Fast R-CNN 详解
Fast R-CNN 详解
-
- 一、R-CNN 和 SPPNet
-
- (一)R-CNN 缺点
- (二)SPPNet 缺点
- 二、网络结构
-
- (一)RoI pooling
- (二)训练过程
-
- 1. 监督预训练
- 2. Fine-turning
- 3. 多任务 loss
- 4. SVD 分解全连接层
- 5. SGD 超参数
Fast R-CNN
论文链接
Fast R-CNN 是一个 end-to-end 的目标检测模型(除了生成 region proposals 的部分)。它的 主要的创新 有以下几点:
(1)将目标的分类和 Bounding Box 的回归都集成在同一个网络且同时训练。
(2)提出了 roi pooling。使网络可以接受多尺度的输入。
(3)只对整个图像做一次特征提取,后多次利用。大大减少了 R-CNN 中冗余的特征提取操作。
(4)采用 SVD 分解对 Fast R-CNN 网络末尾并行的全连接层进行分解,减少计算复杂度,加快检测速度。
Fast R-CNN 在速度、精度、存储的占用上相对于先前的网络都有了质的飞跃。
一、R-CNN 和 SPPNet
(一)R-CNN 缺点
我们先来看一下对于 R-CNN 有哪些缺点?
-
训练是多阶段的:R-CNN 中每部分的网络都需要单独的训练,步骤十分繁琐。
-
训练速度慢、占用空间多:R-CNN 中生成的 region 经过 CNN 网络提取特征之后,需要把每一个生成的 feature map 保存到硬盘。用于下一阶段 SVM 分类器的训练。
-
目标检测速度过慢:检测时,对于所有生成的 region proposals 都要放入 CNN 网络中进行特征提取。region 之间有很多的重叠部分,且每个 region 都要重新输入一遍网络,没有共享计算。这大大降低了目标检测的速度。
(二)SPPNet 缺点
那么对于 SPPNet 有什么缺点?SPPNet 无法 fine-turn SPP-Layer 之前的卷积层
这是为什么呢?这是因为 SPPNet 训练样本来自不同图像导致反向传播效率低下。SPPNet 中 fine-tuning 的样本是来自所有图像的所有 RoI 打散后均匀采样的,即 RoI-centric sampling,这就导致 SGD 的每个 batch 的样本来自不同的图像,需要同时计算和存储这些图像的 Feature Map,过程变得 expensive。
另一个角度来看,反向传播需要计算每一个 RoI 感受野的卷积层梯度,通常几个 RoI 就会覆盖整个图像。如果用 RoI-centric sampling 方式会由于计算太多整幅图像梯度而变得又慢又耗内存。换句话说,我们计算了太多次的重叠部分的梯度。这样会有很多冗余的计算。
二、网络结构

图 1:Fast R-CNN 网络结构。
Fast R-CNN 的输入为图像的 list 和 这些图像对应 region proposals 的 list。其网络主要由 四个部分组成: 第一个部分是 公共的卷积层。第二部分是 RoI pooling 层。第三部分是 公共的全连接层。第四部分是 分类和回归层,第四部分有两个分支,其中一个分支经过独自的 FC 层后输出一个长度为 class + 1 的向量。第二个分支经过独自的 FC 层后输出长度为 4 的向量,其中通道数为 class。每个通道的 4 个值代表 Bounding box 的左上角坐标(x, y)和 宽高(w, h)。
(一)RoI pooling
RoI pooling 借鉴了 SPPNet 的思想,是简化版的 SPPNet。它可以将不同大小的 feature map 转化为相同大小的特征向量。具体过程的动图如下:

图 2:roi pooling 的动态过程。
相比于 SPPNet,RoI pooling 只进行了一组下采样。而 SPPNet 做了多组下采样,然后将结果拼接。RoI pooling 是将 SPPNet 的思想发挥到了精简的极致。
对于一张 feature map,我们先提取出 region proposal 映射到的那部分 feature map 的区域。假如最终我们要生成 H x W 的 feature map,那么我们就 将此 feature map 的区域划分为平均的 H x W 大小的网格。分别求出每个网格中的最大值,我们就会得到 H x W 大小的结果。这就是 roi pooling 的过程。
(二)训练过程
1. 监督预训练
先将通用的网络模型(例如 AlexNet、VGG16 等)在 ImageNet 数据集上进行 预训练。然后经过如下的 3 步变换:
(1)将网络最后的 max pooling 层换成 RoI pooling 层。
(2)网络最后的 FC 层和 softmax 替换成并列的 2 层 FC 层。一个 FC 用来分类【输出长度为:类别数 + 1】,另一个 FC 用来回归最后的 Bounding Box。【输出长度为:4,通道数为:类别数 + 1】
(3)将网络修改为接收 2 个值为输入。图像的 list 和属于这些图像中的 roi 的 list。
2. Fine-turning
| 样本 | 比例 | 来源 |
|---|---|---|
| 正样本( u ≥ 1 u\ge1 u≥1) | 25% | 与 ground truth 的 I O U ≥ 0.5 IOU \ge 0.5 IOU≥0.5 |
| 负样本 ( u = 0 u=0 u=0) | 75% | 与 ground truth 的 I O U < 0.5 IOU \lt0.5 IOU<0.5 |
我们需要 解决 SPPNet 不能 fine-turning SPP-Layer 之前的卷积层的问题 。设 N 为图像的 batch 的个数。R 为一个 batch 的总 roi 的个数。将网络的输入改为,图像的 list 和属于这些图像中的 roi 的 list。然后使用分层采样。先采样 N 个图片组成一个 list,再对每个图片采样 R / N 个 放入 list。这样的话我们每次从 roi 的 list 取出 R / N 个,就是对应的那个图片生成的那些 roi。
这样的策略,可能会导致收敛缓慢。因为同一个样本的 roi 有关联性。不过作者在试验中发现,在实际中并没有出现这种问题。作者使用的 N = 2,R = 128。
3. 多任务 loss
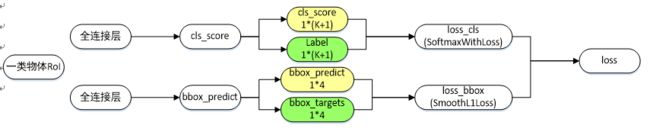
图 3:多任务 loss
- cls_score:用于分类,输出 K+1 维数组 p,表示属于 K 类物体和背景的概率。
- bbox_predict:用于调整候选区域位置,输出 4*K 维数组,也就是说对于每个类别都会训练一个单独的回归器。
- loss_cls:评估分类代价,由真实分类 u 对应的概率决定:用 L c l s ( p , u ) = − l o g ( p u ) L_{cls}(p,u)=-log(p_u) Lcls(p,u)=−log(pu) 表示。
- loss_bbox:评估回归损失代价,比较真实分类 u 对应的预测平移缩放参数 t u = ( t x u , t y u , t w u , t h u ) t^u=(t^u_x,t^u_y,t^u_w,t^u_h) tu=(txu,tyu,twu,thu) 和真实平移缩放参数 v = ( v x , v y , v w , v h ) v=(v_x,v_y,v_w,v_h) v=(vx,vy,vw,vh) 的差距,用 smooth l1 表示:
L l o c ( t u , v ) = ∑ i ∈ { x , y , w , h } s m o o t h L 1 ( t i u , v i ) L_{loc}(t^u,v)=\sum_{i\in\{x,y,w,h\}}smooth_{L_1}(t^u_i,v_i) Lloc(tu,v)=i∈{x,y,w,h}∑smoothL1(tiu,vi)
其中:
s m o o t h L 1 ( x ) = { 0.5 x 2 |x|<1 ∣ x ∣ − 0.5 other smooth_{L1}(x)= \begin{cases} 0.5x^2&& \text{|x|<1}\\ |x|-0.5&& \text{other} \end{cases} smoothL1(x)={0.5x2∣x∣−0.5|x|<1other
图像如下:相比 L2 损失,其对离群点、异常值不敏感。

结合分类损失和回归损失,Fast R-CNN微调阶段总的损失函数为:
L ( p , u , t u , v ) = L c l s ( p , u ) + λ [ u ≥ 1 ] L l o c ( t u , v ) L(p,u,t^u,v)=L_{cls}(p,u)+\lambda[u \ge 1]L_{loc}(t^u,v) L(p,u,tu,v)=Lcls(p,u)+λ[u≥1]Lloc(tu,v)
[ u ≥ 1 ] = { 1 u>1 0 otherwise [u\ge1]= \begin{cases} 1& \text{u>1}\\ 0& \text{otherwise}\\ \end{cases} [u≥1]={10u>1otherwise
约定 u = 0 u=0 u=0 为背景分类,那么 [ u ≥ 1 ] [u≥1] [u≥1] 函数表示背景候选区域。即负样本不参与回归损失,不需要对其进行回归操作。 λ λ λ 控制分类损失和回归损失的平衡,文中所有实验 λ = 1 λ=1 λ=1。
4. SVD 分解全连接层
网络的大部分的参数和计算量都在全连接层。对于 Fast R-CNN 而言,对于每个生成的 region proposal 都要经过全连接层。那么全连接层的速度直接影响到了整个网络在训练和测试阶段的速度。对于全连接层,我们可以使用 SVD 对其参数进行分解。将一个全连接层转化为两个小的全连接层,我们选前 t 个特征值进行近似。会大大减少网络的参数量。具体的推导如下。
物体分类和窗口回归都是通过全连接层实现的,假设全连接层输入数据为 x,输出数据为 y,全连接层参数为 W,尺寸为 u × v,那么该层全连接计算为:
y = W x y=Wx y=Wx
计算复杂度为 u x v。
若将 W 进行 SVD 分解,并用前 t 个特征值近似代替,即:
W = U ∑ V T ≈ U ( u , 1 : t ) ⋅ ∑ ( 1 : t , 1 : t ) ⋅ V ( v , 1 : t ) T W=U\sum V^T≈U(u,1:t) \;·\sum (1:t,1:t)\; · V(v,1:t)^T W=U∑VT≈U(u,1:t)⋅∑(1:t,1:t)⋅V(v,1:t)T
那么原来的前向传播分解成两步:
y = W x = U ⋅ ( ∑ ⋅ V T ) ⋅ x = U ⋅ z y=Wx=U·(\sum·V^T)\;·x=U·z y=Wx=U⋅(∑⋅VT)⋅x=U⋅z
计算复杂度为 u × t + v × t u×t+v×t u×t+v×t,若 t < m i n ( u , v ) t
在实现时,相当于把一个全连接层拆分为两个全连接层,第一个全连接层不含偏置,第二个全连接层含偏置。实验表明,SVD 分解全连接层能使 mAP 只下降 0.3% 的情况下提升 30% 的速度,同时该方法也不必再执行额外的微调操作。(见下图)

5. SGD 超参数
除了修改增加的层,原有的层参数已经通过预训练方式初始化; 用于分类的全连接层以均值为 0、标准差为 0.01 的高斯分布初始化,用于回归的全连接层以均值为 0、标准差为 0.001 的高斯分布初始化,偏置都初始化为 0。
针对 PASCAL VOC 2007 和 2012 训练集,前30k次迭代全局学习率为 0.001,每层权重学习率为 1 倍,偏置学习率为 2 倍,后 10k 次迭代全局学习率更新为 0.0001。动量设置为 0.9,权重衰减设置为 0.0005。
参考链接:
https://arxiv.org/pdf/1504.08083.pdf
https://blog.csdn.net/WoPawn/article/details/52463853
https://www.jianshu.com/p/fbbb21e1e390