【科研导向】Neural Collaborative Filtering 神经协同过滤 <论文理解&代码分析>
Neural Collaborative Filtering——WWW'17
- 文章简介
-
- 一.摘要解析
- 二.技术要点
- 三.实验部分
- 代码解析
-
- 一.模型构建
- 二.难点问题
- 未来展望
文章简介
该文由何向南教授团队于17年发表在IW3C2,其核心思想在于结合了传统矩阵分解的易用性与神经网络对用户项目交互的高维感知力来提高最终推荐的性能表现。
Keywords: 协同过滤//神经网络//深度学习//矩阵分解//隐式反馈
一.摘要解析
研究背景是当年深度学习在语音识别,计算机视觉和NLP方面已经取得了巨大成功。而在推荐系统的研究上,深度学习主要被用于模拟辅助信息,如项目的文本描述和音乐的声学特征等。在对协同过滤的关键因素——用户和项目特征之间的交互建模时,仍然采用矩阵分解的方式。
具体做法是通过可以从数据中学习任意函数的神经架构来替换内积,基于此提出了NCF的通用框架。在NCF的框架下泛化了矩阵分解GMF来建模线性表达,加入了多层感知机MLP来增强非线性建模。
二.技术要点
-
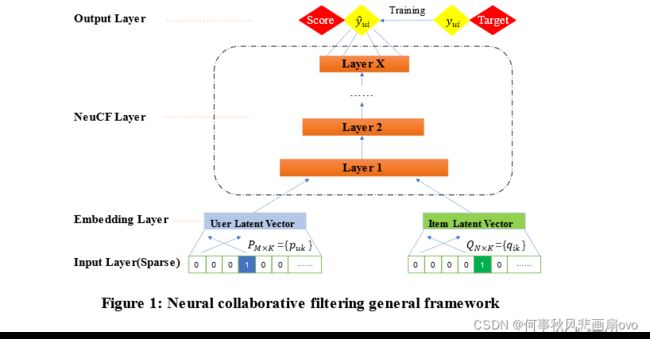
Learning from Implicit Data:从隐式反馈数据中学习用户和项目的交互,其交互矩阵Y=RM×N的构建如下图所示。
编码方式:one-hot
-
GMF:在众多协同过滤技术中,矩阵分解是最受欢迎的一种,它将用户和项目投影到共享的Latent space,使用潜在特征向量来表示用户或项目,而用户与项目的交互则被建模为其潜在向量的内积。而NCF解释了如何将MF作为其框架下的案例之一,并泛化为GMF。核心参数:number_factors即向量表示的因子数
-
MLP:标准的多层感知机,对于网络结构其采用的常见的塔式结构(底层最宽,往上递减),在这里我们可自定义网络的层数以应对不同场景的需求。由于神经网络的特性,MLP在建模非线性表达时具体显著优势,可作为GMF很好的补充。核心参数:number_layers即网络层数与因子数
-
NCF(GMF&MLP):在基础模型构建完成之后,如何融合此二者则变成一个非常重要的问题,这将直接影响模型的性能。在这个问题的处理上,作者同样做了多种尝试,最终考虑到共享GMF和MLP的嵌入可能会限制融合模型的性能(即两个模型对某个数据集的最佳batch_size变化很大),于是采用二者分别学习嵌入,并通过连接二者最后一个隐藏层来组合这两个模型。详见下图:
三.实验部分
实验部分主要回答三个问题:
- NCF与最新的基于隐式反馈的协同过滤方法相比表现如何?
of cause better - 所提出的优化框架(log loss with negative sampling)如何作用于推荐任务?
3~6左右的采样率可以很好的提升方法性能 - 更深层的隐藏单元是否有助于更好的学习用户-项目交互?
实验数据表明在0-4层中,4层的结果最优
实验设置
数据集:MovieLens & Pinterest
预训练:通过两个模型单独学习得到的参数作为NCF初始化参数
评估方法: 该模型采用leave-1-out评估,其中评价指标为HitRate & NDCG //可以理解为命中率和排名靠前率//
基准方法:ItemPop & ItemKNN & BPR & eALS
通过实验验证,表明了进行个性化推荐的必要性以及同时结合线性与非线性模型的先进性。
代码解析
源代码:Neural Collabrative Filtering
该模型基于Pyhon2 & Theano/Keras构建,部分包可能无法从官网获取,需要从Github or Google下载。而且,其中部分代码可能因环境差异导致无法解析,进而影响程序运行。下面我将以伪代码展示出来,并以框架的形式将模型复现,包括对部分源代码的修改。
一.模型构建
Load data
# Series of loaddata functions
def load_negative_file(self, filename):
return negativeList
def load_raing_file_as_list(self, filename):
return ratingList
def load_raing_file_as_matrix(self, filename):
return uimatrix
GMF Part
def get_model(num_users, num_items, latent_dim, regs=[0, 0]):
# para: 用户数,项目数,映射维度
···
predict_vector = merge([user_latent, item_latent], mode = 'mul')
# 以element-wise multiply的形式表达user-item交互
return model
def get_train_instances(train, num_negative):
# para: 训练矩阵,负采样数
···
for (u, i) in train.keys():
user_input / item_input.append(u / i)
labels.append(1)
for t in xrange(num_negative):
j = random(num_items)
# while train.has_key((u, j)) 该行为源码,运行报错
while (u, i) in train: # 此行为修改后可运行的代码
j = random(num_items)
user_input / item_input.append(u / i)
labels.append(0)
return user_input, item_input, labels
MLP Part
def get_model(num_users, num_items, layers=None, reg_layers=None):
# para: 用户数,项目数,网络层数[32, 16, 8](3层)
···
vector = merge([user_latent, item_latent], mode='concat')
# vector = user + item 两个向量直接拼接
for idx in range(1, num_layer=len(layers)):
layer = Dense(···) # 优化器l2,激活函数relu
vector = layer(vector)
prediction = Dense(1, ···)(vector) # 激活函数sigmoid
return model
def get_train_instances(train, num_negative):
# same with upper
NeuMF Part
def get_model(num_users, num_items, mf_dim=8, layers=None, reg_mf =0, reg_layers=None):
···
# MF part: element-wise multiply
mf_vector = merge([mf_user_latent, mf_item_latent], mode='mul')
# MLP part: same with upper
mlp_vector = merge([mlp_user_latent, mlp_item_latent], mode='concat')
for idx in range(1, num_layer):
layer = Dense(layers[idx],···) # 优化器l2,激活函数relu
mlp_vector = layer(mlp_vector)
# Concatenate
# 此处并非简单的将二者结果连接,而是将二者的预测因子拼接后,再经过一次Dense层
predict_vector = merge([mf_vector, mlp_vector], mode='concat')
prediction = Dense(1,···)(predict_vector) # 激活函数sigmoid
return model
def get_train_instances(train, num_negative):
# same with upper
二.难点问题
从文章内容来说,其重点在于理解MF是如何被解释为GMF的一种特例以及两模型融合时采用的策略延展到代码中是如何表现的。文章的思想在于将传统方法与深度学习相结合,既保证其原理性又能借助深度学习提高其非线性的模型表达。
从代码部分来说,查阅多方资料后并修改源代码后,复现NCF模型难度不大。但是该模型相对较老旧,许多包和配置无法直接安装。虽然Python2版本下部分语法的差异性影响了代码可读性,不过代码整体逻辑严密,函数封装合理,结合文章叙述去理解代码相对顺利。
未来展望
作者所期望的是将NCF拓展到对辅助信息建模,如用户评论/知识库/时间信号等。而我在商品推荐的场景下,考虑项目类别信息建模,得益于推荐类别的高精度,利用数据中的类别属性单独建模用户-项目类别,然后在被推荐类别的项目中继续做项目推荐。此举可以在一定程度上缓解u-i矩阵的稀疏度,并提高模型表现。