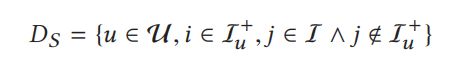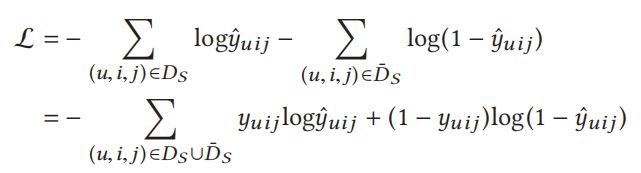基于深度学习的线上问诊系统设计与实现(Python+Django+MySQL)
神经网络15044
深度学习算法神经网络python深度学习django机器学习人工智能算法目标检测
基于深度学习的线上问诊系统设计与实现(Python+Django+MySQL)一、系统概述本系统结合YOLOv8目标检测和ResNet50图像分类算法,构建了一个智能线上问诊平台。系统支持用户上传医学影像(皮肤照片/X光片),自动分析并生成诊断报告,同时提供医生审核功能。二、技术栈后端框架:Django4.2数据库:MySQL8.0深度学习:YOLOv8:皮肤病变区域检测ResNet50:肺炎X光
Java线程与线程池详解
谁他个天昏地暗
Javapythonjava开发语言
一、Java线程基础1.线程创建方式Java中创建线程主要有三种方式://方式1:继承Thread类classMyThreadextendsThread{@Overridepublicvoidrun(){System.out.println("Threadrunning");}}//方式2:实现Runnable接口classMyRunnableimplementsRunnable{@Overrid
深度学习中常见激活函数总结
向左转, 向右走ˉ
深度学习人工智能pytorchpython
以下是一份深度学习激活函数的系统总结,涵盖定义、类型、作用、应用及选择影响,便于你快速掌握核心知识:一、激活函数的定义在神经网络中,激活函数(ActivationFunction)是神经元计算输出的非线性变换函数,作用于加权输入和偏置之和:输出=f(加权和+偏置)核心价值:引入非线性,使神经网络能够拟合任意复杂函数(无激活函数的深度网络等价于单层线性模型)。二、常见激活函数类型1.线性函数(Lin
【Linux】定时任务 Crontab 与时间同步服务器
敖云岚
linux运维服务器
目录一、用户定时任务的创建与使用1.1用户定时任务的使用技巧1.2管理员对用户定时任务的管理1.3用户黑白名单的管理一、用户定时任务的创建与使用1.1用户定时任务的使用技巧第一步:查看服务基本信息systemctlstatuscrond.service//查看周期性计划任务的服务状态,runningsystemctlenable--nowcrond//设置周期性计划任务crond为开机自启动,并且
Linux系统简介
strive颖先生
操作系统(OperatingSystem,简称OS):软件和硬件资源的管理者,他是宇宙中最复杂的软件,对下管理各种硬件,对上为应用程序的运行提供一个平台。主流操作系统PC:Windows,osx,Linux服务器(Server):Unix/Linux,WindowsServer,OSX嵌入式设备(EmbeddedDevice):Linxu,Android,VxWorks,ios,winCE,win
FP16、BF16、INT8、INT4精度模型加载所需显存以及硬件适配的分析
herosunly
大模型精度BF16硬件适配
大家好,我是herosunly。985院校硕士毕业,现担任算法研究员一职,热衷于机器学习算法研究与应用。曾获得阿里云天池比赛第一名,CCF比赛第二名,科大讯飞比赛第三名。拥有多项发明专利。对机器学习和深度学习拥有自己独到的见解。曾经辅导过若干个非计算机专业的学生进入到算法行业就业。希望和大家一起成长进步。 本文主要介绍了FP16、INT8、INT4精度模型加载占用显存大小的分析,希望对学习大
智能办公与科研革命:ChatGPT+DeepSeek大模型在论文撰写、数据分析与AI建模中的实践指南
jwwkyjspt
机器学习SCI论文人工智能chatgpt语言模型机器学习
随着人工智能技术的快速发展,大语言模型如ChatGPT和DeepSeek在科研领域的应用正在为科研人员提供强大的支持。这些模型通过深度学习和大规模语料库训练,能够帮助科研人员高效地筛选文献、生成论文内容、进行数据分析和优化机器学习模型。ChatGPT和DeepSeek能够快速理解和生成复杂的语言,帮助研究人员在撰写论文时提高效率,不仅生成高质量的文章内容,还能优化论文结构和语言表达。在数据分析方面
Leetcode 239. 滑动窗口最大值(单调队列解法)
题目:给你一个整数数组nums,有一个大小为k的滑动窗口从数组的最左侧移动到数组的最右侧。你只可以看到在滑动窗口内的k个数字。滑动窗口每次只向右移动一位。返回滑动窗口中的最大值。1>deque=newArrayDequeSystem.out.print(e.get(0)+":"+e.get(1)+""));System.out.println();}returnres;}/***如果当前队尾有元素
【机器学习&深度学习】适合微调的模型选型指南
一叶千舟
深度学习【应用必备常识】深度学习人工智能
目录一、不同规模模型微调适用性二、微调技术类型对显存的影响三、选择建议(根据你的硬件)四、实际模型推荐五、不同模型适合人群六、推荐几个“非常适合微调”的模型七、推荐使用的微调技术八、场景选择示例场景1:智能客服(中文)场景2:法律问答(中文RAG)场景3:医学问答/健康咨询场景4:AI写作助手(中英文)场景5:代码补全/AI编程助手对比总结表九、不同参数模型特点9.1参数规模vs能力9.2微型模型
【机器学习&深度学习】本地部署 vs API调用:关键看显存!
一叶千舟
深度学习【应用必备常识】深度学习人工智能
目录一、本地部署VSAPI调用1.模型运行方式2.性能与速度3.成本4.隐私与安全5.何时选择哪种方式?二、为什么推荐本地部署?1️⃣零依赖网络和外部服务,更可靠稳定2️⃣无调用次数限制,更适合高频或批量推理3️⃣避免长期API费用,节省成本4️⃣保护用户隐私和数据安全5️⃣可自定义、深度优化6️⃣加载一次即可复用,低延迟高性能7️⃣离线可用(重要!)三、适合本地部署的情况四、本地部署条件4.1模
深度学习 vs 传统机器学习:哪个更适合你的项目?
AI大模型应用之禅
深度学习机器学习人工智能ai
深度学习vs传统机器学习:哪个更适合你的项目?关键词:深度学习、传统机器学习、特征工程、数据量、计算资源、项目选择、算法对比摘要:本文将用"炒菜"和"拼图"等生活案例,从核心原理、适用场景、资源需求等维度对比深度学习与传统机器学习。通过具体代码示例和真实项目场景分析,帮助开发者和企业决策者快速判断:你的项目该选深度学习还是传统机器学习?背景介绍目的和范围随着AI技术普及,"该用深度学习还是传统机器
设置cursor、vscode的默认终端
啥都不会工程师
vscodeide编辑器
一般来说设置为command会比较好,比较方便和anaconda连用。但是正常来说默认是powershel,参考了别的帖子先用ctrl+shift+p调出命令输入settingsjson进入修改为:{"terminal.integrated.profiles.windows":{"CommandPrompt":{"path":"C:\\Windows\\System32\\cmd.exe"},"P
VSCode - 使用 WSL(Windows Subsystem for Linux)
anleng6817
开发工具git
一开始我是只将VSCode集成的终端改成WSL的Bash,结果发现内置的GIt用的还是Windows的Git,GitHooks用的Windows的环境,上网搜了一下发现有很复杂的方式,继续翻了翻发现管饭居然有超好用的方式DevelopingintheWindowsSubsystemforLinuxwithVisualStudioCode(虽然有大神指出这种方式还有有难用的地方。。)总之安装Remo
【深度学习|学习笔记】如何在深度学习中使用 正则化技术 进行模型压缩、稀疏建模和迁移学习调优?
努力毕业的小土博^_^
机器学习基础算法优质笔记2深度学习学习笔记迁移学习人工智能机器学习
【深度学习|学习笔记】如何在深度学习中使用正则化技术进行模型压缩、稀疏建模和迁移学习调优?【深度学习|学习笔记】如何在深度学习中使用正则化技术进行模型压缩、稀疏建模和迁移学习调优?文章目录【深度学习|学习笔记】如何在深度学习中使用正则化技术进行模型压缩、稀疏建模和迁移学习调优?✅一、使用正则化进行模型压缩(ModelCompression)目标:方法:L1正则化促使权重稀疏化代码示例:后续压缩步骤
C#数据流处理:深入解析System.IO.Pipelines的奥秘
阿蒙Armon
C#工作中的应用c#php服务器
C#数据流处理:深入解析System.IO.Pipelines的奥秘在当今高并发、高性能的应用开发领域,高效处理数据流是一项至关重要的挑战。传统的StreamAPI在处理大量数据时,往往面临内存分配效率低、频繁数据拷贝、难以高效处理异步I/O等问题。为了解决这些痛点,.NET团队在.NETCore2.1中引入了System.IO.Pipelines库,为开发者提供了一套高性能、低延迟的数据流处理解
鲲鹏CPU+麒麟操作系统arm环境安装MySQL
运维小乔
mysql数据库
系统环境背景:CPU:鲲鹏920操作系统:Ky10SP3MySQL版本:8.4.2一、下载MySQL官网地址:https://downloads.mysql.com/archives/community/二:MySQL安装前准备2.1关闭防火墙[root@ky-b~]#systemctlstopfirewalld[root@ky-b~]#systemctldisablefirewalldRemov
【机器学习&深度学习】模型微调的基本概念与流程
一叶千舟
深度学习【理论】机器学习深度学习人工智能
目录前言一、什么是模型微调(Fine-tuning)?二、预训练vs微调:什么关系?三、微调的基本流程(以BERT为例)1️⃣准备数据2️⃣加载预训练模型和分词器3️⃣数据编码与加载4️⃣定义优化器5️⃣开始训练6️⃣评估与保存模型四、是否要冻结BERT层?五、完整训练示例代码5.1环境依赖5.2执行代码总结:微调的优势前言在自然语言处理(NLP)快速发展的今天,预训练模型如BERT成为了众多任务
linux深度学习问题汇总
不想改代码
备忘录linuxpython深度学习pytorch人工智能1024程序员节
目录一、异常问题1.segementationfault(coredump)2.Illegalinstruction(coredumped)3.死锁4.掉卡二、通用方法1.查看重启记录2.系统性能监控3.后台执行命令4.异常日志三、深度学习技术1.普通网络改DDP训练,单机多卡,pytorch四、专业内容方法1.微调diffusion类模型本文记录一些在使用linux服务器进行深度学习时遇到的问题
LeetCode[位运算] - #137 Single Number II
Cwind
javaAlgorithmLeetCode题解位运算
原题链接:#137 Single Number II
要求:
给定一个整型数组,其中除了一个元素之外,每个元素都出现三次。找出这个元素
注意:算法的时间复杂度应为O(n),最好不使用额外的内存空间
难度:中等
分析:
与#136类似,都是考察位运算。不过出现两次的可以使用异或运算的特性 n XOR n = 0, n XOR 0 = n,即某一
《JavaScript语言精粹》笔记
aijuans
JavaScript
0、JavaScript的简单数据类型包括数字、字符创、布尔值(true/false)、null和undefined值,其它值都是对象。
1、JavaScript只有一个数字类型,它在内部被表示为64位的浮点数。没有分离出整数,所以1和1.0的值相同。
2、NaN是一个数值,表示一个不能产生正常结果的运算结果。NaN不等于任何值,包括它本身。可以用函数isNaN(number)检测NaN,但是
你应该更新的Java知识之常用程序库
Kai_Ge
java
在很多人眼中,Java 已经是一门垂垂老矣的语言,但并不妨碍 Java 世界依然在前进。如果你曾离开 Java,云游于其它世界,或是每日只在遗留代码中挣扎,或许是时候抬起头,看看老 Java 中的新东西。
Guava
Guava[gwɑ:və],一句话,只要你做Java项目,就应该用Guava(Github)。
guava 是 Google 出品的一套 Java 核心库,在我看来,它甚至应该
HttpClient
120153216
httpclient
/**
* 可以传对象的请求转发,对象已流形式放入HTTP中
*/
public static Object doPost(Map<String,Object> parmMap,String url)
{
Object object = null;
HttpClient hc = new HttpClient();
String fullURL
Django model字段类型清单
2002wmj
django
Django 通过 models 实现数据库的创建、修改、删除等操作,本文为模型中一般常用的类型的清单,便于查询和使用: AutoField:一个自动递增的整型字段,添加记录时它会自动增长。你通常不需要直接使用这个字段;如果你不指定主键的话,系统会自动添加一个主键字段到你的model。(参阅自动主键字段) BooleanField:布尔字段,管理工具里会自动将其描述为checkbox。 Cha
在SQLSERVER中查找消耗CPU最多的SQL
357029540
SQL Server
返回消耗CPU数目最多的10条语句
SELECT TOP 10
total_worker_time/execution_count AS avg_cpu_cost, plan_handle,
execution_count,
(SELECT SUBSTRING(text, statement_start_of
Myeclipse项目无法部署,Undefined exploded archive location
7454103
eclipseMyEclipse
做个备忘!
错误信息为:
Undefined exploded archive location
原因:
在工程转移过程中,导致工程的配置文件出错;
解决方法:
GMT时间格式转换
adminjun
GMT时间转换
普通的时间转换问题我这里就不再罗嗦了,我想大家应该都会那种低级的转换问题吧,现在我向大家总结一下如何转换GMT时间格式,这种格式的转换方法网上还不是很多,所以有必要总结一下,也算给有需要的朋友一个小小的帮助啦。
1、可以使用
SimpleDateFormat SimpleDateFormat
EEE-三位星期
d-天
MMM-月
yyyy-四位年
Oracle数据库新装连接串问题
aijuans
oracle数据库
割接新装了数据库,客户端登陆无问题,apache/cgi-bin程序有问题,sqlnet.log日志如下:
Fatal NI connect error 12170.
VERSION INFORMATION: TNS for Linux: Version 10.2.0.4.0 - Product
回顾java数组复制
ayaoxinchao
java数组
在写这篇文章之前,也看了一些别人写的,基本上都是大同小异。文章是对java数组复制基础知识的回顾,算是作为学习笔记,供以后自己翻阅。首先,简单想一下这个问题:为什么要复制数组?我的个人理解:在我们在利用一个数组时,在每一次使用,我们都希望它的值是初始值。这时我们就要对数组进行复制,以达到原始数组值的安全性。java数组复制大致分为3种方式:①for循环方式 ②clone方式 ③arrayCopy方
java web会话监听并使用spring注入
bewithme
Java Web
在java web应用中,当你想在建立会话或移除会话时,让系统做某些事情,比如说,统计在线用户,每当有用户登录时,或退出时,那么可以用下面这个监听器来监听。
import java.util.ArrayList;
import java.ut
NoSQL数据库之Redis数据库管理(Redis的常用命令及高级应用)
bijian1013
redis数据库NoSQL
一 .Redis常用命令
Redis提供了丰富的命令对数据库和各种数据库类型进行操作,这些命令可以在Linux终端使用。
a.键值相关命令
b.服务器相关命令
1.键值相关命令
&
java枚举序列化问题
bingyingao
java枚举序列化
对象在网络中传输离不开序列化和反序列化。而如果序列化的对象中有枚举值就要特别注意一些发布兼容问题:
1.加一个枚举值
新机器代码读分布式缓存中老对象,没有问题,不会抛异常。
老机器代码读分布式缓存中新对像,反序列化会中断,所以在所有机器发布完成之前要避免出现新对象,或者提前让老机器拥有新增枚举的jar。
2.删一个枚举值
新机器代码读分布式缓存中老对象,反序列
【Spark七十八】Spark Kyro序列化
bit1129
spark
当使用SparkContext的saveAsObjectFile方法将对象序列化到文件,以及通过objectFile方法将对象从文件反序列出来的时候,Spark默认使用Java的序列化以及反序列化机制,通常情况下,这种序列化机制是很低效的,Spark支持使用Kyro作为对象的序列化和反序列化机制,序列化的速度比java更快,但是使用Kyro时要注意,Kyro目前还是有些bug。
Spark
Hybridizing OO and Functional Design
bookjovi
erlanghaskell
推荐博文:
Tell Above, and Ask Below - Hybridizing OO and Functional Design
文章中把OO和FP讲的深入透彻,里面把smalltalk和haskell作为典型的两种编程范式代表语言,此点本人极为同意,smalltalk可以说是最能体现OO设计的面向对象语言,smalltalk的作者Alan kay也是OO的最早先驱,
Java-Collections Framework学习与总结-HashMap
BrokenDreams
Collections
开发中常常会用到这样一种数据结构,根据一个关键字,找到所需的信息。这个过程有点像查字典,拿到一个key,去字典表中查找对应的value。Java1.0版本提供了这样的类java.util.Dictionary(抽象类),基本上支持字典表的操作。后来引入了Map接口,更好的描述的这种数据结构。
&nb
读《研磨设计模式》-代码笔记-职责链模式-Chain Of Responsibility
bylijinnan
java设计模式
声明: 本文只为方便我个人查阅和理解,详细的分析以及源代码请移步 原作者的博客http://chjavach.iteye.com/
/**
* 业务逻辑:项目经理只能处理500以下的费用申请,部门经理是1000,总经理不设限。简单起见,只同意“Tom”的申请
* bylijinnan
*/
abstract class Handler {
/*
Android中启动外部程序
cherishLC
android
1、启动外部程序
引用自:
http://blog.csdn.net/linxcool/article/details/7692374
//方法一
Intent intent=new Intent();
//包名 包名+类名(全路径)
intent.setClassName("com.linxcool", "com.linxcool.PlaneActi
summary_keep_rate
coollyj
SUM
BEGIN
/*DECLARE minDate varchar(20) ;
DECLARE maxDate varchar(20) ;*/
DECLARE stkDate varchar(20) ;
DECLARE done int default -1;
/* 游标中 注册服务器地址 */
DE
hadoop hdfs 添加数据目录出错
daizj
hadoophdfs扩容
由于原来配置的hadoop data目录快要用满了,故准备修改配置文件增加数据目录,以便扩容,但由于疏忽,把core-site.xml, hdfs-site.xml配置文件dfs.datanode.data.dir 配置项增加了配置目录,但未创建实际目录,重启datanode服务时,报如下错误:
2014-11-18 08:51:39,128 WARN org.apache.hadoop.h
grep 目录级联查找
dongwei_6688
grep
在Mac或者Linux下使用grep进行文件内容查找时,如果给定的目标搜索路径是当前目录,那么它默认只搜索当前目录下的文件,而不会搜索其下面子目录中的文件内容,如果想级联搜索下级目录,需要使用一个“-r”参数:
grep -n -r "GET" .
上面的命令将会找出当前目录“.”及当前目录中所有下级目录
yii 修改模块使用的布局文件
dcj3sjt126com
yiilayouts
方法一:yii模块默认使用系统当前的主题布局文件,如果在主配置文件中配置了主题比如: 'theme'=>'mythm', 那么yii的模块就使用 protected/themes/mythm/views/layouts 下的布局文件; 如果未配置主题,那么 yii的模块就使用 protected/views/layouts 下的布局文件, 总之默认不是使用自身目录 pr
设计模式之单例模式
come_for_dream
设计模式单例模式懒汉式饿汉式双重检验锁失败无序写入
今天该来的面试还没来,这个店估计不会来电话了,安静下来写写博客也不错,没事翻了翻小易哥的博客甚至与大牛们之间的差距,基础知识不扎实建起来的楼再高也只能是危楼罢了,陈下心回归基础把以前学过的东西总结一下。
*********************************
8、数组
豆豆咖啡
二维数组数组一维数组
一、概念
数组是同一种类型数据的集合。其实数组就是一个容器。
二、好处
可以自动给数组中的元素从0开始编号,方便操作这些元素
三、格式
//一维数组
1,元素类型[] 变量名 = new 元素类型[元素的个数]
int[] arr =
Decode Ways
hcx2013
decode
A message containing letters from A-Z is being encoded to numbers using the following mapping:
'A' -> 1
'B' -> 2
...
'Z' -> 26
Given an encoded message containing digits, det
Spring4.1新特性——异步调度和事件机制的异常处理
jinnianshilongnian
spring 4.1
目录
Spring4.1新特性——综述
Spring4.1新特性——Spring核心部分及其他
Spring4.1新特性——Spring缓存框架增强
Spring4.1新特性——异步调用和事件机制的异常处理
Spring4.1新特性——数据库集成测试脚本初始化
Spring4.1新特性——Spring MVC增强
Spring4.1新特性——页面自动化测试框架Spring MVC T
squid3(高命中率)缓存服务器配置
liyonghui160com
系统:centos 5.x
需要的软件:squid-3.0.STABLE25.tar.gz
1.下载squid
wget http://www.squid-cache.org/Versions/v3/3.0/squid-3.0.STABLE25.tar.gz
tar zxf squid-3.0.STABLE25.tar.gz &&
避免Java应用中NullPointerException的技巧和最佳实践
pda158
java
1) 从已知的String对象中调用equals()和equalsIgnoreCase()方法,而非未知对象。 总是从已知的非空String对象中调用equals()方法。因为equals()方法是对称的,调用a.equals(b)和调用b.equals(a)是完全相同的,这也是为什么程序员对于对象a和b这么不上心。如果调用者是空指针,这种调用可能导致一个空指针异常
Object unk
如何在Swift语言中创建http请求
shoothao
httpswift
概述:本文通过实例从同步和异步两种方式上回答了”如何在Swift语言中创建http请求“的问题。
如果你对Objective-C比较了解的话,对于如何创建http请求你一定驾轻就熟了,而新语言Swift与其相比只有语法上的区别。但是,对才接触到这个崭新平台的初学者来说,他们仍然想知道“如何在Swift语言中创建http请求?”。
在这里,我将作出一些建议来回答上述问题。常见的
Spring事务的传播方式
uule
spring事务
传播方式:
新建事务
required
required_new - 挂起当前
非事务方式运行
supports
&nbs