特征工程——七大特征处理的方法
以下举例采用的数据集为sklearn中自带的数据,因此在此提前进行读取数据,具体代码如下:
# 导入包
from sklearn.datasets import load_iris
# 获得数据
iris = load_iris()
iris.data运行结果如下:(因为数据过大,因此在此处只进行部分展示)
1. 标准化
标准化是依照特征矩阵的列处理数据,即通过求标准分数的方法,将特征转换为标准正态分布,并和整体样本分布相关。每一个样本点都能对标准化产生影响。
标准化需要计算特征的均值和标准差,公式如下:
![]()
例如,使用preprocrssing库的StandarScaler 类对iris数据集进行标准化,代码如下:
# 标准化,返回值为标准化后的数据
StandardScaler().fit_transform(iris.data)运行结果:
2. 区间缩放法
区间缩放法的思路有很多种,常见的一种是利用两个最值(最大值和最小值)进行缩放,公式如下:
![]()
例如,使用preprocessing库的MinMaxScaler类对iris数据集进行区间缩放,代码如下:
from sklearn.preprocessing import MinMaxScaler
# 区间缩放,返回值为缩放到[0,1]区间的数据
MinMaxScaler().fit_transform(iris.data)运行结果:
3. 归一化
归一化是将样本的特征值转换到同一量纲下,把数据映射到[0,1]或者[a,b]区间内,由于其仅由变量的极值决定,因此区间缩放法是一种归一化的方法。
归一区间会改变数据的原始距离、分布和信息,但标准化一般不会。
规则为L2的归一化公式如下:
![{x}' = \frac{x}{\sqrt{\sum_{j}^{m} {x[j]^2} }}](http://img.e-com-net.com/image/info8/504fb842c6ff4c1a9f377c3d1db6f31c.gif)
例如,使用preprocessing库里的Normalizer类对iris数据集进行归一化,代码如下:
from sklearn.preprocessing import Normalizer
# 归一化,返回值为归一化后的数据
Normalizer().fit_transform(iris.data)运行结果:
4.定量特征二值化
定量特征二值化的核心即为设定一个阈值,当大于这个阈值时就赋值为1,小于等于这个阈值时就赋值为0。公式如下:
![]()
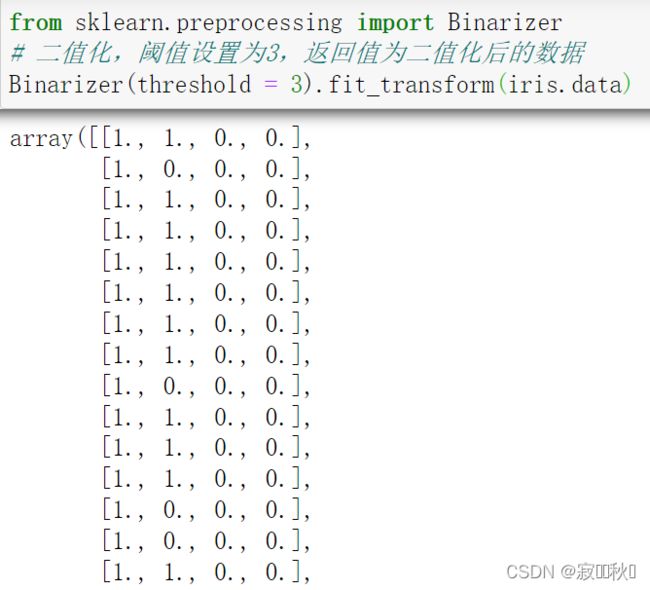
例如,使用preprocessing库里面的Binarizer类对iris数据集进行二值化,代码如下:
from sklearn.preprocessing import Binarizer
# 二值化,阈值设置为3,返回值为二值化后的数据
Binarizer(threshold = 3).fit_transform(iris.data)运行结果:
5.定性特征哑编码
太官方的语言就不说了,在这里就举一个例子:
假设,变量“职业”的取值分别为工人、农民、学生、企业职员、其他等5种选项。那么我们则可以将“工人”定义为(0, 0, 0, 1)、“农民”定义为(0, 0, 1, 0)、“学生”定义为(0, 1, 0, 0)、“企业职员”定义为(1, 0, 0, 0)。
这种方法在我们对数据进行预处理时是非常有用的,比如我们通常会将原始的多分类变量转换为哑变量,在构建回归模型时,每一个哑变量都能得到一个估计的回归系数,这样使得回归的结果更易于解释,也更具有实际意义。
例如,使用preprocessing库的OneHotEncoder类对iris数据集的进行哑编码,具体代码如下:
from sklearn.preprocessing import OneHotEncoder
# 对iris数据集的目标变量哑编码,返回值为哑编码后的数据
OneHotEncoder(categories = 'auto').fit_transform(iris.target.reshape((-1,1)))运行结果:

6. 缺失值处理
当数据中存在缺失值时,用Pandas读取后的特征均为NaN,表示数据缺失,即为数据未知。
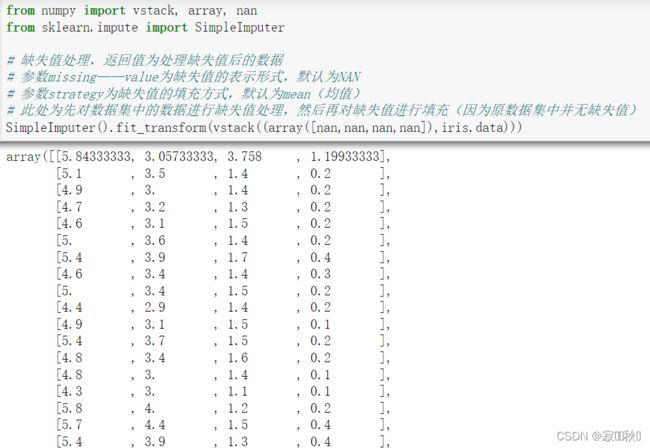
例如,在irsi数据集中加入几个空值NaN,然后使用impute库的SimpleImputer类对这个数数据集进行缺失值计算,代码如下:
from numpy import vstack, array, nan
from sklearn.impute import SimpleImputer
# 缺失值处理,返回值为处理缺失值后的数据
# 参数missing——value为缺失值的表示形式,默认为NAN
# 参数strategy为缺失值的填充方式,默认为mean(均值)
# 此处为先对数据集中的数据进行缺失值处理,然后再对缺失值进行填充(因为原数据集中并无缺失值)
SimpleImputer().fit_transform(vstack((array([nan,nan,nan,nan]),iris.data)))运行结果:
7. 数据转换
(1)多项式转换
4个特征,度为2的多项式转换公式为:
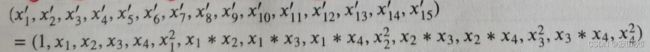
例如,使用preprocessing库的PloynomailFeatures类对iris数据集进行多项式转换,代码如下:
from sklearn.preprocessing import PolynomialFeatures
# 多项式转化
# 参数degree为度,默认值为2
PolynomialFeatures().fit_transform(iris.data)运行结果:

(2)对数变换
基于单变元函数的数据转换可以使一个统一的方法完成。
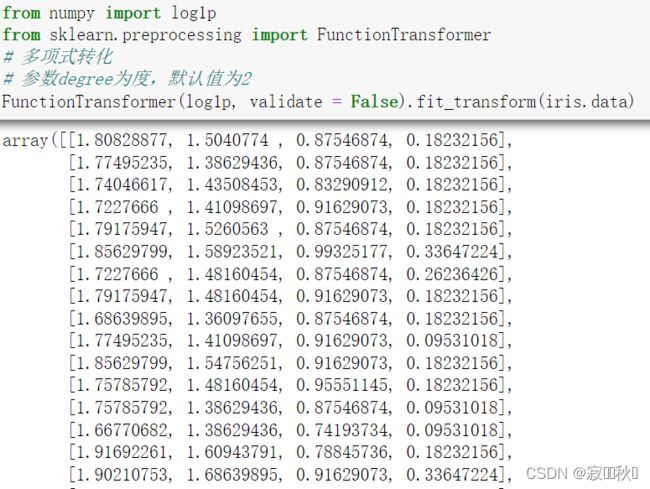
例如,使用preprocessing库的FunctionTransformer类对iris数据集进行对数转换,代码如下:
from numpy import log1p
from sklearn.preprocessing import FunctionTransformer
# 多项式转化
# 参数degree为度,默认值为2
FunctionTransformer(log1p, validate = False).fit_transform(iris.data)运行结果:
8.特征处理小结
此处对以上使用过的sklearn中的方法进行总结:
| 类 | 功能 | 说明 |
| StandardScaler | 无量纲化 | 标准化,基于特征矩阵的列,将特征值转换为服从标准正态分布 |
| MinMaxScaler | 无量纲化 | 区间缩放,基于最大值或最小值,将特征值转换到[0, 1]区间内 |
| Normalizer | 归一化 | 基于特征矩阵的行,将样本向量转换为单位向量 |
| Binarizer | 定量特征二值化 | 基于给定阈值,将定量特征按阈值划分 |
| OneHotEncoder | 定性特征哑编码 | 将定性特征编码为定量特征 |
| Imputer | 缺失值处理 | 计算缺失值,缺失值可填充为均值等 |
| PolynomialFeatures | 多项式数据转换 | 多项式数据转换 |
| FunctionTransformer | 自定义单元数据转换 | 使用单变元函数转换数据 |