汉字风格迁移篇----EasyFont:一个基于风格学习的系统,可以轻松构建大规模手写字体
文章目录
- abstract
- 1 INTRODUCTION
- 2 RELATED WORK
- 3 METHOD DESCRIPTION
-
- 3.1 Selecting Input Character Set
- 3.2 Learning Font Skeleton Manifold
-
- 3.2.1 Character Matching.
- 3.2.2 Training the GP-LVM
- 3.3 Text Segmentation
- 3.4 Stroke Extraction
- 3.5 Overall Style Learning
-
- 3.5.1 Data Structures and Neural Networks.
- 3.5.2 Learning Procedure.
- 3.6 Recovering Handwriting Details
- 3.7 Handwriting Synthesis and Font Generation
- 4 EXPERIMENTS
-
- 4.1 Font Generation without Handwriting Details
-
- 4.1.1 Data Structures and Neural Networks.
- 4.1.2 Size of Input Character Set.
- 4.1.3 Comparison with a Concatenation Method.
- 4.2 Font Generation for Real Applications
-
- 4.2.1 Rendering Results.
- 4.2.2 Comparison with Deep Learning Based Methods.
- 4.2.3 Turing Tests.
- 5 DISCUSSION
- 6 CONCLUSION
- REFERENCES
abstract
生成具有大量字符的个人手写字体是一项枯燥而耗时的任务。例如,商业字体产品的官方标准GB18030-2000由27533个汉字组成。对于普通人来说,始终如一、正确地写出如此庞大的字符通常是一项不可能完成的任务。为了解决这个问题,我们提出了一个名为EasyFont的系统,通过从少量(少至1%)由普通人精心挑选的样本中学习风格,自动合成字体库中所有(例如,中文)字符的个人手写体。我们系统的主要技术贡献有两方面。首先,我们设计了一种有效的笔划提取算法,该算法从经过训练的字体骨架流形中构造最适合的参考数据,然后通过非刚性点集配准方法建立目标和参考字符之间的对应关系。其次,我们开发了一套新颖的技术来学习和恢复用户的整体手写风格和详细的手写行为。包括97名参与者的图灵测试在内的实验表明,所提出的系统生成了高质量的合成结果,与原始手写体无法区分。使用我们的系统,第一次可以自动生成用户个人风格的、任意数量的汉字的实用手写字体库。从我们的实验中还可以观察到,最近流行的基于深度学习的端到端方法无法正确处理这一任务,这意味着许多应用程序需要专家知识和手工规则。
其他关键词和短语:手写、中文、风格学习、字体
论文链接:https://doi.org/10.1145/3213767
1 INTRODUCTION
计算机字体在我们的日常生活中被广泛使用。如今,几乎所有书籍、海报、计算机、移动设备等中显示的文本都是使用主要由专业公司创建的各种字体呈现的。尽管字体产品的数量在过去二十年中迅速增长,但现有资源仍然无法满足每个人的需求,因为越来越多的人希望以自己的手写风格呈现文本,这种风格独特且充满个人信息。通过以个人手写方式发布文本而不是使用统一的打印字体与他人交流,可以使这些体验更加舒适和有趣。
然而,用大量不同的字符构建手写字体库并不容易。正如我们所知,对于只包含一个小字母的书写系统(例如英语)来说,这不是问题。例如,要创建自己的英文手写字体,只需要写26个字母和相应的大写字母。使用一些现有工具(例如FontCreator(2017)和FontLab(2017)),可以在几分钟内完成整个字体生成过程。然而,当字体库中包含的字符数增加时,任务变得更加艰巨。以中文字体为例,官方字符集GB180302000由27533个汉字组成。此外,许多汉字的形状和结构都非常复杂。图1(a)显示了一个发音为“biang”的汉字示例,该汉字有57个笔画。正如我们所知,要成为一个合格的字体库,不仅每个字符的字形应该表示正确的含义,而且所有字形的样式都必须一致。根据中国领先字体生产公司FounderType(Founder 2017)的一份报告,一个由三到五名经验丰富的字体设计师组成的团队需要12个多月才能生成一个GB18030-2000中文字体库。因此,对于一个普通人来说,用他/她自己的手写风格构建一个完整的中文字体库通常是一项不可能的任务。
提高大规模字体库生产效率的一种可能方法是利用给定字符集中字符的冗余组件(即部首、笔划集和笔划)。换句话说,通常,选定子集中的字符组成部分足以覆盖所有字符的组成部分。根据这个直观的想法,已经报道了几种方法(Lin等人,2014;Zhou等人,2011),从用户书写的许多字符生成给定用户的手写字体库。然而,存在以下两个内在缺陷,阻碍了这种方法在实际应用中的应用:(1)不能保证所有要重用的组件都能被正确提取,这妨碍了这些方法的完全自动化;(2) 不仅需要书写的字符百分比太大(超过20%),并且自动生成的字体库的质量对于实际应用程序来说并不令人满意。
吸引许多研究人员的另一个可能的解决方案是利用深度学习技术,这些技术在过去几年中非常流行。采用深度神经网络的方法不仅在许多经典计算机视觉任务(He等人,2016;Krizhevsky等人,2012;L o n g e t a L.2015;Russakovsky等人2015;Simonyan和Zisserman 2014)中获得了最先进的性能,包括图像分类、对象检测、语义分割等,但由于引入了生成对抗网络(GAN)(Goodfellow等人,2014)及其变体(Arjovsky等人,2017),在解决生成问题方面也变得越来越有竞争力(Gatys等人,2017;Isola等人,2017年)。基于深度学习的合成方法擅长为图像传输颜色/纹理样式,但无法构建具有复杂结构的新形状。脚本(如汉字)是具有高级信息和复杂结构的形状,即使其元素的位置和几何结构发生微小变化,也可能极大地改变其含义和/或风格。正如我们从实验结果中看到的,这些端到端的方法在手写体中合成汉字的任务中效果不佳。这主要是由于缺乏对有关字符的高级信息的理解,例如其基本元素(例如笔画)的构成和布局。
因此,为了建立这样一个全自动手写字体生成系统,我们认为需要解决以下两个重要问题:“我们如何自动分解输入字形,从而将其转换为统一的、可学习的数据?”以及“我们如何描述和重构给定用户的手写风格?”
本文旨在处理自动生成大型字体库的挑战性任务。我们开发了一个系统,只需要用户花很短的时间(不到30分钟)在白纸上写出少量常见的汉字。然后,系统可以自动合成同一样式的所有其他字符,并生成具有任意数量的汉字的用户个人手写字体库。需要指出的是,尽管我们目前的系统只支持中文字体的生成,但所提出的方法可以很容易地扩展到具有以下两个特性的任何其他书写系统(参见图1中的一些示例和图21中的实验结果):(1)不同字符的总数相对较大;(2) 所有字符都可以分解为给定的有限数量和类型的笔划。除非另有规定,本文中提到的字体库和字符分别指中文字体库和汉字。
如图2所示,使用我们的系统构建一个大型手写字体库非常方便,因为用户只需要在空白纸上写少量(少至1%)精心挑选的汉字,然后将它们拍照并上传到我们的系统中。在收到这些文本图像后,系统可以在大约两个小时内自动生成用户个人手写风格的GB18030-2000字体库。更具体地说,我们首先基于非刚性点集配准方法和若干启发式规则,为从输入文本图片中分割的每个单个字符图像提取每个笔划的书写轨迹。然后,利用人工神经网络(ANN)学习和重构用户的整体手写风格,可以将其分解为笔画形状风格和笔画布局风格。同时,笔迹细节(包括笔划连接和轮廓形状)也得到了适当的描述和恢复。最后,通过对人类书写样本的图像和所有其他字符的机器生成手写体进行矢量化,可以生成完整的个人字体库。包括对97名参与者进行的图灵测试在内的实验验证了所提出的系统能够准确地学习个人手写风格,自动合成不可区分的手写体,并快速为普通人生成高质量的大规模字体库。我们的实验还表明,领域知识对于许多机器学习任务(例如手写合成和字体设计)仍然至关重要,在这些任务中只有少量的训练样本可用。最近流行的基于深度学习的端到端方法如果没有手工制作的特性和规则,就无法很好地处理这些问题。据我们所知,我们的工作(Lian et al.2016)是第一个能够以用户的个人风格自动生成具有任意大量汉字的实用手写字体库的工作。本文是我们会议论文的扩展版(Chen et al.2017;Lian et al.2016),通过采用几种新技术对原始系统进行了升级,并提供了更多的实现细节和实验结果。
Major contributions of this article are threefold:
本文的主要贡献有三方面:
(1) 我们设计了一种有效的笔划提取算法,该算法从经过训练的字体骨架流形中构造最适合的参考数据,然后通过非刚性点集配准方法建立目标和参考字符之间的对应关系。通过这种方式,我们可以准确地知道用户如何书写这些字符。
(2) 我们提出了一种新颖的系统,使普通人可以轻松生成大规模手写字体。此外,通过利用精心设计的输入字符选择方案、自动笔划提取和手写细节恢复技术,可以保证系统生成的字体库的高质量文本渲染结果在几乎任何类型的手写样式(甚至奇怪和草书样式)的实际使用中得到保证。已经进行了大量实验来验证我们方法的有效性。
(3) 我们已经手动指定了标准“Kaiti”样式(参考)和其他两种手写样式(目标)中所有27533个汉字的每个笔划的书写轨迹。该地面真实数据与一组其他手写图像数据一起在我们的实验中使用的样式可以作为手写合成的基准,这在我们的网站上是公开的。
数据集链接:http://www.icst.pku.edu.cn/zlian/EasyFont/.

图2.所提出的系统概述以及我们的方法与现有字体生成方法的比较。使用我们的系统,用户只需要在空白纸上写少量(例如266个)汉字,然后将照片上传到我们的系统。然后,系统可以自动生成用户个人风格的手写字体库,其中包含大量(例如27533个)汉字。使用我们的系统生成的字体库呈现的文本看起来类似于用户编写的文本。相比之下,另一个字体库所呈现的仅包含266个人类书写字符的字体是不可读的,因为人类书写样本和文字处理器默认字体样式(例如“Songti”)中呈现的字符混合在一起。
2 RELATED WORK
虚拟笔刷:传统上,字体设计师需要使用钢笔、笔刷和/或尺子在纸上书写或绘制字符,然后扫描和矢量化它们以构建计算机字体。在过去的几年里,许多研究人员试图开发“虚拟笔刷”,可以生成与使用真实笔刷或钢笔获得的结果类似的高保真绘画或文字。有了这种虚拟笔刷,设计师可以方便地在计算机上进行字体设计工作,因此,字体设计和制作的效率可以显著提高。Wang和Pang(1991)通过一些计算机图形技术模拟了书法家的书写速度和毛笔上墨水量的变化,以实现不同的书写风格。然后,使用三次Bezier样条描述字符的轮廓。通过这种方式,用户可以在电脑上交互式地创作中国书法。然而,他们的系统的模拟结果并不令人满意,因为他们采用的方法太简单,无法模拟真实电刷的复杂物理特性。在Strassmann(1986)中,通过考虑上述物理特性,首次提出了2D虚拟笔刷模型。Strassmann(1986)将笔刷描述为随着书写轨迹演变的鬃毛集合。从那时起,研究人员开发了大量虚拟笔刷算法,如多参数控制的真实感虚拟笔刷(Xu等人,2003)、基于反向建模的虚拟笔刷,以及数据驱动的3D虚拟笔刷等。
使用具有多自由度(DOF)的设备,熟练的用户能够基于上述虚拟笔刷技术生成富有表现力的结果。然而,很难控制这些设备来为普通人创建高质量的绘图和手写,而且大多数设备都使用DOF较低的通用输入设备。为了解决这个问题,Lu等人(2012)提出了一种数据驱动的方法,用于为低质量输入设备的用户合成6D手势数据,并且由他们的方法生成的6D轨迹可以用作任何虚拟笔刷引擎的输入,以获得富有表现力的手写结果。然后,他们相继报道了两个数据驱动的绘画系统,包括RealBrush(Lu et al.2013),它使用物理媒体的扫描图像来合成绘画,以及DecBrush,它可以合成结构化的装饰图案和用户书写的轨迹。同时,Zitnick(2013)提出了一种手写美化算法,该算法基于对同一手写风格中多个实例的平均外观优于大多数单个实例的洞察力。最近,有人提出了几种专门为汉字设计的虚拟笔刷(Xia and Jin 2009;Y i e t a l.2014)。例如,Yi等人(2014)提出的方法可以通过组合最适合的笔划片段,合成任何字体风格的高质量中文手写体,笔划片段是根据用户书写的轨迹从离线训练的相应风格数据库中选择的。
电脑书法:上述方法可以极大地促进电脑字体的设计和制作。然而,这些方法模拟的是人们使用的工具,而不是艺术创作过程,因此,在计算机上使用虚拟笔刷生成书法或绘画仍然需要大量人工操作。Dong等人(2008)提出基于统计模型自动生成汉字的新笔画形状,该模型学习如何通过大量书法样本的训练集,以全新的风格创作笔画。Xu等人(2005)提出了一种基于相似推理的系统,用于自动生成中国书法作品。该系统能够通过学习训练书法图像的参数表示来创建各种新风格的中国书法。然后,Xu等人(2007)设计了一种基于反向传播神经网络的数字分级方法来评估书法的美,并将其应用于他们之前的系统中(Xu等人,2005),以生成全新风格的视觉愉悦的书法作品。Xu等人(2009)还提出了一种增强形状语法系统来描述汉字的个人手写风格,并使用经过训练的神经网络来测量两个字符图像之间书写风格的相似性。通过将该方法集成到syst e m p r o p o s e d i n X u e t a l(2005)中,可以自动生成以相同风格的输入书法图像表示的汉字。Wang等人(2008)和Yu等人(2009)通过重用一组输入字符图像的笔画和/或部首,介绍了中国书法的自动生成方法,而Xu等人(2008年)不仅选择了输入数据集中的现有组件,还使用具有一定概率的计算机生成组件来合成输出字符形状。Dolinsky和Takagi(2009)报道了一种不同但很有前途的手写字符生成方法,其中作者发现递归神经网络(RNN)可以用于近似模拟手写字符的自然度,这在他们的论文中被定义为手写字符和原型字体字符之间的差异。基于自然度学习方法,他们通过从用户书写的27个平假名字符中学习的自然度模型,成功地生成了34个用户手写风格的平假名。Li等人(2014)提出通过学习从用户书写的字符中提取的信息,以类似的拓扑风格合成中国书法。他们采用了一种称为WF直方图的新特征来测量两个字符之间的拓扑相似性,然后建立了一个评估模型来指导合成过程。最近,Haines等人(2016)开发了一种能够以给定用户的手写风格呈现新文本的系统。通过学习间距、线条粗细、压力、颜色、纸张纹理等参数,系统可以获得与输入数据风格相似的高质量合成手写文本。然而,由于以下两个原因,Haines等人(2016)提出的方法无法扩展到解决大规模手写字体的自动生成问题。首先,半自动用户界面上的手动交互仍然需要精确地分割和标记训练数据。如果我们想为成千上万的普通人提供我们系统的服务,全自动处理始终是必要的。其次,正如作者所提到的,“具有高字符数的语言,例如汉语(>3000),合成起来将非常困难,因为捕获足够的数据是不合理的”,因此,本质上不适合解决本文中提到的问题。
字体生成:尽管一些富有表现力和创造性的书法作品可以通过现有的计算机书法方法生成,但它们仍然不适用于创建包含大量不同字符的大型字体库(例如,中文字体)。一方面,实用的中文字体库通常至少由数千个字符组成。然而,那些现有的方法,最初是在相应研究人员指定的小数据集上测试的,只能处理少量(大多数是几百个)拓扑结构和几何形状相对简单的汉字。另一方面,通过这些现有方法获得的许多结果不能满足实际字体库中对字符形状的视觉质量、可读性和样式一致性的高要求。因此,当前字体设计师在一些字体编辑软件系统(例如FontCreator(2017)和FontLab(2017))的帮助下,仍然严重依赖个人经验和手动操作来生成商业字体产品,而不是使用自动字体生成方法。由于汉字的复杂性和特殊性,一些公司开发了自己的字体设计系统来创建汉字字体,而不是直接使用通用字体编辑软件。例如,由世界最大的中文字体生产商(即方正集团(Founder Group,Founder 2017))开发的字体编辑系统HAND,是专门为中文字体设计的,它考虑了汉字的独特特征(例如,层次表示)。
事实上,这些CAD系统可以显著提高字体设计的效率,但创建一个商业中文字体库仍然需要大量的时间和人工操作(由三到五名熟练的字体设计师花费大约12个月)。在过去的二十年中,已经报道了几项工作,试图通过在字体生成过程中引入更多的启发式规则和自动处理来减少繁重的手动操作(Fan 1990a,1990b;Lai等人,1996;Lian和Xiao 2012;Lin等人,2014),但这些方法仍远未实现。最近,Suveeranont和Igarashi(2010)开发了一个系统,根据用户设计的字形自动生成字体库中的所有字符。他们的关键思想是以自然的方式操纵模板字体库中字符的轮廓和骨架,模板字体库被选择为具有与输入字符最相似的字体样式,以所需字体样式为所有字符构建形状。他们的实验表明,该系统可以显著提高英文字体设计的效率。然而,他们的系统需要为所有字符手动创建精确而复杂的形状模型,这不适合处理包含大量复杂形状字符的大型字体库。Campbell和Kautz(2014)建议构建一个标准字体的生成流形,以平滑地在现有字体之间进行插值和移动。通过这种方式,可以从所谓的字体流形中轻松生成大量新的高质量字体。然而,由于需要在两个字形的轮廓之间建立精确的对应关系,他们的方法也不适用于汉字。Phan等人(2015)开发了一个名为“FlexyFont”的系统,该系统能够通过应用学习的样式构建一个完整的英文字体库,传输规则来组装给定字形的分段部分以生成其他字形。最近,Lake等人(2015)提出了一种使用概率程序归纳的概念学习方法,该方法能够在给定单个字符图像的情况下,以新颖的写作风格生成新的范例。他们的方法无法处理为所有其他看不见的字符生成与输入样本样式相同的手写体的难题。
在过去十年中,深度神经网络(Hinton和Salakhutdinov 2006;Silver等人2016)被广泛应用于处理计算机视觉(Russakovsky等人2015)、计算机图形学(Soltani等人2017)等领域的许多挑战性任务,并在包括图像分类、对象检测、语义分割等任务中获得最先进的结果。最近,AlphaGo(Silver et al.2016)在与包括大量世界冠军在内的职业围棋选手的比赛中的令人惊讶的表现表明,深度学习方法在解决许多以前认为不可能解决的其他难题方面具有更大的潜力。直到现在,已经提出了几种基于深度学习的架构,它们要么是专门设计的,要么适合于字体生成。众所周知,自动编码器(Hinton and Salakhutdinov 2006)能够有效地重建图像。通过实现神经风格转换(Gatys等人,2017),可以将给定图像转换为具有与其他目标图像相似风格的新的视觉吸引力图像。学习纹理/颜色样式比形状几何样式容易得多,形状几何样式通常包含高级智能知识,普通人甚至很难学习。旨在创建高质量2D图像(Isola等人2017)或3D对象(Soltani等人2017)的生成任务最近吸引了越来越多的研究人员的关注。也有一些工作专门关注合成与训练样本相同风格的字体(Baluja 2016;Bernhardsson 2016;Tian 2016),但根据我们的实验,大多数工作无法为复杂的中文手写字符生成合理的结果。据我们所知,到目前为止,“重写”(Tian 2016)和“pix2pix”(Isola et al.2017)是两个性能最好的现有框架,可用于从一小部分手写样本中自动生成中文字体。具体而言,“重写”(Tian 2016)采用了传统的自上而下的CNN结构,而“pix2pix”(Isola等人,2017)具有强大的能力来学习从输入图像到输出图像的映射,这主要是由于使用了GAN。尽管这些基于“端到端”深度学习的架构在给定大量训练样本的情况下,在没有高级领域知识的情况下可以很好地用于某些打印字体,但在尝试为许多手写样式合成具有复杂结构的字形时,它们仍然无法获得令人满意的性能。
Zhou等人(2011)报道了与本文最相关的工作,其中Zhou等开发了一个系统,通过重用用户书写的522个字符的部首来构建2500个相对简单的汉字的字形,从而构建了一个用户手写风格的小字体库。然而,有三个主要的缺点阻碍了他们的系统的实际使用。首先,在系统中重复使用部首而不是笔划,这导致需要大量输入字符(超过20%)。此外,如果考虑具有更复杂形状的字符,系统将不可避免地需要更多的输入字符。其次,带有重叠部首的字符不能用它们的方法正确分割,而这类情况在手写汉字中经常发生。第三,在他们的方法中,根据从标准字体库中提取的布局信息,直接重用和组合选定的部首。除非所需的字体样式与标准字体样式几乎相同,否则无法保证通过他们的方法可以获得高质量的结果。此外,商业字体产品至少需要6763个汉字(GB2312官方标准),但其系统只能处理更小的字符集。为了解决这些问题,我们提出了一种系统,通过从少量(少至1%)人类书写字符中学习样式,自动生成具有任意大量汉字的实用手写字体库(例如,GB18030-2000)。
3 METHOD DESCRIPTION
如上所述,我们打算从普通人书写的少量字符中学习手写风格,然后自动生成整个手写字体库,该库可以具有用户个人风格中任意大量的字符。更具体地说,在离线处理期间,我们首先手动指定标准“Kaiti”字体库中所有(例如,27533个)字符的每个笔划的书写轨迹,该字体库用作样式学习的参考数据。然后,正确选择一系列输入字符集,以满足实际应用中的不同要求(第3.1节)。最后,构建字体骨架流形以生成最适合笔划提取的参考数据(第3.2节)。在线上,我们首先自动提取从输入文本照片中分割的单个字符图像的笔划轨迹(第3.3和3.4节)。然后,我们利用人工神经网络学习和重构用户的整体手写风格,可以将其分解为笔画形状风格和笔画布局风格(第3.5节)。同时,笔迹细节(包括笔划连接和轮廓形状)也得到了适当的描述和恢复(第3.6节)。最后,可以通过对人类书写样本的图像和所有其他字符的机器生成手写体进行矢量化来生成完整的个人字体库(第3.7节)。我们系统的流水线如算法1所示,更多细节如下所示。
3.1 Selecting Input Character Set
为了模仿用户的手写,我们的系统需要通过分析用户书写的一些样本来学习手写风格。这里有一个关键问题:“应该写哪些字符?”显然,如果没有“看到”足够的手写样本,我们的系统甚至专业的书法家都无法精确地模仿用户的手写。我们知道,有32种不同类型的笔画构成了汉字的基本元素(见图3(b))。因此,我们的系统的一个基本要求是,所有类型的笔划都应该在输入字符集中至少出现一次。然而,这远远不够。因此,在离线处理期间,我们手动指定了标准“Kaiti”字体库中所有27533个字符的每个笔划的书写轨迹,并定义了1032类组件(见图3(a)),这些组件由一组笔划组成。由于同一基本类型中笔画的形状可能有很大的差异,我们进一步将其分为339个细粒度类别。利用这些参考数据,可以通过选择覆盖所有339种笔划的字符来确定合适的字符集。如果需要更好的合成性能,我们可以选择更多输入集的字符,以便还可以完全覆盖所有1032种类型的组件。

【图3.(a)将汉字样本分解为成分并最终笔画的演示。(b) 构成汉字基本要素的笔画示例。它们可分为32个基本类别。】

输入:用户书写的带有某些字符的论文照片;
1: 文本分割:通过分割校正后的文本图片来获得单个字符图像;
2: 笔划提取:为每个字符图像提取每个笔划的书写轨迹,并选择正确的提取结果;
3: 整体风格学习:使用人工神经网络学习用户的整体手写风格;
4: 细节建模:分析和描述所有连续笔画对的连通性以及每种笔画类型的轮廓细节;
5: 手写合成:通过在参考数据上添加学习到的样式,为每个字符创建轨迹,然后恢复手写细节;
6: 字体生成:对人类书写样本的图像和其他字符的合成结果进行矢量化,然后生成TrueType字体库。
输出:用户的个人手写字体库。
为了使我们的系统生成的字体产品在真实文本渲染应用程序中表现得更好(参见图2),我们选择将人类书写样本的图像和其他字符的机器生成手写体矢量化,以构建实用的字体库。这是由于一个人书写的字符通常具有随机和不可预测的变化,而机器学习系统只能捕捉该人的平均和稳定的手写风格。通过我们的实验,我们发现,与仅包含合成字形的文本相比,由均匀分布的人类书写样本和机器生成的字符组成的文本渲染结果看起来更自然,更像真实的手写文本。因此,我们希望有一个输入字符集,能够覆盖所有正常中文文章中出现的大约50%或更多字符。为了实现这一目标,我们利用自动爬网从万维网获取了大量的中文文章、博客评论、聊天笔记等,从而获得了超过870亿个字符的数据集。通过计算该数据集中每个字符的出现频率,我们获得了其在正常中文文章中的平均覆盖率。它可以被观察到在按降序对所有字符的覆盖率进行排序后,理论上,前190个字符的组合能够覆盖任何正常中文文章的大约50%的内容。通过这种方式,可以估计使用我们的系统生成的字体库呈现的文章中出现的人类书写字符的平均速率。
根据上述标准,如表1所示,为不同的目的选择输入字符集。第一个由639个字符组成,用于本文的实验中,以评估整体风格学习算法的性能。在这种情况下,在不考虑覆盖率的情况下,选择字符只是为了确保字符集可以覆盖所有类型的组件和笔划。第二个字符集有266个字符,是我们系统实际使用中的最小输入字符集(MinSet)。该输入字符集不仅包括上述覆盖率最高的190个字符,而且还包含另外76个字符,以确保所有339类笔画至少可以写一次。在第二种情况下采用的选择标准中加入了覆盖所有类型组件的要求,我们得到了最后一个由775个常用字符组成的字符集。由于上述分析的优点及其在实验中的高性能和鲁棒性,我们将其称为我们系统的最佳输入字符集(OptSet)。

3.2 Learning Font Skeleton Manifold
为了构建字体骨架流形,首先应用使用数学形态学的细化算法(Jang和Chin 1990)来获得训练集中每个字符的书写轨迹(即骨架)。使用骨架而不是每个字符的轮廓简化了构建字体流形的复杂性。我们通过具有预定义笔划轨迹模型的非刚性点集配准过程,在所有选定字体中匹配每个单个字符的骨架点。然后,我们使用每个字符的密集骨架点对应作为基础,以拟合一个非线性流形,该流形将不同字体样式的字符连接到一个单独的空间中(见图4)。这里,通过使用高斯过程潜在变量模型(GP-LVM)(Lawrence 2005)学习非线性流形。
3.2.1 Character Matching.
具体来说,我们构建了一个高维向量,其中包含笔划骨架点以表示每个字形。要学习字体骨架流形,我们需要首先在不同字体样式的字形之间建立点对应关系。Campbell和Kautz(2014)开发了一种有效的方法来处理字符匹配任务。然而,由于他们提出的能量模型(Campbell和Kautz 2014)仅适用于在具有相同数量的闭合轮廓的字形之间建立对应关系,因此无法匹配通常具有不同和复杂的汉字骨架拓扑结构。因此,我们选择通过设计一种基于点集配准算法的新方法来解决这个问题。为了找出准确的对应关系,我们构建了一个笔划模型数据库,其中包含339个不同类别的笔划。我们手动选择每个笔划模型的书写轨迹上的关键点,然后得到其无分叉点的修订骨架。主要有三种骨架关键点:起点、终点和拐点,围绕着这些骨架关键点存在着丰富的写作风格信息。然后,将每个关键点对之间的骨架段均匀采样为一定数量的点。我们开发了一个工具,可以手动标记选定字体中每个字符的笔划骨架点。然后,我们直接使用相干点漂移(CPD)(Myronenko和Song 2010)算法将输入笔划的骨架点注册到其对应的笔划模型中。如图5所示,关键点与笔划模型对齐,每个关键点对之间的骨架段被采样为与笔划模式相同数量的点。
由于每个笔划骨架上的点已经彼此正确对齐,因此可以建立多个(例如,28个)选定字体中每个字符的对应关系。
3.2.2 Training the GP-LVM
高斯过程潜在变量模型(GP-LVM)(Lawrence 2005)是一种有效的非线性降维技术。它生成高维数据集Y的概率模型,低维数据集X是“潜在的”。我们一开始就在一个非常高维的空间中工作,因为每个字形中平均有大约600个骨架点。与PCA、MDS、IsoMap和其他线性降维方法相比,GP-LVM在从相应的低维潜在向量重构高维数据方面表现得更好。因此,GP-LVM非常适合学习这种字体骨架流形的任务。
假设有M个字体,我们需要为每个字符生成M个高维向量。每个向量都是通过按笔划顺序将所有骨架点样本依次放在一起组成的

其中vmi,j表示字体样式为m的第i个笔划骨架上的第j个点的坐标,n是字符的笔划编号。点坐标的值应归一化为[0,1]。为了应用GP-LVM,我们减去平均向量v,得到向量ym=vm− ¨v。这允许我们使用零均值函数,均值向量v实际上是训练数据的平均字符骨架。然后,高维数据集Y可以表示为
![]()
使用这些Y的骨架向量,GPLVM的训练过程将Y的可能性视为

其中I是单位矩阵,M表示字体的数量,C(X,X|θ)表示向量之间的协方差,σ表示噪声方差,说明每个原始高维向量与其重构版本之间的差异。在我们的实验中,流形只有在参数σ被设置为小(例如0.1)时才能很好地工作,这表明字体骨架实际上位于低维流形上。我们通过在潜在向量X=[··xj··]T以及超参数θ上联合最大化下面的似然来获得潜在变量,从而

从流形中以新的字体样式生成给定字符的骨架是直接使用潜在变量X∗ 和超参数θ∗ (劳伦斯2005)。假设ˆx是流形上的目标位置,则相应的高维向量\710;y可以通过以下等式计算
![]()
其中C(ˆx,x∗|θ ∗) 表示向量与[C(X∗, 十、∗|θ ∗)]−预计算1。我们将上述平均向量v添加到ˆy,t o g e t \710 v,该向量由新字体样式中的字符骨架点的坐标组成。以这种方式,字体骨架流形被离线构建,以在下文描述的笔划提取步骤(第3.4节)期间为每个输入字符图像提供最相似的参考数据。
为我们的系统构建这样一个字体骨架流形有两个主要原因。首先,流形能够以不同的样式生成无限多个有意义的角色轨迹,而手动标记的参考数据的数量总是有限的,因此,与其他方法相比,可以实现更好的笔划提取性能(见图6)。其次,在训练的低维(例如,本文中的两个)流形而不是高维(例如大约1200)插值空间上搜索使得为大多数输入字符图像找到相似参考数据的任务变得可能并且更高效。

图4.在笔划提取过程中,使用训练的字体骨架流形为输入字符图像构造最佳参考。

图5.我们数据库中的标准笔划模型(左)和另一种字体样式中的对应笔划(右)之间的关键点对齐。三角形、菱形和正方形表示两个笔划轨迹的相应起点、终点和角点。
3.3 Text Segmentation
如图2所示,任何人都可以使用我们的系统快速方便地生成手写字体。用户应首先按照指令写出选定输入字符集中的所有字符(266或775,取决于所需的质量)。为了制作一个合格的字体库,字符应该分开书写,不按给定的顺序相互接触,大小和样式保持一致。然后,用户应该按照正确的方向为这些论文拍照,并将文本照片上传到我们的系统。
在接收到用户的文本图像后,系统将通过以下五个步骤自动从这些图片中分割单个字符图像:(1)对原始文本图像应用高斯平滑和自适应图像二值化;(2) 找到具有连接像素的区域,计算其边界框,并将其视为字符的候选;(3) 通过应用几个启发式滤波器(例如,大小、长宽比、黑白像素比)来丢弃不合适的候选。然后,如果有效候选的数量等于需要写入的字符数,则转到下一步。否则,放大图像并返回第二步;(4) 计算图片底部行中检测到的候选的质心,从而可以通过为这些中心点拟合直线来估计文本图像的旋转角度;(5) 从校正的文本图像中顺序地分割各个字符图像,并用相应字符的unicode值标记它们。

图6.使用以下三种不同参考数据对手写汉字笔画提取结果的比较:Kaiti(标准“Kaiti”字体)、NN Fonts(具有28种字体的给定数据库上的最近邻检索)、NNManifold(字体骨架流形上的最近邻居检索)。
这里采用的文本定位算法非常简单和直接,但对于所提出的系统来说已经足够了。在实际应用中,我们在Pan等人(2014)中提出的基于模板的文本分割方案也被用于通过我们的网站。其他最先进的文本检测和识别方法(例如,Sun等人(2016)和Zhang等人(2016年))也可以集成到我们的系统中,以提高其鲁棒性。
3.4 Stroke Extraction
给定许多字符图像,为了知道用户如何书写这些字符,我们必须精确定位字符上每个笔划的书写轨迹。我们的方法的关键思想是利用相干点漂移(CPD)(Myronenko和Song 2010)算法实现给定目标角色图像的骨架与其最佳参考之间的非刚性配准(见图7)。
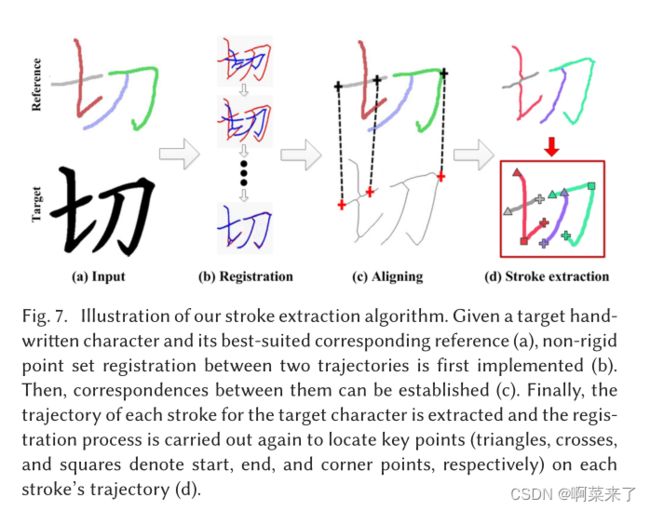
图7.笔划提取算法的图解。给定目标手写字符及其最适合的对应参考(a),首先实现两个轨迹之间的非刚性点集配准(b)。然后,可以建立它们之间的对应关系(c)。最后,提取目标角色的每个笔划的轨迹,并再次执行配准过程,以在每个笔划轨迹(d)上定位关键点(三角形、十字和正方形分别表示起点、终点和角点)。
在上述离线期间,学习字体骨架流形,因此可以生成许多字体骨架,从中我们可以找到输入图像中最相似的一个作为笔划提取的参考数据。由于流形空间是连续的和无限的,所以在流形中遍历任何地方都是不切实际的。然而,可以观察到,附近的位置倾向于生成相似的角色骨架,并且骨架从一个位置连续变化到另一个位置。让z表示在流形中的现有选定字体中生成与目标字符图像最相似骨架的位置;我们推测,最合适的参考人物骨架可能位于z附近。
在上述离线期间,学习字体骨架流形,因此可以生成许多字体骨架,从中我们可以找到输入图像中最相似的一个作为笔划提取的参考数据。由于流形空间是连续的和无限的,所以在流形中遍历任何地方都是不切实际的。然而,可以观察到,附近的位置倾向于生成相似的角色骨架,并且骨架从一个位置连续变化到另一个位置。让z表示在流形中的现有选定字体中生成与目标字符图像最相似骨架的位置;我们推测,最合适的参考人物骨架可能位于z附近。
这里,我们选择在以z为中心的圆中进行遍历,并逐渐增加其半径,直到达到阈值τ。对于我们生成的每个角色骨架,细化方向特征的计算方法与上述相同,我们选择与目标角色图像最相似的一个作为其参考数据(见图4)。
由于笔划标签对于最适合的参考数据上的所有点都是已知的,在建立参考数据和目标数据之间的对应关系之后,可以自动获得目标字符图像上每个笔划的书写轨迹(见图7(d))。更具体地说,假设XN×2=(x1,…,XN)T是目标点集,在用户书写字符的骨架上均匀采样N个点,而YM×2=(y1,…,YM)T是参考点集(即高斯混合模型(GMM)的质心),在相应参考字符的书写轨迹上采样M个点。将参考点集与目标点集配准相当于通过最小化以下目标函数来确定GMM质心的位置(即θ)和GMM分布的等向协方差(即σ2)

这里,我们采用EM算法通过迭代实现E和M步直到收敛来解决这个问题。
在上述过程之后,我们得到的只是一组标记的目标点集。为了实现风格学习和细节恢复,我们想将每个笔划的书写轨迹描述为一条具有多个关键点的单向曲线,包括起点、终点和角点(见图7(d))。我们通过再次应用CPD算法(Myronenko和Song 2010)来实现这一目标,以建立每个目标笔划轨迹的点集与相应的参考笔划模型之间的对应关系。这里,通过手动指定每个笔划类型的书写轨迹和上述关键点一次,离线构建了339个参考笔划模型。
应该指出的是,在实际应用中,由于存在特殊和草书的个人笔迹样式,笔画提取结果总是不正确的。显然,这些错误的提取结果可能严重影响手写合成的性能,甚至可能导致系统崩溃。为了解决这个问题,我们通过计算来评估字符笔划提取结果的正确性。

其中Cr-ec表示重建字符图像与原始字符图像的重叠比,该重建字符图像是通过连续绘制直径等于沿提取的笔划轨迹的平均笔划宽度的盘而获得的;Csim使用几个形状描述符(即Sobel Roberts特征(Khosravi和Kabir 2010)和关键点之间的线角度)测量每个目标笔划轨迹与其对应参考之间的相似性;Crule通过为每种笔划类型设计启发式规则,根据笔划的内在属性(例如,笔划“横”和“竖”应分别看起来像水平和垂直线段)与每种笔画的正确性相关。在我们的系统中,我们选择丢弃20%的正确值小于其他80%的人类书写字符。这是由于从我们的实验中观察到,笔画提取结果对于由639个字符组成的上述测试集中超过90%的字符是正确的。
3.5 Overall Style Learning
在我们的系统中,整体手写风格表示为参考字符(re f)和n d手写字符(手)的轨迹之间的差异。我们将汉字分解为较低层次的概念和结构,即笔画形状(SS)和笔画布局(SL)(见图8)。因此,整个手写风格可以被分解为笔划形状风格(SSS)和笔划布局风格(SLS),它们分别由笔划形状和笔画布局(DSS和DSL)在手写和手写之间的差异表示。

图8.描述手写风格。黑色和绿色轨迹分别表示手写和参考字符。蓝色点和红色点是ref和手的笔划中心。五角形表示角色中心。
为了计算DSS和DSL,我们首先对所有参考字符和手写字符的每个笔划轨迹上的相同数字(NP)o f p o i n t s Pij(k)=(xij(k,yij(k)),k=1,2,…,NP进行采样。因此,笔划可以表示为沿着笔划轨迹的点(为简单起见,除非另有规定,否则在本节中,我们直接使用“笔划”表示“笔划轨迹”),例如,Sij=(Pij(1),Pij(2),…,Pij)。虽然字符表示为笔划Ci=(Si1,Si2,…,SiNS i)的矢量,但w h e r e NS i表示字符Ci中的笔划数。然后,可以容易地计算笔划中心SC和字符中心CC。为了更好地描述笔划的形状,我们计算归一化笔划形状,它由笔划上的点与笔划质心的相对位置组成。同样,通过计算笔划中心与字符中心的相对位置,可以获得归一化的笔划布局。因此,每个冲程的归一化SS和SL可通过SSij=Sij计算− SCij和SLij=SCij− CCi。如上所述,笔画形状样式和笔画布局样式由DSS和DSL表示,可以计算为DSSij=SShandj− SSr ef ij和DSLij=SLhandij− SLr ef ij,w h e r e SShandij,SLhandij表示手写字符笔划j的归一化SS,SL;并且SSr-ef-ij、SLr-ef-ii表示相应参考的归一化SS、SL。
3.5.1 Data Structures and Neural Networks.
图9概述了如何使用我们的方法学习和重构用户的整体手写风格,该方法包括以下内容
两个程序:风格学习和手写合成。在风格学习过程中,神经网络被用于捕获整体手写风格。re f的笔划形状用作学习笔划形状样式的输入,re f和手之间笔划形状的差异用作输出。类似地,当学习笔画布局风格时,输入是re f的笔画布局,输出是re f和hand之间的笔划布局差异。这里,采用不同的数据结构和各种神经网络,并进行比较以学习笔画形状样式,这比学习笔画布局样式的任务更难。输入和输出数据是根据为我们的系统选择的不同数据结构和神经网络构建的。
笔划形状风格学习的数据结构可以按时间依赖性分为顺序和非顺序,或者按粒度分为点式、笔划式和字符式。我们使用的数据结构分类如表2所示,其中Y表示合适,N表示不合适。
对于逐点数据结构,输入和输出分别为SSr ef ij(k)和DSSij(k)(即每个点)。非递归神经网络(non-RNN)不适合这种数据结构,因为很难从单个点捕获手写风格。在递归神经网络(RNN)中,我们可以将每个笔划中的点视为序列,或者将每个字符中的点作为序列。对于笔划式数据结构,输入和输出分别为SSr ef ij和DSSij(即每个笔划)。RNN和非RNN都适合于发现re f和hand之间笔划的差异(风格)。在RNN中,字符中的笔划形成一个序列。尽管RNN可以发现字符笔划之间的时间依赖性,但我们系统中训练样本的有限数量限制了RNN的这种能力。对于字符型数据结构,输入和输出分别为SSr-efi和DSSi(即每个字符)。只有非RNN适用于此数据结构在这种情况下,采样数比笔划式数据结构中的采样数小得多。
我们选择通过以下三种类型的神经网络(NN)来学习整体手写风格:前馈神经网络(FFNN)(Rumelhart等人,1986)、Elman递归神经网络(Elman RNN)(Elman 1990)和长短时记忆(LSTM)网络(Hochreiter和Schmidhuber 1997)。FFNN是非RNN网络,而Elman RNN和LSTM是RNN,它们能够捕获时间相关性。正如我们所知,埃尔曼RNN只有很短的记忆,但LSTM,一个设计良好的RNN,在学习长期依赖性方面表现良好。

图9.我们系统中的整体风格学习和手写合成图解。
3.5.2 Learning Procedure.
如图9所示,我们的学习过程包括三个步骤。首先,基于上述分析选择合适的数据结构和相应的神经网络。然后,我们使用选定的数据结构构建训练数据(包括输入和输出数据)。然后,我们用准备好的数据训练神经网络,以分别学习笔画形状样式和笔画布局样式。同时,验证集用于在训练过程中自动调整参数。最后,我们获得了经过训练的神经网络,可以用于生成过程中的手写体合成。

3.6 Recovering Handwriting Details
在捕获用户的整体手写风格后,可以生成所有字符的书写轨迹。然后,创建合成字形的最简单方法是使用人类书写字符的平均笔划宽度来渲染轨迹(参见图14中的一些渲染示例)。
然而,如图10所示,书写轨迹上每个点的笔划宽度可能会根据不同的手写行为而发生很大变化,尤其是在笔划的开始和结束区域。此外,两个连续笔划的连接性也是用户手写风格的一个重要特征。为了捕捉笔划轮廓上的手写细节,我们将笔划分为三个区域,即开始、结束和中间区域。通过确保起点/终点与笔划轮廓上的点之间的最大距离等于平均笔划宽度ws的两倍来调整起点和终点的位置。然后,如图10的左部分所示,通过发射均匀分布在与书写方向相反的半区域中的多条(例如11条)射线,获得笔划轮廓上笔划轨迹起点周围的点的相对位置。
如果任何这些光线在到达笔划轮廓之前都会遇到其他笔划的轨迹,我们将其标记为无效的起始区域。可以以相同的方式捕获末端区域的手写细节,并且中间区域的形状由轨迹上的多个(例如10个)均匀采样点的笔划宽度值来描述。如上所述,所有笔划都被分类为339个类别,因此我们可以计算每种笔划类型中所有有效区域的上述细节信息的平均值,并在渲染属于同一类别的笔划轨迹时使用它来恢复轮廓上的细节。
为了描述每对连续笔划的连接性质,我们计算了一个339×339矩阵Mc,其中元素mcij表示在笔划i的终点和笔划j的起点之间绘制轨迹的概率,通过使用我们自动提取的带有关键点的笔划轨迹,很容易判断字符中的两个连续笔划是否被写为一个连接的组件。然后,通过计算连接笔划对(即笔划i和j)的数量与该类型笔划对的总数之比,获得mcij的值。当生成合成结果时,如果mCij的值大于随机数Pc(Pc∈ [0,1]),将创建具有适当宽度值的自然平滑线,以连接笔划i的终点和笔划j的起点。
3.7 Handwriting Synthesis and Font Generation
如图9所示,在生成过程(即手写合成过程)中,参考数据(即SSr ef ij和SLr ef i j)被输入到训练的NN中,以估计DSSij和DSLij。然后,我们通过将DSSij与DSLij分别应用于SSr efi j和SLr ef i。,SShandj=DSSij+SSr ef ij和SLhandj=DSLij+SLr ef i j。通过设置字符中心CCi,可以使用计算的SShandi和SLhandij来定位笔划中心和笔划上采样点的位置。

图10.如何恢复手写细节的演示。在字形中间学习的书写轨迹用红色表示。
在获得用户尚未书写的所有字符的合成书写轨迹后,在我们的系统中实现了几个美化过程,以获得更好的视觉效果。首先,可以通过稍微平滑生成的轨迹来减少合成结果的失真。此外,使用上述技术正确地绘制轨迹以恢复书写细节可以使合成结果看起来更像用户的真实手写。我们的方法最重要的优点之一是,一旦提供了所需的参考数据,就可以通过训练的网络自动生成学习的手写体中任意数量的汉字。最后,通过对人类书写样本的图像和所有其他字符的机器生成手写体进行矢量化和打包,可以构建用户个人手写风格的Truetype字体库。
4 EXPERIMENTS
我们在本节中进行了两组实验。第一组实验主要旨在研究不同配置的效果,并对所提出的总体风格学习方法进行性能比较,该方法在我们的系统中起着关键作用。另一组实验包括图灵测试,旨在证明我们的字体生成系统在实际应用中的有效性和优越性。除非另有规定,我们的实验设置如下:“凯蒂”字体库中的字符被用作风格学习的参考数据,因为大多数中国人开始学习书写时都是模仿“凯蒂”字体的字形。笔划布局样式由FFNN学习。这些算法是在Matlab中使用3.5GHz Intel i7-5930K CPU和32.0GB RAM在PC上实现的。
4.1 Font Generation without Handwriting Details
在第一组实验中,我们比较了具有不同数据结构和神经网络配置的方法的学习性能。计算均方误差(MSE)和n d相关系数(R)以定量评估性能。为了实现准确的比较和定量分析,我们在iPad上以固定笔画宽度手动指定两个用户(即用户1和2)书写的所有字符的笔画轨迹,并将其作为实验中的基本事实。该数据集在我们的网站上公开,以便其他研究人员可以将其用作手写合成的基准数据库。这里,在这组实验中选择了由639个不同汉字组成的输入字符集(详见第3.1节和表1),这些字符集能够覆盖常用汉字的所有笔画类型和组成部分。这639个字符被随机分为训练集、验证集和测试集,分别具有4/6、1/6和1/6的分割比。
4.1.1 Data Structures and Neural Networks.
对于笔划布局风格学习,采用隐藏层中具有五个单元的FFNN。我们每次使用SLr ef ij作为输入,输出是参考字符和手写字符之间的SLij之差,即DSLij。首先,在训练集上训练FFNN以学习SLS。然后,利用训练的FFNN和新的输入数据来生成新字符的SLhandj。我们观察到,在学习过程中,收敛发生在大约8000次迭代之后,在测试集上评估的R值大约为0.965,这意味着机器生成的数据和地面真实数据之间的高度相似性。
接下来,我们测试具有不同数据结构的NN以学习笔划形状风格,即,使用FFNN的笔划学习(SWL-FFNN)、使用Elman RNN的笔划式学习(SWLERNN)、使用LSTM的笔划方式学习(SWL-LSTM)、使用每笔划序列中的LSTM的点式学习(PWL-LSTMPSS)、,以及基于FFNN的字符学习(CWL-FFNN)。

表3.在测试集上评估的不同配置的方法的MSE和R值
这里,在所有NN中仅使用一个隐藏层;这意味着网络结构是I∗ H∗ O、 I、h、和 O分别表示输入层、隐藏层和输出层中的单元数。表3列出了每个NN中的单元编号,这些编号是通过实验选择的。我们尝试在每个NN中使用更多的层和单元,但性能无法提高。一种可能解释是,对于小规模数据,浅网络通常比深网络更适合。

图11.在笔划形状风格学习的不同方法的训练集和验证集上评估的MSE值图。
从表3可以看出,采用笔划配置的方法比采用点和字符配置的方法性能更好。因此,当训练样本数量较少时,笔划式配置更适合于风格学习。此外,具有不同笔划配置的方法表现相似,这表明,对于这种小样本学习任务,递归神经网络(ERNN和LSTM)相对于前馈神经网络(FFNN)没有明显的优势。
如图11所示,它显示了不同方法的性能,FFNN的训练误差和验证误差需要很长时间才能减小,直到收敛。因此,我们采用了一种技巧,即根据错误的趋势及时自动调整学习速度。通过这种方式,可以很快解决由于大学习率而导致的梯度中断。相反,Elman RNN和LSTM的训练误差继续快速减少,然后在Elman RN网络和LSTM中经过数百次迭代后出现过拟合。尽管达到Elman RNN和LSTM的最佳条件所需的迭代次数较少,但每次迭代的时间开销很高,因为无法并行计算。
图12显示了由不同方法生成的没有平滑的字形。我们发现,笔划学习方法比其他方法表现得更好。有趣的是,不同神经网络的笔划学习方法实现了近似相似的视觉效果。这表明数据结构对学习效果有很大影响,我们的方法可以从有限的样本中充分学习个人手写风格。与SWL-FFNN相比,SWL-LSTM和SWL-ERNN中出现了更多的抖动,这主要是因为有限数量的样本无法稳定LSTM和Elman RNN中的更多权重。通常,SWL-FFNN在这些方法中获得了最佳的视觉效果,因此在其他实验中被用于学习笔划形状样式。
4.1.2 Size of Input Character Set.
我们从上述639个字符中随机选择不同数量的训练样本,其中其他样本用作测试数据。然后,针对每个训练样本大小,对我们在不同数量样本上训练的方法进行10次评估,以计算MSE和R的平均值。从图13中可以看出,仅使用270个样本,我们的方法就可以获得足够好的性能,MSE=0.207和R=0.849。

图12.使用不同配置的方法对“用户1”的合成结果进行比较。C1、C2和C3表示不同的字符。
4.1.3 Comparison with a Concatenation Method.
为了验证我们的系统的优越性,我们将所提出的方法与Zhou等人(2011)提出的名为字符字根合成模型(CRCM)的连接方法进行了比较。图14显示了分别使用CRCM和我们的方法获得的合成结果的比较。对于CRCM方法,我们手动调整字符分割结果,以确保所有正确提取自由基。CRCM大约需要13到13个小时才能生成一个包含6763个简化汉字的GB2312字体库。但是,CRCM生成的字体库不能在没有手动修改的情况下直接使用。正如我们所看到的,CRCM的合成结果存在许多明显的缺陷,例如激进的尺寸和激进的布局不合适。相反,我们的方法学习手写风格和构建字体库只需要大约216个小时。事实上,由于不可避免地存在不正确的自由基提取结果,CRCM不能在没有人工干预的情况下自动实现,但我们的系统可以。此外,我们方法的合成结果在视觉上更令人愉悦(见图14)。

图13.在同一测试集上使用不同训练样本大小评估的MSE和R值图。
4.2 Font Generation for Real Applications
在第二组实验中,我们想检查我们的系统在实际使用中的性能。更具体地说,这里测试的系统使用“FFNN”学习笔划布局风格,使用“SWL-FFNN“学习笔划形状风格。选择由775个字符组成的OptSet(见表1)作为输入字符集。此外,所提出的文本分割方案、笔划提取和细节恢复算法都被实现,以确保系统在接收到用户上传的手写文本照片后可以完全自动运行,并且合成结果可以与原始手写体区分开来。尽管只有266个字符的MinSet(见表1)也可以被用作输入字符集,事实上,使用MinSet已经获得了相当好的结果(见图2),但我们仍然建议使用OptSet来保证在奇怪、非常草草的实际应用中更好、更稳定的性能,甚至不正确的手写也可能被输入到我们的系统中。事实上,一个受过教育的中国人在纸上正确写出OptSet中的所有字符,平均只需要20-30分钟。根据用户调查,时间和工作负荷对他们来说是可以接受的,主要是因为这775个字符中的大多数很容易写,并且在我们的日常生活中很常见。到目前为止,已有数百名用户将他们的手写体上传到我们的网站,其中包括775个字符。其中,我们选择了三个用户(即用户3、4和5)提供的手写数据作为本组实验中系统的输入数据,这三个用户具有截然不同的手写风格(见图16)。

图14.两个用户的合成结果比较。第一行显示人类书写的字符。第二行和第三行分别显示了我们的方法和CRCM的合成结果。
4.2.1 Rendering Results.
利用我们的系统生成的三个用户的个人手写字体,我们使用它们来渲染一篇著名散文中的两首诗和一段话。从图15可以看出,其中两首诗是使用三个字体库渲染的,图中下划线的机器生成字形的质量相当高。此外,我们的合成结果的整体手写风格和手写细节看起来与原始手写非常相似。图16显示了使用四种字体的段落的渲染结果,其中包括一个仅由“用户3”编写的775个字符组成的字体库,以及由我们的系统生成的三个用户的完整字体库。如我们所知,如果选定的字体库不包括要呈现的文本中的某些字符,通常我们使用的文字处理器将应用默认字体样式(例如“Songti”)来呈现这些字符。图16(a)显示了一个这样的例子,一个段落中混合了两种不同的字体样式,显著降低了渲染结果的可读性。相反,使用我们的系统生成的三个字体库渲染的文本不仅具有很高的可读性,而且看起来与相应个人风格的真实手写文本非常相似。这里给出的结果以及我们获得的其他更多实验结果清楚地表明,我们的系统自动生成的大规模手写字体库可以直接用于实际应用中。
4.2.2 Comparison with Deep Learning Based Methods.
在本节中,我们首先将我们的方法与两种基于深度学习的端到端字体合成方法进行比较(i.e., “Rewrite” (Tian 2016) and “pix2pix” (Isola et al. 2017))。我们直接使用作者提供的源代码来实现两种现有方法。更具体地说,选择由775个汉字组成的OptSet作为训练数据,选择标准的“Kaiti”字体样式作为此处比较的所有方法的输入参考。也就是说,在离线训练期间,标准“Kaiti”风格的775个字符图像被导入作为神经网络的输入,用户手写风格的相应字符图像被认为是理想的目标输出。在线上,未包含在OptSet中的所有其他字符将被顺序输入到经过训练的网络中,以生成用户手写风格的合成字符图像。

图15.使用我们的系统生成的三个手写字体库渲染两首著名的中国诗歌的结果。带下划线的字符是合成手写体,而其他字符由相应的用户书写。
图17显示了分别使用我们的方法和上述两种方法获得的合成结果的一些示例。正如我们所看到的,“重写”只能为用户4合成一些粗略的字符形状,无法为其他两个用户生成任何合理的结果。“pix2pix”方法的性能比“重写”要好得多,这主要是因为引入了对抗性网络,可以显著提高生成性网络的合成性能。然而,如图17所示,尽管“pix2pix”合成的形状的细节与相应用户编写的输入字符图像具有相似的风格,但这些合成字符中的大多数是不可读的。相反,使用我们的方法获得的合成结果不仅精确地继承了用户的整体和详细手写风格,而且清楚地表示了相应字符的正确含义。正如我们所知,大多数现有的基于深度学习的方法,包括这里比较的两种方法,都采用了所谓的端到端学习架构,这在很大程度上依赖于网络对训练数据的解释能力。端到端架构已被证明可以很好地用于全局或粗数据解释任务(例如,分类、检测、分割),但仍不能自动、精确地解释包含在具有优雅和复杂结构的训练图像中的高级和详细知识。因此,如果没有对训练字符图像的正确解释,这些端到端方法就无法生成具有正确含义的高质量合成手写体,尤其是对于复杂字符。
尽管上述实验验证了我们的系统在处理普通人书写的字形时的有效性和优越性,仅采用标准“Kaiti”样式的参考数据的EasyFont系统仍然无法为具有复杂轮廓形状或非常草草的书写轨迹的手写/设计字形生成令人满意的结果(见图18)。因此,在离线处理期间,选择另外57种具有代表性的GB2312中文字体来构建字体骨架流形。也就是说,我们需要手动指定85个不同样式的选定字体库中所有6763个汉字的每个笔划的书写轨迹。在线上,将选择其中一种与输入字符图像风格最相似的字体作为参考字体,以取代原始系统中使用的“Kaiti”字体。样式相似度通过通过第3.4节中描述的相同方法计算的相应字形对的形状相似度之和来测量。
为了用多种字体样式的参考数据检验我们的EasyFont系统的有效性,我们对五种不同样式的中文字体库进行了实验(见图18),并将我们的系统(EasyFonts)与其他现有方法进行了比较,其可分为两类:基于最近邻(NN)检索的方法(即NN字体和NN流形)和基于CNN的端到端方法(即重写、pix2pix和zi2zi)。NN字体和NN流形是其合成结果分别是从具有上述85种字体和我们的字体骨架流形的给定数据库中检索的最近邻居的方法。“zi2zi”(Tian 2017)专门旨在将一种字体样式的字形图像转移到另一种字体风格,实际上是由“pix2pix”修改而来的GAN模型。从图18中,我们可以看到,基于NearestNeighbor检索的方法由于其对训练数据的高度依赖性而工作得很差,而那些基于CNN的端到端方法通常合成不正确的字形。还可以观察到,所提出的具有多种字体样式的参考数据的EasyFont系统不仅适用于合成普通人的手写字体,而且可以为专业人士设计的艺术风格的字体生成高质量的合成结果。然而,我们的制度仍然存在一些局限性。从图18的最后一行可以看出(请放大以便更好地检查),专业人员设计的字体合成字形(例如“FZQKBYSJW”)中仍然会出现微小的瑕疵,一些随机出现的书写细节仍然无法精确地模仿具有草书风格的个人手写字体(例如““FZZJ-HJYBXCJW”和“FZzzJ-ZSXKJT”)。

图16.使用四种不同字体库呈现段落的结果。如果使用的字体库不包含段落中的某些字符,则将采用我们使用的文字处理器的默认字体样式(例如“Songti”)来呈现这些字符(见图16(a))。

图17.使用我们的方法和其他两种基于深度学习的端到端方法(即Rewrite(Tian 2016)和pix2pix(Isola等人2017))生成的合成手写体的比较。

图18.使用我们的方法(EasyFont)、NN Fonts(具有85种字体的给定数据库上的最近邻检索)、NN-Manifold(字体骨架流形上的最近邻居检索)和其他三种基于深度学习的端到端方法(即Rewrite(Tian 2016)、pix2pix(Isola等人2017)和zi2zi(Tian 2017))生成的合成结果的比较。
4.2.3 Turing Tests.
最后,为了定量测量人类书写字符和我们的系统生成的合成手写体之间的风格相似性,在本节中进行了图灵测试。具体来说,我们构建了一个网站,为每个参与者展示了一份随机的试卷(参见图19(b)–(d)中的一些试卷示例,以及图19(a)中的相应答卷),其中随机选择并放置了100个机器生成的字符和100个用户个人风格的人类书写字符。同时,用户随机选择的50个字符也被显示给参与者作为参考。每个参与者都被要求在足够的时间内挑选尽可能多的角色,他们认为这些角色是计算机模仿的。显然,如果机器生成的字符的书写风格与原始手写体不同,受过教育的中国人很容易找到它。同时,如果机器生成的字形不仅看起来像人类书写的字符,而且与同一个人书写的字符相似,那么很难从试卷中挑出它。因此,我们在这里进行的图灵测试可以说明合成结果是否具有所需的个人手写风格。

图19.图灵测试中使用的三种笔迹样式的试卷区域及其相应的答卷(a)示例。彩色方块中的字符由我们的系统生成,其他字符是人类书写的字符。
我们邀请了97名年龄(16-51岁)和职业(如学生、教师、公司员工)不同的受过教育的中国人通过互联网参加我们的图灵测试。区分机器生成字符和原始字符的平均准确率为52.17%,接近随机猜测的准确率(50%),准确率值的95%置信区间为[52.17%− 1.74%, 52.17% + 1.74%]. 图灵测试的结果证明,我们的系统生成的合成手写体很难与相应用户的原始手写体区分开来。这是因为,如图19所示,所提出的方法不仅可以很好地模仿用户手写体的整体风格,而且还可以模仿用户手写的许多重要细节。

图20.使用我们的系统获得的“用户4”的不同风格权重值的角色的合成结果
5 DISCUSSION
随机性存在于一个人所写的每一个角色中;甚至还有一些人没有稳定的书写风格。基本上,许多机器捕捉到的手写风格学习方法,如我们的方法,是用户的平均风格(即一种统计手写风格)。据报道(Zitnick 2013),同一笔迹形状的多个实例的平均值通常比大多数单个实例看起来更好。因此,由我们的方法生成的合成字符本质上非常适合构建字体库,这些字体库要求渲染结果的可读性和书写风格的稳定性更高。然而,由纯机器生成的字符组成的文本缺乏随机变化,与真实手写文本相比,通常看起来过于统一。我们通过将少量人类书写字符与大量其他字符的合成手写体相结合来生成完整的字体库,从而解决了这个问题。由于在正常文章中,用户书写的所有字符的平均覆盖率约为50%,因此以这种方式,人类书写的字符和机器生成的字符将均匀分布在使用我们的系统生成的字体库呈现的文章中。这使得渲染结果类似于真实的手写文本。

图21.三个用户手写风格中一些韩文字符的合成结果。
在我们的系统中,用户的整体手写风格可以量化为一组值,这些值测量用户的手写和参考风格中的对应字符(例如“Kaiti”)之间的差异。默认情况下,个人手写样式的权重选择为w=1,以便合成字形(例如,图20中红色方块内的字符)可以具有与用户书写的字符相同的样式。直观地,我们可以调整样式权重值(w≥ 0)以获得各种合成结果(见图20)。这使一个有趣的应用程序,在学习用户的手写风格之后,我们的系统能够为用户提供一系列手写字体产品,这些产品具有对应于不同权重值的平滑变化的风格。显然,用户选择的风格权重值越大,合成结果的个人手写风格就越强。因此,选择较小的权重值可以使合成手写体的风格变得更类似于标准的“Kaiti”风格。拥有丑陋手写风格的人可能会喜欢这个功能,因为他们可以使用它来美化自己的手写,从而可以获得更美观的个人字体库。
需要指出的是,尽管我们目前的方法已经能够恢复重要的书写细节并处理奇怪和草书手写,但我们的系统生成的非常草书手写风格的合成结果仍然不如原始的草书,因为该方法所学到的是用户的平均手写风格。如果需要,可以很容易地应用一些现有的技术(Lin和Wan 2007),使合成的字符更加草书,从而与原始字符更加相似。
最后但并非最不重要的是,如前所述,我们的方法可以很容易地扩展到许多其他书写系统。例如,图21显示了通过直接使用第4.2节中提到的学习模型获得的三种用户手写风格中的合成韩文字符的一些示例。我们认为,所提出的方法不仅适用于生成中文手写字体,还可以用于轻松构建其他语言的大规模手写字体库。
6 CONCLUSION
本文提出了一种新颖的系统,该系统能够从普通人编写的少量输入样本中学习手写风格,并为用户生成个人手写字体库,该库可以具有任意数量的汉字。实验结果表明,我们的系统可以用于自动生成高质量的手写字体库,其中包括大量机器生成的字符,这些字符与原始手写字体无法区分。未来,我们计划通过将强大的深度学习方法与书法专业领域知识相结合,进一步提高综合性能。
REFERENCES
M. Arjovsky, S. Chintala, and L. Bottou. 2017. Wasserstein GAN. arXiv preprint
arXiv:1701.07875 (2017).
S. Baluja. 2016. Learning typographic style. CoRR abs/1603.04000 (2016). http://arxiv.
org/abs/1603.04000.
W. Baxter and N. Govindaraju. 2010. Simple data-driven modeling of brushes. In Proc.
ACM SIGGRAPH Symposium on Interactive 3D Graphics and Games. 135–142.
E. Bernhardsson. 2016. Analyzing 50k fonts using deep neural networks. Re-
trieved from https://erikbern.com/2016/01/21/analyzing-50k-fonts-using-deep-
neural-networks/.
N. D. F. Campbell and J. Kautz. 2014. Learning a manifold of fonts. ACM Transactions
on Graphics 33, 4 (2014), 91.
X. Chen, Z. Lian, Y. Tang, and J. Xiao. 2017. An automatic stroke extraction method
using manifold learning. In Proc. Eurographics 2017 Short Paper.
Já. Dolinsky and H. Takagi. 2009. Analysis and modeling of naturalness in handwrit-
ten characters. IEEE Transactions on Neural Networks 20, 10 (2009), 1540–1553.
J. Dong, M. Xu, and Y. Pan. 2008. Statistic model-based simulation on calligraphy
creation. Chinese Journal of Computers 31, 7 (2008), 1276–1282 (In Chinese).
J. L. Elman. 1990. Finding structure in time. Cognitive Science 14, 2 (1990), 179–211.
J. Fan. 1990a. Intelligent Chinese character design and an experimental system ICCDS.
JCIP 4, 3 (1990), 1–11 (In Chinese).
J. Fan. 1990b. A method of computerizing the calligraphical rules basing on CC struc-
ture code. JCIP 4, 4 (1990), 43–52 (In Chinese).
FontCreator. 2017. High logic. Retrieved from http://www.high-logic.com/.
FontLab. 2017. Fontlab. Retrieved from http://www.fontlab.com/.
Founder. 2017. Founder group. Retrieved from http://www.foundertype.com/.
L. A. Gatys, A. S. Ecker, M. Bethge, S. Hertzmann, and E. Shechtman. 2017. Controlling
perceptual factors in neural style transfer. In Proc. CVPR 2017.
I. J. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A.
Courville, and Y. Bengio. 2014. Generative adversarial networks. In Proc. NIPS
2014.
T. S. F. Haines, M. Aodha, and G. J. Brostow. 2016. My text in your handwriting. ACM
Transactions on Graphics (TOG) 35, 3 (2016), 26.
K. He, X. Zhang, S. Ren, and J. Sun. 2016. Deep residual learning for image recognition.
In Proc. CVPR 2016. 770–778.
G. E. Hinton and R. R. Salakhutdinov. 2006. Reducing the dimensionality of data with
neural networks. Science 313, 5786 (2006), 504–507.
S. Hochreiter and J. Schmidhuber. 1997. Long short-term memory. Neural Computa-
tion 9, 8 (1997), 1735–1780.
P. Isola, J. Y. Zhu, T. Zhou, and A. A. Efros. 2017. Image-to-image translation with
conditional adversarial nets. In Proc. CVPR 2017.
B. K. Jang and R. T. Chin. 1990. Analysis of thinning algorithms using mathematical
morphology. IEEE Transactions on Pattern Analysis and Machine Intelligence 12, 6
(1990), 541–551.
L. Jin and X. Gao. 2004. Study of several handwritten Chinese character directional
feature extraction approaches. Application Research of Computers 21, 11 (2004),
38–40.
H. Khosravi and E. Kabir. 2010. Farsi font recognition based on Sobel–Roberts fea-
tures. Pattern Recognition Letters 31, 1 (2010), 75–82.
A. Krizhevsky, I. Sutskever, and G. E. Hinton. 2012. ImageNet classification with deep
convolutional neural networks. In Advances in Neural Information Processing Sys-
tems 25. 1097–1105.
P. K. Lai, D. Y. Yeung, and M. C. Pong. 1996. A heuristic search approach to Chinese
glyph generation using hierarchical character composition. Computer Processing
of Oriental Languages 10, 3 (1996), 307–323.
B. M. Lake, R. Salakhutdinov, and J. B. Tenenbaum. 2015. Human-level concept learn-
ing through probabilistic program induction. Science 350, 6266 (2015), 1332–1338.
N. Lawrence. 2005. Probabilistic non-linear principal component analysis with Gauss-
ian process latent variable models. Journal of Machine Learning Research 6, Nov
(2005), 1783–1816.
W. Li, Y. Song, and C. Zhou. 2014. Computationally evaluating and synthesizing Chi-
nese calligraphy. Neurocomputing 135, 5 (2014), 299–305.
Z. Lian and J. Xiao. 2012. Automatic shape morphing for Chinese characters. In Proc.
SIGGRAPH Asia 2012 TB. 2
Z. Lian, B. Zhao, and J. Xiao. 2016. Automatic generation of large-scale handwriting
fonts via style learning. In Proc. SIGGRAPH Asia 2016 TB. 12.
J. Lin, C. Wang, C. Ting, and R. Chang. 2014. Font generation of personal handwritten
Chinese characters. In Proc. IGIP 2014.
Z. Lin and L. Wan. 2007. Style-preserving English handwriting synthesis. Pattern
Recognition 40, 7 (2007), 2097–2109.
J. Long, E. Shelhamer, and T. Darrell. 2015. Fully convolutional networks for semantic
segmentation. In Proc. CVPR 2015. 3431–3440.
J. Lu, C. Barnes, S. DiVerdi, and A. Finkelstein. 2013. RealBrush: Painting with exam-
ples of physical media. In Proc. ACM SIGGRAPH 2013.
J. Lu, C. Barnes, C. Wan, P. Asente, R. Mech, and A. Finkelstein. 2014. DecoBrush:
Drawing structured decorative patterns by example. In Proc. ACM SIGGRAPH
2014.
J. Lu, F. Yu, A. Finkelstein, and S. DiVerdi. 2012. HelpingHand: Example-based stroke
stylization. In Proc. ACM SIGGRAPH 2012.
A. Myronenko and X. Song. 2010. Point set registration: Coherent point drift. IEEE
Transactions on Pattern Analysis and Machine Intelligence 32, 12 (2010), 2262–2275.
W. Pan, Z. Lian, R. Sun, Y. Tang, and J. Xiao. 2014. FlexiFont: A flexible system to
generate personal font libraries. In Proc. DocEng 2014. 17–20.
H. Q. Phan, H. Fu, and A. B. Chan. 2015. FlexyFont: Learning transferring rules for
flexible typeface synthesis. Computer Graphics Forum 34, 7 (2015), 245–256.
D. E. Rumelhart, G. E. Hinton, and R. J. Williams. 1986. Learning representations by
back-propagating errors. Nature 323, 6088 (1986), 533–536.
O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A.
Khosla, M. Bernstein, A. C. Berg, and L. Fei-Fei. 2015. ImageNet large scale visual
recognition challenge. International Journal of Computer Vision 115, 3 (2015), 211–
252.
D. Silver, A. Huang, and C. J. Maddison. 2016. Mastering the game of Go with deep
neural networks and tree search. Nature 529, 7587 (2016), 484–489.
K. Simonyan and A. Zisserman. 2014. Very deep convolutional networks for large-
scale image recognition. CoRR abs/1409.1556 (2014).
A. A. Soltani, H. Huang, J. Wu, T. Kulkarni, and J. Tenenbaum. 2017. Synthesizing 3D
shapes via modeling multi-view depth maps and silhouettes with deep generative
networks. In Proc. CVPR 2017.
S. Strassmann. 1986. Hairy brushes. In Proc. ACM SIGGRAPH 1986, Vol. 20. 225–232.
Z. Sun, L. Jin, Z. Xie, Z. Feng, and S. Zhang. 2016. Convolutional multi-directional
recurrent network for offline handwritten text recognition. In 2016 15th Interna-
tional Conference on Frontiers in Handwriting Recognition (ICFHR). 240–245.
R. Suveeranont and T. Igarashi. 2010. Example-based automatic font generation. In
Proc. Smart Graphics. 127–138.
Y. Tian. 2016. ReWrite. Retrieved from https://github.com/kaonashi-tyc/Rewrite/.
Y. Tian. 2017. ReWrite. Retrieved from https://github.com/kaonashi-tyc/zi2zi/.
Y. Wang, H. Wang, C. Pan, and L. Fang. 2008. Style preserving Chinese character
synthesis based on hierarchical representation of character. In Proc. ICASSP 2008.
1097–1100.
Z. Wang and Y. Pang. 1991. A computer calligraphy system CCCS. Journal of Computer
Aided Design and Computer Graphics 3, 1 (1991), 35–40 (In Chinese).
S. T. Wong, H. Leung, and H. H. S. Ip. 2008. Model-based analysis of Chinese calligra-
phy images. Computer Vision and Image Understanding 109, 1 (2008), 69–85.
W. Xia and L. Jin. 2009. A Kai style calligraphic beautification method for handwriting
chinese character. In Proc. ICDAR 2009. 798–802.
S. Xu, H. Jiang, T. Jin, F. Lau, and Y. Pan. 2008. Automatic facsimile of Chinese calli-
graphic writings. In Computer Graphics Forum, Vol. 27. 1879–1886.
S. Xu, H. Jiang, F. C. M. Lau, and Y. Pan. 2007. An intelligent system for Chinese
calligraphy. In Proc. The National Conference on Artificial Intelligence, Vol. 22. 1578.
S. Xu, T. Jin, H. Jiang, and F. C. M. Lau. 2009. Automatic generation of personal chinese
handwriting by capturing the characteristics of personal handwriting. In Proc.
IAAI 2009.
S. Xu, F. Lau, F. Tang, and Y. Pan. 2003. Advanced design for a realistic virtual brush.
In Computer Graphics Forum, Vol. 22. 533–542.
S. Xu, F. C. M. Lau, W. K. Cheung, and Y. Pan. 2005. Automatic generation of artistic
Chinese calligraphy. IEEE Intelligent Systems 20, 3 (2005), 32–39.
T. Yi, Z. Lian, Y. Tang, and J. Xiao. 2014. A data-driven personalized digital ink for
Chinese characters. In Proc. MultiMedia Modeling 2014. 254–265.
K. Yu, J. Wu, and Y. Zhuang. 2009. Style-consistency calligraphy synthesis system in
digital library. In Proc. the 9th ACM/IEEE-CS Joint Conference on Digital Libraries.
145–152.
Z. Zhang, C. Zhang, W. Shen, C. Yao, W. Liu, and X. Bai. 2016. Multi-oriented text
detection with fully convolutional networks. In Proc. CVPR 2016. 4159–4167.
B. Zhou, W. Wang, and Z. Chen. 2011. Easy generation of personal chinese handwrit-
ten fonts. In Proc. ICME 2011. 1 – 6 .
C. L. Zitnick. 2013. Handwriting beautification using token means. In Proc. ACM SIG-
GRAPH 2013.