Jina 实例秀|基于神经搜索的网络安全威胁检测(一)

摘要
在本文中,我们使用 Jina 演示了如何使用相似性搜索来解决网络安全这样一个常见的业务挑战。与原方案的效果相比,精确度提升了 21.3%,召回率提升了 62.1%!

前言
根据 IBM 的研究¹,网络攻击导致的数据泄露给企业造成的平均成本为 386 万美元,并且企业平均需要花费 280 天的时间来识别和遏制网络攻击。
那么,什么是网络攻击?我们如何利用像 Jina 这样的下一代搜索工具来减轻我们的网络安全威胁呢?
网络攻击就是恶意行为者利用网络存在的漏洞和安全缺陷,对系统和资源进行攻击。恶意流量识别是维护网络空间安全的重要手段。
在一个包含 100-1000 维度的数据集会带来相当棘手的挑战,好比大海捞针。而相似性检索技术能够破解高维数据的处理难题,其工作原理是,对于给定的样本对象,在集合中查找与之内容最相似的对象。你可以把它看作是一个最近邻(KNN)问题,其相似性由欧式距离来衡量。

相似度检索技术²

目标
在本课程项目中,我们将利用 Jina 搭建一个由深度学习驱动的网络安全仪表板,模拟网络流量,实时监测恶意事件。我们的目标是开发一个可靠、可扩展,并且高性能的入侵检测系统,实时预测攻击是否发生。
为了实现这一目标,我们将对预训练的神经网络执行“网络手术”,移除分类层,并将神经网络重新用作特征提取器。也就是说,我们的网络最终输出的是特征,而不是标签。

“网络手术”示意图
接着,我们使用特征提取器所生成的 128 维嵌入,并通过 Jina Flow 对它们进行索引,使其可搜索。通过索引数千个这些 128 维向量及其标签(良性/恶意),我们就可以依据它们的距离,来判断它们的相似性。
可视化嵌入
我们能够从不同的日期,获取没见过的网络流量数据,提取其特征。接着依据最近邻的类别,来确定它是良性还是恶意的。简单来说,我们微调了预训练的神经网络,把一个二分类任务,转化为相似性检索任务,以模拟实时检测恶意网络流量。

把相似度检索作为分类基础
以下是具体步骤:
1. 使用神经网络作为特征提取器,生成网络流量的向量表示。
2. 确认相似性度量标准,使相似事物的向量表示更接近。
3. 找到查找对象的最近邻,并返回良性或恶意的结果,以识别出恶意流量。

数据集
在数据科学领域里,收集和预处理数据可是个苦差事,通常是构建应用程序中最耗时、最具挑战性的一步。在网络安全领域更是如此,因为很难找到针对自己任务的数据集。
由于我们无法在一篇文章中涵盖所有内容,所以假设我们在这个已经预处理完的 CSV 数据集上碰了壁。它有 79 列的数值特征(例如,端口、协议、转发数据包等)和一个分类标签(0表示良性,1表示恶意),记录了某一天的网络流量,共 15,000 行。

数据集

初选方案
一开始,我用 Keras 在数据集上训练了一个简单的前馈神经网络来检测恶意流量,精确度和召回率实在不太理想。
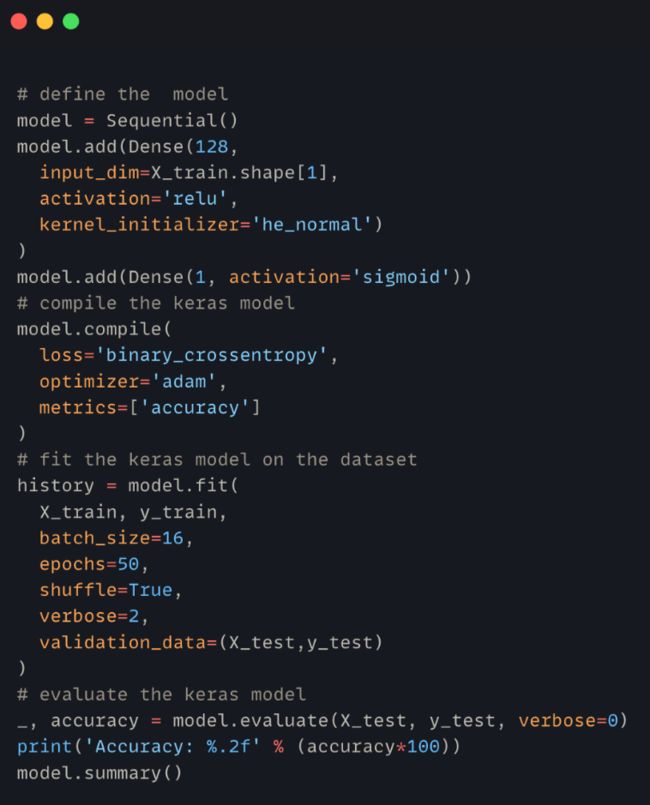
模型训练脚本


左右滑动查看数据表现
可以看到,初选方案在恶意流量的分类上表现很差。

Jina 来救援!优化方案
于是我对原始模型做了一次“网络手术”,剔出分类层,并将神经网络重新用作特征提取器,将二分类问题转变为相似性检索问题。
正好机缘巧合下,我了解到了 Jina,我想试试看能否通过将编码特征索引到 DocumentArray,根据它在向量空间中的最近邻的类别,将网络流量分类为良性/恶意,来获得更好的结果。现在模型采用 79 维的输入特征,运行后输出一个良性或恶意的分类结果。
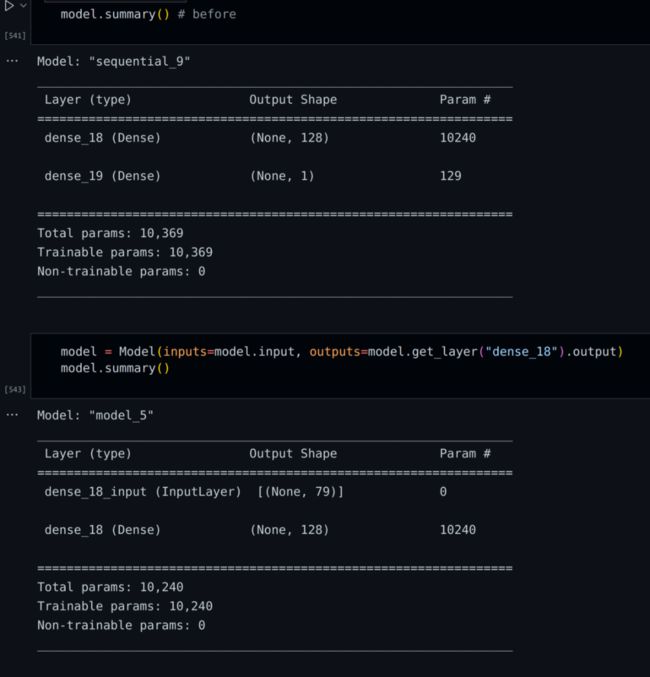
“网络手术”后的模型

索引
我们通过特征提取器,以向量嵌入的形式生成了丰富的、数学化的网络流量数据。接下来就进入到索引阶段了。计算得出的向量的余弦相似度,用距离最近的样本数据来代表目标数据的分类。
为此,我们需要定义我们的索引 Flow
Flows 是 Jina 生态系统的“木偶大师”,它将多个 Executor 连接起来,协调成流水线(Pipeline),进出 Flow 的所有内容都必须是 Document。
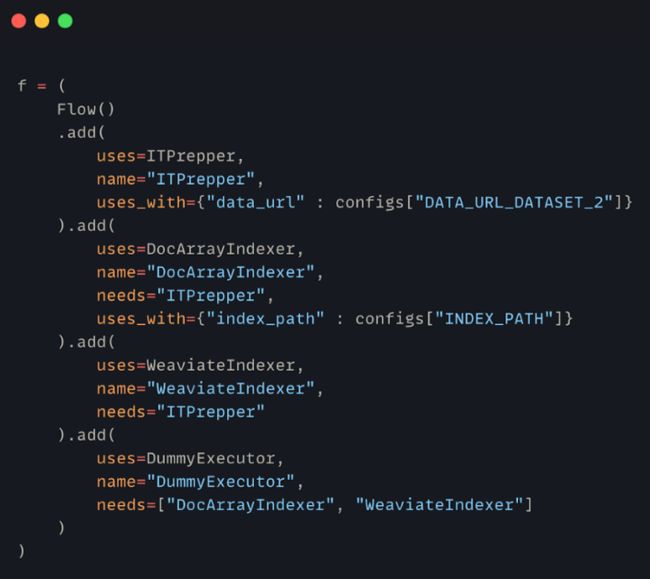
定义 Flow
Flow 默认每个 Executor 都依赖之前添加的 Executor 。但是因为 Flows 在内部被建模为图,所以 Flow 并不局限于顺序执行。Flow 可以表示任何复杂的、非循环的拓扑结构来索引或查询文档。
如图所示,Flow 的典型用例是具有标准预处理部分,但不同的索引器分隔了 embedding 和数据的拓扑结构。它还可以用于构建类似交换机的节点,其中一些 Documents 通过 Flow 的一个并行分支,而其他 Documents 通过不同的分支。
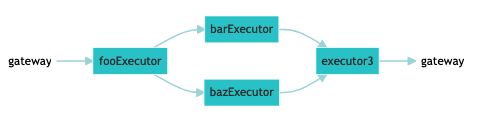
Flow 的拓扑结构
我们微调了 Flow 拓扑结构,并用它来索引我们的网络流量 embedding。如下图所示,Document 不是“按顺序”访问我们 Flow 中定义的每个 Executor,而是从一个叫 ITPrepper 的 Executor 开始。然后,文档将被并行发送到 DocArrayIndexer 和 WeaviateIndexer,Flow 确保每个源自 ITPrepper 的文档都只到达每个索引器一次。最后一个执行器 DummyExecutor ,将接收两个 DocumentArrays 并自动合并它们。
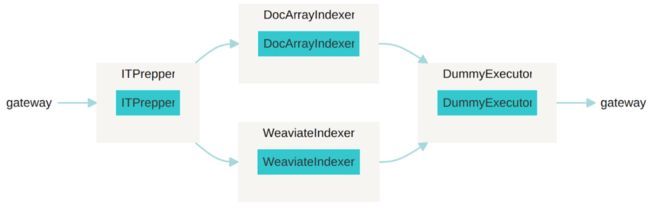
本应用的 Flow
为什么要使用两个不同的索引器呢?因为这样能利用不同搜索算法的不同索引器,实现各自独立查询。并在查询时,从使用不同的搜索算法的索引里创建预测的集合。
聊完了 Flow 拓扑结构,现在最重要的就是——当我们的神经网络模型被用作特征提取器时的性能表现。相比于原始神经网络的分类输出,使用相似性检索是否能获得更好的精确度、召回率等。

结果
由于我们现在有两个独立的索引(DocArrayIndexer, WeaviateIndexer)。其中包含我们的网络流量 embedding 及其在 DocumentArrays 中的相关标签。下图是良性和恶意的样本,注意“know_label”(已知标签)和匹配的区别。
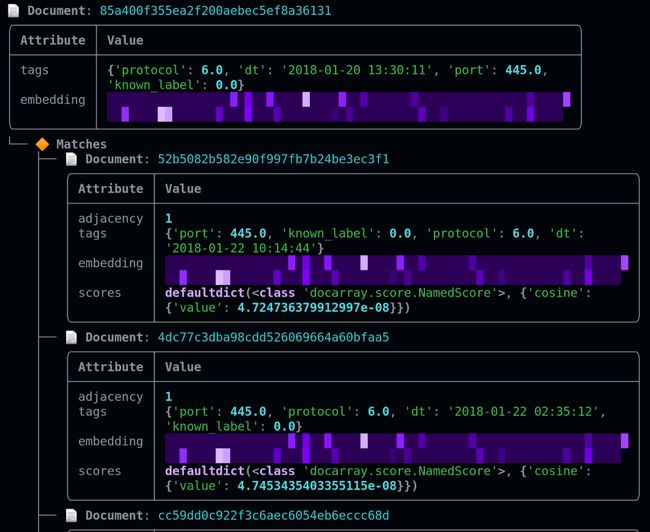
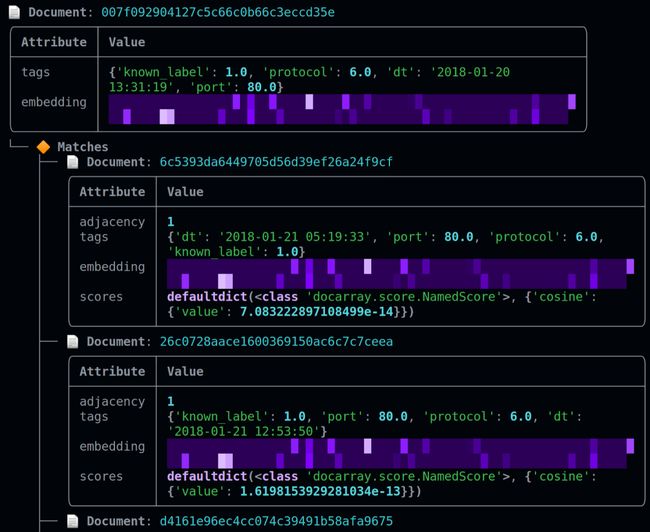
左右滑动查看
现在我们分别加载每个索引,将其与自身匹配以获得最近邻,并遍历每个文档,将它们的已知和预测标签附加到预先初始化的 Python 列表中。我们将采用余弦相似度作为度量标准,使用 scikit-learn 计算准确度、精确度、召回率和 F1 值。

DocumentArray 索引的评估指标
通过比较每个 Document 的 embedding 和索引中的每个embedding,取距离最近,相似度最高的那一个,并根据其最近邻的“known_label”将其分类为良性或恶意。
以下是两次方案的评估指标数据。可以看到,相较于使用实际神经网络输出的原方案,使用 Jina 以相似性检索作为分类基础的优化方案,在准确率和召回率上均得到了大幅提升。

之前
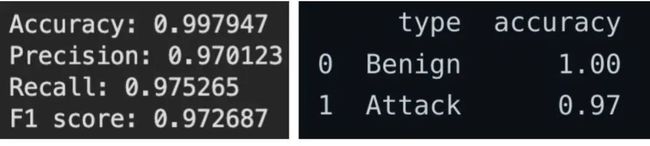
之后...哎哟不错!
之后,我们【将此模型用作更广泛的恶意流量类别的特征提取器,来提取训练期间未发现的恶意流量。这就是所谓的迁移学习,我们使用预训练的神经网络作为起点,找到已有知识和新知识之间的相似性,从最初未训练的数据中学习模式。
项目代码
github.com/k-zehnder/cybersecurity-jina
英文原文(或阅读原文)
medium.com/jina-ai/it-threat-detection-using-neural-search-3f3ff03caade

结论
在本文中,我们使用 Jina 演示了如何使用相似性搜索来解决网络安全这样一个常见的商业业务挑战。我们通过从预训练的神经网络开发一个特征提取器来实现目标,根据与其他已知训练样本的相似性,而不是网络的输出标签来预测网络流量是否是恶意的。
在本系列文章中,我们将继续探讨如何让 Jina 后端和 Streamlit 前端更好的结合,让我们可以轻松地通过浏览器实时模拟网络流量监控!
参考资料
[1]Cost of a Data Breach Report 2022.IBM Com.
[2]https://youtu.be/ainS3BBn7rs
[3]https://medium.com/jina-ai/search-tattoos-with-text-an-open-source-project-made-with-jina-12ac54ac1f78

神经搜索、多模态应用
教程、干货分享
扫码备注加入讨论组
更多精彩内容(点击图片阅读)

