python 基础知识
前言
-
推荐使用Typora解锁全套,下载地址:https://www.typora.io/
-
Markdown是一种可以使用普通文本编辑器编写的标记语言,通过简单的标记语法,它可以使普通文本内容具有一定的格式。
-
使用
word撰写文档,有如下的弊端:- 只能对纯文本文件进行版本控制,而word是二进制格式
- 格式繁杂,经常需要中断写作来控制格式
- 代码与文档分离,给写文档造成更大的阻力
-
而假如单纯的使用txt,就没有一点格式了,
-
用html虽然既有格式又能加入版本控制,但是需要花费较多的时间在标签上,而且标签占了文档的较大百分比,不易阅读。
所以,最终的解决方案就是 Markdown ,作为一种轻量级的标记语言,能在非常短的时间内掌握。而且不仅可以用于写文档,还可以写博客、写简书、做一些随手笔记。Markdown文件以.md结尾,可以导出为html和PDF(需要使用的工具支持)。它是一种语法(个人认为是简化版的html),但是和html不同的是,各种解析器对其会有不同的表现。比如我的IDEA Markdown插件会把分割线显示成一条细灰线,Cmd Markdown则是显示一条虚线。所以建议保持使用一种Markdown工具和尽量使用标准语法。
一、Markdown基本语法
1.1 标题
# 一级标题
## 二级标题
### 三级标题
#### 四级标题
##### 五级标题
###### 最小只有六级标题
效果:
你复制粘贴即知晓!!!
1.2 加粗
**我被加粗了**
效果:
我被加粗了
1.3 斜体
*我倾斜了了*
效果:
我倾斜了了
1.4 代码引用(>式)
> hello markdown!
效果:
hello markdown!
> hello markdown!
>> hello markdown!
效果:
hello markdown!
hello markdown!
1.5 代码引用(```式)
```python
print('hello nick')
```
效果:
print('hello nick')
1.6 有序列表
1. one
2. two
3. three
效果:
-
one
-
two
-
three
1.7 无序列表
* one
* two
* three
效果:
-
one
-
two
-
three
1.8 分割线
---
效果:
1.9 表格
第二行必须得有,并且第二行的冒号代表对齐格式,分别为居中;右对齐;左对齐):
段落==>表格==>插入表格
总结
- 以上所述就是Markdown的基本标签,虽然不多,但是可以解决大部分情况
二. 计算机基本概念
2.1 计算机是什么?
- 计算机(computer)俗称电脑,是现代⼀种⽤于⾼速计算的电⼦计算机器
- 计算机的特点:数值计算、逻辑计算、存储记忆功能
- 总结 : 能够按照程序运行、自动、高速处理数据的现代化智能电子设备
2.2 计算机的组成
- 硬件和软件:
- 硬件:⿏标 键盘 显示器 CPU 硬盘… 看的⻅摸的着
- 软件:PyCharm, QQ 浏览器 英雄联盟… 看不⻅摸不着
- 软件就是通过编程,完成的一个一系列按照特定顺序组织的计算机数据和特定指令的集合
2.3 计算机语⾔概述
2.3.1 计算机语⾔的基本概念
- 概念 :计算机语⾔(Computer Language)指⽤于⼈与计算机之间通讯的语⾔。
- 总结:能够按照程序运⾏、⾃动、⾼速处理数据的现代化智能电⼦设备
2.3.2 计算机语⾔的发展
- 机器语⾔ --> 汇编语⾔ --> ⾼级计算机语⾔
- 机器语⾔:最初的机器语⾔都是由0 和 1组成的⼆进制数,说⽩了⼆进制就是机器语⾔组成的基础
- 汇编语⾔:汇编语⾔是在机器语⾔基础之上发展的,它⽤了⼀些简单的字⺟和符号串来代替⼆进制串,这样就提⾼了语⾔的记忆性和识别性
- ⾼级计算机语⾔: 就是⼀系列指令的集合 例如: JAVA C C++ Python
2.3.3 解释型语⾔和编译型语⾔的区别
- 编译型语言:在机器执行之前就编译成了机器码------->先编译在执行----->执行速度快、跨平台性不好 (代表语⾔ C)
- 解释型语言: 在执行之时进行解释------->一边解释一边执行--------> 执行速度慢、跨平台性好(代表语⾔ Python)
2.3.4交互模式
-
TUI:命令行的交互方式
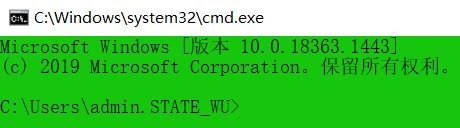
-
win键 + R --> CMD --> 回⻋
-
命令⾏结构
-
Microsoft Windows [版本 10.0.18363.1443] —> 版本
- © 2019 Microsoft Corporation。保留所有权利。—> 版权声明
- C:\Users\admin.STATE_WU>
- C: —>所在磁盘的根⽬录 (可以通过 X: 切换盘符)
- \User\admin.STATE_WU —> 所在磁盘路径,当前所在的⽂件夹
- ’>’ —> 命令提示符 (在后⾯可以直接输⼊指令)
-
dos命令
| 指令 | 作用 |
|---|---|
| dir | 列出当前目录下的文件夹或者文件 |
| md | 创建目录 |
| rd | 删除目录 |
| cd | 进入指定目录 |
| cd… | 退回上一级目录 |
| cd/ | 退回到根目录 |
| del | 删除文件 |
| exit | 退出dos命令 |
| win+R | 快捷进入cmd |
| where | 想查找某个可执行命令的绝对路径 |
- GUI:图形界面化的交互方法
2.4.⽂本⽂件和字符集
2.4.1⽂本⽂件
- ⽂本分为两种 : ⼀种 纯⽂本 ⼀种 富⽂本
- 纯⽂本只能保存单⼀的⽂本内容,⽆法保存内容⽆关的东⻄(例如 txt⽂本⽂档)
- 富⽂本可以保存⽂本以外的东⻄(例如 有道笔记)
- 纯⽂本在计算机底层也会转换为⼆进制保存
- 将字符转换为⼆进制码的过程,我们称之为编码 encode()
- 将⼆进制码转换成字符的过程,我们称之为解码 decode()
2.5 常⻅的字符集
- ASCII :美国⼈编码 使⽤7位来对美国常⽤的字符进⾏编码 包含128个字符
- ISO-8859-1: 欧洲的编码 使⽤8位来编码 包含256个字符
- GBK: 中国⼈编码(国标码)
- Unicode 万国码 包含世界上所有语⾔和字符 编写程序⼀般都会使⽤Unicode 编码
- Unicode 编码有多种实现 UTF-8 UTF-16 UTF-32
2.6 进制
进制也就是进位计数制,是人为定义的带进位的计数方法(有不带进位的计数方法,比如原始的结绳计数法,唱票时常用的“正”字计数法,以及类似的tally mark计数)。
对于任何一种进制—X进制,就表示每一位置上的数运算时都是逢X进一位。
2.6.1进制的计数
- 十进制:
- ⼗进制满⼗进⼀ ⼗进制⼀共有10个数字
- 计数 : 0 1 2 3 4 5 6 7 8 9 10 11 12 …19 20
- 十六进制
- ⼗六进制满⼗六进位 ⼗六进制的数字 引⼊了 a b c d e f 表示 10 11 12 13 14 15
- 计数 : 0 1 2 3 4 5 6 7 8 9 a b c d e f 10 11 12 13 … 1a 1b 1c 1d 1e 1f 20 21 22 23 24…2a 2b 2c 2d 2e 2f 30 31 32 33 34… 3a 3b…
- 八进制
- ⼋进制满⼋进⼀ ⼋进制⼀共有8个数字
- 计数 : 0 1 2 3 4 5 6 7 10 11 … 17 20 21…27 30
- 二进制
- ⼆进制满⼆进⼀ ⼆进制⼀共有2个数字 0 1
- 计数 : 0 1 10 11 100 101 110 111 1000…
- 以此类推,x进制就是逢x进位。
2.6.2进制之间的转换
- ⼗进制–>⼆进制 原理: 对⼗进制数进⾏除2运算
将25转换为二进制数
解:25÷2=12 余数1
12÷2=6 余数0
6÷2=3 余数0
3÷2=1 余数1
1÷2=0 余数1
所以25=(11001)2
同理,
把十进制数转换为十六进制数时,将基数2转换成16就可以了.
例:将25转换为十六进制数
解:25÷16=1 余数9
1÷16=0 余数1
所以25=(19)16
- 二进制数转换为十六进制数,从左向右每四位一组,依次写出每组4位二进制数所对应的十六进制数――简称四位合一位.
例:将二进制数(000111010110)2转换为十六进制数.
解: 0001 1101 0110
1 D 6
所以(111010110)2=(1D6)16
转换时注意最后一组不足4位时必须加0补齐4位
- ⼆进制 – > ⼗进制 原理:⼆进制乘以2(次幂)的过程
- 进制越⼤表现形式越短,之所以出现其他进制就是为了更⽅便的表示数据
2.6.3 数据间的换算
- bit是计算机中最⼩的单位
- byte是我们最⼩的可操作的单位
| 8 bit | 1 byte | 字节 | byte |
| 1024 byte | 1 KB | 千字节 | Kilobyte |
| 1024 KB | 1 MB | 兆字节 | Megabyte |
| 1024 MB | 1 GB | 吉字节 | Giga byte |
| 1024 GB | 1 TB | 太字节 | Trillion byte |
| 1024 TB | 1 PB | 拍字节 | Peta byte |
| 1024 PB | 1 EB | 艾字节 | Exa byte |
| 1024 EB | 1 ZB | 泽字节 | Zetta byte |
| 1024 ZB | 1 YB | 尧字节 | Jotta byte |
| 1024 YB | 1 BB | 亿字节 | Bronto byte |
| 1024 BB | 1 NB | Nona Byte | |
| 1024 NB | 1 DB | Dogga Byte |
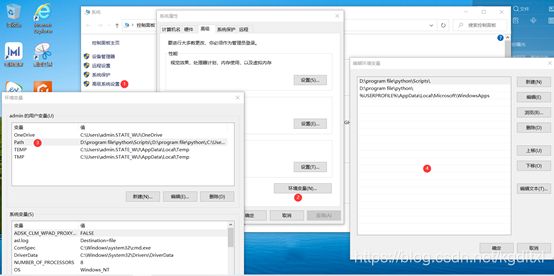
2.7 环境变量
2.7.1基本概念
- 环境变量(environment variables)⼀般是指在操作系统中⽤来指定操作系统运⾏环境的⼀些参数,如:临时⽂件夹位置和系统⽂件夹位置等
- 环境变量操作
- 1.查看环境变量
- 右键计算机(此电脑),选择属性
- 系统界⾯左侧选择 ⾼级系统设置
- 选择环境变量
- 2.添加环境变量
- 通过新建按钮添加环境变量
- 环境变量可以有多个值 , 值与值之间⽤ 英⽂分号隔开
- 3 修改环境变量
- 通过编辑按钮来修改环境变量
- 4.删除环境变量
- 通过删除按钮来删除环境变量
- 1.查看环境变量
2.7.2 path环境变量
- path环境变量 保存的是⼀个⼀个的路径
- 当我们在命令⾏中输⼊⼀个命令,系统会先在当前⽬录下找,如果有就直接打开
- 如果没有则会去path环境变量的路径去找,直到找到为⽌。没找到则会报错
- 我们可以将⼀些经常要访问的⽂件或程序的路径添加到环境变量当中。这样我们就可以在任意位置来访问这些⽂件了
- 注意事项:
- path环境变量不区分⼤⼩写 path Path PATH
- 多个路径之间⽤ ; 隔开
三. Python语言基本概念
3.1 Python语⾔的基本概念
- Python 是⼀种极少数能兼具 简单 与 功能强⼤ 的编程语⾔。你将惊异于发现你正在使⽤的这⻔编程语⾔是如此简单,它专注于如何解决问题,⽽⾮拘 泥于语法与结构
- 官⽅对 Python 的介绍如下:
- Python 是⼀款易于学习且功能强⼤的编程语⾔。 它具有⾼效率的数据结构,能够简单⼜有效地实现⾯向对象编程。Python 简洁的语法与动态输⼊之特性,加之其解释性语⾔的本质,使得它成为⼀种在多种领域与绝⼤多数平台都能进⾏脚本编写与应⽤快速开发⼯作的理想语⾔
- Python 的创造者吉多·范罗苏姆(Guido van Rossum)采⽤ BBC 电视节⽬《蒙提·派森的⻜⾏⻢戏团(Monty Python’s Flying Circus,⼀译巨蟒剧团)》的名字来为这⻔编程语⾔命名
3.2 Python 的特⾊
- 简单
- 易于学习
- ⾃由且开放
- 跨平台
- 可嵌⼊性
- 丰富的库
3.3 Python的发展及应⽤

- Python的应⽤
- 常规软件开发
- 科学计算
- ⾃动化运维
- ⾃动化测试
- WEB开发
- ⽹络爬⾍
- 数据分析
- ⼈⼯智能
3.4 Python之禅
(输⼊ import this)
美胜于丑陋(Python 以编写优美的代码为⽬标)
明了胜于晦涩(优美的代码应当是明了的,命名规范,⻛格相似)
简洁胜于复杂(优美的代码应当是简洁的,不要有复杂的内部实现)
复杂胜于凌乱(如果复杂不可避免,那代码间也不能有难懂的关系,要保持接⼝简洁)
扁平胜于嵌套(优美的代码应当是扁平的,不能有太多的嵌套)
间隔胜于紧凑(优美的代码有适当的间隔,不要奢望⼀⾏代码解决问题)
可读性很重要(优美的代码是可读的)
即便假借特例的实⽤性之名,也不可违背这些规则(这些规则⾄⾼⽆上)
不要包容所有错误,除⾮你确定需要这样做(精准地捕获异常,不写except:pass ⻛格的代码)
当存在多种可能,不要尝试去猜测⽽是尽量找⼀种,最好是唯⼀⼀种明显的解决⽅案(如果不确定,就⽤穷举法)
虽然这并不容易,因为你不是 Python 之⽗(这⾥的 Dutch 是指 Guido )
做也许好过不做,但不假思索就动⼿还不如不做(动⼿之前要细思量)
如果你⽆法向⼈描述你的⽅案,那肯定不是⼀个好⽅案;反之亦然(⽅案测评标准)
命名空间是⼀种绝妙的理念,我们应当多加利⽤(倡导与号召)
四 Python解释器和集成环境
4.1 Windows下Python环境搭建
搭建环境
Python的解释器
- 环境搭建就是安装Python的解释器
- Python的解释器分类:
- CPython(官⽅我们⽤的就是这个版本) ⽤c语⾔编写的Python解释器
- PyPy ⽤Python语⾔编写的Python解释器
- JPython ⽤Java编写的Python解释器
搭建Python环境
官⽹链接
下载安装包


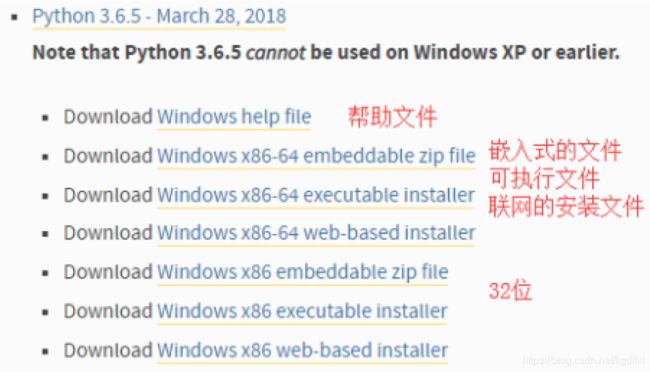

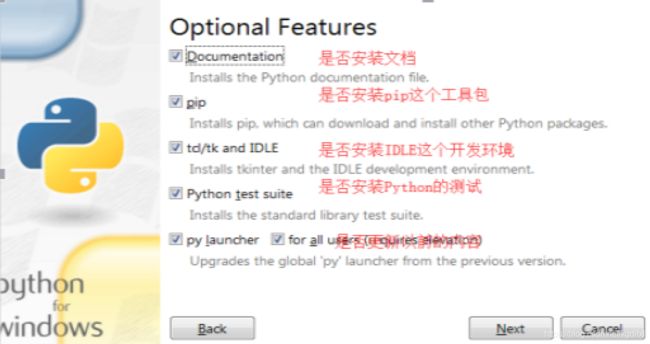
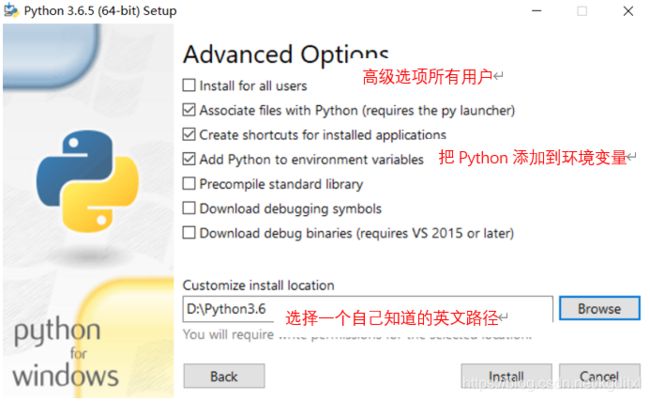
安装成功
4.2 Python的交互模式
- win键 + R --> CMD --> 回⻋ --> 输⼊Python
- 命令⾏结构
- Python 3. 6. 5 … —> 版本
- Type “help”,“copyright”…—> 版权声明
- “>>>” —> 命令提示符 (在后⾯可以直接输⼊指令)

4.3 pip⼯具的使⽤
pip介绍
我们都知道python有很多的第三⽅库或者说是模块。这些库针对不同的应⽤,
发挥不同的作⽤。我们在实际的项⽬中肯定会⽤到这些模块。那如何将这些模
块导⼊到⾃⼰的项⽬中呢?
Python官⽅的PyPi仓库为我们提供了⼀个统⼀的代码托管仓库,所有的第三⽅
库,甚⾄你⾃⼰写的开源模块,都可以发布到这⾥,让全世界的⼈分享下载 。
python有两个著名的包管理⼯具easy_install和pip。在python 2中
easy_install是默认安装的,⽽pip需要我们⼿动安装。随着Python版本的提
⾼,easy_install已经逐渐被淘汰,但是⼀些⽐较⽼的第三⽅库,在现在仍然只
能通过easy_install进⾏安装。⽬前,pip已经成为主流的安装⼯具,⾃Python
2 >=2.7.9或者Python 3.4以后默认都安装有pip
pip使⽤
在命令⾏下,输⼊pip,回⻋可以看到帮助说明:

- 查看pip版本
pip -V
pip --version
- 普通安装
pip install requests
- 指定版本安装
pip install robotframework==2.8.7
- 卸载已安装的库
pip uninstall requests
pip install SomePackage
pip install SomePackage==1.0.5 # 指定版本
pip install 'SomePackage>=1.0.6' # 最⼩版本
- 升级指定的包,通过使⽤==, >=, <=, >, < 来指定⼀个版本号。
- 列出已经安装的库
1 pip list
- 显示所安装包的信息
1 pip show package
- 将已经安装的库列表保存到⽂本⽂件中
pip freeze > D:\桌⾯\install.txt

- 批量下载导出来的包
pip install -r packages.txt
- 使⽤wheel⽂件安装
除了使⽤上⾯的⽅式联⽹进⾏安装外,还可以将安装包也就是wheel格式的⽂
件,下载到本地,然后使⽤pip进⾏安装。⽐如我在PYPI上提前下载的pillow库
的wheel⽂件,后缀名为whl
地址:链接

可以使⽤pip install pillow-4.2xxxxxxx.whl的⽅式离线进⾏安装 - 第⼀步 安装 wheel

- 第⼆步 找到下载的whl⽂件的⽬录进⾏安装(以桌⾯为例)

- 第三步 执⾏命令安装

换源安装
⾖瓣 :https://pypi.douban.com/simple/
阿⾥ :https://mirrors.aliyun.com/pypi/simple/
中国科学技术⼤学:http://pypi.mirrors.ustc.edu.cn/simple
清华:https://pypi.tuna.tsinghua.edu.cn/simple
例如:pip install SomePackage -ihttps://pypi.douban.com/simple
4.4 Python的第⼀个程序
- 可以在交互模式实现
- 可以⽤Python⾃带的idle
- 可以⽤⾼级开发⼯具如 : PyCharm
4.5 Pycharm简介
PyCharm 是 Python 最著名的集成开发环境 IDE 之⼀,由⼤名鼎鼎的 JetBrains 公司开发,如果你⽤过该公司其它产品,像 Intellij IDEA 或者 WebStorm,你将对 PyCharm 驾轻就熟,该公司旗下产品在功能布局及设置等⽅⾯都保持了很好的⼀致性。
4.5.1 什么是 IDE?
IDE 是集成开发环境的英⽂缩写 (Integrated Development Environment),所谓集成开发环境就是将你在开发过程中所需要的⼯具或功能集成到了⼀起,⽐如:代码编写、分析、编译、调试等功能,从⽽最⼤化地提⾼开发者的⼯作效率。
-
IDE 通⽤特点:
- 提供图形⽤户界⾯,在 IDE 中可以完成开发过程中所有⼯作;
- ⽀持代码补全与检查,并提供快速修复选项;
- 内置解释器与编译器;
- 功能强⼤的调试器,⽀持设置断点与单步执⾏等功能。
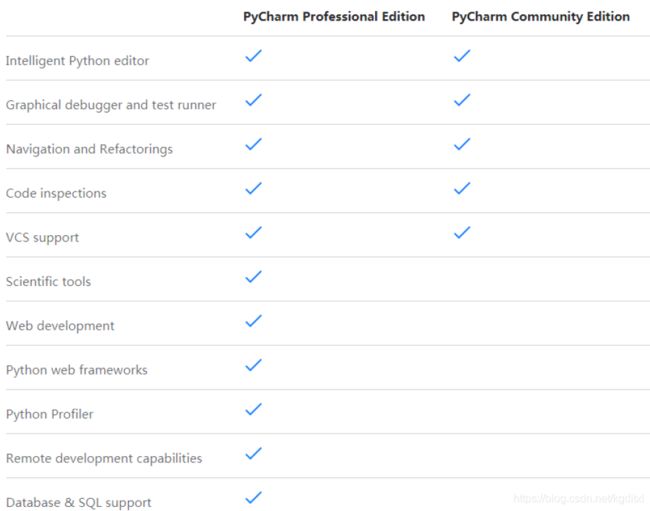
4.5.2 PyCharm 的版本
⽬前 PyCharm 共有三个版本:Professional、Community 和 Edu 版。Community 和 Edu 版本是开源项⽬,它们是免费的。 Edu 版完整的引⽤了 Community 版所有的功
能。同时集成了⼀个python的课程学习平台,⽐较适合从未接触过的任何开发语⾔的⼩⽩。Professional 版是收费的,下⾯是 Profession 与 Community 版的对⽐,后者相对前者缺少很多重要功能,对于开发⼈员还是强烈建议选择 professional 版本,本课程中也将以 Professional 版本为例进⾏讲解。
4.5.3 其它 IDE 对⽐
4.5.3.1 Spyder
在 IDE 市场也是⼤名鼎鼎, 主要是为科学计算⽽开发的。它是开源⼯具, 可运⾏在 Linux, Windows and Mac OS 上。

优点:
-
在查找和消解除代码性能链瓶颈⽅⾯⾮常⾼效;
-
可即时查看任何⽂档并修改⾃⼰的⽂档。
-
⽀持扩展插件。
缺点:
- 同时调⽤太多插件时,其性能下降⽐较多;
- ⽆法配置开发⼈员想要禁⽤的警告。
4.5.3.2 PyDev + Eclipse

Eclipse 是 Java 语⾔的 IDE,PyDev 是其⼀个插件,安装后,可以在 Eclispe 中进⾏ Python 的开发⼯作。
优点:
"""
- 提供了代码语法⾼亮显示、解析器错误、代码折叠和多语⾔⽀持;
- 具有良好的界⾯视图,提供⼀个交互式控制台;
- ⽀持 CPython、Jython、Iron Python 和 Django,并允许在挂起模式下进⾏交互式测试。
缺点:
- 如果应⽤程序太⼤,使⽤多个插件,PyDev IDE 的性能会降低;
- 作为插件,在实际使⽤过程中不是很稳定。
"""
4.5.3.3 IDLE

如果你的电脑上安装了 Python,同时也就安装了 IDLE。初学者可以利⽤它⽅便地创建、运⾏、测试Python 程序。
优点:
-
IDLE 纯粹在 Python 中开发,使⽤ Tkinter GUI ⼯具包,也是⼀个跨平台⼯具,可以⼯作在Windows, macOS 与 Linux 上;
-
它具有多窗⼝⽂本编辑器的良好功能,具有调⽤提示、智能缩进、撤消等许多功能;
-
它还⽀持对话框、浏览器和可编辑配置。
缺点:
- 它有⼀些正常的使⽤问题,有时它缺乏焦点,在代码⾃动补全⽅⾯只⽀持内置标准库;
- 在界⾯上缺少⼀些基本的设计,⽐如缺少⾏号。
4.5.3.4 Wing

也是在当今市场上流⾏和强⼤的 IDE,具有许多适合 Python 开发⼈员要求的功能, 可以⼯作在 Windows,macOS 与 Linux 上。 它是商业软件,Wing Personal 与 Wing 101 两个版本是为了学⽣与初学者的免费版本。
"""
优点:
1. 在试⽤版过期的情况下,Wing 为开发⼈员提供了⼤约 10 分钟的时间来迁移其应⽤程序;
2. 它有⼀个源浏览器,有助于显示脚本中使⽤的所有变量;
3. 功能强⼤的调试器,提供了⼀个额外的异常处理选项卡,可帮助开发⼈员调试代码。
缺点:
1. 在科学计算⽅⾯没有集成⼀些常⽤⼯具与库;
2. 商业版本功能强⼤,也意味占⽤内存⽐较⼤
"""

4.5.4 为什么是 PyCharm?
上⼀部分总结了其它 IDE 的优缺点, 相较其它产品,PyCharm 是功能最为完备,⽤户体验最好的IDE,适合⼤型项⽬的开发。 具体特性如下:
- 智能代码编辑功能: ⾃动代码补全,你继续输⼊时,拼写提示列表会缩⼩范围以匹配你输⼊的字符。
具有实时编辑功能,⽴即⾃动保存编辑内容; - 专业⼯具集成: ⼏乎集成了程序员可能希望的所有功能, ⽐如集成单元测试,代码检测,集成版本控
制,代码重构⼯具等等; - ⽀持各种 Web 开发语⾔:如 HTML/CSS、Javascript、Angular JS、node JS 等。Pycharm 还⽀
持多种类型的 Web 开发框架和⼴泛的 Web 模板; - 科学计算:集成了 IPython Notebook,其作为交互式的 python 控制台,⽀持各种⼯具如
Anaconda, NumPy, Matplotlib 等等; - 可定制 + 跨平台: 可以⾃定义UI界⾯,可运⾏在 Linux, Windows and Mac OS 上;
- 远程调试:通过配置 Docker 或者 Vagrant 及 SSH, ⽀持在本地使⽤远程服务器的 Python 解释器和
环境进⾏调试和运⾏, 这是其它⼤多数其它 IDE 不具备的功能; - 最流⾏:意味着当你在使⽤中遇到问题,意味着可以在互联⽹上更快的找到解决⽅案相对于其它 IDE。
PyCharm 主界⾯:
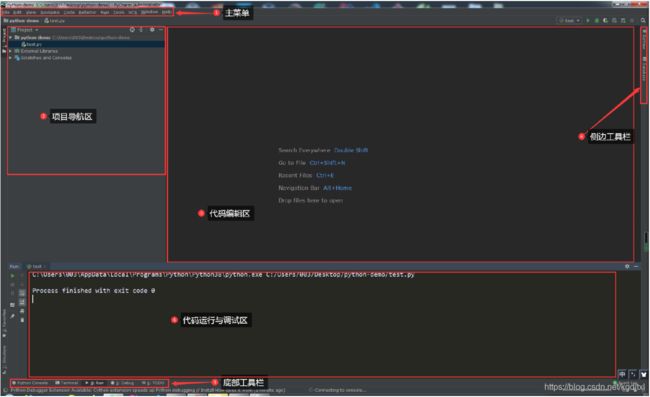

4.5.5 PyCharm的安装和配置
4.5.5.1 PyCharm的安装

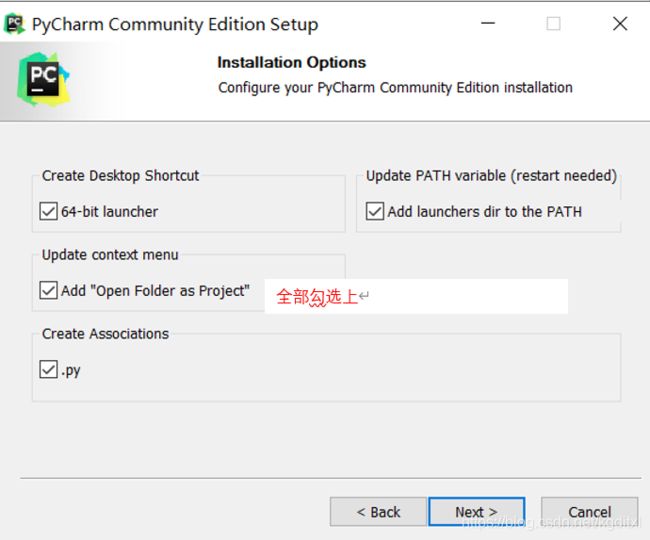


4.5.5.2 PyCharm的简单配置
- 主题修改 File–settings–apperance–theme
- 代码字体修改 File–settings–Editor-Font
- 关闭更新 File–settings—apperance—System Settings —Updates — Automatically check updates for 取消打钩
- 快捷键修改 File–settings—apperance-- Keymap 选择⾃⼰习惯的快捷键⽅式
- ⾃动导包 File–settings—apperance–General —Auto Import打钩
- 进制打开上次的⼯程 File–settings—apperance—System Settings —Reopen last project startup
- 修改新建⽂件⽂件头 File–settings–Editor—Code Style — File and Code Templates — Python Script
#!/usr/bin/env python# -*- coding: utf-8 -*-
# @Time : ${DATE} ${TIME}
# @Author : Jerry
# @File : ${NAME}.py
# @Software: ${PRODUCT_NAME}
- 修改字体编码 File–settings–Editor—Code Style — File Encoding — Project Encoding
常⻅问题总结
- pip版本⽐较低安装命令输⼊错误
问题描述

解决⽅案
1 pip版本太低 输⼊升级指令 python -m pip install --upgrade pip 然后在去安装2 直接 pip install requests (不需要在后⾯加东⻄)3 或者通过换源⽅式去安装 pip install SomePackage -i https://pypi.douban.com/simple
- ⽹速以及⽹络延时问题
问题描述
解决⽅案
1 多安装⼏次2 通过换源⽅式去安装 pip install SomePackage -i https://pypi.douban.com/simple
- 解释器配置问题
问题描述

解决⽅案

- 缩进的错误
问题描述
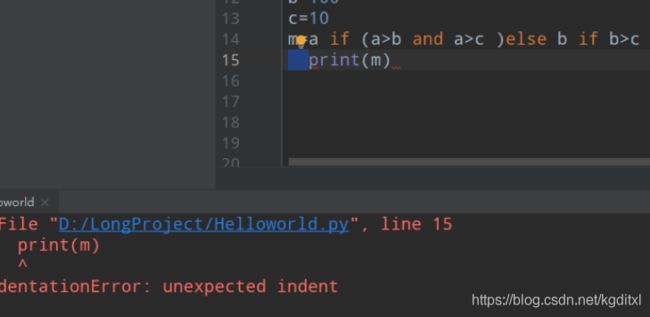
解决⽅案

- 安装了pycharm之后桌⾯右键选项框变⼤了怎么做?
windows键+R键输⼊regedit
按照以下路径:
HKEY_CLASSES_ROOT\Directory\Background\shell\PyCharm Community Edition,找到
PyCharm Community Edition⽂件夹,删除即可
五 python基础
5.1. ⼏个概念
-
表达式
-
语句
-
程序
-
函数
5.1.1 表达式
例如:1+2,可以运行,但是没有输出结果
- 表达式,是由数字、算符、数字分组符号(括号)、⾃由变量和约束变量等以能求得数值的有意义排列⽅法所得的组合
- 表达式特点
- 表达式⼀般仅仅⽤于计算⼀些结果,不会对程序产⽣实质性的影响
- 如果在交互模式中输⼊⼀个表达式,解释器会⾃动将表达式的结果输出
5.1.2 语句:
例如:判断语句,循环语句,比较语句等
- ⼀个语法上⾃成体系的单位,它由⼀个词或句法上有关连的⼀组词构成
- 语句的执⾏⼀般会对程序产⽣⼀定的影响,在交互模式中不⼀定会输出语句的执⾏结果
5.1.3 程序(program)
一个程序就是相当于一个功能
- 程序就是由⼀条⼀条的语句和⼀条⼀条的表达式构成的。
5.1.4 函数(function)
- 函数就是⼀种语句,函数专⻔⽤来完成特定的功能
- 函数⻓的形如:xxx()
- 函数的分类:
- 内置函数 : 或者内建函数,就是由语法规定存在的函数,这些函数,包含在编译器的运⾏时库中,程序员不⽐单独书写代码实现它,只需要调⽤既可。例如:input(),print()
- ⾃定义函数 : 由程序员⾃主的创建的函数 当我们需要完成某个功能时,就可以去调⽤内置函数,或者⾃定义函数。 例如 def fun():
- 函数的2个要素
- 参数
- 返回值
5.2. 标识符
5.2.1 关键字
- python⼀些具有特殊功能的标识符,这就是所谓的关键字关键字,是python已经使⽤的了,所以不允许开发者⾃⼰定义和关键字相同的名字的标识符
win键 + R --> CMD --> 回⻋,在命令行里面输入:python回车,import keyword回车,再输入keyword.kwlist,就可以看到python保留字
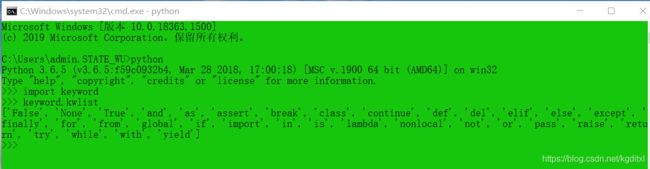
5.2.2 标识符概念
- 开发⼈员在程序中⾃定义的⼀些符号和名称。标识符是⾃⼰定义的,如变量名、函数名等
- 组成:由26个英⽂字⺟⼤⼩写,数字 0-9, 符号 _
- 标识符的规则:
- 标识符中可以包含字⺟、数字、_,但是不能使⽤数字开头
- 例如:正确的:name1 ,name_1, _name1 ; 错误的:1name(不⾏)
- Python中不能使⽤关键字和保留字来作为标识符
- 命名⽅式
- 驼峰命名法:
- ⼩驼峰式命名法: 第⼀个单词以⼩写字⺟开始;第⼆个单词的⾸字⺟⼤写,例如:myName、aDog
- ⼤驼峰式命名法: 每⼀个单字的⾸字⺟都采⽤⼤写字⺟,例如:FirstName、LastName
- 下划线命名法
- 不过在程序员中还有⼀种命名法⽐较流⾏,就是⽤下划线“_”来连接所有的单词,⽐如 get_url buffer_size
- 驼峰命名法:
六 变量
6.1 变量的概念?
-
我们首先来想想看你是怎么认识一个人的,今天来你会认识我,明天来你还会认识我。那你是不是记住我这个人的典型特征,比如我的名字、体重、身高…世间万物我们是不是都是这样去认识的?毫无疑问是的。既然人能识别世间万物,那么我们之前一直把计算机想象成人,那是不是说计算机也能识别世间万物呢?对的。计算机通过记录我们的状态认识我。这就是量的概念。
- 量:记录现实世界中的状态,让计算机能够像人一样去识别世间万物。
今天我可能180,明年我是不是可能就是185了(5cm不过分),那这种状态是不是会发生变化。
- 变:现实世界中的状态是会发生改变的。
-
为什么要有变量
- 对于现实世界,一定是要有一个变量来描述世间万物的。
- 但是计算机为什么也要有变量的概念呢?其实计算机中程序的运行就是一系列状态的变化,如王者荣耀中账号等级0级到30级、废铁到王者;植物大战僵尸中僵尸打着打着就死了。
-
变量是计算机内存中的⼀块区域,存储规定范围内的值,值 可以改变,通俗的说变量就是给数据起个名字。
-
变量命名规则
- 变量名由字⺟、数字、下划线组成要符合标识符的命名规范
- 数字不能开头
- 不能使⽤关键字
-
注意 : 两个对象相等和两个对象是同⼀个对象是两个概念
6.2 定义变量
既然知道了变量是什么玩意,那我们如何在Python中定义变量呢?
name = 'state'
age = 36
gender = 'male'
height = 176
weight = 140
6.3 变量的组成
从我们上面定义的变量可以看到,变量的组成分为以下三个部分:
- 变量名:变量名用来引用变量值,但凡需要用变量值,都需要通过变量名。
- 赋值符号:赋值
- 变量值:存放数据,用来记录现实世界中的某种状态。
name # 报错,无任何意义
age = 18
height = 185
print(age)
print(height)
# 打印出结果
18
185
6.4 变量的运算
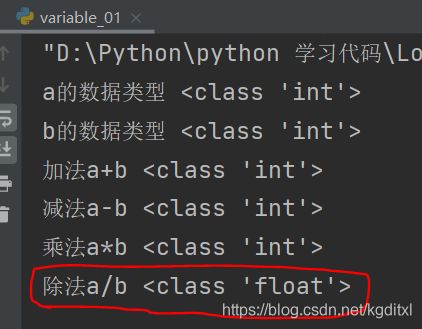
- 变量的运算就是正常的四则运算 ,需要注意的是在运算过程中含有浮点数,那么它返回的就是⼀个浮点数类型
- 变量的除法,即使变量都是整数型(int),结果依然是浮点数型(float)

6.5 变量在内存中的原理
- 原理:变量在内存中就是⼀块特定的存储区域(地址)
6.5.1 引⽤变量
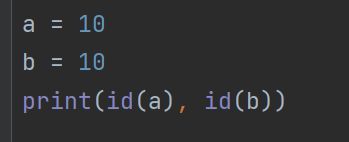
-
两个引⽤指向同⼀个int数据: 结果:地址⼀样

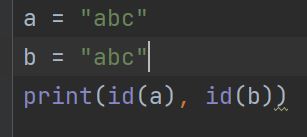
-
两个引⽤指向同⼀个str数据 结果:地址⼀样

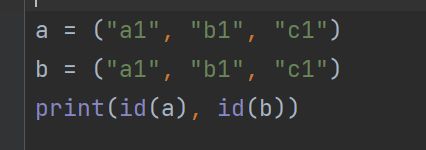
-
两个引⽤指向同⼀个list数据 结果:地址不⼀样 因为列表是可变类型
6.6 变量的三个特性
对于每个变量,python都提供了这三个方法分别获取变量的三个特征,其中python的内置功能id(),内存地址不一样,则id()后打印的结果不一样,因为每一个变量值都有其内存地址,而id是用来反映变量值在内存中的位置,内存地址不同则id不同。
6.6.1 打印
a= 10
print(a)
# 打印出来的结果是10
6.6.2 判断变量值是否相等
a="good"
b="moring"
print(a==b)
# 打印出来的结果是False
6.6.3 判断变量id是否相等
a=11
b=11
print(a is b)
# 打印出来的结果是 True
a=11
b=15
print(a is b)
# 打印出来的结果是 False
七 常量
变量是变化的量,常量则是不变的量。python中没有使用语法强制定义常量,也就是说,python中定义常量本质上就是变量。如果非要定义常量,变量名必须全大写。
Age= 18
print(Age)
#打印出来的结果是18
Age=Age+1
Print(Age)
#打印出来的结果是19
如果是常量,那就没必要更改,所以python就只制定了一个规范,而没指定常量的语法,
因此常量也是可以修改的,但不建议。
八 基本数据类型
8.1 基本数据类型
- 数据类型指的就是变量的值的类型,也就是可以为变量赋哪些值
| 类型 | 表示方法 |
|---|---|
| 文本类型 | str |
| 数值类型 | int(整数型), float(浮点数), complex(复数) |
| 序列类型 | list(列表), tuple(元组), range(区间) |
| 映射类型 | dict(字典) |
| 集合类型 | set(集合), frozenset (冻结的集合) |
| 布尔类型 | bool(布尔) |
| 二进制类型 | bytes(字节), bytearray(新字节数组), memoryview (内存查看对象) |
8.1.1 整数和⼩数
- 整数 : 所有整数 例如 : a = 1 b = 100 c =999 都是int类型
- ⼩数常量 : 所有⼩数 例如 a = 1.2 b=6.66 ⽤float类型表示
8.1.2 布尔值和空值
- 布尔: 只有2个值⼀个是True ⼀个是False
- **None常量:**只有⼀个数值就是None 也就是空值
8.1.3 字符串
8.1.3.1 什么是字符串
- 字符串是由数字、字⺟、下划线组成的⼀串字符
- 注意
- 单引号或双引号不能混合使⽤
- Python中⽤⼀对双引号或者⼀对单引号包裹的内容就是字符串

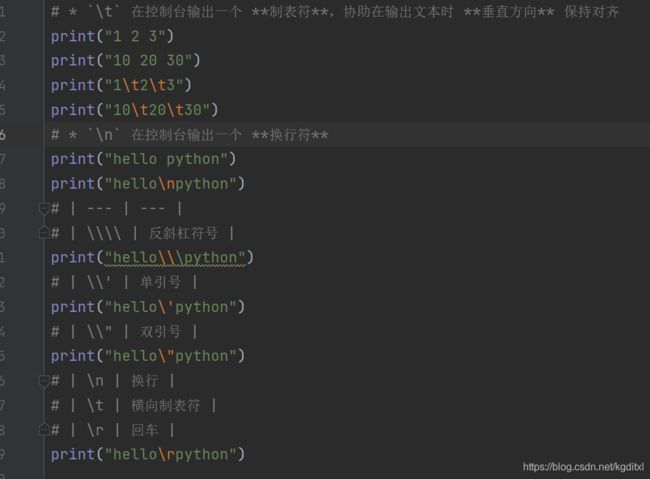
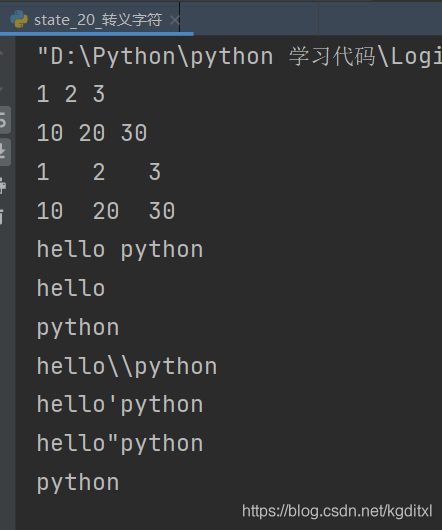
8.1.3.2 转义字符
- 转义字符是⼀种特殊的字符常量。转义字符以反斜线""开头,后跟⼀个或⼏个字符。转义字符具有特定的含义,不同于字符原有的意义,故称“转义”字符
- 总结
\t 表示制表符
\n 表示换⾏符
\\ 表示反斜杠
\' 表示 '
\ '' 表示 ''
\(在行尾时)表示续行符
\e表示换页
8.1.3.3 ⻓字符串
- ⻓字符串 ⼜叫做⽂档字符串 我们使⽤三重引号来表示⼀个⻓字符串’’’ ‘’'或‘’‘’‘’
- 三重引号可以换⾏,并且会保留字符串中的格式
- Python 长字符串由三个双引号"""或者三个单引号’’'包围,语法格式如下
"""长字符串内容"""'''长字符串内容'''


长文本注释,运行程序不会报错

8.1.3.4 格式化字符串
-
第⼀种格式化字符串 拼串

-
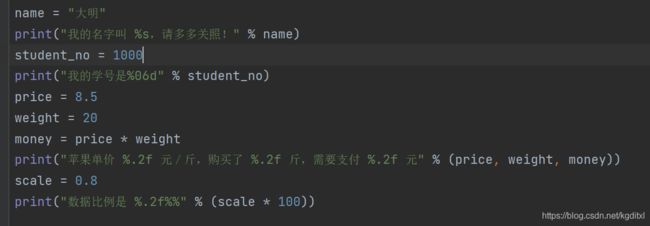
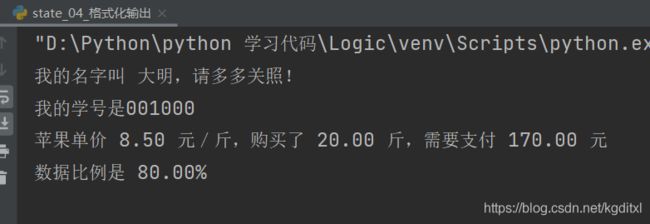
第⼆种格式化字符串 参数传递
-
第三种格式化字符串 占位符
- %s 字符串占位
- %f 浮点数占位
- %d 整数占位

-
第四种格式化字符串 f’{变量}’
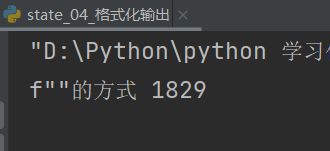
-
第五种格式化字符串:str.format ()

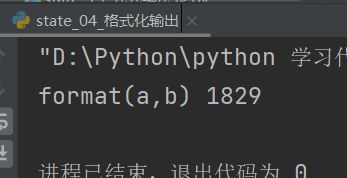
8.1.3.5 字符串的其他操作
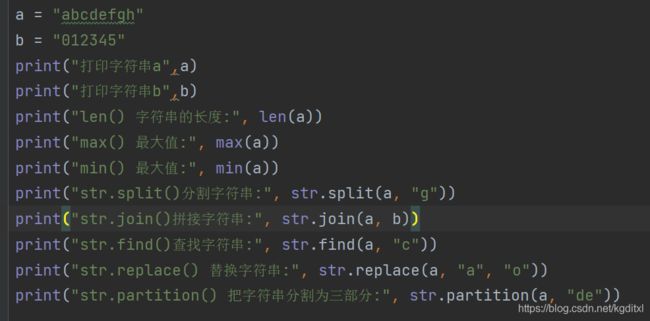
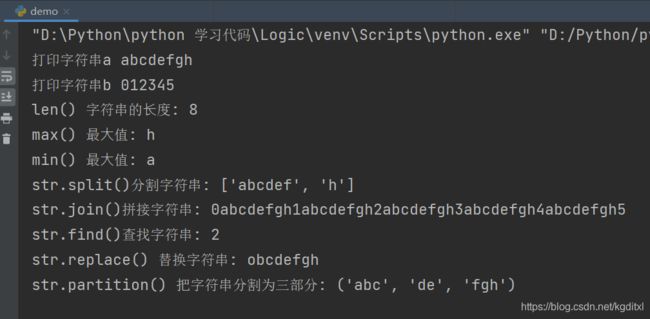
-
len() 字符串的⻓度
-
max() 最⼤值
-
min() 最⼩值
-
str.split()分割字符串
-
str.join()拼接字符串
-
str.find()查找字符串
-
str.replace() 替换字符串
-
str.partition() 把字符串分割为三部分
-
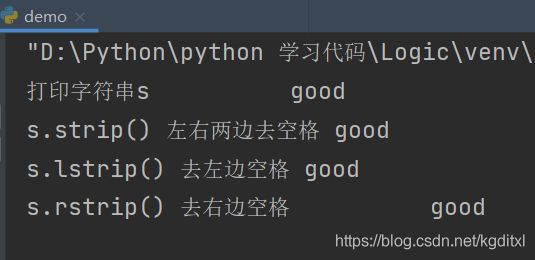
去空格
- s.strip() 左右两边去空格
- s.lstrip() 去左边空格
- s.rstrip() 去右边空格

-
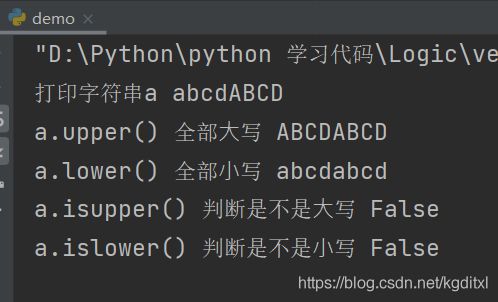
字符串⼤⼩写
-
s.upper() 全部⼤写
-
s.lower() 全部⼩写
-
s.isupper() 判断是不是⼤写
-
s.islower() 判断是不是⼩写

第三讲作业
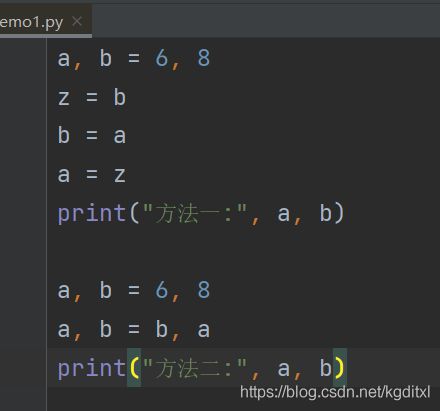
- a,b = 6, 8 我想让a=8 b=6我该怎么办?⽤2种⽅式实现

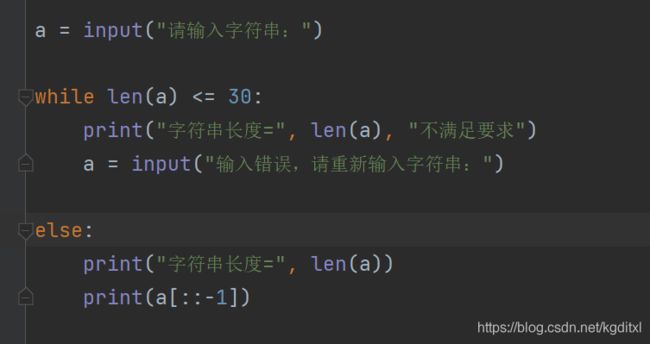
- 完成字符串的逆序以及统计
- 设计⼀个程序,要求只能输⼊⻓度低于31的字符串,否则提示⽤户重新输⼊
- 打印出字符串⻓度
- 使⽤切⽚逆序打印出字符串
-

九 运算符
9.1 运算符的概念
- 运算符⽤于执⾏程序代码运算,会针对⼀个以上操作数项⽬来进⾏运算。例如:2+3,其操作数是2和3,⽽运算符则是“+”
9.2 运算符的分类
- 算术运算符
- 赋值运算符
- ⽐较运算符(关系运算符)
- 逻辑运算符
- 条件运算符(三元运算符)
9.2.1 算术运算符
- 加法运算符 表现形式 +
- 减法运算符 表现形式 -
- 乘法运算符 表现形式 *
- 除法运算符 表现形式 /
- // 整除,只会保留计算后的整数位,总会返回⼀个整型int
- % 取模,求两个数相除的余数
- ** 幂运算,求⼀个值的⼏次幂
- 字符串和字符串运算不支持减法和乘法
- 字符串和数字乘法表示输出字符串的倍数
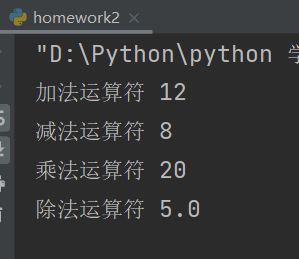
a = 10
b = 2
print("加法运算符", a + b)
print("减法运算符", a - b)
print("乘法运算符", a * b)
print("除法运算符", a / b)
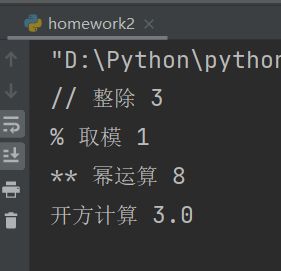
a = 10
b = 3
print("// 整除", a // b)
print("% 取模", a % b)
c = 2
d = 3
print("** 幂运算", c ** d)
a1 = 9
print("开方计算", a1 ** 0.5)
9.2.2 赋值运算符
赋值运算符的特殊写法 x = x + 3 其实是和 x += 3 是⼀样的
+= (x+= 3 相当于 x = x + 3 )
-= (x -= 3 相当于 x= x - 3 )
*= (x = 3 相当于 x = x 3 )
**= (x **= 3 相当于 x = x ** 3 )
/= (x /= 3 相当于 x = x/ 3 )
//= (x //= 3 相当于 x = x // 3 )
%= (x %= 3 相当于 x= x % 3 )
9.2.3 ⽐较运算符
- ⽐较运算符⽤来⽐较两个值之间的关系,总会返回⼀个布尔值。如果关系成⽴,返回True;否则返回False
- ‘’> ⽐较左侧值是否⼤于右侧值
- ‘’>= ⽐较左侧的值是否⼤于或等于右侧的值
- < ⽐较左侧值是否⼩于右侧值
- <= ⽐较左侧的值是否⼩于或等于右侧的值
- 特殊的⽐较⽅式
- == ⽐较两个对象的值是否相等
- != ⽐较两个对象的值是否不相等
- is ⽐较两个对象是否是同⼀个对象,⽐较的是对象的id
- is not ⽐较两个对象是否不是同⼀个对象,⽐较的是对象的id
9.2.4 逻辑运算符
9.2.4.1 not 逻辑⾮
-
not可以对符号右侧的值进⾏⾮运算,对于布尔值,⾮运算会对其进⾏取反操作,True变False,False变True
-
0,空串,None, 还有一些表示空性的值都会转换为True, 其他的值都可以转换为False
-
下面几个代码运行结果都是True
a = not 0
b = not None
c = not {}
d = not []
print(a)
print(b)
print(c)
print(d)
9.2.4.2 and 逻辑与
- and可以对符号两侧的值进⾏与运算。 只有在符号两侧的值都为True时,才会返回True,只要有⼀个False就返回False
- 与运算是找False的,如果第⼀个值为False,则不再看第⼆个值
下面代码只有第一个是True, 其余都是False
a = 10 > 1 and 45.6 > 44
a1 = 1 > 10 and 45.6 > 44
a2 = 1 > 10 and 45.6 > 46
print(a)
print(a1)
print(a2)
9.2.4.3 or 逻辑或
- 或运算两个值中只要有⼀个True,就会返回True
- 或运算是找True的
下面代码,只有第三个才是False,第一,第二都是True
a = 3 > 2 or 6 > 4
a1 = 3 > 2 or 4 > 6
a2 = 1 > 2 or 4 > 6
print(a)
print(a1)
print(a2)
9.2.4.4⾮布尔值的与或运算
- 当我们对⾮布尔值进⾏与或运算时,Python会将其当做布尔值运算,最终会返回原值
print(10 and 20)
print(2 and 0)
print("" or "https://www.baidu.com")
print(18.5 or "https:www.baidu.com")
# 返回结果:200https://www.baidu.com18.5
- ⾮布尔值与运算的规则
- 与运算是找False的,如果第⼀个值是False,则不看第⼆个值。如果第⼀个值是False,则直接返回第⼀个值,否则返回第⼆个值
- ⾮布尔值或运算的规则
- 或运算是找True的,如果第⼀个值是True,则不看第⼆个值。如果第⼀个值是True,则直接返回第⼀个值,否则返回第⼆个值
9.2.5 条件运算符(三元运算符)
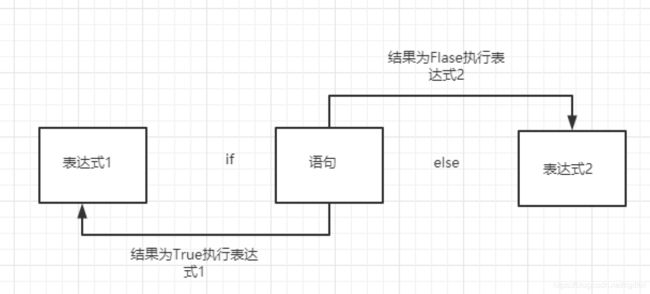
- 条件运算符在执⾏时,会先对条件表达式进⾏求值判断
- 如果判断结果为True,则执⾏语句1,并返回执⾏结果
- 如果判断结果为False,则执⾏语句2,并返回执⾏结果
- 语法: 语句1 if 条件表达式 else 语句2
a = int(input("Input a: "))
b = int(input("Input b: "))
print("a大于b") if a > b else (print("a小于b") if a < b else print("a等于b"))
9.2.6 运算符的优先级
- 所谓优先级,就是当多个运算符同时出现在一个表达式中时,先执行哪个运算符。
- 例如对于表达式a + b * c,Python 会先计算乘法再计算加法;b * c的结果为 8,a + 8的结果为24,所以 d 最终的值也是 24。先计算*再计算+,说明乘的优先级高于加。
- Python 支持几十种运算符,被划分成将近二十个优先级,有的运算符优先级不同,有的运算符优先级相同,请看下表。
运算符优先级参照表

- 当一个表达式中出现多个运算符时,Python 会先比较各个运算符的优先级,按照优先级从高到低的顺序依次执行;当遇到优先级相同的运算符时,再根据结合性决定先执行哪个运算符:如果是左结合性就先执行左边的运算符,如果是右结合性就先执行右边的运算符。
第四讲作业
- 以4种格式化字符串的⽅式来实现 521 xxx 嫁给我好吗?
a = "@@@"
# 第一种:
print("521", a, "嫁给我好吗?")
# 第二种%s
print("521 %s 嫁给我好吗?" % a)
# 第三种f""
print(f"521 {a} 嫁给我好吗?")
# 第四种
print("521 {} 嫁给我好吗?".format(a))
- 现在有a b c三个变量,三个变量中分别保存有三个数值,请通过条件运算符获取三个值中的最⼤值
a = 10
b = 30
c = 20
res = a if a > b else b if b > c else c if c > a else a
print(res)
十 流程控制
10.1 条件判断
10.1.1 条件判断语句(if语句)
- if语句在执⾏时,会先对条件表达式进⾏求值判断,
- 如果为True,则执⾏if后的语句
- 如果为False,则不执⾏

- 语法:if 条件表达式 :
代码块 - 代码块代码块中保存着⼀组代码,同⼀个代码块中的代码,要么都执⾏要么都不执⾏
- 代码块以缩进开始,直到代码恢复到之前的缩进级别时结束
- 代码块就是⼀种为代码分组的机制
10.1.2 input() 函数
- 该函数⽤来获取⽤户的输⼊
- input()调⽤后,程序会⽴即暂停,等待⽤户输⼊
- ⽤户输⼊完内容以后,点击回⻋程序才会继续向下执⾏
- ⽤户输⼊完成以后,其所输⼊的的内容会以返回值得形式返回
- input() 函数接受一个标准输入数据,返回为 string 类型。
input("请输入:")
请输入是提示信息
10.1.3 if-else语句
- 语法:
if 条件表达式 :
代码块
else :
代码块
- 执⾏流程
- if-else语句在执⾏时,先对if后的条件表达式进⾏求值判断
- 如果为True,则执⾏if后的代码块
- 如果为False,则执⾏else后的代码块
# 1. 定义布尔型变量 `has_ticket` 表示是否有车票
has_ticket = True
# 2. 定义整型变量 `knife_length` 表示刀的长度,单位:厘米
knife_length=int(input("请输入刀的长度:"))
# 3. 首先检查是否有车票,如果有,才允许进行 **安检**
if has_ticket:
print("有车票,可以开始安检..")
# 4. 安检时,需要检查刀的长度,判断是否超过 20 厘米
if knife_length>=20:
print("不允许携带 %d 厘米长的刀上车" % knife_length)
print("不允许上车")
else:
print("请上车")
#* 如果超过 20 厘米,提示刀的长度,不允许上车
#* 如果不超过 20 厘米,安检通过
# 5. 如果没有车票,不允许进门
else:
print("您要先买票啊")
10.1.4 if-elif-else 语句
- 语法结构
if 条件表达式1
:代码块
elif 条件表达式2 :
代码块
elif 条件表达式3 :
代码块
........
else :
代码块
- 执⾏流程
- if-elif-else语句在执⾏时,会⾃上向下依次对条件表达式进⾏求值判断,
- 如果表达式的结果为True,则执⾏当前代码块,然后语句结束
- 如果表达式的结果为False,则继续向下判断,直到找到True为⽌
- 如果所有的表达式都是False,则执⾏else后的代码块
elif和else都必须和if联合使用,而不能单独使用- 可以将
if、elif和else以及各自缩进的代码,看成一个 完整的代码块
- if语句的关键字为:if – elif – else
- 总结: if-elif-else中只会有⼀个代码块会执⾏
- 由于 python 并不支持 switch 语句,所以多个条件判断,只能用 elif 来实现,如果判断需要多个条件需同时判断时,可以使用 or (或),表示两个条件有一个成立时判断条件成功;使用 and (与)时,表示只有两个条件同时成立的情况下,判断条件才成功。
# if-elif-else语句一定会有且只有一个条件执行
value = 20000 # ?
if value >= 30000:
print('有钱任性')
elif value >= 20000:
print('有钱真好)
elif value >= 10000:
print(''哥也月薪上万了')
elif value >= 5000:
print('工资还说的过去')
elif value >= 2000:
print('能养活自己了')
else:
print('吃土我开心')
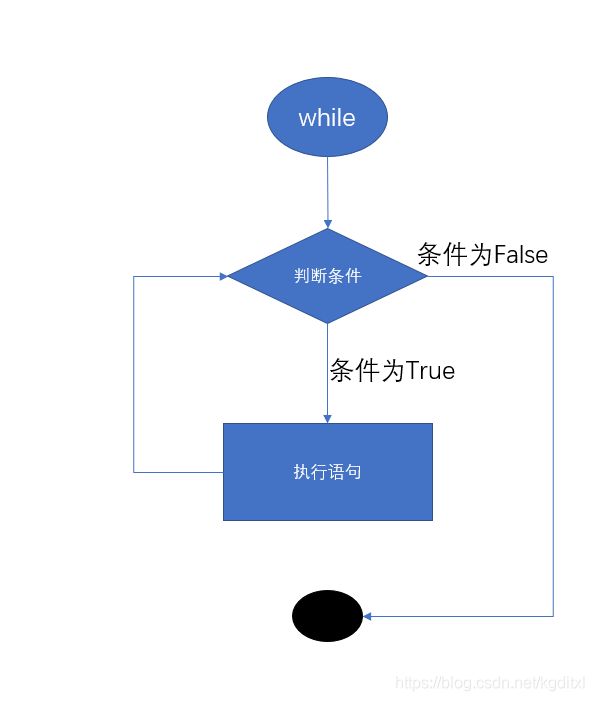
10.1.5 while 语句循环控制
- 循环语句可以使指定的代码块重复指定的次数.循环语句分成两种,while循环和 for循环
- 语法:
while 条件表达式 :
代码块
else:
代码块
案例:
a = input("请输入字符串:")
print(a)
while len(a) <= 5:
print("字符串长度是{}".format(len(a)), a)
a = input("输入错误,请输入字符串:")
else:
print("恭喜你输入正确", "字符串长度是{}".format(len(a)), a)
print("逆序", a[::-1])
- 循环嵌套
- 你可以在循环体内嵌入其他的循环体,如在while循环中可以嵌入for循环, 反之,你可以在for循环中嵌入while循环。
i = 0
while i < 5:
j = 0
while j < 5:
print('*', end='')
j += 1
print()
i += 1
break和continue
-
break 可以⽤来⽴即退出循环语句,包括else语句
- break语句用来终止循环语句,即循环条件没有False条件或者序列还没被完全递归完,也会停止执行循环语句。
- break语句用在while和for循环中。
- 如果使用嵌套循环,break语句将停止执行最深层的循环,并开始执行下一行代码。
-
continue ⽤来跳过当次循环
- Python continue 语句跳出本次循环,而break跳出整个循环。
- continue 语句用来告诉Python跳过当前循环的剩余语句,然后继续进行下一轮循环。
i = 0
while i < 5:
i += 1
if i == 2:
break
# continue
print(i)
# print(b)
else:
# while循环的后继语句会在while循环正常执行完毕之后继续执行
print('循环正常执行完毕')
- 打印99乘法表
# 99乘法表
#代码一
row = 0
while row < 9:
row += 1
col = 0
while col < row:
col += 1
print("{}*{}={}".format(col, row, col * row), end="\t")
print()
#代码二
row = 1
while row <= 9:
col = 1
while col <= row:
print("{}*{}={}".format(col, row, col * row), end="\t")
col += 1
print()
row += 1
第五讲作业
1.求1000以内所有的⽔仙花数
2.获取⽤户输⼊的任意数,判断其是否是质数?
3.猜拳游戏:
出拳 玩家:⼿动输⼊ 电脑:随机输⼊
判断输赢: 玩家获胜 电脑获胜 平局
- 作业1:
方法一
for a in range(0, 9):
for b in range(0, 9):
for c in range(0, 9):
i = a * 100 + b * 10 + c
if a ** 3 + b ** 3 + c ** 3 == i and i > 100:
print(i, "是水仙花数")
方法二
for i in range(100, 1000):
a = str(i)
b = int(a[0])
c = int(a[1])
d = int(a[2])
if i == b ** 3 + c ** 3 + d ** 3:
print(i)
方法三:使用while
i = 100
while i <= 1000:
a = str(i)
b = int(a[0])
c = int(a[1])
d = int(a[2])
if i == b ** 3 + c ** 3 + d ** 3:
print(i)
i += 1
- 作业2
方法一:
a = int(input("请输入任意一个数字:"))
if a > 1:
for b in range(2, a):
if a % b == 0:
print("%s是合数" % a)
break
else:
print("%s是质数" % a)
else:
print("输入错误")
num = int(input("请输入一个数:"))
i = 2
while i < num:
if num % i == 0:
print("%s是合数" % num)
break
else:
print("%s是质数" % num)
break
# i += 1
- 作业3
import random
# | 1 | 石头
# | 2 | 剪刀
# | 3 | 布
# 1、石头1 胜 剪刀2
# 2、剪刀2 胜 布3
# 3、布3 胜 石头1
# 4、玩家=电脑 平局
while True:
player = int(input("请输入1,2,3三个数中一个数:"))
computer = random.randint(1, 3)
if (player == 1 and computer == 2) or \
(player == 2 and computer == 3) or \
(player == 3 and computer == 1):
print("玩家获胜")
elif (player == 2 and computer == 1) or \
(player == 3 and computer == 2) or \
(player == 1 and computer == 3):
print("电脑获胜")
elif player == computer:
print("咱心有灵犀,平局啦!")
if player == 0:
print("游戏停止")
break
print("玩家选择的拳头是%s -电脑出的拳是%s" % (player, computer))
print("输入0游戏停止")
方法二:
while True:
import random
player = int(input('请输入1,2,3:'))
computer = random.randint(1, 3)
# list1 = [(1, 3), (2, 1), (3, 2)]
if (player == 1 and computer == 3) or (player == 2 and computer == 1) or (player == 3 and computer == 2):
print('玩家获胜')
elif player == computer:
print('平局')
else:
print('电脑获胜')
10.1.6 for循环遍历
- for循环
- 通过for循环来遍历列表
- for 变量 in 序列(遍历的规则): # 对于这个数据在这个列表中:挨个进行访问,称呼为遍历
1 语法
2 for 变量 in 序列(遍历的规则):
3 代码块
for i in range(1, 11):
print(i)
- 注意: for循环的代码块会执⾏多次,序列中有⼏个元素就会执⾏⼏次。每执⾏⼀次就会将序列中的⼀个元素赋值给变量,所以我们可以通过变量来获取列表中的元素
10.1.7 range函数
-
函数格式
range (start, stop[, step])
-
range(开始数据,结束数据,步长) 左闭右开型, 取头不取尾
-
开始数据可以省略,默认是从0开始, 结尾数据不可以省略,步长可以省略,默认为1
-
参数说明
- start: 计数从 start 开始。默认是从 0 开始。例如range(5)等价于range(0, 5)
- stop: 计数到 stop 结束,但不包括 stop。例如:range(0, 5) 是[0, 1,2, 3, 4]没有5
- step:步⻓,默认为1。例如:range(0, 5) 等价于 range(0, 5, 1)
10.1.8 循环嵌套
- Python 语⾔允许在⼀个循环体⾥⾯嵌⼊另⼀个循环。
while 表达式:
while 表达式:
代码块
代码块
for 变量 in 循环规则:
for 变量 in 循环规则:
代码块
代码块
10.1.9 无限循环
- 我们可以通过设置条件表达式永远不为 false 来实现无限循环,实例如下:
a= 1
while a == 1 :
# 表达式永远为 true
b = int(input("输入一个数字 :"))
print ("你输入的数字是: ", b)
print ("Good bye!")
十一 序列(sequence)
基本概念
- 序列是Python中最基本的⼀种数据结构。序列⽤于保存⼀组有序的数据,所有的数据在序列当中都有⼀个唯⼀的位置(索引)并且序列中的数据会按照添加的顺序来分配索引
- 数据结构指计算机中数据存储的⽅式
序列的分类
- 可变序列(序列中的元素可以改变)例如:列表[list],字典{dict},集合{set}
- 不可变序列(序列中的元素不能改变),例如:字符串“str” , 元组(tuple)
11.1 列表(list)
- 列表是Python中的⼀个对象
- 列表的作⽤
- 列表中可以保存多个有序的数据
- 列表是⽤来存储对象的对象
11.1.1 列表的使用
- 列表的创建:通过[]来创建⼀个空列表。例如:list1 = []
- 访问列表中的值,
- 与字符串的索引一样,列表索引从 0 开始,第二个索引是 1,依此类推。
- 通过索引列表可以进行截取、组合等操作。
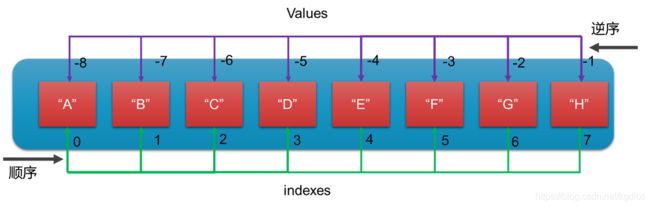
11.1.2 切片
- 切⽚是指从现有列表中获得⼀个⼦列表
- 通过切⽚来获取指定的元素
- 语法: 列表[起始 : 结束 : 步⻓]
- 通过切⽚获取元素时,会包括起始位置的元素,不会包括结束位置的元素
- 起始位置和结束位置的索引可以不写
- 如果省略结束位置, 则会从当前的开始位置⼀直截取到最后
- 如果省略开始位置, 则会从第⼀个元素截取到结束的元素,但是不包括结束的元素
- 如果开始位置和结束位置都省略, 则则会从第⼀个元素开始截取到最后⼀个元素
- 步⻓表示每次获取元素的间隔,默认是1(可以省略不写)
- 步⻓不能是0,可以是正数也可以为负数
list1 = ['柯南', '蜡笔小新', '火影忍者', '海贼王', '奥特曼']
print(list1[1:3])
# 根据索引值来做
print(list1[-2][2])
# print(list1[-100])
print(list1[::0])
11.1.3 通⽤操作
- “+” 和 *
- “+ ”可以将两个列表拼接成⼀个列表
- “*” 可以将列表重复指定的次数 (注意2个列表不能够做乘法,要和整数做乘法运算)
a = [1, 2, 3] + [4, 5, 6]
a = [1, 2, 3] * [4, 5, 6]
a = [1, 2, 3] * 2
print(a)
- in 和 not in
- in⽤来检查指定元素是否在列表当中
- not in ⽤来检查指定元素是否不在列表当中
list1 = ['柯南', '蜡笔小新', '火影忍者', '海贼王', '奥特曼', '海贼王']
print('海贼王' in list1)
- len() 获取列表中元素的个数
list1 = ['柯南', '蜡笔小新', '火影忍者', '海贼王', '奥特曼', '海贼王']
print(len(list1))
- max() 获取列表中最⼤值
- min() 获取列表中最⼩值
a = [1, 2, 3]
print(max(a))
print(min(a))
- list.index(x[, start[, end]])
- 第⼀个参数 获取指定元素在列表中的位置
- 第⼆个参数 表示查找的起始位置
- 第三个参数 表示查找的结束位置
list1 = ['柯南', '蜡笔小新', '火影忍者', '海贼王', '奥特曼', '海贼王']
print(list1.index('柯南'))
- list.count(x) 统计指定元素在列表中出现的个数
list1 = ['柯南', '蜡笔小新', '火影忍者', '海贼王', '奥特曼', '海贼王']
print(list1.count('海贼王'))
11.1.4 修改列表
- 通过切⽚来修改(起始就是给切⽚的内容重新赋值,但是赋值的内容必须是⼀个序列)
- 当设置了步⻓时,序列中元素的个数必须和切⽚中元素的个数保持⼀致
- 通过切⽚来删除元素
- del list[起始 : 结束]
- list1 = []
#在指定位置插入列表
list1 = ['柯南', '蜡笔小新', '火影忍者', '海贼王', '奥特曼', '海贼王']
list1[5] = '死神'
print(list1)
#del 删除
list1 = ['柯南', '蜡笔小新', '火影忍者', '海贼王', '奥特曼', '海贼王']
del list1[5]
print(list1)
# 通过切片的方式来修改列表
list1 = ['柯南', '蜡笔小新', '火影忍者', '海贼王', '奥特曼', '海贼王']
list1[4::] = 'abcd'
list1[4::] = 'a'
list1[4::] = 123
# 替换的数据必须是一个序列
print(list1[4::])
list1[0:0] = ['死神']
list1[::2] = 'abc'
#删除列表内容
list1[4:] = ''
list1[4:] = []
print(list1)
11.1.5 列表的方法
- append() 像列表的最后添加⼀个元素
list1 = ['柯南', '蜡笔小新', '火影忍者', '海贼王', '奥特曼', '海贼王']
list1.append('死神')
- insert(arg1,arg2) 像列表指定位置插⼊⼀个元素 参数1:要插⼊的位置 参数2:要插⼊的元素
list1 = ['柯南', '蜡笔小新', '火影忍者', '海贼王', '奥特曼', '海贼王']
list1.insert(4, '死神')
- extend(iterable) 使⽤⼀个新的序列来扩展当前序列(它会将该序列的中元素添加到列表中) 参数需要传递⼀个序列
list1 = ['柯南', '蜡笔小新', '火影忍者', '海贼王', '奥特曼', '海贼王']
list1.extend(['死神', '机器猫'])
- pop() 根据索引删除并返回指定元素
list1 = ['柯南', '蜡笔小新', '火影忍者', '海贼王', '奥特曼', '海贼王']
res = list1.pop(3)
print(res)
- remove() 删除指定元素 (如果相同值的元素有多个,只会删除第⼀个)
list1 = ['柯南', '蜡笔小新', '火影忍者', '海贼王', '奥特曼', '海贼王']
list1.remove('海贼王')
- reverse() 翻转列表
list1 = [1, 4, 3, 7, 5, 6, 8]
list1.reverse()
- sort(key=None,reverse=False) ⽤来对列表中的元素进⾏排序 reverse:True反序;False 正序
list1 = [1, 4, 3, 7, 5, 6, 8]
list1.sort(reverse=True)
print(list1)
11.1.6 列表的坑
list1 = ['柯南', '蜡笔小新', '火影忍者', '海贼王', '奥特曼']
# 将索引为奇数的元素删除 ['java','c','c#']
for item in list1:
if list1.index(item) % 2 != 1:
list1.pop(list1.index(item))
print(list1) # ['蜡笔小新', '火影忍者', '奥特曼']
这是因为列表用pop之后,后面的索引都会自动减1
第六讲作业
- 现在有 a = [1,2,3,4,5,6] ⽤多种⽅式实现列表的反转([6,5,4,3,2,1]) 并写出推导过程
a = [1, 2, 3, 4, 5, 6]
print("方法一:", a[::-1])
a.reverse()
print("方法二:", a)
a.sort(reverse=True)
print("方法三:", a)
- 给⽤户9次机会 猜1 - 10 个数字随机来猜数字。如果随机的数字和⽤户输⼊的数字⼀致则表示正确,如果不⼀致则表示错误。最终结果要求⽤户怎么也猜不对
import random
i = 9
while i > 0:
# 电脑随机数字computer
computer = random.randint(1, 10)
# user用户输入数字
user = int(input("请您输入1-10其中一个数字:"))
# 当用户中奖时再次随机更换电脑数字
while user == computer:
computer = random.randint(1, 10)
# 当用户不再中奖则跳出
if user != computer:
break
# i是计数器
i -= 1
str_1 = "您输入的数字是:{},开奖号码是:{}".format(user, computer)
str_2 = "您输入的数字是:{},开奖号码是:{},您9次机会已用完".format(user, computer)
if i == 0:
print(str_2)
else:
print(str_1)
方法二:
list1 = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
i = 1
while i < 10:
num = int(input("请输入1~10数字:"))
list1.remove(num)
print("猜错了,重新输入")
i += 1
print("正确答案是%s"%list1[0])
- 有两个列表 lst1 = [11, 22, 33] lst2 = [22, 33, 44]获取内容相同的元素
# 3. 有两个列表 lst1 = [11, 22, 33] lst2 = [22, 33, 44]获取内容相同的元素
list1 = [11, 22, 33]
list2 = [22, 33, 44]
for a in list1:
for b in list2:
a = int(a)
b = int(b)
if a == b:
print("list1位置:", list1.index(a), a, end="\t")
print("list2位置:", list2.index(b), b)
- 现在有8位⽼师,3个办公室,要求将8位⽼师随机的分配到三个办公室中
import random
teachers = ["赵老师", "钱老师", "孙老师", "李老师", "周老师", "吴老师", "郑老师", "王老师"]
room = [[], [], []]
for teacher in teachers:
room_num = random.randint(0, 2)
room[room_num].append(teacher)
print("房间1有这几位老师:", room[0])
print("房间2有这几位老师:", room[1])
print("房间3有这几位老师:", room[2])
- 要求从键盘输⼊⽤户名和密码,校验格式是否符合规则,如果不符合,打印出不符合的原因,并提示重新输⼊
- ⽤户名⻓度6-20,⽤户名必须以字⺟开头
- 密码⻓度⾄少6位,不能为纯数字,不能有空格
while True:
# 获取用户名输入
username = input("请输入用户名:")
if username == 'quit':
break
# 校验用户名格式是否在6-20之间,查看用户名是不是以字母开头
if 6 > len(username) or len(username) > 20 or username[0] not in "abcdefghijklmnopqrstuvvwxyaABCDEFGHIJKLMNOPQRTSUVWXYZ":
print(username[0])
print("请输入有效的用户名,长度6-20,且必须以字母开头")
# print("请重新输入!!!")
continue
# 获取密码输入
passwd = input("请输入密码:")
# 校验密码格式6位,不能为纯数字,不能有空格
if len(passwd) < 6 or passwd.isdigit() or " " in passwd:
print("密码长度至少6位,不能为纯数字,不能有空格")
print("请重新输入")
# 如果不正确直接重新开始 ,所以使用continue
continue
print("校验成功!!,请输入quit退出。")
11.2 元组
- 元组简介
- 元组表现形式tuple

tuple1 = ()
print(type(tuple1), tuple1)
- 元组是⼀个不可变序列(⼀般当我们希望数据不改变时,我们使⽤元组,其他情况下基本都⽤列表)
- 使⽤()创建元组
- 元组不是空元组⾄少有⼀个 逗号(,) 当元组不是空元组时括号可以省略
- 元组解包指将元组当中的每⼀个元素都赋值给⼀个变量
tuple1 = (1, True, None, [])
print(type(tuple1), tuple1)
print(tuple1[2])
tuple1 = 10
# 类型是int
tuple2 = 10,
# 类型是tuple
tuple3 = (10)
# 类型是int
tuple4 = (10,)
# 类型是tuple
print(type(tuple1))
print(type(tuple2))
print(type(tuple3))
print(type(tuple4))
-
结论:
- tuple2 = 10, # 当你创建元组的时候,可以省略括号
- 如果你创建的不是一个空元祖,那么元组里面必须要有一个逗号
-
修改元组:元组中的元素值是不允许修改的,但我们可以对元组进行连接组合
tuple1 = (1, 2.3)
tuple2 = ('a', 'b','c')
# 以下修改元组元素操作是非法的。
# tuple1[0] = 100
# 创建一个新的元组
tuple3 = tuple1 + tuple2
print (tuple3)
- 删除元组:元组中的值是不允许删除的,但我们可以使用del语句来删除整个元组
tuple1= ('a', 'b','c')del tuple1print(tuple1)
输出会报错:NameError: name ‘tuple1’ is not defined
11.2.1 拆包
- 数据的拆包,只要是一个序列,就可以进行拆包
- 元组的拆包
tuple1 = (1, 2, 3, 4)
a, *b, c = tuple1 # *是一个通配符,一个元组里面通配符只能有一个
print(a)
print(b)
print(c)
- 字符串拆包
字符串的拆包
s = 'sagdvdf'
a, *b, c = s # *是一个通配符,一个字符串里面通配符只能有一个
print(a)
print(b)
print(c)
- 列表的拆包
list1 = [1, 2, 3, 4, 5]
a, *b, c = list1 # *是一个通配符,一个列表里面通配符只能有一个
print(a)
print(b)
print(c)
11.3 字典
11.3.1字典的基本介绍

- 字典属于⼀种新的数据结构称为映射(mapping)
- 字典的作⽤和列表类似,都是⽤来存储对象的容器
- 列表存储数据的性能好,但是查询数据的性能差,字典正好与之相反
- 在字典中每⼀个元素都有唯⼀的名字,通过这个唯⼀的名字可以找到指定的元素
- 这个唯⼀的名字我们称之为key 通过key可以快速查询value 也可以称之为值
- 字典我们也称之为键值对(key-value)结构
- 每个字典中都可以有多个键值对,⽽每⼀个键值对我们称其为⼀项(item)
- 创建⼀个有数据的字典 语法 {key:value}
- 字典的值可以是任意对象 字典的键可以是任意的不可变对象(int str bool tuple…)
- 字典的键是不能重复的,如果出现重复的后⾯的会替换前⾯的
11.3.2 字典的使⽤
- dict()函数来创建字典
- get(key[,default]) 根据键来获取字典的值。第⼆个参数可以指定⼀个默认值,当获取不到值的时候会返回默认值
dict1 = {} # 创建空字典
- update() 将其他字典的key-value添加到当前的字典当中
dict1 = { 'name': '杨过', 'age': 18, 'gender': '男', 'skill': '黯然销魂掌',}
# dict.update() 将其他字典中的数据添加到这个字典当中来
dict1.update({'age': 1, '2': 2})
print(dict1)
- del 删除字典中的key-value
#del 关键字删除
del dict1['1']
- popitem() 删除字典最后的⼀个key-value 这个⽅法是有返回值的。删除之后它会将删除的key-value作为返回值返回
dict.popitem()
#不需要传递参数,会默认删除最后一个键值对
res = dict1.popitem()
# 返回值是删除的内容
print(res)
- pop(key[,default]) 根据key删除⾃定中的value。第⼆个参数可以指定⼀个默认值,当获取不到值的时候会返回默认值
# dict.pop(key, [default])
res = dict1.pop('3', 'key不存在')
# 当不存在这个key的时候,会返回你设置的默认值
print(res)print(dict1)
11.3.3 深拷贝和浅拷贝
- 浅拷贝(copy):拷贝父对象,不会拷贝对象的内部的子对象。
import copy# 浅拷贝 :只能拷贝第一层的数据,不能拷贝第二层乃至更多层的数据独立出来
dict1 = {'name': 123, 'data': [1, 2, 3]}
dict2 = copy.copy(dict1)
dict1['name'] = 456
dict1['data'][1] = 456
print(dict1,dict2)
print(id(dict1), id(dict2))
输出结果:
{‘name’: 456, ‘data’: [1, 456, 3]} {‘name’: 123, ‘data’: [1, 456, 3]}
2064326258832 2064326258904
- 深拷贝(deepcopy): copy 模块的 deepcopy 方法,完全拷贝了父对象及其子对象。
import copy
dict1 = {'name': 123, 'data': [1, 2, 3]}
dict2 = copy.deepcopy(dict1)
dict1['data'][1] = 456
print(dict1, dict2)
print(id(dict1['data']), id(dict2['data']))
print(id(dict1), id(dict2))
输出结果:
{‘name’: 123, ‘data’: [1, 456, 3]} {‘name’: 123, ‘data’: [1, 2, 3]}
2011805403272 2011805404232
2011802759312 2011803561632
11.3.4 遍历字典
- 我们主要可以通过3种⽅式对字典进⾏遍历
- keys() 该⽅法返回字典所有的key
- values() 该⽅法返回⼀个序列 序列中保存有字典的值
- items() 该⽅法会返回字典中所有的项 它返回⼀个序列,序列中包含有双值⼦序列 双值分别是 字典中的key和value
dict1 = {
'name': '杨过',
'age': 18,
'gender': '男',
'skill': '黯然销魂掌',
}
# keys()
for k in dict1.keys():
print(dict1[k])
# values()
for v in dict1.values():
print(v)
# items()
for k, v in dict1.items():
print(k, '=', v)
11.4 集合
11.4.1 集合简介
- 集合表现形式set 集合和列表⾮常相似
- 不同点
- 集合只能存储不可变对象
- 集合中存储的对象是⽆序的
- 集合不能出现重复元素
- 使⽤{}来创建集合
- 可以通过set()来将序列和字典转换成集合
- len() 使⽤len()来获取集合中元素的数量
- add()像集合中添加元素
# 添加元素
set.add(元素)
s = set()
s.add(1)
print(s)
- update()将⼀个集合中的元素添加到另⼀个集合当中
set.update()
s.update({2, 3, 4, 5})
print(s)
- pop()随机删除集合中的⼀个元素⼀般是删除第⼀个元素
# set.pop()
s={2, 3, 4, 5}
s.pop()
print(s)
- remove() 删除集合中指定的元素
# set.remove() 指定元素进行删除s={2, 3, 4, 5}s.remove(4)print(s)
- clear() 清空集合
set.clear()
11.4.2 集合的运算
- & 交集运算==>相同部分
- | 并集运算 ==>两个集合合并,去除重复部分
- ‘- 差集运算’==>S1-S2去除相同保留S1不同部分,S2-S1去除相同保留S2不同部分
- ‘^ 亦或集’==>去除相同保留S1和S2不同部分
s1 = {1, 2, 3, 4}
s2 = {3, 4, 5, 6}
# 集合的运算
# & 交集运算
print(s1 & s2)
# | 并集运算
print(s1 | s2 )
# - 差集运算
print(s1 - s2)
print(s2 - s1)
# ^ 亦或集
print(s1 ^ s2)
- ‘<= 检查⼀个集合是否是另⼀个集合的⼦集’ 结果是True or False
- ‘< 检查⼀个集合是否是另⼀个集合的真⼦集’
- ‘>=检查⼀个集合是否是另⼀个集合的超集’
- ‘>检查⼀个集合是否是另⼀个集合的真超集’
a = {1, 2, 4}
b = {1, 2, 3, 4, 5}
# <= 检查⼀个集合是否是另⼀个集合的⼦集
result = a <= b
# < 检查⼀个集合是否是另⼀个集合的真⼦集
result1 = a < b
# >=检查⼀个集合是否是另⼀个集合的超集
result2 = a >= b
# >检查⼀个集合是否是另⼀个集合的真超集
result3 = a >= b
print(result)
print(result1)
print(result2)
print(result3)
第七讲作业
a = {“name”:“123”,“data”:{“result”:[{“src”:“python1”},{“src”:“python2”},{“src”:“python3”}]}} 找到python1/python2/python3
a = {"name": "123","data": {"result": [{"src": "python1"}, {"src": "python2"}, {"src": "python3"}]}}
b = a.get("data").get("result")for i in b:
print(i.get("src"))
- 有如下值列表[11,22,33,44,55,66,77,88,99,90], 将所有⼤于66的值保存⾄字典的第⼀个key的值中,将⼩于66值保存⾄第⼆个key的值中。
a = [11, 22, 33, 44, 55, 66, 77, 88, 99, 90]list1=[]list2=[]dict1={}
for i in a:
if i>66:
list1.append(i)
elif i<66:
list2.append(i)
dict1["key1"]=list1
dict1["key2"]=list2
print(dict1)
十二 函数
12.1 函数简介
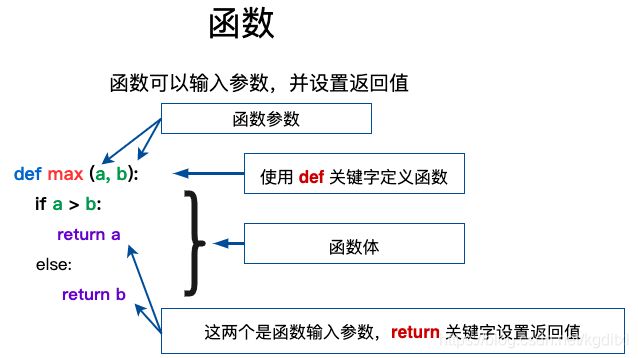
- 函数也是⼀个对象
- 函数⽤来保存⼀些可执⾏的代码,并且可以在需要时,对这些语句进⾏多次调⽤
语法
def 函数名([形参1,形参2,形参3…]):
代码块
- 注意:函数名必须符合标识符的规范(可以包含字⺟、数字、下划线但是不能以数字开头)
- print是函数对象 print()是调⽤函数
12.2 函数的参数
def fun(a, b):
# 函数的参数就是相当于在函数内部定义了这两个变量, 但是并没有给他们赋值 ab就是一个形参(形式上的参数)
print(a + b)
fun(1, 2)
# 调用函数 ,如果有形参,那么必须传递实参(实际的参数)
12.2.1 形参和实参
- 形参(形式参数) 定义形参就相当于在函数内部声明了变量,但是并不是赋值
- 实参(实际参数)指定了形参,那么在调⽤函数时必须传递实参,实参将会赋值给对应的形参,简单来说有⼏个形参就要有⼏个实参
12.2.2 函数的传递⽅式
- 定义形参时,可以为形参指定默认值。指定了默认值以后,如果⽤户传递了参数则默认值不会⽣效。如果⽤户没有传递,则默认值就会⽣效
- 位置参数:位置参数就是将对应位置的实参赋值给对应位置的形参
def fun(a, b, c=20): # c=20 这个就是给c设置了一个默认值, 当设置了默认值之后,可以不传递这个参数的实参,那么这个时候这个参数的值就是这个默认值, 但是你如果传递了这个实参,那么就会覆盖掉这个默认值
print(a)
print(b)
print(c)
fun(1, 2, 3)
- 关键字参数 : 关键字参数可以不按照形参定义的顺序去传递,⽽根据参数名进⾏传递
# 2. 关键字传参 可以不按照定义形参的顺序去传递实参,根据参数名进行传递参数
def fun(a, b, c=20):
print(a)
print(b)
print(c)
fun(a=1, c=3, b=2)
- 混合使⽤位置参数和关键字参数的时候必须将位置参数写到关键字参数前⾯去
# 位置传参和关键字传参的混合使用: 位置传参必须放到关键字传参的前面
def fun(a, b, c=20):
print(a)
print(b)
print(c)
fun(1, b=2, c=3)
12.3 不定⻓参数
- 定义函数时,可以在形参前⾯加⼀个*,这样这个形参可以获取到所有的实参,它会将所有的实参保存到⼀个元组中
- 带*号的形参只能有⼀个,可以和其他参数配合使⽤
- 带*形参只能接受位置参数,不能接受关键字参数
- 带**形参可以接收其他的关键字参数,它会将这些参数统⼀保存到字典当中。字典的key就是参数的名字,字典的value就是参数的值
- 带**形参只有⼀个,并且必须写在所有参数的后⾯
# 不定长参数: 不知道会接受几个实参,所以用不定长参数(形参)来接受实参
def fun(c, *args, b):
# *a就是不定长参数 当*a和位置传参混合使用的时候,位置参数一定要放到*a的前面
# 当*a和关键字传参一起使用的时候,关键字传参要放到后面去
# 顺序: 位置参数, *args, 关键字参数, **kwargs
print(*args)
print(args)
r = 0
for i in a:
r += i
print(r)
fun(2, 3, 4, 5, b=1)
四种参数传递排列顺序:位置,‘*’a,关键字,‘’** a
12.4 参数的解包
- 传递实参时,也可以在序列类型的参数前添加星号,这样它会⾃动的将序列中元素依次作为参数传递
- 要求序列中的元素的个数必须和形参的个数⼀致
def fun(a, b, c):
print(a)
print(b)
print(c)
t = (1, 2, 3)
t = 'abc'
t = {'a': 1, 'b': 2, 'c': 3}
# fun(t[0], t[1], t[2])fun(**t) #使用**t可以对参数进行拆包
第八讲作业
"""
1. 打印名⽚程序:输⼊姓名,电话号码,性别,最后打印出来名⽚
控制姓名⻓度为6-20
电话号码⻓度11
性别只能允许输⼊男或⼥
每⼀样信息不允许为空
"""
def card():
while True:
name = input("请输入姓名:")
if 6 < len(name) < 20:
break
else:
print("长度不对,请重新输入:")
while True:
Tel = input("请输入电话:")
if len(Tel) == 11:
if Tel.isdigit():
break
else:
print('格式不对,请重新输入')
# continue
while True:
gender = input("请输入性别:")
if gender == '男' or gender == '女':
break
else:
print('性别只有男女,请重新输入')
continue
return name, Tel, gender
name_card = card()
print(name_card)
"""
2. 使⽤函数求前20个斐波那契数列斐波那契数列:1,1,2,3,5,8,13,21...即: 起始
两项均为1,此后的项分别为前两项之和
"""
def fun(n):
fib = [1, 1]
for i in range(n):
fib.append(fib[-1] + fib[-2])
fibs = fib[i]
print(fibs)
fun(n=20)
"""
3. 编写⼀段代码,定义⼀个函数求1-100之间所有整数的和,并调⽤该函数打印
出结果
"""
def sum1(a, b):
r = 0
for i in range(a, b + 1):
r += i
print(r)
sum1(1, 100)
12.5 函数的返回值
return [表达式] 语句用于退出函数,选择性地向调用方返回一个表达式。不带参数值的return语句返回None。之前的例子都没有示范如何返回数值
- 返回值就是函数执⾏以后返回的结果
- 通过return来指定函数的返回值
- return后⾯可以跟任意对象,返回值甚⾄可以是⼀个函数
def fun(*args):
r = 0
for i in args:
r += i
print(r) # 这个结果仅仅只是让我们可以观测到这个r的值
# return 1
def fun1():
pass
# return 'agc' # return 后面跟的值会作为返回值返回出去, return后面的代码不在执行
return fun1
- 总结:
- fun是函数对象 打印fun打印出来的结果是id
- fun() 是函数的调用 打印fun() 打印出来的结果是函数的返回值
12.6 ⽂档字符串
- help()是Python中内置函数,通过help()函数可以查询Python中函数的⽤法
- 在定义函数时,可以在函数内部编写⽂档字符串,⽂档字符串就是对函数的说明
def fun(a, b):
"""
文档字符串
:param a:
:param b:
:return:
"""
pass
print()
help(print)
12.7 函数的作⽤域
- 作⽤域(scope)
- 作⽤域指的是变量⽣效的区域
- 在Python中⼀共有两种作⽤域
- 全局作⽤域
- 全局作⽤域在程序执⾏时创建,在程序执⾏结束时销毁
- 所有函数以外的区域都是全局作⽤域
- 在全局作⽤域中定义的变量,都是全局变量,全局变量可以在程序的任意
- 位置进⾏访问
- 函数作⽤域
- 函数作⽤域在函数调⽤时创建,在调⽤结束时销毁
- 函数每调⽤⼀次就会产⽣⼀个新的函数作⽤域
- 在函数作⽤域中定义的变量,都是局部变量,它只能在函数内部被访问
def fun():
# 声明此处的变量是全局变量
global a, b
a = 123
b = 223
print(a)
print(b)
def fun1():
print(a)
print(b)
fun1()
return a, b
print(fun())
print(a)
print(b)
12.8 命名空间
- 命名空间实际上就是⼀个字典,是⼀个专⻔⽤来存储变量的字典
- locals()⽤来获取当前作⽤域的命名空间
- 如果在全局作⽤域中调⽤locals()则获取全局命名空间,如果在函数作⽤域中调⽤locals()则获取函数命名空间
- 返回值是⼀个字典
a = 1
b = 2
c = 3
d = 4
# def fun():
# a = 2
# b = 4
# space = locals()
# print(space)
#
# pass
## fun()space = locals()
# space['abc'] = 123
print(space)
12.9 递归函数
- 递归是解决问题的⼀种⽅式,它的整体思想,是将⼀个⼤问题分解为⼀个个的⼩问题,直到问题⽆法分解时,在去解决问题
- 递归式函数有2个条件
- 基线条件 问题可以被分解为最⼩问题,当满⾜基线条件时,递归就不执⾏了
- 递归条件 可以将问题继续分解的条件
# 需求: 求10!的值
# 1! = 1
# 2! = 2*1
# 3! = 3*2*1
# print(1*2*3*4*5*6*7*8*9*10)
# 10!= 10*9! n! = n * (n-1)!
# 相当于数学里面的推导式
# 9! = 9*8!
# 。。。。。
# 1! = 1
def fun(n): # 求n! 的值
if n == 1:
return 1
return n * fun(n-1)
# n * (n-1) * fun(n-2) * 1
print(fun(10))
# 需求:求任意数的任意次幂的值
# m ** n m * m**(n-1)
# 10 ** 5
# 10 * 10 **4
# 10 ** 1 = 10
def fun(m, n): # 求m**n幂的值
if n == 1:
return m
return m * fun(m, n-1)
print(fun(10, 5))
print(fun(5, 5))
# 需求: 检测一个字符串是不是回文字符串
# 123456789987654321
# abcdefgfedcba
# 上海自来水来自海上
def fun1(s):
if len(s) < 2:
return True
elif s[0] != s[-1]:
return False
return fun1(s[1:-1])
print(fun1('abcdegfedcba'))
第九讲作业
"""
1. ⽤函数实现⼀个判断⽤户输⼊的年份是否是闰年的程序
1.能被400整除的年份
2.能被4整除,但是不能被100整除的年份
以上2种⽅法满⾜⼀种即为闰年
"""
def fun(year):
if int(year) % 400 == 0 or (int(year) % 4 == 0 and int(year) % 100 != 0):
print("{}是闰年".format(year))
else:
print("{}是非闰年".format(year))
fun(input("请输入年份:"))
"""
2. 猴⼦吃桃问题(递归):
猴⼦第⼀天摘下若⼲个桃⼦,当即吃了⼀半,还不瘾,⼜多吃了⼀个。第
⼆天早上⼜将剩下的桃⼦吃掉⼀半,⼜多吃了⼀个。以后每天早上都吃了前
⼀天剩的⼀半零⼀个。到第10天早上想再吃时,⻅只剩下⼀个桃⼦了,求第
⼀天共摘了多少桃⼦?
桃子数n
第一天:n/2+1
第二天:(n-(n/2+1))/2+1 ==>n-1/2+1
"""
def fun1(n):
if n == 1:
return 1
return (fun1(n-1) + 1) * 2
print(fun1(10))
12.10⾼阶函数
-
高阶函数的概念:
- 1.接收函数作为参数
- 2.或者将函数作为返回值返回的函数就是高阶函数
递归不是高阶函数,而是自己调用自己
list1 = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
def fun(lst):
new_list = []
for i in list1:
if i % 2 == 0:
new_list.append(i)
return new_list
print(fun(list1))
# 上面这个不属于高阶函数
list1 = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
def fun(lst):
def fun1(n):
if n % 2 == 0:
return True
new_list = []
for i in lst:
if fun1(i):
new_list.append(i)
return new_list
print(fun(list1))
# 上面这个任然不属于高阶函数
list1 = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
def fun1(n):
if n % 2 == 0:
return True
def fun2(n):
if n > 5:
return True
def fun(lst, fn): # lst=list1;fn=fun1
new_list = []
for i in lst:
if fn(i): # fn(i)就相当于fun1(i)
new_list.append(i)
return new_list
print(fun(list1, fun1)) # fun1是函数对象;把fun1可以改为fun2就直接变为大于5的数了
12.11匿名函数
- 所谓匿名,意即不再使用 def 语句这样标准的形式定义一个函数
- 匿名函数的语法: (lambda 参数列表:运算)(实参) 用于做一些简单的运算,而不用定义函数
- lambda 函数拥有自己的命名空间,且不能访问自己参数列表之外或全局命名空间里的参数
- lambda 函数可接受任意数量的参数,但只能有一个表达式。
- 为何使用 Lambda 函数?
- 当您把 lambda 用作另一个函数内的匿名函数时,会更好地展现 lambda 的强大能力。
res = (lambda a, b: a + b)(1, 3)
print(res)
c = 1
d = 2
dict1 = {
'key': (lambda a, b: a + b)(c, d)
}
print(dict1)
12.12闭包
- 将函数作为返回值也是⾼阶函数我们也称为闭包
- 闭包的好处
- 通过闭包可以创建⼀些只有当前函数能访问的变量
- 可以将⼀些私有数据藏到闭包中
- ⾏成闭包的条件
- 函数嵌套
- 将内部函数作为返回值返回
- 内部函数必须要使⽤到外部函数的变量
# 需求:创建一个函数,赋值一个变量,要求再这个变量的基础上每次和不同的数字进行相加
def fun_out(num1):
def fun_inner(num2):
res = num1 + num2
return res
return fun_inner
fun_out(1) # fun_out(1)=fun_inner
r = fun_out(1) # r=fun_out(1)相当于fun_inner
# 到这一步函数没有执行完
r(2) # r(2)相当于fun_inner(2)
print(r(2))
# 到这一步函数已经执行完毕
print(r(3)) # 从这一步看出外部函数执行后没有被销毁
# 结论:闭包里面的外部函数的变量可以保证不被销毁;
# 如果闭包使用多了会造成内存溢出,所以闭包要慎用。
# 在闭包中修改外部函数的变量
def fun_out(num1):
def fun_inner(num2):
# 如果一定要修改,需要用到nonlocal
nonlocal num1 # 这行不添加的话结果就是1,1,增加这一行结果就是1,10
# nonlocal告诉解释器此处使用的不是本地的这个变量,而是外部变量
num1 = 10
res = num1 + num2
return res
print(num1)
fun_inner(1)
print(num1)
return fun_inner
# fun_out(1)
r = fun_out(1)
r(2)
12.13装饰器的引⼊
- 我们可以直接通过修改函数中的代码来完成需求,但是会产⽣以下⼀些问题
- 如果修改的函数多,修改起来会⽐较麻烦
- 不⽅便后期的维护
- 这样做会违反开闭原则(ocp) The Open-Closed Principle
-
程序的设计,要求开发对程序的扩展,要关闭对程序的修改
-
12.14装饰器的使⽤
- 通过装饰器,可以在不修改原来函数的情况下来对函数进⾏扩展
- 在开发中,我们都是通过装饰器来扩展函数的功能的
12.15 PEP8规范
Python编码风格指南
第十讲 作业
# 请使⽤装饰器实现已存在的函数的执⾏所花费的时间
import time
def fun_out(old):
def fun_inner(*args, **kwargs): # 万能写法
begin = time.time()
print("程序开始执行了")
time.sleep(2)
print(old(*args, **kwargs))
time.sleep(2)
print("程序执行结束了")
time.sleep(2)
end = time.time()
print(end - begin)
return fun_inner
@fun_out
def power(a, b):
return a ** b
power(3, 5)
12.16 可迭代对象
- 我们已经知道可以对list、tuple、dict、set、str等类型的数据使⽤for…in…的循环语法从其中依次拿到数据进⾏使⽤,我们把这样的过程称为遍历,也叫迭代。
- 把可以通过for…in…这类语句迭代读取⼀条数据供我们使⽤的对象称之为可迭代对象(Iterable)
12.17 推导式
- 推导式分为 列表推导式、字典推导式、集合推导式等。在这⾥我们主要说其中⼀种也是⽤的最多列表推导式列表推导式是Python构建列表(list)的⼀种快捷⽅式,可以使⽤简洁的代码就创建出⼀个列表简单理解就是由⼀个旧的列表来构建出⼀个新的列表
语法
1 [表达式 for 变量 in 旧列表]
2 [表达式 for 变量 in 旧列表 if 条件]
12.18 ⽣成器
-
背景
- 通过列表推导式我们可以直接创建出⼀个列表,但是受到内存的限制,我们不可能创造出⼀个⽆限⼤的列表。⽽且创建⼀个有200万个元素的列表,会占⽤很⼤的内存空间,⽽这个时候我们仅仅需要访问列表中⼏个元素,那么后⾯的元素就占⽤着空间就是⼀种浪费的⾏为。那么我们可不可以⽤⼏个元素就创建出⼏个元素。这样在⼀定程度上就优化了内存。那么在Python中有⼀种⼀边循环⼀边计算的机制就是⽣成器
-
创建⽣成器的⽅式
-
通过列表推导式的⽅式 -
# 方法一:类似于列表推导式 list2=[i for i in range(1,10) if i % 3==0] print(list2) gen = (i for i in range(1, 10) if i % 3 == 0) print(gen) print(gen.__next__()) print(gen.__next__()) print(gen.__next__()) print(gen.__next__()) # 超过迭代次数就会停止迭代并报错 # 或者 print(next(gen)) print(next(gen)) print(next(gen)) print(next(gen)) -
通过函数来构造生成器
-
# 方法二 通过函数来构造生成器
def fun():
i = 0
while True:
i += 1
return i #此时不是生成器
r = fun()
print(r)
def fun(): # 此时的fun就是一个生成器
i = 0
while True:
i += 1
yield i # 把return改为yield
r = fun()
print(r)
def fun1():
for i in range(1, 10):
yield i
r = fun1()
# print(next(r))
# print(next(r))
res = [i for i in r]
res1 = [i for i in r] #这个列表返回为空,因为生成器的特性,数据只能用一次
print(res)
print(res1)
- 只要在函数中出现yield关键字它就是⼀个⽣成器函数
12.19 迭代器
- 迭代器是访问集合元素的⼀种⽅式。迭代器是⼀个可以记住遍历位置的对象。
- 迭代器对象从集合的第⼀个元素开始访问,直到所有元素被访问完结束。
- 可以被next()函数调⽤并不断返回下⼀个值的对象称为迭代器Iterator
- ⽣成器是可迭代的,也是迭代器
- 列表是可迭代的,但不是迭代器
- 通过iter()函数可以将可迭代的变成⼀个迭代器
list1 = [1, 2, 3, 4, 5, 6]
itr=iter(list1)
print(iter)
print(next(itr))
print(next(itr))
# __iter__自身 返回自己
# __next__下一个,拿到下一个
13 面向对象
13.1⾯向对象简介
- Python是⼀⻔⾯向对象的编程语⾔
- 所谓⾯向对象的语⾔,简单理解就是语⾔中的所有操作都是通过对象来进⾏的
- ⾯向过程
- ⾯向过程指将我们的程序分解为⼀个⼀个步骤,通过对每个步骤的抽象来完成程序、
- 这种编写⽅式往往只适⽤于⼀个功能,如果要实现别的功能,往往复⽤性⽐较低
- 这种编程⽅式符号⼈类的思维,编写起来⽐较容易
- 1.妈妈穿⾐服穿鞋出⻔
- 2.妈妈骑上电动⻋
- 3.妈妈到超市⻔⼝放好电动⻋
- 4.妈妈买⻄⽠
- 5.妈妈结账
- 6.妈妈骑电动⻋回家
- 7.到家孩⼦吃⻄⽠
- ⾯向对象的编程语⾔,关注的是对象,⽽不注重过程,对于⾯向对象⼀切皆对象
- 以上⽅式可以⽤ 孩⼦妈妈给孩⼦买⽠来解决
- ⾯向对象的编程思想,将所有功能统⼀保存到对应的对象中,要使⽤某个功能,直接找到对应的对象即可
- 这种编码⽅式⽐较容易阅读,并且易于维护,容易复⽤。但是编写的过程中不太符合常规的思维,编写相对麻烦
13.2. 类(class)
- 我们⽬前学习的都是Python的内置对象,但是内置对象并不都能满⾜我们的需求,所以我们在开发中经常要⾃定义⼀些对象
- 类简单理解它就是相当于⼀个图纸,在程序汇总我们需要根据类来创建对象。
- 类就是对象的图纸
- 我们也称对象是类的实例(instance)
- 如果多个对象是通过⼀个类创建的,我们称这些对象是⼀类对象
# 语法
class 类名([⽗类]):
pass
- 类也是⼀个对象,类就是⽤来创建对象的对象
- 可以像对象中添加变量,对象中的变量称之为属性 语法:对象.属性名 = 属性值
13.3. 类的定义
- 类和对象都是对现实⽣活中事物的抽象
- 事物包含两部分
- 数据(属性)
- ⾏为(⽅法)
- 调⽤⽅法 对象.⽅法名()
- ⽅便调⽤和函数调⽤的区别:如果是函数调⽤,调⽤时有⼏个形参,就会传递⼏个实参。如果是⽅法调⽤,默认传递⼀个参数,所以⽅法中⾄少得有⼀个形参
- 在类代码块中,我们可以定义变量和函数
- 变量会成为该类实例的公共属性,所有的该实例都可以通过 对象.属性名的形式访问
- 函数会成为该类实例的公共⽅法,所有该类实例都可以通过 对象.⽅法名的形式访问
# 定义类:class 类名(): 类名遵循大驼峰方式来命名
# 实例对象的创建:实例对象=类名()
# 设置属性:实例对象.属性名称=“属性值”
# 方法创建:直接在类里面定义一个函数(函数,只是为了让大家理解,这里这么来称呼)
# 方法的使用:实例对象.方法名()
class MyClass:
name="周慧敏" # 公共属性
def sing(self): #公共方法
print("唱歌可好听了")
print(MyClass, type(MyClass))
mc = MyClass()
mc.name = "刘亦菲"
print(mc.name)
mc1 = MyClass()
print(mc1.name)
mc1.sing()
13.4 参数self
13.4.1 属性和⽅法
- 类中定义的属性和⽅法都是公共的,任何该类实例都可以访问
- 属性和⽅法的查找流程
- 当我们调⽤⼀个对象的属性时,解析器会现在当前的对象中寻找是否还有该属性,如果有,则直接返回当前的对象的属性值。如果没有,则去当前对象的类对象中去寻找,如果有则返回类对象的属性值。如果没有就报错
- 类对象和实例对象中都可以保存属性(⽅法)
- 如果这个属性(⽅法)是所以的实例共享的,则应该将其保存到类对象中
- 如果这个属性(⽅法)是摸个实例独有的。则应该保存到实例对象中
- ⼀般情况下,属性保存到实例对象中 ⽽⽅法需要保存到类对象中
13.4.2 self
- self在定义时需要定义,但是在调⽤时会⾃动传⼊。
- self的名字并不是规定死的,但是最好还是按照约定是⽤self
- self总是指调⽤时的类的实例
class Person:
name = "刘亦菲"
def speak(self):
print("大家好,我是{}".format(self.name))
p1 = Person()
p1.name = "刘亦菲"
p2 = Person()
p2.name = "周慧敏"
p1.speak()
p2.speak()
13.5 特殊⽅法
- 在类中可以定义⼀些特殊⽅法也称为魔术⽅法
- 特殊⽅法都是形如 xxx()这种形式
- 特殊⽅法不需要我们调⽤,特殊⽅法会在特定时候⾃动调⽤
class person:
print("这个是类中的代码")
def __init__(self, name, age, weight):
self.name = name
self.age = age
self.weight = weight
def speak(self):
print(f"我的名字叫{self.name},我的年龄是{self.age}岁,体重是{self.weight}")
p1 = person("bill", 15, "30kg")
p2 = person("jason", 35, "70kg")
p1.speak()
# p2 = person("jason", 35, "70kg")
p2.speak()
13.6 封装
-
出现封装的原因:我们需要⼀种⽅式来增强数据的安全性
- 属性不能随意修改
- 属性不能改为任意的值
-
封装是⾯向对象的三⼤特性之⼀
-
封装是指隐藏对象中⼀些不希望被外部所访问到的属性或⽅法
-
我们也可以提供给⼀个getter()和setter()⽅法是外部可以访问到属性
- getter() 获取对象中指定的属性
- setter() ⽤来设置对象指定的属性
-
使⽤封装,确实增加了类的定义的复杂程度,但是它也确保了数据的安全
- 隐藏属性名,使调⽤者⽆法随意的修改对象中的属性
- 增加了getter()和setter()⽅法,很好控制属性是否是只读的
- 使⽤setter()设置属性,可以在做⼀个数据的验证
- 使⽤getter()⽅法获取属性,使⽤setter()⽅法设置属性可以在读取属
性和修改属性的同时做⼀些其他的处理
-
可以为对象的属性使⽤双下划线开头 __xxx。双下划线开头的属性,是对象
的隐藏属性,隐藏属性只能在类的内部访问,⽆法通过对象访问 -
其实隐藏属性只不过是Python⾃动为属性改了⼀个名字
_类名__属性名 例如 __name -> _Person__name -
这种⽅式实际上依然可以在外部访问,所以这种⽅式我们⼀般不⽤。⼀般我
们会将⼀些私有属性以_开头 -
⼀般情况下,使⽤_开头的属性都是私有属性,没有特殊情况下不要修改私有
属性
13.7 property装饰器
- 我们可以使⽤@property装饰器来创建只读属性,@property装饰器会将⽅
法转换为相同名称的只读属性,可以与所定义的属性配合使⽤,这样可以防⽌
属性被修改
13.8 继承
13.8.1 继承简介
- 继承是⾯向对象三⼤特性之⼀
- 通过继承我们可以使⼀个类获取到其他类中的属性和⽅法
- 在定义类时,可以在类名后⾯的括号中指定当前类的⽗类(超类、基类)
- 继承提⾼了类的复⽤性。让类与类之间产⽣了关系。有了这个关系,才有了多态的特性
13.8.2 ⽅法重写
-
如果在⼦类中有和⽗类同名的⽅法,则通过⼦类实例去调⽤⽅法时,会调⽤⼦类的⽅法
⽽不是⽗类的⽅法,这个特点我们称之为⽅法的重写(覆盖)
-
当我们调⽤⼀个对象的⽅法时:
-
会优先去当前对象中寻找是否具有该⽅法,如果有则直接调⽤
-
如果没有,则去当前对象的⽗类中寻找,如果⽗类中有则直接调⽤⽗类中的⽅法
-
如果没有,则去⽗类中的⽗类寻找,以此类推,直到找到object,如果依然没有找到就报错了
-
13.8.3 super()
- super()可以获取当前类的⽗类
- 并且通过super()返回对象调⽤⽗类⽅法时,不需要传递self
13.8.4 多重继承
- 在Python中是⽀持多重继承的。也就是我们可以为⼀个类同时指定多个⽗类
- 可以在类名的()后边添加多个类,来实现多重继承
- 多重继承,会使⼦类同时拥有多个⽗类,并且会获取到所有⽗类中的⽅法
- 在开发中没有特殊情况,应该尽量避免使⽤多重继承。因为多重继承会让我
们的代码更加复杂 - 如果多个⽗类中有同名的⽅法,则会先在第⼀个⽗类中寻找,然后找第⼆
个,找第三个…前⾯会覆盖后⾯的
13.8.5 多态
- 多态是⾯向对象的三⼤特性之⼀。从字⾯理解就是多种形态
- ⼀个对象可以以不同形态去呈现
- ⾯向对象三⼤特性
- 封装 确保对象中数据的安全
- 继承 保证了对象的扩展性
- 多态 保证了程序的灵活性
- Python中多态的特点
- 1、只关⼼对象的实例⽅法是否同名,不关⼼对象所属的类型;
- 2、对象所属的类之间,继承关系可有可⽆;
- 3、多态的好处可以增加代码的外部调⽤灵活度,让代码更加通⽤,兼容
性⽐较强; - 4、多态是调⽤⽅法的技巧,不会影响到类的内部设计。
13.8.6 属性和⽅法
- 属性
- 类属性,直接在类中定义的属性是类属性
- 类属性可以通过类或类的实例访问到。但是类属性只能通过类对象来修
改,⽆法通过实例对象修改 - 实例属性 通过实例对象添加的属性属于实例属性
- 实例属性只能通过实例对象来访问和修改,类对象⽆法访问修改
- ⽅法
- 在类中定义,以self为第⼀个参数的⽅法都是实例⽅法
- 实例⽅法在调⽤时,Python会将调⽤对象以self传⼊
- 实例⽅法可以通过类实例和类去调⽤
- 当通过实例调⽤时,会⾃动将当前调⽤对象作为self传⼊
- 当通过类调⽤时,不会⾃动传递self,我们必须⼿动传递self
- 类⽅法 在类的内容以@classmethod 来修饰的⽅法属性类⽅法
- 类⽅法第⼀个参数是cls 也会⾃动被传递。cls就是当前的类对象
- 类⽅法和实例⽅法的区别,实例⽅法的第⼀个参数是self,类⽅法的第⼀
个参数是cls - 类⽅法可以通过类去调⽤,也可以通过实例调⽤
- 静态⽅法
- 在类中⽤@staticmethod来修饰的⽅法属于静态⽅法
- 静态⽅法不需要指定任何的默认参数,静态⽅法可以通过类和实例调⽤
- 静态⽅法,基本上是⼀个和当前类⽆关的⽅法,它只是⼀个保存到当前类
中的函数 - 静态⽅法⼀般都是些⼯具⽅法,和当前类⽆关
13.8.7 单例模式
# __new__()⽅法
# __new__()⽅法⽤于创建与返回⼀个对象。在类准备将⾃身实例化时调⽤。
class Demo(object):
def __init__(self):
print("__init__")
def __new__(cls, *args, **kwargs):
print("__new__")
d = Demo()
"""
练习
以上代码打印输出的顺序?(C)
A.__init__,__new__
B.__init__
C.__new__
D.__new,__init__
"""
注意
- _new_()⽅法⽤于创建对象
- _init_()⽅法在对象创建的时候,⾃动调⽤
- 但是此处重写了⽗类的__new__()⽅法,覆盖了⽗类__new__()创建对象的功能,所以对象
并没有创建成功。所以仅执⾏__new__()⽅法内部代码
对象创建执⾏顺序
- 1.通过_new_()⽅法创建对象
- 2.并将对象返回,传给_init_()
class Demo(object):
def __init__(self):
print("__init__")
def __new__(cls, *args, **kwargs):
print("__new__")
return super().__new__(cls)
d = Demo()
"""
练习
以上代码打印输出的顺序?(D)
A.__init__,__new__
B.__init__
C.__new__
D.__new,__init__
"""
"""
注意
1.在创建对象时,⼀定要将对象返回,在会⾃动触发__init__()⽅法
2.__init__()⽅法当中的self,实际上就是__new__返回的实例,也就是该对象
__init__()与__new__()区别
__init__实例⽅法,__new__静态⽅法
__init__在对象创建后⾃动调⽤,__new__创建对象的⽅法
"""
13.8.8 单例模式
-
单例模式介绍
- 单例模式是⼀种常⽤的软件设计模式。也就是说该类只包含⼀个实例。
- 通过单例模式可以保证系统中⼀个类只有⼀个实例⽽且该实例易于外界访问,从⽽⽅便对实例
个数的控制并节约系统资源。如果希望在系统中某个类的对象只能存在⼀个,单例模式是最好
的解决⽅案。 - 通常应⽤在⼀些资源管理器中,⽐如⽇志记录等。
-
单例模式实现
- 当对象不存在时,创建对象
- 当对象存在时,永远返回当前已经创建对象
class single(object):
__isinstance = None
def __new__(cls, *args, **kwargs):
if cls.__isinstance is None:
cls.__isinstance = super().__new__(cls)
return cls.__isinstance
else:
return cls.__isinstance
a = single()
b = single()
print(id(a))
print(id(b))
13.9 模块
- 模块化指将⼀个完整的程序分解成⼀个个的⼩模块
- 通过将模块组合,来搭建出⼀个完整的程序
- 模块化的优点
- ⽅便开发
- ⽅便维护
- 模块可以复⽤
13.9.1 模块的创建
- 在Python当中⼀个py⽂件就是⼀个模块
- 在⼀个模块中引⼊外部模块 import 模块名(模块名就是py⽂件)
- 可以引⼊同⼀个模块多次,但是模块的实例只会创建⼀次
- import 模块名 as 模块别名
- 在⼀个模块内部都有⼀个_name_。通过它我们可以获取模块的名字
- 如果py⽂件直接运⾏时,那么
__name__默认等于字符串’__main__’。
__name__属性值为__main__的模块是主模块。⼀个程序中只有⼀个主模块
13.9.2 模块的使⽤
- 访问模块中的变量 语法是 模块名.变量名
- 访问模块中的函数 语法是 模块名.函数名
- 访问模块中的对象 语法是 模块名.对象名
- 我们也可以引⼊模块中部分内容 语法 from 模块名 import 变量,变量…
- 还有⼀种引⼊⽅式 语法 from 模块名 import 变量 as 别名
13.10 异常
13.10.1 异常简介
- 程序在运⾏过程中可能会出现⼀些错误。⽐如: 使⽤了不存在的索引,两个不
同类型的数据相加…这些错误我们称之为异常 - 处理异常 程序运⾏时出现异常,⽬的并不是让我们的程序直接终⽌!Python
是希望在出现异常时,我们可以编写代码来对异常进⾏处理
13.10.2 异常的传播
- 当在函数中出现异常时,如果在函数中对异常进⾏了处理,则异常不会在进
⾏传播。如果函数中没有对异常进⾏处理,则异常会继续向函数调⽤传播。
如果函数调⽤处处理了异常,则不再传播异常,如果没有处理则继续向调⽤
处传播。直到传递到全局作⽤域(主模块)如果依然没有处理,则程序终⽌,并
显示异常信息。 - 当程序运⾏过程中出现异常以后,所有异常信息会保存到⼀个异常对象中。
⽽异常传播时,实际上就是异常对象抛给了调⽤处
13.10.3 异常对象
try语句
try:
代码块(可能出现错误的语句)
except 异常类型 as 异常名:
代码块(出现错误以后的处理⽅式)
except 异常类型 as 异常名:
代码块(出现错误以后的处理⽅式)
except 异常类型 as 异常名:
代码块(出现错误以后的处理⽅式)
....
else:
代码块(没出错时要执⾏的语句)
finally:
代码块(是否出错该代码块都会执⾏)
try是必须的 else有没有都可以
except和finally⾄少有⼀个
14 文件操作
14.1 ⽂件打开
- ⽂件(file) 通过Python程序来对计算机中的各种⽂件进⾏增删改查的操作 ⽂
件也叫I/O(Input/Output) - ⽂件的操作步骤
- 打开⽂件
- 对⽂件进⾏各种操作(读、写)然后保存
- 关闭⽂件
- ⽂件会有⼀个返回值。返回⼀个对象,这个对象就表示的是当前的⽂件
file_name = 'demo.txt'
file_obj = open(file_name)
print(file_obj)
14.2 关闭⽂件
- 调⽤close()⽅法来关闭⽂件
- with…as 语句不⽤写close()来关闭。它⾃带关闭
file_name = 'demo.txt'
# open打开文件
file_obj = open(file_name)
content = file_obj.read()
print(content)
# 关闭文件
file_obj.close()
file_obj.read()
# with 打开文件,不需要手动关闭
try:
with open(file_name) as f:
print(f.read())
except Exception as e:
print('文件不存在', e)
print(f.read())
14.3 读取⽂件
- 通过read()来读取⽂件的内容
- 调⽤open()来打开⼀个⽂件,可以将⽂件分为2中类型
- ⼀种 纯⽂本⽂件(使⽤utf-8编码编写的⽂件)
- ⼀种 ⼆进制⽂件(图⽚ mp3 视频…)
- open()打开⽂件时,默认是以⽂本⽂件的形式打开的 open()默认的编码
为None。所以处理⽂本⽂件时要指定编码
file_name = 'demo.txt'
try:
with open(file_name, encoding='utf-8') as f:
print(f.read(7))
# help(f.read)
except Exception as e:
print('文件不存在', e)
14.3.1 较⼤⽂件的读取
- 通过read()读取⽂件内容时会将⽂件中所有的内容全部读取出来。如果对于
读取的⽂件⽐较⼤的话。会⼀次性的将⽂件加载到内容中。容易导致内存泄
露。所以对于较⼤的⽂件。不要直接调⽤read() - read()可以接收⼀个size作为的参数。该参数⽤来指定要读取字符的数量。默
认值为-1.-1也就是要读取全部的内容 - 每次读取都会从上次读取到的位置开始。如果字符的数量⼩于size。则会读
取所有的。如果读取到最后的⽂件。则会返回空串 - readline() 该⽅法⽤来读取⼀⾏
- readlines() 该⽅法⽤于⼀⾏⼀⾏的读取内容,它会⼀次性将读取到的内容封
装到⼀个列表当中返回
14.4 ⽂件的写⼊
- write()来向⽂件中写⼊内容
- 该⽅法可以分多次向⽂件写⼊内容
- 写⼊完成之后该⽅法会返回写⼊的字符的个数
- 使⽤open()函数打开⽂件时,必须要指定打开⽂件要做的操作(读、写、追
加)。如果不指定操作类型,则默认是读取⽂件,⽽读取⽂件是不能向⽂件中
写⼊- r 表示只读
- w表示可以写。使⽤w写⼊⽂件时,如果⽂件不存在则会创建⼀个⽂件。
如果⽂件存在则会覆盖原⽂件内容
file_name = 'demo.txt'
try:
with open(file_name, 'a', encoding='utf-8') as f:
f.write('我喜欢你,嫁给我吧!')
f.write('我愿意')
f.write(str(1111))
# help(f.read)
except Exception as e:
print('文件不存在', e)
14.4.1 ⼆进制⽂件写⼊
- 读取⽂本⽂件时,size是以字符为单位。读取⼆进制⽂件时,size是以字节
为单位 - 我们⽤wb来写⼊⼆进制⽂件
From the distanceit looked like a skinny tube,
but as we got closer we could see it flesh out before our eyes.
It was tubular all right but fatter than we could see from far awa
y.
Furthermore, we were also astonished to notice that the building w
as really in two parts.
a pagoda sitting on top of a tubular one-story structure.
file_name = r'C:\Users\EDZ\Desktop\李荣浩 - 麻雀.mp3'
with open(file_name, 'rb') as f:
# print(f.read(100))
new_file = '123.mp3'
with open(new_file, 'wb') as file:
while True:
content = f.read(1024*100)
if not content:
break
file.write(content)