(7、7、30),即每个位置2个边界框预测。更快但不太准确的YOLO版本称为Fast YOLO,它仅使用9个卷积图层,具有较浅的特征图。
损失函数
YOLO预测每个网格单元有多个边界框。为了计算真实正值的损失,我们只希望其中一个负责对象。为此,我们选择具有最高IoU(与工会的交集)和基本事实的人。这种策略导致边界框预测之间的专门化。每个预测都可以更好地预测某些大小和纵横
比。
YOLO使用预测值与基本事实之间的平方和误差来计算损失。损失函数包括:
在分类的损失
位置的损失(预测边界框与真实框之间的误差)
置信度的损失

非最大抑制
YOLO可以对同一物体进行重复检测。为了解决这个问题,YOLO应用了非最大抑制以较低的置信度删除重复项。非最大抑制会在mAP中增加2-3%。
这是可能的非最大抑制实现之一:
按置信度分数对预测进行排序。
从最高分开始,如果我们发现任何先前的预测与当前预测具有相同的类并且IoU>
0.5,则忽略任何当前预测。
重复步骤2,直到检查完所有预测。
YOLOv2
SSD是YOLO的强大竞争对手,它一方面证明了实时处理的更高准确性。与基于区域的探测器相比,YOLO的定位误差更高,召回率(衡量所有物体的定位效果)更低。YOLOv2是YOLO的第二个版本,目的是在提高准确性的同时又要使其更快。
第一方面:精度提升
批量标准化
在卷积层中添加批处理规范化。mAP提升了2%。
高分辨率分类器
YOLO培训分为两个阶段。首先,我们训练像VGG16这样的分类器网络。然后,我们用卷积层替换完全连接的层,并端到端对其进行重新训练以进行对象检测。YOLO用224×224图片,然后是448×448图片来训练分类器,以进行物体检测。YOLOv2从224×224张图片开始进行分类器训练,但随后以更少的时间间隔再次以448×448张图片重新分类器。这使检测器的训练更加轻松,并将mAP提高4%。
卷积与锚框
如YOLO论文所述,早期训练易受不稳定梯度的影响。最初,YOLO在边界框上进行任意猜测。这些猜测可能对某些对象有效,但对另一些对象则不利,从而导致陡峭的梯度变化。在早期的培训中,关于哪种形状要专门进行预测是相互斗争的。

由于我们只需要一个猜测就对了,因此,如果我们从现实生活中常见的各种猜测开始,初始训练将更加稳定。例如,我们可以创建5个具有以下形状的锚框。

代替预测5个任意边界框,我们预测到上面每个锚定框的偏移量。如果我们限制偏移值,则我们可以保持预测的多样性,并使每个预测着眼于特定形状。因此初始培训将更加稳定。
删除负责预测边界框的完全连接的层
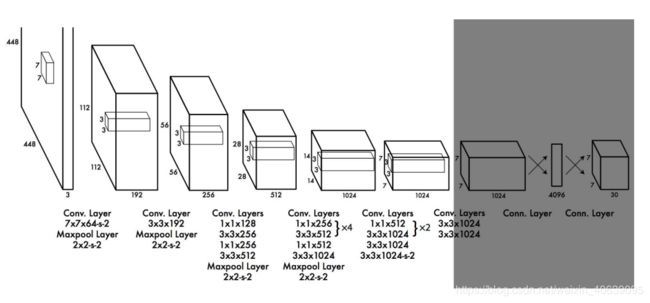
增加边界框为5个
每个预测都包括边界框的4个参数(x, y, w, h),1个框的置信度得分(客观性)和20个类概率。即5个带有25个参数的边界框:每个网格单元125个参数。与YOLO一样,客观性预测仍可预测地面实况和拟议方框的IOU。
将输入图像的大小从448×448更改为416×416。
这将创建一个奇数空间尺寸(7×7与8×8网格单元)。图片的中心通常被大物体占据。使用奇数网格单元,可以更确定对象所属的位置。
维度簇
在许多问题域中,边界框具有很强的模式。例如,在自动驾驶中,两个最常见的边界框将是距离不同的汽车和行人。为了确定对训练数据具有最佳覆盖范围的前K个边界框,我们在训练数据上运行K-均值聚类,以找到前K个聚类的质心。

细粒度的功能
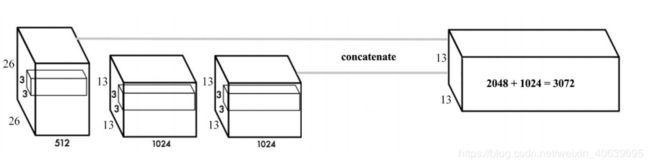
卷积层逐渐减小空间尺寸。随着相应分辨率的降低,很难检测到小物体。其他对象检测器(如SSD)可从功能图的不同层定位对象。因此,每一层都以不同的规模专长。YOLO采用了另一种称为直通的方法。它将26×26×512层重塑为13×13×2048。然后
与原始的13×13×1024输出层连接。现在,我们在新的13×13×3072层上应用卷积滤波器进行预测。
多尺度培训
删除完全连接的图层后,YOLO可以拍摄不同尺寸的图像。如果宽度和高度加倍,我们将只进行4倍的输出网格单元,因此进行4倍的预测。由于YOLO网络会将输入下采样32倍,因此我们只需要确保宽度和高度是32的倍数即可。在训练期间,YOLO拍摄
的图像尺寸为320×320、352×352,…和608×608(步骤32)。对于每10批,YOLOv2随机选择另一个图像大小来训练模型。这充当数据增强,并迫使网络针对不同的输入图像尺寸和比例进行良好的预测。另外,我们可以使用较低分辨率的图像进行目标检测,但要以准确性为代价。在低GPU功耗的设备上,这可能是一个不错的折衷方案。YOLO以288×288的速度在90 FPS的条件下运行,其mAP几乎与Fast R-CNN一样。
准确性
这是应用到目前为止讨论的技术之后的准确性提高:

不同检测器的精度比较:

YOLOv3
在Pascal Titan X上,它以30 FPS的速度处理图像,并且在COCO测试开发中的mAP为57.9%。
class预测
大多数分类器假定输出标签是互斥的。如果输出是互斥的对象类,则为true。因此,YOLO应用softmax函数将分数转换为总计为1的概率。YOLOv3使用多标签分类。例如,输出标签可以是非排他性的“行人”和“孩子”。(现在输出的总和可以大于1。)
YOLOv3用独立的逻辑分类器替换了softmax函数,以计算输入属于特定标签的可能性。YOLOv3在计算分类损失时不使用均方误差,而是对每个标签使用二进制交叉熵损失。通过避免softmax函数,这也降低了计算复杂度。
边界框预测和损失函数计算
YOLOv3使用逻辑回归预测每个边界框的客观性得分。YOLOv3改变了计算损失函数的方式。如果边界框先验(锚点)与真实物体的重叠程度大于其他事实,则对应的客观性得分应为1。对于重叠度大于预定义阈值(默认值为0.5)的其他先验,它们不
会产生任何成本。每个地面真理对象仅与一个边界框相关联。如果没有分配先验边界框,则不会导致分类和定位丢失,而只会降低客观性的置信度。我们使用tx和ty(而不是bx和by)来计算损失。

金字塔网络
YOLOv3每个位置进行3个预测。每个预测由边界框,客观性和80个类别分数组成,即N×N×[3×(4 + 1 + 80)]个预测。YOLOv3以3种不同的尺度进行预测(类似于FPN)
特征提取器
使用新的53层Darknet-53代替Darknet-19作为特征提取器。Darknet-53主要由3×3和1×1滤波器组成,这些滤波器具有跳过连接,例如ResNet中的残留网络。与ResNet152相比,Darknet-53具有更少的BFLOP(十亿浮点运算),但以2倍的速度实现了相
同的分类精度。
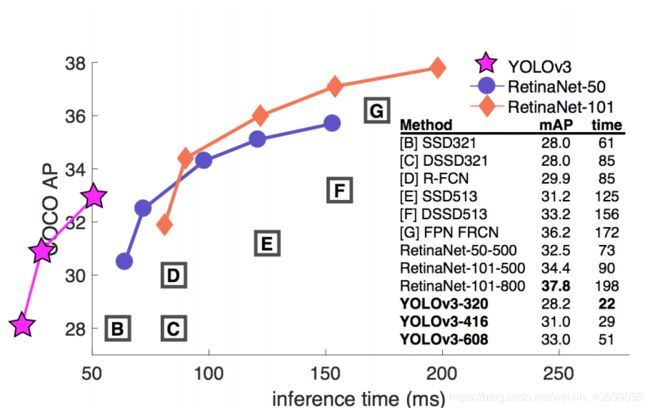
YOLOv3性能
YOLOv3的COCO AP指标与SSD相当,但速度提高了3倍。但是YOLOv3的AP仍然落后于RetinaNet。特别是,AP @ IoU = .75与RetinaNet相比明显下降,这表明YOLOv3具有更高的定位误差。YOLOv3在检测小物体方面也显示出显着改进。

当速度很重要时,YOLOv3在快速检测器类别中的表现非常好。