【论文阅读】开放域问答论文总结,文本召回与问答的另一种思路
【论文总结】开放域问答,纯文本召回与精排的另一种思路
- 前言
- SCIVER: Verifying Scientific Claims with Evidence
-
- 任务介绍
- 数据样例
- 开放域问答
- Reading Wikipedia to Answer Open-Domain Questions (2017)
-
- Document Retriever
- Document Reader
- 个人总结
- Dense Passage Retrieval for Open-Domain Question Answering (2020)
-
- Encoders
- Training
- End-to-end QA System
- 个人总结
- Leveraging Passage Retrieval with Generative Models for Open Domain Question Answering (2020)
-
- Encoder
- Decoder
- result
- 个人总结
- DISTILLING KNOWLEDGE FROM READER TO RETRIEVER FOR QUESTION ANSWERING (2021)
-
- Reader
- CROSS-ATTENTION SCORE
- Retriever
- Training
- Result
- 个人总结
- 题外话
前言
这篇文章是年前欠下来的,当时在选择比赛的项目时,SDP @NAACL 的第二项任务SCIVER: Verifying Scientific Claims with Evidence,和开放域问答系统类型非常相似,因此调研了一些开放域问答的经典文献和SOTA方法,在这里做一个总结。通过这4篇论文,可以对开放域问答任务的研究方向有一个基本的了解,从统计特征到可训练特征再到无样本学习,从span抽取到直接生成。
涉及论文:
- Reading Wikipedia to Answer Open-Domain Questions
- Dense Passage Retrieval for Open-Domain Question Answering
- Leveraging Passage Retrieval with Generative Models for Open Domain Question Answering
- DISTILLING KNOWLEDGE FROM READER TO RETRIEVER FOR QUESTION ANSWERING

SCIVER: Verifying Scientific Claims with Evidence
任务介绍
Due to the rapid growth in scientific literature, it is difficult for scientists to stay up-to-date on the latest findings. This challenge is especially acute during pandemics due to the risk of making decisions based on outdated or incomplete information. There is a need for AI systems that can help scientists with information overload and support scientific fact checking and evidence synthesis.
在SCIVER共享任务中,我们将构建以下形式的系统:
- 以科学主张为输入
- 识别大型语料库中的所有相关摘要
- 将其标记为支持或驳回
- 选择句子作为标签的证据
关键步骤
- 识别大型语料库中的相关:考虑到效率和运行时间的要求,当我们得到一个query (此处为科学主张)后我们无法将大型语料库中成千上万的句子分别做一次分类识别,因此我们需要现根据query对语料库中相关的文档进行召回,尽可能减少我们的候选集。
- 选择句子作为标签的证据:对少量候选集中的文档中的句子进行精细分类,来判断其时候可用以支持或驳回主张。
数据样例
{
"id": 52,
"claim": "ALDH1 expression is associated with poorer prognosis for breast cancer primary tumors.",
"evidence": {
"11": [ // 2 evidence sets in document 11 support the claim.
{"sentences": [0, 1], // Sentences 0 and 1, taken together, support the claim.
"label": "SUPPORT"},
{"sentences": [11], // Sentence 11, on its own, supports the claim.
"label": "SUPPORT"}
],
"15": [ // A single evidence set in document 15 supports the claim.
{"sentences": [4],
"label": "SUPPORT"}
]
},
"cited_doc_ids": [11, 15]
}
开放域问答
上述任务其实是NLP中经典问题:开放域问答的变体,开放域问答以wikipedia知识回答为例,其思路分两个步骤,1. 首先从大量的文章里检索出相关的文章,2. 从相关的文章里定位到答案。
解决该类问题的关键是如何设计一个高效的召回系统,以及如何从召回少量候选集中精准锁定关键句子。
Reading Wikipedia to Answer Open-Domain Questions (2017)
作为开放域问答的经典论文,Danqi Chen提出的DrQA,搭建了开放域问答解决系统的基本框架:
(1) the Document Retriever module for finding relevant articles and
(2) a machine comprehension model, Document Reader, for extracting answers from a single document or a small collection of documents.
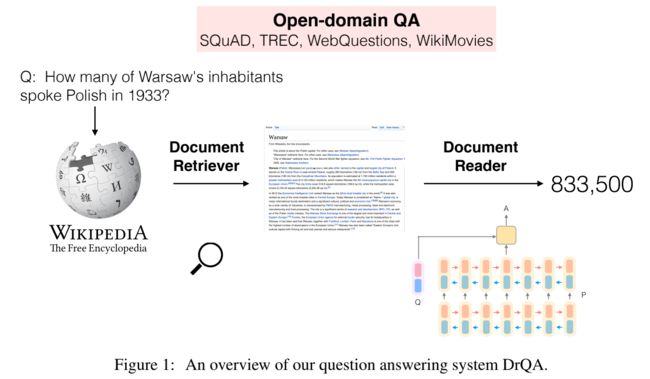
Document Retriever
- TF-IDF: 通过构建问题和文档的TF-IDF特征向量,计算两者的相似度来作为召回标准。为了提高召回的速度和内存效率,n-grams词组往往包含更多的词语顺序信息,作为召回特征也更加明确。因此作者通过Murmur Hash3将bigrams映射到 2^24 桶中, 以此提高检索效率。
- 具体实现上,每次召回5篇最相关的维基百科文档交给Document Reader处理。
- 此外,作者还比较了Okapi BM25、 word embeddings space + 余弦相似度等方式构建问题和文章召回特征的方式,结果表现更差。
- 召回实验结果:

Document Reader
- Paragraph encoding: p 1 , . . . , p m = R N N ( p ˜ 1 , . . . , p ˜ m ) {p1, . . . , pm} = RNN({p˜1, . . . , p˜m}) p1,...,pm=RNN(p˜1,...,p˜m),通过BiLSTM对召回文档的段落进行encoding,pi为作为BiLSTM的前后隐藏单元的concat输出。p˜i为构建的输入token的特征,具体如下:
- Word embeddings: 300-dimensional Glove word embeddings trained from 840B Web crawl data. 作者固定了词向量的embedding在模型训练时只fine-tune前1000高频的词向量,原因在于认为像what, how, which 这种高频的提问词可能对于QA systems来说更加关键。
- Exact match: 作者使用了01向量的embedding来标记段落中的哪些词是与问题完全匹配的,并在后续实验中证明了这个特征的有效性。
- Token features: 添加了 Token的part-of-speech (POS) and named entity recognition (NER) tags and its (normalized) term frequency (TF).等人工特征。
- Aligned question embedding: 在每个输入token中融合该token与question的attention特征,具体实现如下: f ( p i ) = ∑ j a i j 2 E ( q j ) f(pi) = \sum_{j}a_{ij}^2E(q_j) f(pi)=∑jaij2E(qj) 其中: a i j = e x p ( α ( E ( p i ) ) ⋅ α ( E ( q j ) ) ) ∑ j ′ e x p ( α ( E ( p i ) ) ⋅ α ( E ( q j ′ ) ) ) a_{ij} =\frac{exp (α(E(p_i)) · α(E(q_j )))} {\sum_{j'}exp (α(E(p_i)) · α(E(q_j' )))} aij=∑j′exp(α(E(pi))⋅α(E(qj′)))exp(α(E(pi))⋅α(E(qj))) , E ( q j ) E(q_j) E(qj)是question每个token的embedding, E ( p i ) E(p_i) E(pi)是段落中每个token的embedding,α(·) 是单个dense层接非线性激活函数Relu。与Exact match这一特征不同是,Aligned question embedding可以捕获到段落token与问题token中的近义词/词义关系,如(e.g., car and vehicle).
- Question encoding:question的encoding较为简单,通过简单的循环神经网络提取 Question token 的embedding特征使用单一向量作为question feature q 1 , . . . , q l → q . {q1, . . . , ql} → q. q1,...,ql→q.
q = ∑ j b j q j q = \sum_{j}b_jq_j q=∑jbjqj 其中: b j = e x p ( w ⋅ q j ) ∑ j e x p ( w ⋅ q j ′ ) bj =\frac{exp(w · q_j)}{ \sum_{j}exp(w · q_j')} bj=∑jexp(w⋅qj′)exp(w⋅qj) w为需要学习的参数。相当于让模型学习如何将question中的token embedding根据在question中的重要性进行加权平均。 - 训练阶段,将上述得到的Paragraph vector {p1, . . . , pm} 和 question vector作为输入,对每个Paragraph token的最后output结合question vector作coress-attention后进行两次二分类,来判断其是否为答案的起点或终点。 P s t a r t ( i ) ∝ e x p ( p i W s q ) Pstart(i) ∝ exp (p_iW_sq) Pstart(i)∝exp(piWsq) P e n d ( i ) ∝ e x p ( p i W e q ) Pend(i) ∝ exp (p_iW_eq) Pend(i)∝exp(piWeq)
- 推理阶段,我们考虑所有长度<=15的span, s c o r e = P s t a r t ( i ) × P e n d ( i ′ ) score = Pstart(i)×Pend(i') score=Pstart(i)×Pend(i′),并且考虑到分数在多个段落之间比较的兼容性,作者使用非归一化指数,并在所有可能的span中使用argmax进行最终预测。
- reader实验结果:

个人总结
- DrQA的Retriever突出简单的特性,使用TF-IDF捕捉bigram统计特征,不需要经过训练,只需要预先计算好每篇文档的特征向量即可进行快速检索,但这也带来了一定的问题,简单的词频统计特征无法捕捉到潜在语意上的相关性,不好解决棘手的抽象问题。尽管这种方式具有良好的泛化能力,但是针对特定领域的QA召回,我们仍然通过训练模型,来增强召回性能。
- Reader部分,2017还是传统神经网络的时代,encoding部分使用了简单的bilstm,因此为了更加丰富的表达token的信息和其与问题的关联性信息等,我们需要制作大量额外的人工特征。
- 但这并不影响DrQA给后续开放领域问答研究带来的Retriever + Reader重要的框架思路。
Dense Passage Retrieval for Open-Domain Question Answering (2020)
Danqi Chen卷土重来!文章通过引入Bert等预训练语言模型,在QA系统的Retriever部分大作文章,构建的DPR召回系统针对训练Retriever模型提出了精妙的负采样设计和训练方法。极大程度地提升了开放领域问答文档召回部分的准确性。Dense Passage Retrieval用可训练的embedding低维连续的稠密向量代替了原本TF-IDF等稀疏向量表示。
Encoders
- 通过两个独立的bert分别编码question和passage,以bert最后一层CLS输出768纬特征作为向量表示,通过计算两者之间的点积作为相关性评价: s i m ( q , p ) = E Q ( q ) T E P ( p ) sim(q, p) = E_Q(q)^TE_P (p) sim(q,p)=EQ(q)TEP(p),这一方法与本人之前复现的Sentence-BERT极为相似,当模型训练完成后,我们可以通过提取所有语料库中的passage的特征向量并通过FAISS保存来加快query的查询速度,在博客末尾也提及了使用两个独立的bert分别编码的思考点所在。
Training
- 模型训练阶段:对于每一个匹配的QP训练样本,我们设置 q i , p i + , p 1 − , p 2 − , p n − q_i,p_i^+,p_1^-,p_2^-,p_n^- qi,pi+,p1−,p2−,pn−,其中包括一个正passage样本和n个负passage样本。损失函数如下:
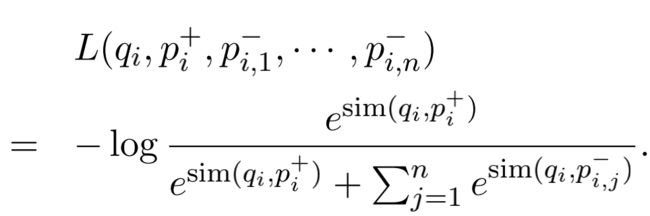
- 负采样:对于每一组训练样本的构建,正样本是给定的,重点在于如何进行负采样选择合适的负样本,太简单的负样本会使Retriever训练不充分而导致欠拟合,召回效果差。在一般的推荐系统当中,我们会倾向于同时设置hard样本和soft样本来丰富模型的召回能力。本文中,作者考虑了三种类型的负样本,并对不同组合进行了测试:
- Random: any random passage from the corpus;
- BM25: top passages returned by BM25 which don’t contain the answer but match most question tokens;
- Gold: positive passages paired with other questions which appear in the training set.
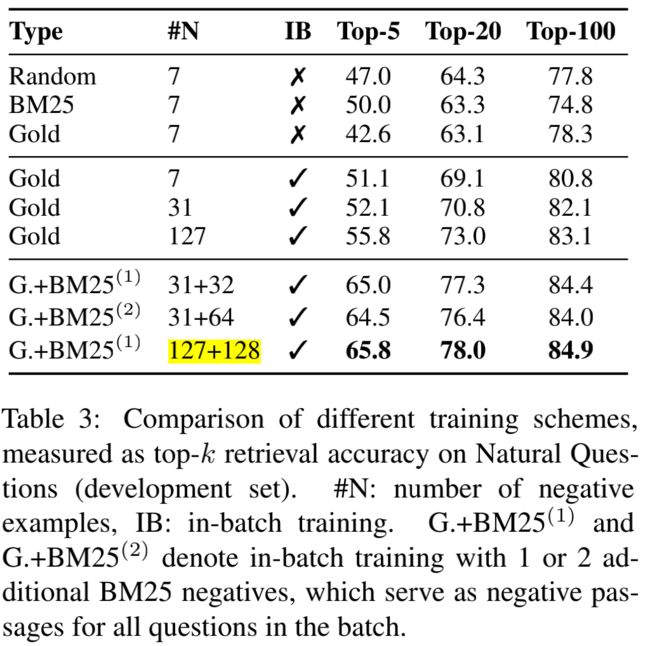
- In-batch negatives: batch negatives的方法大家应该不陌生,简单来说就是通过batch内的样本互为negatives来加快模型训练效率。如果不使用该方法,我们需要预先生成m组正样本+mn组负样本,由于mn的存在使得模型的训练效率降低,如果形成batch negatives,在batch中模型只需要对每一个样本进行一次正向传播,即可同时完成所有正负样本的loss计算。具体来说我们传入一个batch 一共B组QP对,通过一次正向传播加矩阵乘积我们可以得到 S = Q P T S = QP^T S=QPT 一个 ( B × B ) (B×B) (B×B) 相关性矩阵每一行代表一个Question和Passage的相关性得分,对于每一个Question来说,包含1个正样本,B-1个负样本。效率上通过B计算复杂度得到了B^2的样本对效果,并且省去了前期样本构建的工作。
- 理解了In-batch negatives的方法上述结果图也会比较好理解,最好的样本构建方法为为每一个question构建一个positive passage和一个BM25最大的negative passage,设置batch_size=128,因此对于每一个question来说最终会有127个Gold negative passage和128个BM25 negative passage作为负样本。
- It has been shown to be an effective strategy for learning a dual-encoder model that boosts the number of training example。

- Term-matching methods like BM25 are sensitive to highly selective keywords and phrases, while DPR captures lexical variations or semantic relationships better. 考虑到两种召回模式的优势,作者尝试了模型融合,其中BM25 + DPR为BM25和DPR的召回结果的融合, u n i o n S c o r e = B M 25 ( q , p ) + 1.1 ∗ s i m ( q , p ) unionScore = BM25(q,p) + 1.1 * sim(q, p) unionScore=BM25(q,p)+1.1∗sim(q,p)
End-to-end QA System
- The passage selection model serves as a reranker through crossattention between the question and the passage。答案选择模型作为精排模型服务于召回模型召回的文章。
- Reader模型的设计其实较为多样,文章并没有展开详细讨论,在Bert框架下可以通过第一篇文章中的cross-attention来联系question和候选的passage的特征信息,也可以参考本人之前复现的机器阅读理解baseline进行设计。
- 具体的文章设置了span首尾评估和passage selected组合评估指标:
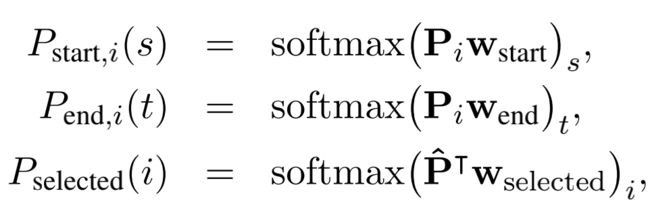
- 其中 P i ∈ R L × h ( 1 ≤ i ≤ k ) Pi ∈ R^{L×h} (1 ≤ i ≤ k) Pi∈RL×h(1≤i≤k) 是每篇文章的bert最外层特征向量, P ˆ = [ P 1 [ C L S ] , . . . , P k [ C L S ] ] ∈ R h × k Pˆ=[P^{[CLS]}_1, . . . , P^{[CLS]}_k ] ∈R^{h×k} Pˆ=[P1[CLS],...,Pk[CLS]]∈Rh×k w s t a r t w_{start} wstart, w e n d w_{end} wend, w s e l e c t e d w_{selected} wselected 是需要学习的参数。
P s t a r t , i ( s ) × P e n d , i ( t ) P_{start,i}(s) × P_{end,i}(t) Pstart,i(s)×Pend,i(t)表示该span的得分,而 P s e l e c t e d ( i ) P_{selected}(i) Pselected(i)表示该文章的得分。 - 对于每一组正样本,从前100名Retriever召回的Passage中随机选择23个负样本进行训练。

个人总结
- 对比DrQA的Retriever,DPR更加关心question与passage之间的潜在语意关系,并通过融合BM25和DPR,在文本召回的准确性上远远超过传统的统计特征模型。
- 合理的负采样方法配合In-batch negatives训练方法,确保模型能有效区别正负样本的同时,提高了模型的计算与训练效率,设计巧妙但又易于实现。
- 对于文本召回相关任务来说,DPR是一个简洁且巧妙的baseline。
Leveraging Passage Retrieval with Generative Models for Open Domain Question Answering (2020)
之前开放域问答系统的Reader部分的设计,往往是对Retriever召回的文档进行再次精排,通过span分类任务抽取相应的answer,在一步中如何处理和比较不同文档之间的span预测是一个难题,而且按token进行二分类任务存在棘手的正负类别不平衡问题。如何能让模型同时考虑所有召回文本,并且自己学会识别答案,如图所示该论文提出了Fusion-in-Decoder模型将Reader的工作从分类变成了Seq2seq。
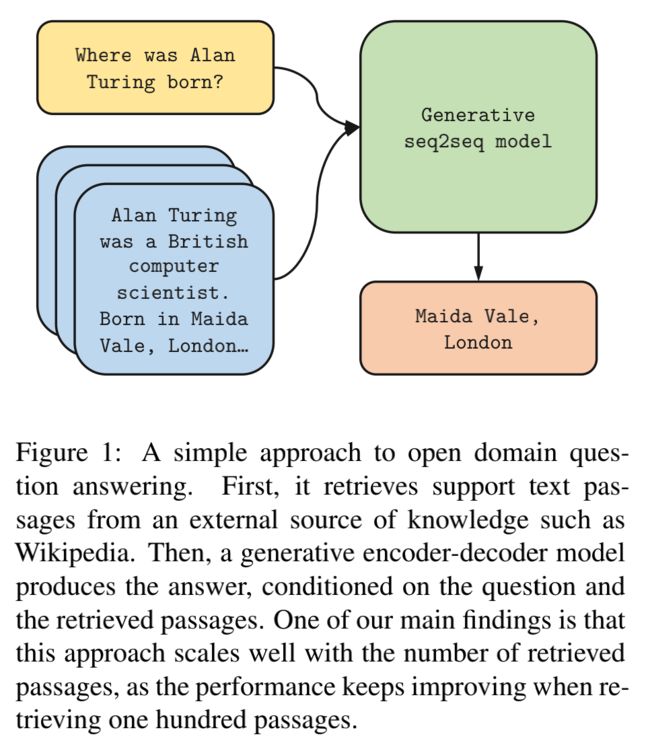
Encoder
- Reader是一个sequence-to-sequence的网络结构, 使用了T5或者Bart等预训练模型。
- 对于每一个Retriever召回的Passage,将Question与Passage通过特殊的Token连接构建成[ q u e s t i o n : question: question:, t i t l e : title: title:, c o n t e x t : context: context:] 的格式,分别通过encoder编码成一个全局特征矩阵 X ∈ ( ∑ k l k ) ∗ d X ∈(\sum_{k}l_k)*d X∈(∑klk)∗d 其中 l k l_k lk 是第k个召回Passage输入长度,d 为encoder的hidden dimension。
- 之后Decoder处理特征X,通过自回归输出答案A。
Decoder
- 与传统的transformer的decoder相似,每一个block中先做一次输出的self-attention,之后的通过 Q = W Q H , K = W K X , V = W V X Q = W_QH, K = W_KX, V = W_VX Q=WQH,K=WKX,V=WVX来计算cross-attention,具体计算公式与transformers一致,不再展开叙述。其中X为encoder输出的最后的特征表示,H为decoder中上一个self-attention的输出。
result

- 随着encoder输入的召回文章数量的提高,decoder的输出与答案的match程度也随之升高,在50左右达到较高平稳峰值,这说明Fusion-in-Decoder能有效的结合来自多个Passage的信息。

- 模型在开放域问答公开数据集上达到了SOTA,这也证明了用Seq2seq的方式来生成答案是一个有效的方法。
个人总结
- 没错,就是这么简单,就是这么一个颠覆性的认知加上一个小小的改动,Fusion-in-Decoder可以说是完全套用了transfomers的模型结构,在对Retriever召回的Passage的处理上采取了如此暴力美学的方法,直接全部encode然后concat在一起丢到decoer里面让模型去学。简单,粗暴,有效。
- 个人比较好奇的是这个方法在Train的时候encoder是跟着一起train的吗,还是freeze的。个人理解应该是freeze的。
DISTILLING KNOWLEDGE FROM READER TO RETRIEVER FOR QUESTION ANSWERING (2021)
开放域问答系统中的Retriever的训练,往往是有监督的,这需要我们为模型提供大量的样本数据,这篇文章利用知识蒸馏的技术,让Retriever去学习Reader的attention score,这样的方法并不需要标注好的query和documents对。
Reader
- Reader部分直接沿用了Fusion-in-Decoder模型,通过Fusion-in-Decoder模型检索候选文章输出答案时产生的attention矩阵来指导Retriever进行学习。
- 这其实是一件非常直觉又有趣的事情,Retriever本应该作为Reader的老师,告诉Reader应该看哪些文章,并从中得出答案。但相反,由于Reader已经提前知道了答案,如果Reader阅读范围足够广,我们可以通过attention矩阵来映射Reader在生成答案时把注意力放在了哪些文章上,并以此告诫Retriever,下次召回时应该召回类似的文章。
CROSS-ATTENTION SCORE
- 根据Fusion-in-Decoder论文提到的,decoder中的cross-attention计算公式如下: Q = W Q H , K = W K X , V = W V X Q = W_QH, K = W_KX, V = W_VX Q=WQH,K=WKX,V=WVX
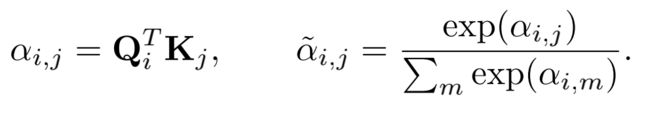

- 作者假设 α : , j α_{:,j} α:,j可以用来度量第 j 个key token对于模型通过value计算下一个特征表示的重要性,并以此作为与该key token对应文档的重要性的代表——the more the tokens in a text segment are attended to, the more relevant the text segment is to answer the question.
- 因此通过对attention score进行聚合,我们可以得到各个Passage的相关性分数 ( G q , p k ) 1 ≤ k ≤ n (G_{q,pk})1≤k≤n (Gq,pk)1≤k≤n,具体来说分数G是聚合了decoder中该文档所有key token的pre-attention scores α 0 , : α_{0,:} α0,:得到的。作者比较了不同的mean_max和选取不同层attention score的聚合方法。最后表面简单的对所有层,所有token的attention score作平均效果最佳。

- 作者通过一个简单的实验证明了 G q , p k G_{q,pk} Gq,pk是一个优秀的Passage相关性的评估指标:100篇由DPR召回的文档,使用DPR分数选择前10篇,召回性能从48.2EM降低到了42.9EM,但如果根据 G q , p k G_{q,pk} Gq,pk选择前10篇最重要的文档,召回性能仅从48.2EM降低到了46.8EM。
Retriever
- Retriever的模型结构设计与DPR相似,只是将两个独立的Bert编码器减少到了一个共享参数的特征编码器。
- 损失函数的设计上,由于Retriever不再是拟合一个二分类问题,而是拟合Reader产生的注意力分布,因此需要最小化 S θ ( q , p ) S_θ(q, p) Sθ(q,p)与 G q , p G_{q,p} Gq,p之间的KL离散:

- 同时作者还比较了MSE、max-margin loss等其他损失函数,最终KL离散的训练效果最佳。
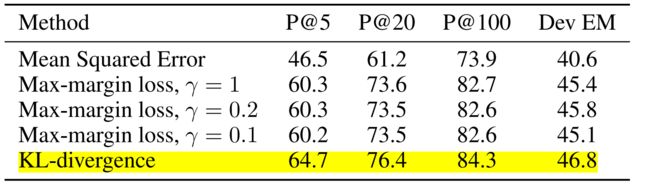
Training
- iterative pipeline:
- Train the reader R using the set of support documents for each question D q 0 D^0_q Dq0 .
- Compute aggregated attention scores ( G q , p ) q ∈ Q , p ∈ D q 0 (G_{q,p})_{q∈Q,p∈D^0_q} (Gq,p)q∈Q,p∈Dq0 with the reader R.
- Train the retriever E using the scores ( G q , p ) q ∈ Q , p ∈ D q 0 (G_{q,p})_{q∈Q,p∈D^0_q} (Gq,p)q∈Q,p∈Dq0.
- Retrieve top-passages with the new trained retriever E.
- 文章使用了Bert作为retriever,T5作为reader。
- 之所以这一套QA循环训练系统不需要给到retriever E标注好的数据对,是因为在训练过程中我们只需要初始化好最开始的support documents集合,通过对R的训练指导E的下一步的召回,即可实现自我迭代。
- 关键点1: 如何初始化support documents,实验表明,通过BM25初始化每一个Question的support documents优于通过预训练的Bert进行相似度计算进行初始化。并且我们可以发现尽管通过预训练的Bert进行初始化召回,在未开始跌倒时文档的召回效率巨差无比,但随着迭代的进行retriever的召回能力快速回温,这也证明了这一套iterative pipeline的有效性。

- 关键点2: 每轮迭代开始时,重新初始化reader-T5的权重,并保留retriever-Bert的权重继续训练。文章并没有对这样的做法做出解释,猜测有两个作用:
- reader-T5的训练相对于retriever-Bert来说更加容易,尽管我们初始化了reader-T5,但由于retriever-Bert的性能越来越强,召回的文章越来越准确,reader-T5也会更快的收敛,这一定程度上平衡了两个模块的训练进程,防止一方陷入过拟合后导致系统崩溃。
- 通过初始化reader-T5,文章通过监控reader-T5和retriever-Bert的注意力/打分对文章排名的差异性来监控retriever-Bert的训练进程,当reader-T5和retriever-Bert对文章排名结果相近且稳定时,认为系统已经训练充分,停止迭代。
Result
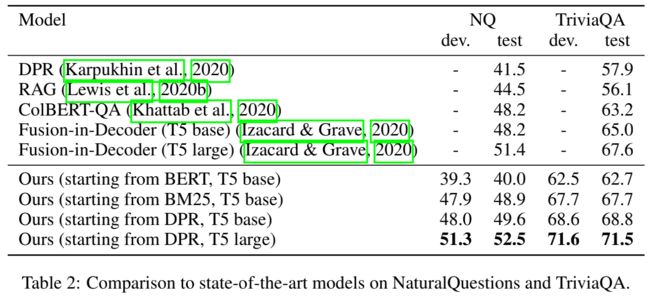
- 通过BM25初始化召回达到了SOTA,通过DPR初始化召回则得到了更高的性能。
- 证明了不需要大量有监督的文档数据我们也可以训练一个非常强大的retriever模型。
个人总结
- 本论文仅使用问题答案样本对就实现了开放域问答的SOTA,这归功于其精彩蒸馏思路将原本两个独立的训练模块Reader和Retriever进行连接,Pipeline的思路减少了模块之间的误差传递,使得整个系统更加一体化。并且文章对于损失函数、初始化方法、attention score的进行了大量的对比实验,组合出了一套完整的训练方案。
- 如果我们把Reader视为精排,Retriever视为召回,这种通过精排模块指导召回模块训练的方法非常值得借鉴。
- 本文从侧面反映了Transformer架构中,attention机制的可解释性,利用模型的attention模块的中间输出,我们可以获取更多其他的有效信息。
题外话
- DISTILLING KNOWLEDGE FROM READER TO RETRIEVER FOR QUESTION ANSWERING这篇文章的方法可拓展性强吗?由于其Reader模块采用的是Seq2Seq结构配合问答,是否存在特殊性?适用于其他的召回 + X 系统吗(排序/打分等)
- 其实最近也比较流行用NLG完成NLU任务的论文,All NLP Tasks Are Generation Tasks: A General Pretraining Framework,GPT Understands, Too等。这种召回+生成框架迁移的根本难点在于我们如何针对不同的任务类型进行设计不同的“Decoder”。值得研究~