笔记︱几款多模态向量检索引擎:Faiss 、milvus、Proxima、vearch、Jina等
转自:https://zhuanlan.zhihu.com/p/364923722
引用文章[7]的开篇,来表示什么是: 向量化搜索
人工智能算法可以对物理世界的人/物/场景所产生各种非结构化数据(如语音、图片、视频,语言文字、行为等)进行抽象,变成多维的向量。
这些向量如同数学空间中的坐标,标识着各个实体和实体关系。我们一般将非结构化数据变成向量的过程称为 Embedding,而非结构化检索则是对这些生成的向量进行检索,从而找到相应实体的过程。
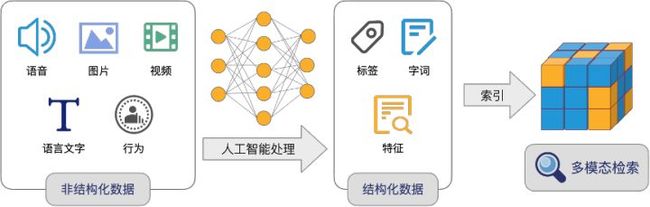
非结构化检索本质是向量检索技术,其主要的应用领域如人脸识别、推荐系统、图片搜索、视频指纹、语音处理、自然语言处理、文件搜索等。
随着 AI 技术的广泛应用,以及数据规模的不断增长,向量检索也逐渐成了 AI 技术链路中不可或缺的一环,更是对传统搜索技术的补充,并且具备多模态搜索的能力。
向量检索的应用场景远不止上面提到的这些类型。
如下图所示,它几乎覆盖了大部分的可以应用AI的业务场景。

1 facebook - Faiss
github: https://github.com/facebookresearch/faiss
tutorial: https://github.com/facebookresearch/faiss/wiki/Getting-started向量化检索开山鼻祖的应用,Faiss库是由 Facebook 开发的适用于稠密向量匹配的开源库,支持 c++ 与 python 调用。
Faiss 支持多种向量检索方式,包括内积、欧氏距离等,同时支持精确检索与模糊搜索,篇幅有限嘛,我就先简单介绍精确检索相关内容。
Faiss 主要特性:
- 支持相似度检索和聚类;
- 支持多种索引方式;
- 支持CPU和GPU计算;
- 支持Python和C++调用;
Faiss 使用场景:
最常见的人脸比对,指纹比对,基因比对等。
2 国产 - Milvus
文章[1][8]提及,
Milvus 是一款开源的特征向量相似度搜索引擎Milvus 使用方便、实用可靠、易于扩展、稳定高效和搜索迅速。
Milvus能够很好地应对海量向量数据,它集成了目前在向量相似性计算领域比较知名的几个开源库(Faiss, SPTAG等),通过对数据和硬件算力的合理调度,以获得最优的搜索性能。

Milvus 提供完整的向量数据更新,索引与查询框架。Milvus 利用 GPU(Nvidia)进行索引加速与查询加速,能大幅提高单机性能。除了提供针对向量的近实时搜索能力外,Milvus 可以对标量数据进行过滤。
随着数据和查询规模的增加,Milvus 还提供了集群分片的解决方案,支持读写分离、水平扩展、动态扩容等功能,实现了对于超大数据规模的支持。
目前,Milvus 是一个单节点主从式架构(Client-server model)的服务器,最高可以支持 TB 级特征数据的存储和搜索服务。对于有更大数据规模或者高并发需求的用户,可以使用目前尚在实验阶段的集群分片中间件 Mishards 进行部署。
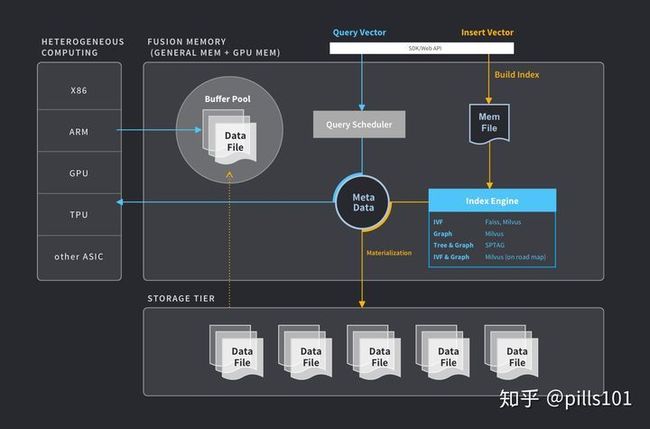
Milvus索引类型:
- IVF:集成 Faiss IVF、Milvus 团队自研 IVF
- Graph:Milvus 团队实现的 NSG 索引、集成 Faiss hnsw
- Tree & Graph:集成微软 SPTAG
- IVF & Graph:Milvus 团队实现
可支撑的应用场景
2.1 图像视频检索
深度学习模型最开始就是用来对图像、视频等进行处理,通过训练可以精准的提取图片、视频中的特征从而对图片、视频进行分类,打标签,以图搜图,以图搜视频等等。Milvus凭借其出色的性能和数据管理能力,可以支持各种深度学习模型,实现对海量图片和视频的高性能分析检索能力。
- 图片搜索
- 图片去重
- 视频去重
- 以商品搜商品
2.2 智能问答机器人
传统的问答机器人大都是基于规则的知识图谱方式实现,这种方式需要对大量的语料进行分类整理。而基于深度学习模型的实现方式可以彻底摆脱对语料的预处理,只需提供问题和答案的对应关系,通过自然语言处理的语义分析模型对问题库提取语义特征向量存入Milvus中,然后对提问的问题也进行语义特征向量提取,通过对向量特征的匹配就可以实现自动回复,轻松实现智能客服等应用。
- 语义提取
- 个性化推荐
- 语料分析和推荐
2.3 赋能传统向量计算
在传统的数据处理领域也存在大量向量计算的场景,使用传统的计算方式需要消耗大量的算力而Milvus凭借先进的算法可以在同等算力资源下将向量数据处理能力提高至少两个数量级。
- 分子结构相似性分析
- 分子药理分析
- 药物分子虚拟筛选
2.4 音频数据处理
利用深度学习模型对音频数据进行分析和处理能够大大提高语音识别的准确率,而其核心也是对相关音频切片进行向量化处理并且通过向量距离的计算来判断其表达的含义,因此,Milvus在语音、音乐等音频数据处理领域的也有丰富的应用。
- 个性化音乐推荐
- 音乐去重
- 声纹验证
- 语音识别
- 智能语音小助手
- 智能翻译机器人
3 国产 - Jina- 神经网络搜索
文章[15]提及,
Jina AI是一家专注基于深度学习模型搭建搜索引擎技术的开源商业公司,打造下一代的开源神经搜索引擎开发平台,通过深度学习和人工智能搜索能力的结合做到全内容搜索,无论是文本、图片、语音、视频、源代码、元数据亦或是文件都可以称为搜索引擎输入源进行全域全方位搜索。
由AI界大名鼎鼎的肖涵老师带领的开源团队创始和开发,秉承了肖涵老师团队优秀的开源文化,其团队名下的Bert as server 和Fashion-Mnist 在GitHub的star数都高达8000,故本次的Jina质量可见一斑。
Jina以通用性为目标,几乎可以搜索任何内容形式(例如文本,图像,视频,音频);它的目标是在AI生产中,利用现代软件基础架构并以最佳工程实践进行构建。旨在易于使用,针对多个平台,架构和用例进行优化。
Jina也有着自身的Yaml语法,可通过API和仪表盘迅速的搭建出一个属于自己的云端系统。同时他最大的亮点就是其可以在多个平台和架构上实现任意类型的大规模索引和查询。
Jina Hub
- 90+ 的 Pod 镜像可供使用
- 支持最先进的AI模型
- 支持多种向量数据库
- 支持多种Evaluation 的方式
4 阿里达摩院 - Proxima & 蚂蚁金服- ZSearch
4.1 阿里达摩院 -Proxima
文章[7]提及,
Proxima 是阿里巴巴达摩院自研的向量检索内核。目前,其核心能力广泛应用于阿里巴巴和蚂蚁集团内众多业务,如淘宝搜索和推荐、蚂蚁人脸支付、优酷视频搜索、阿里妈妈广告检索等。
同时,Proxima 还深度集成在各式各类的大数据和数据库产品中,如阿里云 Hologres、搜索引擎 Elastic Search 和 ZSearch、离线引擎 MaxCompute (ODPS) 等,为其提供向量检索的能力。
Proxima 是通用化的向量检索工程引擎,实现了对大数据的高性能相似性搜索,支持 ARM64、x86、GPU 等多种硬件平台,支持嵌入式设备和高性能服务器,从边缘计算到云计算全面覆盖,支持单片索引十亿级别下高准确率、高性能的索引构建和检索。
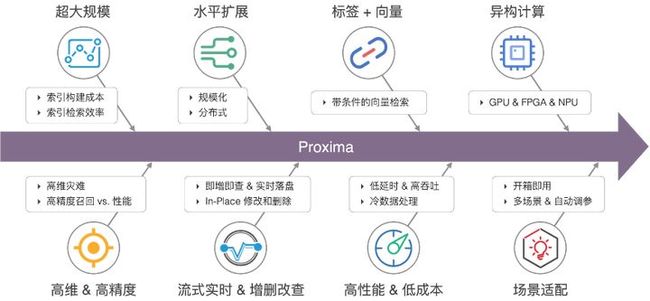
向量检索的算法繁多且缺乏通用性,应对不同数据维度和分布有不同算法,但总体可归为三类思想:
空间划分法:空间划分法以 KD-Tree、聚类检索为代表,检索时快速定位到这些小集合,从而减少需要扫描的数据点的量,提高检索效率。
空间编码和转换法:空间编码和转换法,如 p-Stable LSH、PQ 等方法,将数据集重新编码或变换,映射到更小的数据空间,从而减少扫描的数据点的计算量。
- 邻居图法:邻居图法,如 HNSW、SPTAG、ONNG 等,通过预先建立关系图的方法,去加快检索时的收敛速度,减少需要扫描的数据点的量,以提高检索效率。
向量检索发展多年,并逐渐成为非结构化检索的主流方法,但仍存在了不少的技术挑战和问题。
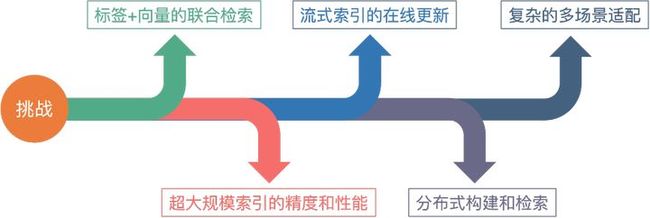
业务场景:标签+向量的联合检索
在大多数业务场景下,需要同时满足标签检索条件和相似性检索的要求,如查询某些属性条件组合下相似性的图片等,我们称这种检索为“带条件的向量检索”。
目前,业内采用多路归并的方式,即分别检索标签和向量再进行结果合并,虽可以解决部分问题,但多数情况下结果不甚理想。主要原因在于,向量检索无范围性,其目标是尽可能保证 TOPK 的准确性,TOPK 很大时,准确性容易下降,造成归并结果的不准确甚至为空的情况。

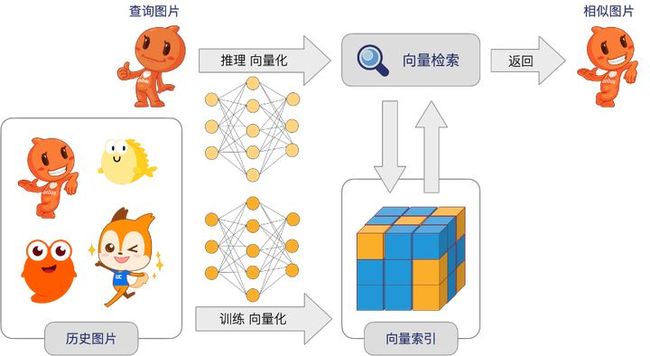
业务场景: 语音/图像/视频检索
以图片搜索为例,我们先以离线的方式对所有历史图片进行机器学习分析,将每一幅图片(或者图片里分割出来的人物)抽象成高维向量特征,然后将所有特征构建成高效的向量索引,当一个新查询(图片)来的时候,我们用同样的机器学习方法对其进行分析并产出一个表征向量,然后用这个向量在之前构建的向量索引中查找出最相似的结果,这样就完成了一次以图片内容为基础的图像检索。
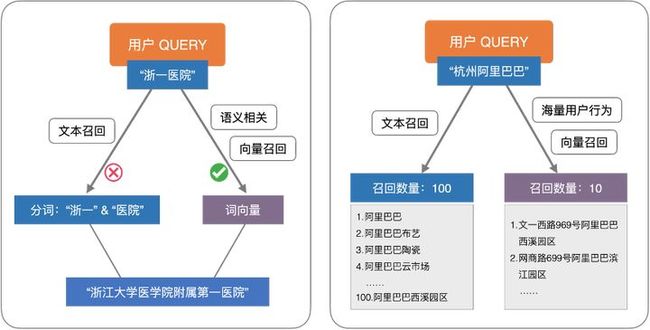
业务场景: 文本检索
地址查询,如果我们想在标准地址库中搜索“杭州阿里巴巴”的地址,在仅使用文本召回的时候,几乎没办法找到相似的结果,但是我们如果通过对海量用户的点击行为进行分析,将点击行为加上地址文本信息合并形成高维向量,这样在检索的时候就可以天然的将点击率高的地址召回并排列在前面。
业务场景: 搜索/推荐/广告
在电商领域的搜索/推荐/广告业务场景中,常见的需求是找到相似的同款商品和推荐给用户感兴趣的商品,这种需求绝大多数都是采用商品协同和用户协同的策略来完成的。
新一代的搜索推荐系统吸纳了深度学习的 Embedding 的能力, 通过诸如 Item-Item (i2i)、User-Item (u2i)、User-User-Item (u2u2i)、User2Item2Item (u2i2i) 等向量召回的方式实现快速检索。
算法工程师通过对商品的相似和相关关系,以及被浏览和被购买的用户行为的抽象,将它们表征成高维向量特征并存储在向量引擎中。这样,当我们需要找一个商品的相似商品(i2i)时,就可以高效快捷地从向量引擎中检索出来。