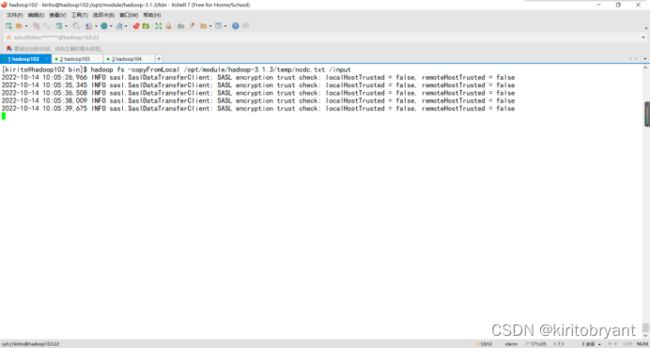
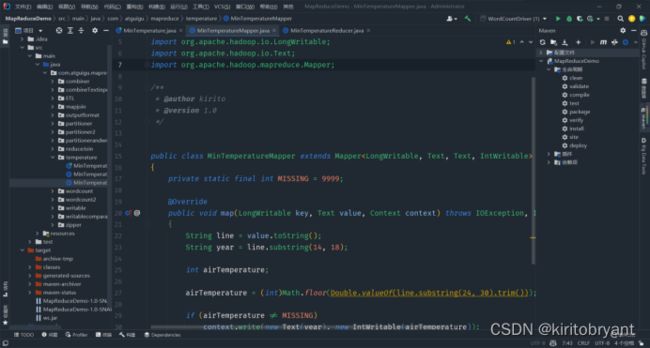
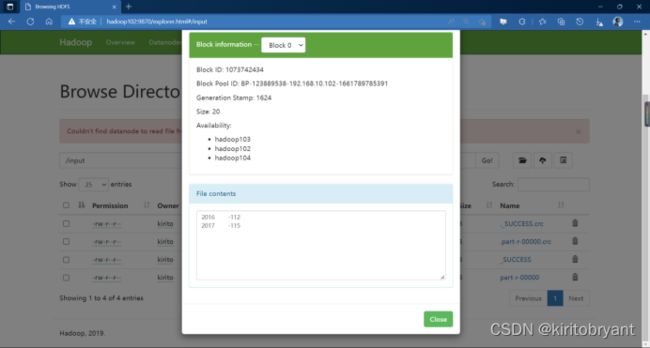
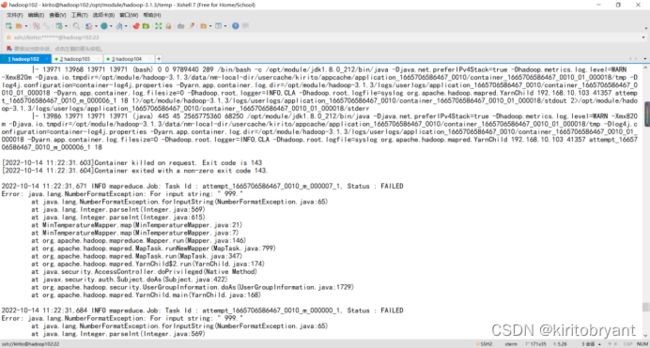
- YARN container cpu超核如何解决
fzip
YARN超核
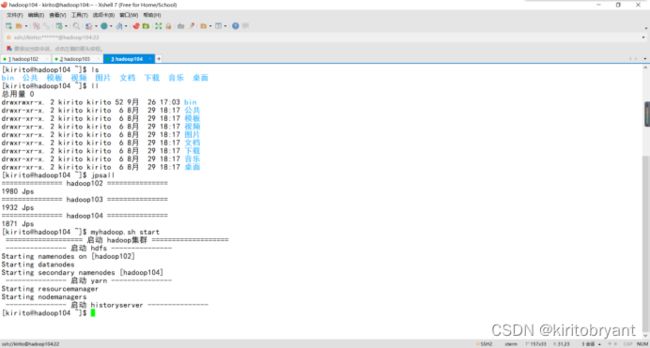
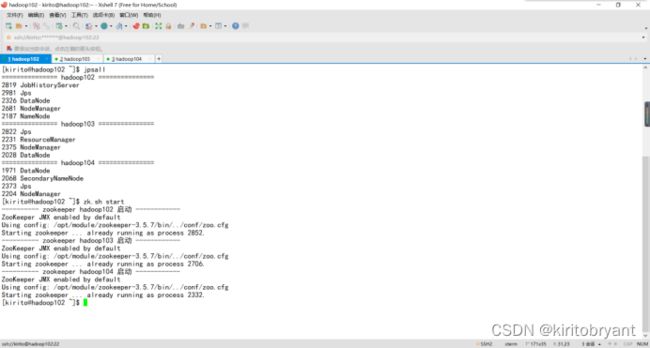
在ApacheHadoopYARN中,ContainerCPU超核(即Container使用的CPU资源超过分配量)是一个常见问题,可能导致集群性能下降或不稳定。以下是解决该问题的详细步骤:1.问题诊断1.1确认超核现象查看YARNWebUI:访问http://:8088,检查Container的CPU使用率是否持续超过分配的vCore数。检查NodeManager日志:查看/var/log/ha
- Hadoop-Mapreduce入门
Hadoop-Mapreduce入门MapReduce介绍mapreduce设计MapReduce编程规范入门案例WordCountMapReduce介绍MapReduce的思想核心是“分而治之”,适用于大量复杂的任务处理场景(大规模数据处理场景)。知识。Map负责“分”,把复杂的任务分解为若干个“简单的任务”来并行处理。可以进行拆分的前提是这些小任务可以并行计算,彼此间几乎没有依赖关系。Redu
- Flink ClickHouse 连接器:实现 Flink 与 ClickHouse 无缝对接
Edingbrugh.南空
大数据flinkflinkclickhouse大数据
引言在大数据处理领域,ApacheFlink是一款强大的流处理和批处理框架,而ClickHouse则是一个高性能的列式数据库,专为在线分析处理(OLAP)场景设计。FlinkClickHouse连接器为这两者之间搭建了一座桥梁,使得用户能够在Flink中方便地与ClickHouse数据库进行交互,实现数据的读写操作。本文将详细介绍FlinkClickHouse连接器的相关内容,包括其特点、使用方法
- Hadoop MapReduce入门
且行且安~
数据分析进阶之路Linux命令hadoopMapReduce入门
入门简介计算过程分为两个阶段Map和ReduceMap阶段并行处理输入数据Reduce阶段对Map结果进行汇总针对python语言来说:map函数或者reduce函数来说,输出的数据格式为元组tuple一个简单的MapReduce程序只需要指定map()reduce()input()output()剩下的由框架完成。Linux常见命令:-读取文件(文本文件,在Windows下使用记事本打开的文件)
- Hadoop MapReduce 入门
一、Hadoop3.0.4环境准备1.环境要求Java8(Hadoop3.0.4不支持Java11+)单节点或多节点Linux系统(推荐Ubuntu18.04+)至少4GB内存(建议8GB+)50GB以上磁盘空间2.安装Java#安装Java8sudoapt-getinstallopenjdk-8-jdk#验证安装java-version3.下载与安装Hadoop3.0.4#下载Hadoop3.0
- 【前端开发】Uniapp分页器:新增输入框跳转功能
基于UniApp官方扩展组件库uni-ui中的uni-pagination分页器组件,针对大数据量场景进行优化主要优化以下内容:新增输入框跳转功能:在原有分页器基础上,新增了一个输入框区域,允许用户直接输入目标页码进行跳转双向页码绑定优化:实现了输入框与当前页码的双向绑定机制。当用户通过其他方式(如点击上一页、下一页、页码按钮)切换页面时,输入框会自动更新显示当前页码。同时,当用户在输入框中输入页
- 大数据技术之Flink
第1章Flink概述1.1Flink是什么1.2Flink特点1.3FlinkvsSparkStreaming表Flink和Streaming对比FlinkStreaming计算模型流计算微批处理时间语义事件时间、处理时间处理时间窗口多、灵活少、不灵活(窗口必须是批次的整数倍)状态有没有流式SQL有没有1.4Flink的应用场景1.5Flink分层API第2章Flink快速上手2.1创建项目在准备
- 如何在YashanDB中实现多级缓存策略
数据库
随着大数据时代的到来,数据存储和访问的效率要求越来越高。数据库技术在面对海量数据、高并发访问时,性能瓶颈逐渐凸显,尤其是响应时间和系统吞吐量成为开发者和DBA关注的重点。为了解决这些问题,缓存策略被引入作为一种有效的解决方案。然而,不同类型的缓存(如内存缓存、磁盘缓存等)之间需要协调工作,以达到最佳性能。在此背景下,YashanDB作为一个云原生数据库,支持多级缓存策略,为数据访问提供了灵活的加速
- 蛋白质结构预测/功能注释/交互识别/按需设计,中国海洋大学张树刚团队直击蛋白质智能计算核心任务
hyperai
蛋白质作为生命活动的主要承担者,在人体生理功能中扮演关键角色。然而传统研究面临结构解析成本高昂、功能注释严重滞后、新型蛋白质设计效率低下等挑战。近年来,生命科学对蛋白质复杂特性解析的需求日益迫切,大数据、深度学习、多模态计算等技术的突破性发展,为构建蛋白质智能计算体系提供了全新的发展契机。蛋白质智能计算体系的构建,使得蛋白质在大规模功能注释、交互预测及三维结构建模等领域取得显著成果,为药物发现与生
- 管理大数据存储的十大技巧
weixin_34238633
大数据数据库运维
在1990年,每一台应用服务器都倾向拥有直连式系统(DAS)。SAN的构建则是为了更大的规模和更高的效率提供共享的池存储。Hadoop已经逆转了这一趋势回归DAS。每一个Hadoop集群都拥有自身的——虽然是横向扩展型——直连式存储,这有助于Hadoop管理数据本地化,但也放弃了共享存储的规模和效率。如果你拥有多个实例或Hadoop发行版,那么你就将得到多个横向扩展的存储集群。而我们所遇到的最大挑
- 【计算机毕业设计】基于Springboot的办公用品管理系统+LW
枫叶学长(专业接毕设)
Java毕业设计实战案例课程设计springboot后端
博主介绍:✌全网粉丝3W+,csdn特邀作者、CSDN新星计划导师、Java领域优质创作者,掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和学生毕业项目实战,高校老师/讲师/同行前辈交流✌技术范围:SpringBoot、Vue、SSM、HLMT、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、小程序、安卓app、大数据、物联网、机器学习等设计与开发。主要内容:
- MapReduce数据处理过程2万字保姆级教程
大模型大数据攻城狮
mapreduce大数据yarncdhhadoop大数据面试shuffle
目录1.MapReduce的核心思想:分而治之的艺术2.HadoopMapReduce的架构:从宏观到微观3.WordCount实例:从代码到执行的完整旅程4.源码剖析:Job.submit的魔法5.Map任务的执行:从分片到键值对6.Shuffle阶段:MapReduce的幕后英雄7.Reduce任务的执行:从数据聚合到最终输出8.Combiner的魔法:提前聚合的性能利器9.Partition
- Hadoop核心组件最全介绍
Cachel wood
大数据开发hadoop大数据分布式spark数据库计算机网络
文章目录一、Hadoop核心组件1.HDFS(HadoopDistributedFileSystem)2.YARN(YetAnotherResourceNegotiator)3.MapReduce二、数据存储与管理1.HBase2.Hive3.HCatalog4.Phoenix三、数据处理与计算1.Spark2.Flink3.Tez4.Storm5.Presto6.Impala四、资源调度与集群管
- 数据仓库技术及应用(Hive 产生背景与架构设计,存储模型与数据类型)
娟恋无暇
数据仓库笔记hive
1.Hive产生背景传统Hadoop架构存在的一些问题:MapReduce编程必须掌握Java,门槛较高传统数据库开发、DBA、运维人员学习门槛高HDFS上没有Schema的概念,仅仅是一个纯文本文件Hive的产生:为了让用户从一个现有数据基础架构转移到Hadoop上现有数据基础架构大多基于关系型数据库和SQL查询Facebook诞生了Hive2.Hive是什么官网:https://hive.ap
- 深入解析Spring Boot与Kafka集成:构建高性能消息驱动应用
Uranus^
JavaSpringBootKafka消息队列分布式系统
深入解析SpringBoot与Kafka集成:构建高性能消息驱动应用引言在现代分布式系统中,消息队列是实现异步通信和解耦的关键组件之一。ApacheKafka作为一种高性能、分布式的消息队列系统,被广泛应用于大数据处理、实时流处理以及事件驱动的架构中。本文将深入探讨如何在SpringBoot应用中集成Kafka,构建高性能的消息驱动应用。Kafka简介ApacheKafka是一个分布式流处理平台,
- 掌握大数据领域数据湖的部署要点
掌握大数据领域数据湖的部署要点关键词:数据湖,大数据部署,数据治理,存储架构,元数据管理,数据质量,湖仓一体摘要:在数据爆炸的时代,企业面临着"数据多却用不好"的困境——结构化数据藏在数据库里,非结构化数据堆在服务器上,半结构化数据散落在日志文件中。数据湖就像一个"智能中央仓库",能统一存储所有类型的数据,并通过灵活的管理让数据"活起来"。本文将用"图书馆管理员建仓库"的故事,从概念理解、架构设计
- (阳:算法霸权 / 阴:数据确权)→当GDPR类法规覆盖53%经济体量时,催生出隐私计算新范式
百态老人
人工智能机器学习深度学习算法
当GDPR类法规覆盖53%经济体量时,隐私计算新范式的兴起可归因于以下多维度因素的相互作用:一、算法霸权与数据确权的矛盾激化算法霸权的危害大型科技公司通过算法歧视、大数据杀熟等手段形成垄断优势,利用数据优势操控用户行为,导致消费者权益受损。这种"算法黑箱"不仅加剧市场不公平,还阻碍数据要素的自由流动。例如,算法框架的底层逻辑掌握在少数企业手中,产生"数据黑箱"问题。数据确权的立法需求数据权属不明确
- 缺少关键的 MapReduce 框架文件
计算圆周率时提醒Hadoop集群缺少关键的MapReduce框架文件mr-framework.tar.gz在http://master:7180/cmf/services/4/status里直接安装再次运行代码:
- 解析大数据领域结构化数据的管理模式
大数据洞察
大数据ai
解码结构化数据:大数据时代的高效管理模式与实践指南关键词结构化数据、大数据管理、数据建模、分布式数据库、数据仓库、数据治理、性能优化摘要在大数据的洪流中,结构化数据犹如隐藏在波涛之下的磐石,虽然不如非结构化数据那般引人注目,却是企业决策的基石。本文深入剖析了大数据环境下结构化数据的管理模式,从传统关系型数据库到现代分布式系统,从数据建模到存储架构,全面解读了结构化数据管理的核心技术与实践方法。通过
- ClickHouse【理论篇】01:什么是ClickHouse
ClickHouse是一款开源的列式数据库管理系统(Column-OrientedDBMS),专为高性能实时数据分析(OLAP,OnlineAnalyticalProcessing)场景设计。它由俄罗斯搜索引擎公司Yandex开发(2016年开源),目前由独立基金会ClickHouse,Inc.维护,广泛应用于大数据分析、日志处理、用户行为洞察等领域。一、核心定位:OLAP场景的“性能标杆”传统关
- 【大数据入门核心技术-DolphinScheduler】(二)DolphinScheduler安装部署-集群模式
forest_long
大数据技术入门到21天通关大数据sparkhivehadoop交互flinkmapreduce
目录一、部署模式1、单机模式2、伪集群模式3、集群模式二、部署安装1、下载2、创建mysql元数据库3、配置一键部署脚本4、初始化数据库5、一键部署DolphinScheduler6、访问DolphinSchedulerUI三、启停命令一、部署模式DolphinScheduler支持多种部署模式,包括单机模式(Standalone)、伪集群模式(PseudoCluster)、集群模式(Cluste
- 利用已有的 PostgreSQL 和 ZooKeeper 服务,启动dolphinscheduler-standalone-server3.1.9 镜像
云游
大数据平台zookeeperdockerpostgresql工作流任务调度
ApacheDolphinScheduler是一个分布式易扩展的可视化DAG工作流任务调度开源系统。适用于企业级场景,提供了一个可视化操作任务、工作流和全生命周期数据处理过程的解决方案。ApacheDolphinScheduler旨在解决复杂的大数据任务依赖关系,并为应用程序提供数据和各种OPS编排中的关系。解决数据研发ETL依赖错综复杂,无法监控任务健康状态的问题。DolphinSchedule
- Alpha系统联结大数据、GPT两大功能,助力律所管理降本增效
资讯分享周
大数据gpt
如何通过AI工具实现法律服务的提质增效,是每一位法律人都积极关注和学习的课题。但从AI技术火爆一下,法律人一直缺乏系统、实用的学习资料,来掌握在法律场景下AI的使用技巧。今年5月,iCourt携手贵阳律协大数据与人工智能专业委员会,联合举办了《人工智能助力律师行业高质量发展巡回讲座》,超过100家律所的律师参与活动。讲座上,iCourtAIGC研究员、AlphaGPT产品研发负责人兰洋,为贵州律协
- 电商API性能优化:策略体系与实施要点
Joe13265449558
性能优化电商返回值淘宝API接口京东
电商API性能优化策略介绍在电商领域,API(应用程序编程接口)作为连接电商平台与外部系统、服务或应用的关键桥梁,其性能直接关系到用户体验、业务效率以及系统的整体稳定性。随着电商业务的快速发展,API接口面临着高并发、大数据量处理等挑战,因此,对电商API进行性能优化显得尤为重要。本文将从多个维度探讨电商API性能优化的策略。一、数据库优化策略数据库是电商API接口的核心组件之一,其性能直接影响A
- ECharts 智慧医疗大屏制作实例详解
在大数据时代,数据可视化已成为信息传递和决策支持的重要手段。ECharts作为一款功能强大、易于上手的开源可视化库,凭借其丰富的图表类型、灵活的配置项和良好的跨平台兼容性,广泛应用于企业级数据大屏、BI报表、实时监控等场景。本教程以“智慧医疗大屏”为例,完整演示了从页面搭建、图表配置到动态交互与响应式适配的全过程。通过循序渐进的讲解,读者将掌握如何使用ECharts构建专业、美观、可交互的数据可视
- 大数据 ETL 工具 Sqoop 深度解析与实战指南
一、Sqoop核心理论与应用场景1.1设计思想与技术定位Sqoop是Apache旗下的开源数据传输工具,核心设计基于MapReduce分布式计算框架,通过并行化的Map任务实现高效的数据批量迁移。其特点包括:批处理特性:基于MapReduce作业实现导入/导出,适合大规模离线数据迁移,不支持实时数据同步。异构数据源连接:支持关系型数据库(如MySQL、Oracle)与Hadoop生态(HDFS、H
- 安装Hadoop集群&入门&源码编译
只年
大数据Hadoophadoop大数据分布式
安装Hadoop集群完全分布式先决条件准备三台机器NameStaticIPDESCbigdata102192.168.1.102DataNode、NodeManager、NameNodebigdata103192.168.1.103DataNode、NodeManager、ResourceManagerbigdata104192.168.1.104DataNode、NodeManager、Seco
- Hadoop之HDFS
只年
大数据HadoopHDFShadoophdfs大数据
Hadoop之HDFSHDFS的Shell操作启动Hadoop集群(方便后续测试)[atguigu@hadoop102~]$sbin/start-dfs.sh[atguigu@hadoop102~]$sbin/start-yarn.sh-help:输出这个命令参数[atguigu@hadoop102~]$hadoopfs-helprm-ls:显示目录信息[atguigu@hadoop102~]$h
- Python(28)Python循环语句指南:从语法糖到CPython字节码的底层探秘
一个天蝎座白勺程序猿
Python爬虫入门到高阶实战python开发语言
目录引言一、推导式家族全解析1.1基础语法对比1.2性能对比测试二、CPython实现揭秘2.1字节码层面的秘密2.2临时变量机制三、高级特性实现3.1嵌套推导式优化3.2条件表达式处理四、性能优化指南4.1内存使用对比4.2执行时间优化技巧五、最佳实践建议六、总结Python爬虫相关文章(推荐)引言在Python编程中,循环语句是控制流程的核心工具。传统for循环虽然直观,但在处理大数据时往往面
- 安装Python3.12报错:HTTP 429 TOO MANY REQUESTS for url <https://mirrors.ustc.edu.cn/anaconda/pkgs/free/li
安装Python3.12报错(base)[xxx@hadoop104python_shell]$condacreate--namepythonThirteenpython=3.12报错如下:Retrievingnotices:…working…ERRORconda.notices.fetch:get_channel_notice_response(63):Requesterrorforchanne
- Maven
Array_06
eclipsejdkmaven
Maven
Maven是基于项目对象模型(POM), 信息来管理项目的构建,报告和文档的软件项目管理工具。
Maven 除了以程序构建能力为特色之外,还提供高级项目管理工具。由于 Maven 的缺省构建规则有较高的可重用性,所以常常用两三行 Maven 构建脚本就可以构建简单的项目。由于 Maven 的面向项目的方法,许多 Apache Jakarta 项目发文时使用 Maven,而且公司
- ibatis的queyrForList和queryForMap区别
bijian1013
javaibatis
一.说明
iBatis的返回值参数类型也有种:resultMap与resultClass,这两种类型的选择可以用两句话说明之:
1.当结果集列名和类的属性名完全相对应的时候,则可直接用resultClass直接指定查询结果类
- LeetCode[位运算] - #191 计算汉明权重
Cwind
java位运算LeetCodeAlgorithm题解
原题链接:#191 Number of 1 Bits
要求:
写一个函数,以一个无符号整数为参数,返回其汉明权重。例如,‘11’的二进制表示为'00000000000000000000000000001011', 故函数应当返回3。
汉明权重:指一个字符串中非零字符的个数;对于二进制串,即其中‘1’的个数。
难度:简单
分析:
将十进制参数转换为二进制,然后计算其中1的个数即可。
“
- 浅谈java类与对象
15700786134
java
java是一门面向对象的编程语言,类与对象是其最基本的概念。所谓对象,就是一个个具体的物体,一个人,一台电脑,都是对象。而类,就是对象的一种抽象,是多个对象具有的共性的一种集合,其中包含了属性与方法,就是属于该类的对象所具有的共性。当一个类创建了对象,这个对象就拥有了该类全部的属性,方法。相比于结构化的编程思路,面向对象更适用于人的思维
- linux下双网卡同一个IP
被触发
linux
转自:
http://q2482696735.blog.163.com/blog/static/250606077201569029441/
由于需要一台机器有两个网卡,开始时设置在同一个网段的IP,发现数据总是从一个网卡发出,而另一个网卡上没有数据流动。网上找了下,发现相同的问题不少:
一、
关于双网卡设置同一网段IP然后连接交换机的时候出现的奇怪现象。当时没有怎么思考、以为是生成树
- 安卓按主页键隐藏程序之后无法再次打开
肆无忌惮_
安卓
遇到一个奇怪的问题,当SplashActivity跳转到MainActivity之后,按主页键,再去打开程序,程序没法再打开(闪一下),结束任务再开也是这样,只能卸载了再重装。而且每次在Log里都打印了这句话"进入主程序"。后来发现是必须跳转之后再finish掉SplashActivity
本来代码:
// 销毁这个Activity
fin
- 通过cookie保存并读取用户登录信息实例
知了ing
JavaScripthtml
通过cookie的getCookies()方法可获取所有cookie对象的集合;通过getName()方法可以获取指定的名称的cookie;通过getValue()方法获取到cookie对象的值。另外,将一个cookie对象发送到客户端,使用response对象的addCookie()方法。
下面通过cookie保存并读取用户登录信息的例子加深一下理解。
(1)创建index.jsp文件。在改
- JAVA 对象池
矮蛋蛋
javaObjectPool
原文地址:
http://www.blogjava.net/baoyaer/articles/218460.html
Jakarta对象池
☆为什么使用对象池
恰当地使用对象池化技术,可以有效地减少对象生成和初始化时的消耗,提高系统的运行效率。Jakarta Commons Pool组件提供了一整套用于实现对象池化
- ArrayList根据条件+for循环批量删除的方法
alleni123
java
场景如下:
ArrayList<Obj> list
Obj-> createTime, sid.
现在要根据obj的createTime来进行定期清理。(释放内存)
-------------------------
首先想到的方法就是
for(Obj o:list){
if(o.createTime-currentT>xxx){
- 阿里巴巴“耕地宝”大战各种宝
百合不是茶
平台战略
“耕地保”平台是阿里巴巴和安徽农民共同推出的一个 “首个互联网定制私人农场”,“耕地宝”由阿里巴巴投入一亿 ,主要是用来进行农业方面,将农民手中的散地集中起来 不仅加大农民集体在土地上面的话语权,还增加了土地的流通与 利用率,提高了土地的产量,有利于大规模的产业化的高科技农业的 发展,阿里在农业上的探索将会引起新一轮的产业调整,但是集体化之后农民的个体的话语权 将更少,国家应出台相应的法律法规保护
- Spring注入有继承关系的类(1)
bijian1013
javaspring
一个类一个类的注入
1.AClass类
package com.bijian.spring.test2;
public class AClass {
String a;
String b;
public String getA() {
return a;
}
public void setA(Strin
- 30岁转型期你能否成为成功人士
bijian1013
成功
很多人由于年轻时走了弯路,到了30岁一事无成,这样的例子大有人在。但同样也有一些人,整个职业生涯都发展得很优秀,到了30岁已经成为职场的精英阶层。由于做猎头的原因,我们接触很多30岁左右的经理人,发现他们在职业发展道路上往往有很多致命的问题。在30岁之前,他们的职业生涯表现很优秀,但从30岁到40岁这一段,很多人
- [Velocity三]基于Servlet+Velocity的web应用
bit1129
velocity
什么是VelocityViewServlet
使用org.apache.velocity.tools.view.VelocityViewServlet可以将Velocity集成到基于Servlet的web应用中,以Servlet+Velocity的方式实现web应用
Servlet + Velocity的一般步骤
1.自定义Servlet,实现VelocityViewServl
- 【Kafka十二】关于Kafka是一个Commit Log Service
bit1129
service
Kafka is a distributed, partitioned, replicated commit log service.这里的commit log如何理解?
A message is considered "committed" when all in sync replicas for that partition have applied i
- NGINX + LUA实现复杂的控制
ronin47
lua nginx 控制
安装lua_nginx_module 模块
lua_nginx_module 可以一步步的安装,也可以直接用淘宝的OpenResty
Centos和debian的安装就简单了。。
这里说下freebsd的安装:
fetch http://www.lua.org/ftp/lua-5.1.4.tar.gz
tar zxvf lua-5.1.4.tar.gz
cd lua-5.1.4
ma
- java-14.输入一个已经按升序排序过的数组和一个数字, 在数组中查找两个数,使得它们的和正好是输入的那个数字
bylijinnan
java
public class TwoElementEqualSum {
/**
* 第 14 题:
题目:输入一个已经按升序排序过的数组和一个数字,
在数组中查找两个数,使得它们的和正好是输入的那个数字。
要求时间复杂度是 O(n) 。如果有多对数字的和等于输入的数字,输出任意一对即可。
例如输入数组 1 、 2 、 4 、 7 、 11 、 15 和数字 15 。由于
- Netty源码学习-HttpChunkAggregator-HttpRequestEncoder-HttpResponseDecoder
bylijinnan
javanetty
今天看Netty如何实现一个Http Server
org.jboss.netty.example.http.file.HttpStaticFileServerPipelineFactory:
pipeline.addLast("decoder", new HttpRequestDecoder());
pipeline.addLast(&quo
- java敏感词过虑-基于多叉树原理
cngolon
违禁词过虑替换违禁词敏感词过虑多叉树
基于多叉树的敏感词、关键词过滤的工具包,用于java中的敏感词过滤
1、工具包自带敏感词词库,第一次调用时读入词库,故第一次调用时间可能较长,在类加载后普通pc机上html过滤5000字在80毫秒左右,纯文本35毫秒左右。
2、如需自定义词库,将jar包考入WEB-INF工程的lib目录,在WEB-INF/classes目录下建一个
utf-8的words.dict文本文件,
- 多线程知识
cuishikuan
多线程
T1,T2,T3三个线程工作顺序,按照T1,T2,T3依次进行
public class T1 implements Runnable{
@Override
- spring整合activemq
dalan_123
java spring jms
整合spring和activemq需要搞清楚如下的东东1、ConnectionFactory分: a、spring管理连接到activemq服务器的管理ConnectionFactory也即是所谓产生到jms服务器的链接 b、真正产生到JMS服务器链接的ConnectionFactory还得
- MySQL时间字段究竟使用INT还是DateTime?
dcj3sjt126com
mysql
环境:Windows XPPHP Version 5.2.9MySQL Server 5.1
第一步、创建一个表date_test(非定长、int时间)
CREATE TABLE `test`.`date_test` (`id` INT NOT NULL AUTO_INCREMENT ,`start_time` INT NOT NULL ,`some_content`
- Parcel: unable to marshal value
dcj3sjt126com
marshal
在两个activity直接传递List<xxInfo>时,出现Parcel: unable to marshal value异常。 在MainActivity页面(MainActivity页面向NextActivity页面传递一个List<xxInfo>): Intent intent = new Intent(this, Next
- linux进程的查看上(ps)
eksliang
linux pslinux ps -llinux ps aux
ps:将某个时间点的进程运行情况选取下来
转载请出自出处:http://eksliang.iteye.com/admin/blogs/2119469
http://eksliang.iteye.com
ps 这个命令的man page 不是很好查阅,因为很多不同的Unix都使用这儿ps来查阅进程的状态,为了要符合不同版本的需求,所以这个
- 为什么第三方应用能早于System的app启动
gqdy365
System
Android应用的启动顺序网上有一大堆资料可以查阅了,这里就不细述了,这里不阐述ROM启动还有bootloader,软件启动的大致流程应该是启动kernel -> 运行servicemanager 把一些native的服务用命令启动起来(包括wifi, power, rild, surfaceflinger, mediaserver等等)-> 启动Dalivk中的第一个进程Zygot
- App Framework发送JSONP请求(3)
hw1287789687
jsonp跨域请求发送jsonpajax请求越狱请求
App Framework 中如何发送JSONP请求呢?
使用jsonp,详情请参考:http://json-p.org/
如何发送Ajax请求呢?
(1)登录
/***
* 会员登录
* @param username
* @param password
*/
var user_login=function(username,password){
// aler
- 发福利,整理了一份关于“资源汇总”的汇总
justjavac
资源
觉得有用的话,可以去github关注:https://github.com/justjavac/awesome-awesomeness-zh_CN 通用
free-programming-books-zh_CN 免费的计算机编程类中文书籍
精彩博客集合 hacke2/hacke2.github.io#2
ResumeSample 程序员简历
- 用 Java 技术创建 RESTful Web 服务
macroli
java编程WebREST
转载:http://www.ibm.com/developerworks/cn/web/wa-jaxrs/
JAX-RS (JSR-311) 【 Java API for RESTful Web Services 】是一种 Java™ API,可使 Java Restful 服务的开发变得迅速而轻松。这个 API 提供了一种基于注释的模型来描述分布式资源。注释被用来提供资源的位
- CentOS6.5-x86_64位下oracle11g的安装详细步骤及注意事项
超声波
oraclelinux
前言:
这两天项目要上线了,由我负责往服务器部署整个项目,因此首先要往服务器安装oracle,服务器本身是CentOS6.5的64位系统,安装的数据库版本是11g,在整个的安装过程中碰到很多的坑,不过最后还是通过各种途径解决并成功装上了。转别写篇博客来记录完整的安装过程以及在整个过程中的注意事项。希望对以后那些刚刚接触的菜鸟们能起到一定的帮助作用。
安装过程中可能遇到的问题(注
- HttpClient 4.3 设置keeplive 和 timeout 的方法
supben
httpclient
ConnectionKeepAliveStrategy kaStrategy = new DefaultConnectionKeepAliveStrategy() {
@Override
public long getKeepAliveDuration(HttpResponse response, HttpContext context) {
long keepAlive
- Spring 4.2新特性-@Import注解的升级
wiselyman
spring 4
3.1 @Import
@Import注解在4.2之前只支持导入配置类
在4.2,@Import注解支持导入普通的java类,并将其声明成一个bean
3.2 示例
演示java类
package com.wisely.spring4_2.imp;
public class DemoService {
public void doSomethin