SegNet分割模型解析(含详细代码及注释)
目录
模型特点
完整代码
SegNet是剑桥大学于2015年提出的分割模型
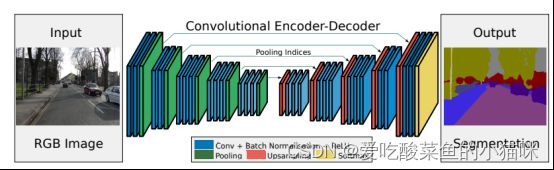
模型特点
1. backbone: vgg16
2. encoder-decoder,左右网络层对称。
encoder中,卷积层负责提取图像特征,经过池化层下采样,图像宽高减半 但是通道数不变,将尺度不变的特征传送到下一层,bn层对训练图像进行批标准化(BatchNormalization),加速模型的学习。
decoder中,对缩小后的特征图进行上采样,然后对上采样后的图像进行卷积处理,来完善图像中物体的几何形状,将encoder中获得的特征还原到原来图像的具体的像素点上。
3. 带索引的最大池化上采样。
记录下采样过程的indices,在上采样过程中使用,以提供位置信息。
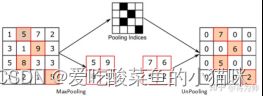
(图片来源自知乎)
注意:
encoder中通过 nn.MaxPool2d(kernel_size=2, stride=2, return_indices=True) 中的return_indices返回元素的指标位置。
decoder中不含池化层,对应位置为反池化层。
完整代码
import torch
import torch.nn as nn
from torchvision import models
class SegNet(nn.Module):
def __init__(self, num_classes, in_channels=3, path_model=None):
super(SegNet, self).__init__()
vgg_bn = models.vgg16_bn()
if path_model:
vgg_bn.load_state_dict(torch.load(path_model, map_location="cpu"))
print("load pretrain model done!")
encoder = list(vgg_bn.features.children()) # features中共44个网络层
# 调整输入维度,以防输入维度!=3 (vgg16中第一个网络层输入维度为3,输出维度为64)
if in_channels != 3:
encoder[0] = nn.Conv2d(in_channels, 64, kernel_size=3, stride=1, padding=1)
# Encoder, VGG without any maxpooling
self.stage1_encoder = nn.Sequential(*encoder[:6])
self.stage2_encoder = nn.Sequential(*encoder[7:13])
self.stage3_encoder = nn.Sequential(*encoder[14:23])
self.stage4_encoder = nn.Sequential(*encoder[24:33])
self.stage5_encoder = nn.Sequential(*encoder[34:-1])
# 通过return_indices记录下采样过程元素的指标位置
self.pool = nn.MaxPool2d(kernel_size=2, stride=2, return_indices=True)
# 先将encoder中的池化层以外的网络层翻转,翻转后的结果:每三个均为relu+bn+conv的形式(一共39个网络)
decoder = [i for i in encoder[::-1] if not isinstance(i, nn.MaxPool2d)]
# 改变最后一个卷积层
decoder[-1] = nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=1)
# 将每三个relu+bn+conv 翻转成 conv+bn+relu
decoder = [item for i in range(0, len(decoder), 3) for item in decoder[i:i+3][::-1]]
# 改变输入输出通道数(输入通道数应等于输出通道数)
for i, module in enumerate(decoder):
if isinstance(module, nn.Conv2d):
if module.in_channels != module.out_channels:
decoder[i+1] = nn.BatchNorm2d(module.in_channels)
decoder[i] = nn.Conv2d(module.out_channels, module.in_channels, kernel_size=3, stride=1, padding=1)
self.stage1_decoder = nn.Sequential(*decoder[0:9])
self.stage2_decoder = nn.Sequential(*decoder[9:18])
self.stage3_decoder = nn.Sequential(*decoder[18:27])
self.stage4_decoder = nn.Sequential(*decoder[27:33])
self.stage5_decoder = nn.Sequential(*decoder[33:],
nn.Conv2d(64, num_classes, kernel_size=3, stride=1, padding=1)
)
# 反池化
self.unpool = nn.MaxUnpool2d(kernel_size=2, stride=2)
# 模型权重初始化
self._initialize_weights(self.stage1_decoder, self.stage2_decoder, self.stage3_decoder,
self.stage4_decoder, self.stage5_decoder)
def _initialize_weights(self, *stages):
for modules in stages:
for module in modules.modules():
if isinstance(module, nn.Conv2d):
nn.init.kaiming_normal_(module.weight)
if module.bias is not None:
module.bias.data.zero_()
elif isinstance(module, nn.BatchNorm2d):
module.weight.data.fill_(1)
module.bias.data.zero_()
def forward(self, x):
# Encoder
x = self.stage1_encoder(x)
x1_size = x.size()
x, indices1 = self.pool(x) # 返回值为:特征x以及指标位置indices
x = self.stage2_encoder(x)
x2_size = x.size()
x, indices2 = self.pool(x)
x = self.stage3_encoder(x)
x3_size = x.size()
x, indices3 = self.pool(x)
x = self.stage4_encoder(x)
x4_size = x.size()
x, indices4 = self.pool(x)
x = self.stage5_encoder(x)
x5_size = x.size()
x, indices5 = self.pool(x)
# Decoder
# 上采样:使用对应位置的indices进行反池化,输出大小为pool前的特征x的大小
x = self.unpool(x, indices=indices5, output_size=x5_size)
x = self.stage1_decoder(x)
x = self.unpool(x, indices=indices4, output_size=x4_size)
x = self.stage2_decoder(x)
x = self.unpool(x, indices=indices3, output_size=x3_size)
x = self.stage3_decoder(x)
x = self.unpool(x, indices=indices2, output_size=x2_size)
x = self.stage4_decoder(x)
x = self.unpool(x, indices=indices1, output_size=x1_size)
x = self.stage5_decoder(x)
return x
if __name__ == "__main__":
fake_img = torch.randn((2, 3, 224, 224))
model = SegNet(num_classes=12, path_model=0)
output = model(fake_img)
print(output.shape)