MMLAB学习-MMCLS项目-模块配置文件组成
源码目录
源码已上传
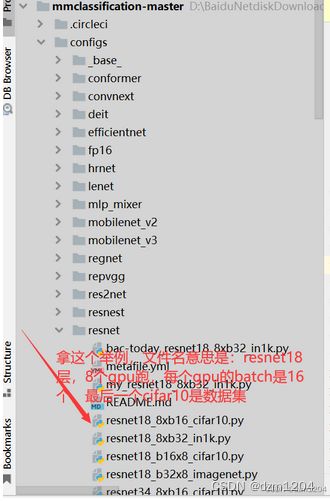
举例介绍resnet18的各个模块

分析各模块
找到模型模块,在_base_/models/resnet18.py
# model settings
model = dict(
# 所有的type值表示,在运行的时候源码走哪个类
# ImageClassifier在mmcls下的models下的classifiers
type='ImageClassifier',
# resnet在mmcls下的models下的backbones 分了任务最主要的就是backone 主要是提特征
backbone=dict(
type='ResNet',
# 网络层数、这个是可以改的、尽量不该
depth=18,
# stages越多输出的值越小,每过一个stage大小减小一半
num_stages=4,
# 输出层 可以输出多个 由自己定
out_indices=(3, ),
# 一般默认pytorch
style='pytorch'),
# neck层是对提取的特征做一个融合策略 输入大小不同 做一个全局平均池化
neck=dict(type='GlobalAveragePooling'),
# 输出层
head=dict(
# 全连接做输出
type='LinearClsHead',
# 做几分类,自己决定
num_classes=1000,
# neck最终输出多少特征图,这块就多少
in_channels=512,
# 损失、在mmcls下的models下的losses有很多损失函数,用谁直接改掉type值
loss=dict(type='CrossEntropyLoss', loss_weight=1.0),
# 评估标准,用什么评估方法评估模型可以自己定
topk=(1, 5),
))
在分析第二个,数据集策略,根据路径找到该模块
# dataset settings
# 数据格式,不是固定的,也可以自己定义 可以在mmcls下的datasets找到imagenet.py 后期会写自己的数据格式
dataset_type = 'ImageNet'
img_norm_cfg = dict(
# rgb三颜色通道的均值和标准差
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
# 预处理操作
train_pipeline = [
# 根据指定文件夹的位置把图片数据读进来
dict(type='LoadImageFromFile'),
# 随机裁剪
dict(type='RandomResizedCrop', size=224),
# 随机翻转
dict(type='RandomFlip', flip_prob=0.5, direction='horizontal'),
# 归一化操作
dict(type='Normalize', **img_norm_cfg),
# 图像数据转换成tensor
dict(type='ImageToTensor', keys=['img']),
dict(type='ToTensor', keys=['gt_label']),
# 返回什么 返回图像和标签
dict(type='Collect', keys=['img', 'gt_label'])
]
# 跟训练集预处理操作基本类似
test_pipeline = [
dict(type='LoadImageFromFile'),
# 因为测试的图片都是没有经过人工处理的,所以可能大小不一样
dict(type='Resize', size=(256, -1)),
dict(type='CenterCrop', crop_size=224),
dict(type='Normalize', **img_norm_cfg),
dict(type='ImageToTensor', keys=['img']),
# 只返回img
dict(type='Collect', keys=['img'])
]
# 训练的时候要配置的东西
data = dict(
# 单卡这里就是batchsize,多卡的话就是每张卡的batchsize,显存不够就往小调
samples_per_gpu=32,
workers_per_gpu=2,
# 指定路径
train=dict(
type=dataset_type,
# 读数据
data_prefix='data/imagenet/train',
pipeline=train_pipeline),
val=dict(
type=dataset_type,
data_prefix='data/imagenet/val',
# 读标签
ann_file='data/imagenet/meta/val.txt',
pipeline=test_pipeline),
test=dict(
# replace `data/val` with `data/test` for standard test
type=dataset_type,
data_prefix='data/imagenet/val',
ann_file='data/imagenet/meta/val.txt',
pipeline=test_pipeline))
# 评估 interval=1 表示1个epoch评估一次,评估的时候用什么标准:准确率 或者别的都可以
evaluation = dict(interval=1, metric='accuracy')
第三个,训练策略模块,根据路径找到该模块
# optimizer
# 指定优化器,学习率,动量多少,学习率衰减策略
optimizer = dict(type='SGD', lr=0.1, momentum=0.9, weight_decay=0.0001)
# 基本不用这个
optimizer_config = dict(grad_clip=None)
# learning policy
# 学习率衰减,迭代30次,60次,90次衰减,也可以自己指定
lr_config = dict(policy='step', step=[30, 60, 90])
# 表示最多迭代多少次
runner = dict(type='EpochBasedRunner', max_epochs=100)
第四个默认配置模块,根据路径找到该模块,这个模块基本上不需要该,简单认识一下
# checkpoint saving
# 表示间隔多少给epoch保存
checkpoint_config = dict(interval=1)
# yapf:disable
# 保存的日志
log_config = dict(
# 迭代多少次保存
interval=100,
hooks=[
dict(type='TextLoggerHook'),
# dict(type='TensorboardLoggerHook')
])
# yapf:enable
dist_params = dict(backend='nccl')
log_level = 'INFO'
# 表示从哪加载我们的模型
load_from = None
# 表示上一个epoch保存的checkpoint继续做训练
resume_from = None
# 单卡不用改
workflow = [('train', 1)]
总结
大多数网络的模块大同小异,认识各个模块的之后就是可以训练自己的任务,构建自己的数据集了