Vision Permutator: A Permutable MLP-Like Architecture for Visual Recognition——2022 TPAMI论文笔记
这篇文章是上周分享那篇论文的作者的另外一项工作,也发表在今年的pami上。提出了一个纯的基于多层感知机的网络用于图像分类任务。
论文链接:Vision Permutator: A Permutable MLP-Like Architecture for Visual Recognition | IEEE Journals & Magazine | IEEE Xplore
Code: GitHub - houqb/VisionPermutator: MLP-Like Vision Permutator for Visual Recognition (PyTorch)
背景
2021年有些研究表示纯的基于多层感知机的网络在图像分类任务上表现良好。相对于利用空间卷积的CNN网络和利用自注意力层编码空间信息的ViT类模型,MLP类的网络利用纯的全连接层,在训练和推理阶段都更高效。但是以往的MLP-like模型在没有额外大规模数据支持的情况下,性能会比CNNs和ViT类模型差很多。
这篇文章主要贡献就是提出了一种概念简单、数据高效的MLP类的视觉识别架构,称为Vision Permutator。 Vision Permutator的架构设计可以使其在避免像transformer一样建立注意力的情况下,捕获到长距离的依赖关系,然后将输出聚合成有表现力的特征表示。 在不依赖空间卷积和注意力机制、不使用额外的训练数据的情况下, Vision Permutator仅使用25M参数在ImageNet数据集上可以达到81.5%的top-1准确率,高于绝大多数同等参数规模的CNNs和vision transformers。
Vision Permutator
现有的MLP-like架构首先会将输入图像的二维空间维度flatten成一维,然后进行线性映射来实现对图像的编码,但这会导致编码得到的特征缺失2D的位置信息。而Vision Permutator会沿着width和height的维度分别编码空间信息,来保持输入图像的原始空间维度。

Vip模型的整体架构如上图所示,对于一张输入图像,首先将其分割成一个个的小的patchs,然后通过线性映射将它们映射为token embeddings,维度为height×width×channels。
然后将这些token embeddings输入到一系列的Permutator块中,每一个Permutator块包含一个Permute-MLP用于编码空间信息和一个通道-MLP用于混合通道信息(这部分后文会详细介绍)。
最后使用一个全局平均池化层和一个全连接层对特征进行分类。
作者指出与现有的将两个维度混合(flatten)为一个维度的MLP-like模型相比,本文模型沿着这些维度单独处理特征,可以产生更具区分性的特征表示。
Permutator
如果不管LayerNorms层和网络连接方式,一个转换器(permutator)主要由两个部件组成:Permute-MLP和Channel-MLP:
Channel-MLP是由两个全连接层和一个中间的激活层组成的。Permute-MLP比较复杂一些,下文介绍。
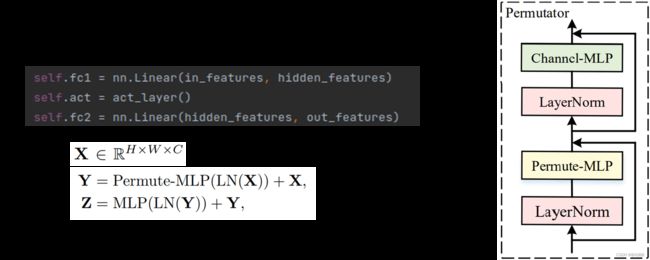
Permute-MLP
然后介绍最重要的Permute-MLP结构。
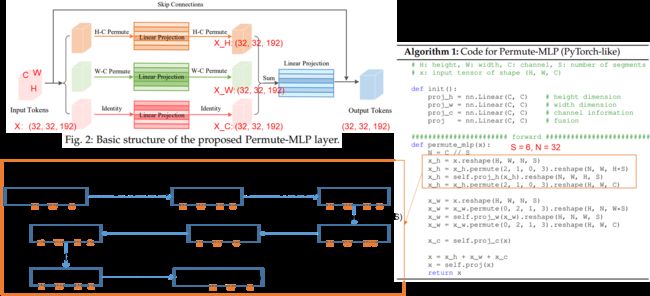
这里输入token的维度是三维的:(H,W,C)。Permute-MLP包含三个分支,分别负责沿着高度、宽度和通道维度编码特征。然后将三个分支的输出相加,最后输入到一个全连接的层进行特征融合,得到输出tokens。
以输入token大小为(32,32,192)为例:
沿着通道维度编码很简单,只需要一个全连接层,就可以对输入X进行线性投影,得到X_C。
然后是在H的方向进行空间信息的编码,先是把最后一维192分成了S段,代码里面S为6,然后这一维就成了(32,6)两个维度,再把H这一维跟N这一维调换位置,然后把最后两个维度reshape成一个维度,变成(32,32,192)。再通过一个线性层,不改变维度大小。然后剩下的操作就是逆变换:把192展成2个维度变成H*S,再把H和N维调换位置,最后把后两维还原成C。得到的X_H的维度也是(32,32,192).
在W的方向进行空间信息的编码的操作也是类似的,就不具体介绍了。
最后将得到的X_H、X_W和H_C进行加权相加(Weighted Permute-MLP),再通过一个全连接层就得到了输出tokens。
与卷积网络和Transformer的关系
Vision Permutator在从原始图像抽取图像块转化为patch embedding的时候,使用了一层二维卷积,所以Vip模型可以看作是卷积网络和MLP的混合架构,但大部分的操作还是用的全连接层。Transformer模型也只由mlp组成,但是它依赖于自注意力来建立token之间的关系,本文的Vip模型没有显式地对token之间的相似性进行建模,因此与Transformer是很不同的。
不同参数配置的Vision Permutator
通过配置不同的参数,可以产生不同的Vip模型,参数规模各不相同,论文里面实验部分主要用到了以下五种Vip模型,参数规模从23M到88M。

EXPERIMENTS
在ImageNet上的主要结果
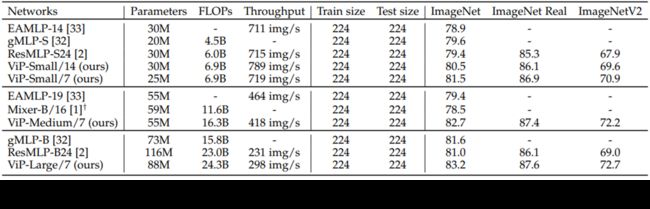
这一张图片是本文模型与最近的MLP-like模型在Imagenet、ImageNet Real和ImageNetV2数据集上的Top1准确率对比。所有的模型都没有使用额外的训练数据,参数规模相当,ViP-Small/7只有25M参数,达到了81.5%的Top-1准确率,已经高于大多数MLP-like模型(比73M参数量的gMLP-B模型只低0.1个点)。当扩展模型到55M参数量时,准确率已经高于所有其他的MLP类的模型,进一步扩展能达到83.2%的准确率。
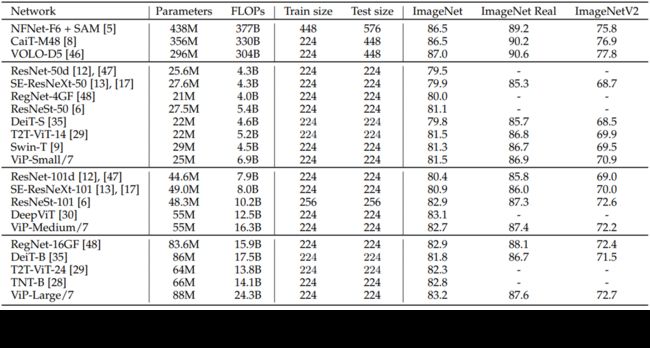
然后是本文模型与经典的卷积神经网络和ViT变种模型在ImageNet、ImageNet Real和ImageNetV2数据集上的Top-1准确率对比,选择的也是参数规模相当的模型,所有模型都没有使用额外的训练数据(但是本文模型有使用多种数据增强策略)。与参数规模相近的CNN网络和基于Transformer的模型相比,能达到差不多的性能,但是比最近的sota 卷积网络和transformer-based网络(表中前三行)还是落后一大截的,不过这些网络规模也大了许多。
其中一个消融实验
文中还做了多组消融实验,证明沿着宽和高的方向分别进行空间信息的编码,提取的特征是更好的;以及不同参数设置下的模型的消融实验。这里只介绍一个使用不同数据增强方法的消融实验。

文中用了四种不同的数据增强方法,分别来自四篇论文。第一个随机数据增强,就是从多种数据增强方法中随机选择一些;第二个随机擦除就是随机擦除一些图像区域;第三个MixUp就是将随机的两张样本按比例混合,分类结果按比例分配;第四个CutMix就是将一部分区域剪切掉但不填充0像素,而是随机填充训练集中其他数据的区域像素值,分类结果按一定比例分配。
随着数据增强方式的加入,准确率在逐步上升。上文在与其他经典网络进行对比时,其他网络应该是没有使用相同的数据增强策略的,所以如果ViP没有加数据增强得到的75.3%的准确率,估计是比不过其他CNNs和transformer-based模型的。
其他
ViP模型参数规模小,代码简洁规范,易复现。我没有在ImageNet上做实验,直接把模型用在其他数据集上,能取得不错的效果。不过从我目前实验结果来看,收益主要来源于数据增强策略... 下一步准备尝试一下ViP模型的迁移学习效果。