案例推荐|服务 50+ 业务线,Apache Pulsar 在科大讯飞 SRE 的探索与实践
本文整理自 8 月 Apache Pulsar Meetup 上的分享。科大讯飞是中国最大的智能语音技术提供商,在中文语音合成、语音识别、口语评测等多项技术上拥有国际领先的成果。2022 年 3 月,科大讯飞正式将 Pulsar 上线。本文将介绍经历一年多的测试与评估,科大讯飞为何选择 Pulsar;如何利用 SRE 保障体系将 Pulsar 从 0 到 1 落地;内部的监控与参数优化与 Pulsar 使用过程中可能出现的一系列问题及相应的解决方案。
本文首发自 InfoQ。

Pulsar Summit Asia 2022 盛大来袭
业务简介
科大讯飞股份有限公司是亚太地区知名的智能语音和人工智能上市企业。自成立以来,科大讯飞一直从事智能语音、自然语言理解、计算机视觉等核心技术研究并保持了国际前沿技术水平。目前讯飞云对接了集团内部的各条业务线,包括个性化、计量授权、语音与字幕的非实时转写、AI 办公、语音云、集团云、开放平台等。其中 Pulsar 主要提供高可用、低延时的消息中间件能力。数据通过 Web API 和 SDK 的方式接入 MQ,经过消息的削峰填谷与上下游打通,从而满足业务快速增长的需求。
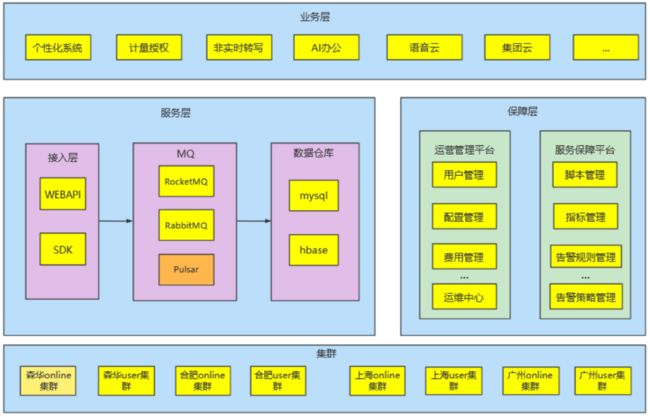
服务的保障层分为运营管理和服务保障平台。运营管理平台主要对申请的集群与业务进行统一管理;服务保障平台主要对脚本、指标、告警策略等方面进行管理。团队要求中间件具有为业务提供高吞吐和海量级数据服务的能力。目前,Pulsar 每天处理的数据量在十亿级别,还肩负多个跨可用区的数据同步工作。
MQ 有以下服务保障难点:
• 业务流量上涨十几倍,集群在流量洪峰时出现不稳定情况;
• 集群扩容业务的感知数据在新老节点上有平衡问题;
• 跨可用区数据同步时延及幂等性问题;
• 维护多套集群、tickets 复杂度较高。
MQ 对高效 SRE 也有迫切需要:
• 接入 MQ 业务线的更多服务需要梯级保障(50+ 业务线);
• 更高的端对端消息写入及数据同步延时要求;
• 业务接入 MQ 需要流程化和规范化;
• 需要提升持续服务业务的能力;
• 降本增效需求。
基于以上需求,团队一直在寻找合适的消息中间件产品来承载业务,通过内部多轮调研及评审,最终选择了 Apache Pulsar。
Apache Pulsar 在讯飞的演进
首先,团队选择 Apache Pulsar 主要考虑到以下优势:
• 业务收敛,多个小的集群的流量可以聚合至 Pulsar;
• 减少运维工作量,提高生产效率,让业务聚焦于数据而非服务;
• 集群服务存算分离,扩展性高,计算节点无状态性;
• 多租户的友好支持,便于服务通过租户对业务进行隔离;
• 高效率的跨地域复制数据同步能力;
• 提供多个语言的 SDK,接入度及社区活跃度高。

Apache Pulsar 在讯飞内部的演进经历了几个阶段,上图为 Pulsar 在科大讯飞的演进过程。2021 年 7 月,讯飞内部进行了 Pulsar 的调研综述,包括技术调研、可行性调研和落地实施调研。2021 年 9 月,团队进行了 Pulsar 内部压测,验证 Pulsar 是否满足流量规划的需求。2022 年 2 月,团队开始针对压测过程中出现的问题进行性能、配置和架构等方面的调优工作。2022 年 3 月,讯飞内部上线了 Pulsar 的第一个发布版本。
服务保障体系
团队一直在思考该使用怎样的方式来保障 Pulsar 在集团内部的稳定性和高可用性。为此团队引入了服务分级保障的概念。目前团队根据业务线的需求设置了四级服务保障:

测量周期:季度
测算方法:可用性 % =(服务总时长-累计影响时长)/ 服务总时长
数据来源:PaaS 监控系统
利用 SRE 保障体系进行落地
SRE(Site Reliability Engineering),顾名思义是站点可靠性工程。SRE 团队使用软件作为工具,来管理系统、解决问题并实现运维任务自动化。SRE 在创建可扩展和高度可靠的软件系统时十分重要。
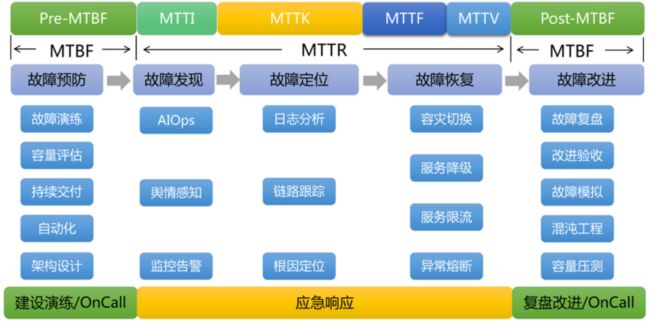
上图是讯飞云内部结合经验沉淀的 SRE 流程。它分为 MTBF(故障平均间隔时间)和 MTTR(故障平均修复时间)两个部分。MTTR 又分为故障发现、定位、处理和恢复的流程。本次分享中主要针对容量评估、架构设计、监控告警和服务限流其中几个模块,讲解 SRE 的保障理念。
架构设计

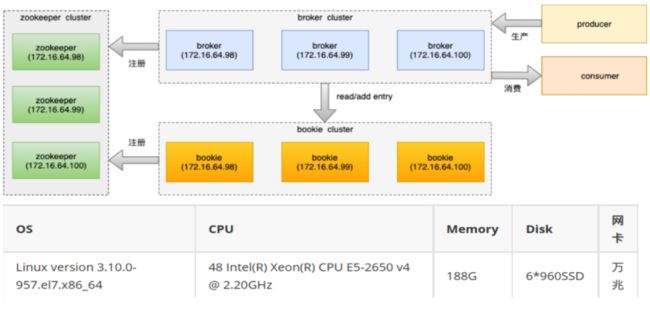
目前 Pulsar 采用多可用区的部署模式。客户端通过 VIP 接入服务,数据进入 Broker 层进行 Topic-Ownership 找到主题所在的节点,Broker 返回客户端通知当前连接所在的 Owner-Broker。下方是 BookKeeper 集群存储层。元数据存储采用 ZooKeeper 集群。多可用区之间通过跨地域复制能力进行数据同步。整体架构为混部模式,以保障 Broker 和 Bookie 交互 ZooKeeper 时的读写低延迟。
容量规划与流量评估
在集群接入时需要做好流量评估,观察集群容量能否满足流量需求。具体来说,团队会根据业务增长的规模(50+ 业务线)进行规划,并根据现有接入业务线申请总流量进行评估。
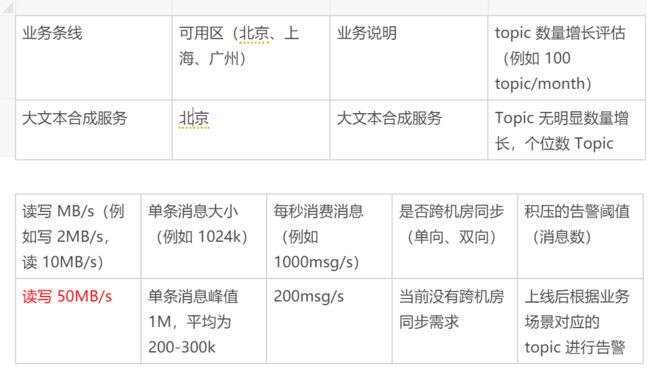
上图为业务接入示例。业务反馈对应 Topic 在 Pulsar 数据增长的结果,比如 Topic 从稳定、缓慢增长到暴涨所体现出的问题;带宽读写速率的大小;单条消息大小;是否存在峰值如重大活动;业务数据是否涉及跨机房复制;消息积压告警阈值等。中间件内部发生消息积压是无法避免的,所以有必要把对应策略同步业务方,及时消除积压。
团队会通过容量模型对部署架构进行验证。下图为验证环境:三台配置相同的物理器,每台都部署了 ZooKeeper、Bookie 和 Broker 组件,模拟实时生产和消费。
在实践过程中,上述容量模型会经过以下场景的测试:
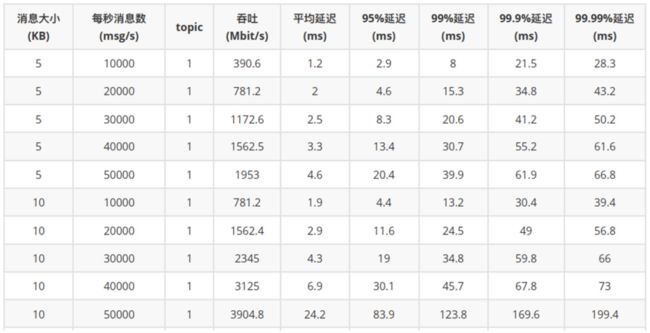
场景一:只生产不消费,异步刷盘,Journal 和 Ledger 盘单独挂载,持续时间 30 分钟。可以看到随着消息量增长,各项延迟指标都有所增加。
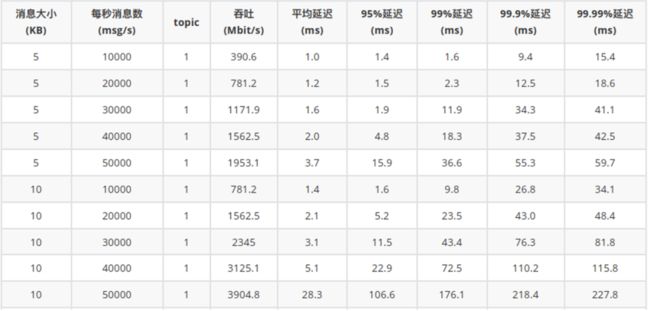
场景二:只生产不消费,同步刷盘,Journal 和 Ledger 盘单独挂载,持续时间 30 分钟。可以看到各项延迟指标相比异步刷盘场景要高。
团队提出了以下硬件规划建议:
• 物理机,48 core CPU、256G 内存、万兆网卡;
• 每台机器规划六块 SSD,为 ZooKeeper、Journal 和 Ledger 单独设置磁盘,让 Journal 盘在大流量写入时有冗余;
• ZooKeeper 的 log、datalogs 盘独立 SSD,保障 ZooKeeper 读写低延迟;
• Bookie 的 journalDirectories 独立挂载两块 SSD,提高 Journal 写盘及刷内存表并发能力;
• Bookie 的 ledgerDirectories 独立挂载三块 SSD,减少 Ledger 在切换期间时延。
Pulsar 监控告警链路

上述告警链路主要借助内部 PaaS 平台的微服务来模块化和清晰化整个告警流程,每个模块专职专责。自上而下,链路包括 PaaS-Agent 感知服务、PaaS-Collector 数据收集服务、PaaS-Probe 集群可用性采集服务、PaaS-Alert 告警模块等。数据从 PaaS-Agent 的节点服务器服务出发,经过 Collector 收集、Prometheus 采集到最终的 PaaS-Alert 进行精筛,对比当前阈值是否满足预期。
该链路支持:
• 多可用区互监控;
• 基础信息多可用区同步;
• 集群信息自动同步;
• 默认告警策略自动添加;
• 默认告警规则自动下发;
• 告警策略规则自由定义;
• 短信、邮件和微信告警;
• 秒级延迟;
• 月、周、天报表。
告警链路使用的核心指标有:

其中星号为重点关注指标。其中:
• Broker 端指标监控 Topic 流量,用以调整 Broker 端负载的均衡;
• Bookie 端指标监控 Journal 及 Ledger 数据刷盘情况,排查数据读写问题;
• ZooKeeper 端指标监控兜底监控整个集群元数据读写延迟状态。
下图是一些监控指标的实践展示:

下图是具体的告警策略,仅供参考:

服务限流
良好的服务限流策略可以预防突发流量击垮集群。具体而言,限流策略会根据业务提供的申请表内容评估峰值流量,调整生产者流量限制在可控区间;更好地利用集群磁盘及网卡资源,保障集群稳定性。
我们对一些 Namespace 进行限流操作。如下图左侧,需要限制生产者总流量为 50M,多余的部分会被拒绝,从而更好地保障集群;如下图右侧,需要限制所有 Topic 的生产者流量为 20M。不同的总流量数值都是根据业务评估得出。

遇到的问题与解决方案
在实践中团队还发现了一些问题,在此与大家分享我们的解决方案。
问题一:在特定业务需要写入单条消息容量较大情况下,Bookie 出现了 readOnly 模式。
原因:Broker 服务与 Bookie 服务限制消息大小不一致,导致客户端发送的消息在 Broker 端正常,但发送到 Bookie 端被拒绝,触发 Broker 重试机制。
解决方法:配置参数调整 dispatcherMaxReadSizeBytes、nettyMaxFrameSizeBytes。
问题二:ZooKeeper 的 data、datalog 盘与 Bookie 的 Journal 及 Ledger 盘混用,读写性能、集群稳定性不佳。
原因:Bookie 的 Journal 及 Ledger 盘读写 IO 出现高水位情况,导致 ZooKeeper 读写延迟升高。
解决方法:将 ZooKeeper 的数据盘与 Bookie 读写数据盘进行物理隔离,专盘专责。
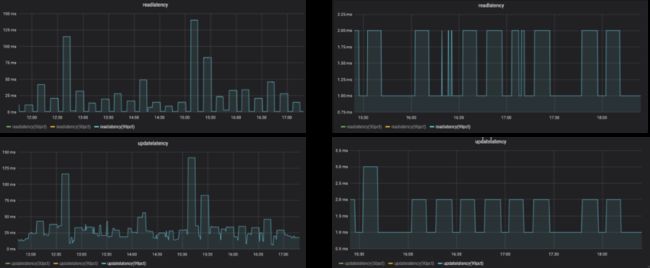
问题三:集群中某些 Broker 节点流量不均衡,造成集群内其他机器较为繁忙。
原因:现阶段 Broker 触发 load-balancer 策略,统计单台节点 heap、direct-heap、cpu、bindwithIn、bindWithOut 的使用比例,取其中一个最大值与默认阈值 85% 对比。
解决方法:基于权重的负载均衡策略,修改 loadBalancerLoadSheddingStrategy。
问题四:高吞吐业务场景下,遇到 broker-direct-memory-OOM 时进程停止。
原因:底层 Bookie 写入变慢,导致大量消息堆积在 Broker 的堆外内存,直至 OOM。
解决方法:生产环境下,不能保证底层 Bookie 始终写入低延迟,在 Broker 层针对特定 Namespace 或 Topic 开启限流策略。
问题五:业务提出是否可以提供统一 IP 供客户端访问?
原因:serviceUrl 配置列表太长,扩容 Broker 节点,业务需要同步修改配置文件。
解决方法:结合业界成熟的 VIP 方案,搭建 Keepalived + HAProxy 高可用架构。
未来规划
科大讯飞团队的计划后续部署 Apache Pulsar 服务的认证授权功能,来进一步提高系统安全性;实现同城双中心,保障集团更多业务接入 Apache Pulsar 时更加高效稳定。团队也会尝试将 Pulsar 与更多大数据组件(Apache Flink、Apache Spark 等)结合,完善生态。目前讯飞云基于 Docker 进行部署,缺少调度。因此团队也在探索如何在 Kubernetes 中应用 Apache Pulsar,做到开箱即用,来降低部署难度。
作者介绍
刘侃,科大讯飞软件开发工程师,主要负责科大讯飞 -AI 云平台消息中间件 Pulsar 的落地,以及对应 SRE 服务保障工作。
Pulsar Summit Asia 2022 直播预约
Pulsar Summit 是 Apache Pulsar 社区年度盛会,它将分布在世界各地的 Apache Pulsar 项目 Contributor、Committer 和各企业 CTO/CIO、开发者、架构师、数据科学家,以及消息和流计算社区的精英召集在一起,分享 Apache Pulsar 实践经验、场景案例、技术探究和运维故事,交流探讨 Pulsar 一线落地技术干货。
议程已公布,扫描下方二维码即可预约观看直播,11 月 19 - 20 日,我们不见不散!

扫码报名
点击「阅读原文」报名 Pulsar Summit Asia 2022~