深度学习模型相关部署的学习:(yolov5)WIN10+CUDA11.3+TensorRT
什么是模型部署?
模型部署时机器学习项目的最后阶段之一,是将训练好的机器学习模型提供给最终用户的途径。需要以下三个步骤:
- 模型持久化——一般以文件方式持久化
- 选择适合的服务器加载已经持久化的模型
- 提高服务接口,拉通前后端数据交流
一般有三种方法
- 依赖环境直接运行代码,flask框架下使用web提供服务
- 使用tensorflow serving
- tensorRT
tensorRT
caffe、pytorchde 等框架推荐Nvidia的TensorRT Inference Server,它支持所有模型的部署,包括TF系、ONNX系、mxnet等等,TRT会先对你的网络进行融合,合并可以同步计算的层,然后量化计算子图,让你的模型以float16、int8等精度进行推理,大大加速推理速度,而你只需要增加几行简单的代码就能实现。而且TRT Inference Server能够处理负载均衡,让你的GPU保持高利用率。
TensorRT是由C++、CUDA、python三种语言编写成ik=y一个库,其中核心代码为C++和CUDA,Python端作为前端与用户交互。当然,TensorRT也是支持C++前端的,如果我们追求高性能,C++前端调用TensorRT是必不可少的。
-
安装tensorRT
查看CUDA版本nvcc -V为CUDA11.3
查看CUDNN版本 8.4.0
登录NVIDA官网下载对应版本的tensorRT

下载完成后解压
按照以下操作将文件合并
这里
在VS中点击重新生成显示成功,但是在点击exe文件的时候显示寻找zlibwapi.dll失败
在这个网站
下载x64版本的ddl,然后将lib文件复制到CUDA的lib文件夹,dll文件复制到bin文件夹中
参考办法
显示如下则成功
这里就说明安装成功了,虽然提示了TensorRT was linked against cuDNN 8.4.1 but loaded cuDNN 8.4.0要加载cudnn8.4.1,但是本版本的cudnn8.4.0是支持cuda11.x的,所以可以正常运行的。 -
Yolov5转化为onnx
发现yolov5源代码中自带转化代码,export.py,所以只需运行相应语句即可完成转换
python export.py --weights runs/train/exp12/weights/best.pt --img 640 --batch 1
(yolo) E:\PycharmProjects\yolo\yolov5-master>python export.py --weights runs/train/exp44/weights/best.pt --img 640 --batch 1
export: data=E:\PycharmProjects\yolo\yolov5-master\data\coco128.yaml, weights=[‘runs/train/exp44/weights/best.pt’], imgsz=[640], batch_size=1, device=cpu, half=False, inplace=False, train
=False, keras=False, optimize=False, int8=False, dynamic=False, simplify=False, opset=12, verbose=False, workspace=4, nms=False, agnostic_nms=False, topk_per_class=100, topk_all=100, iou_
thres=0.45, conf_thres=0.25, include=[‘torchscript’, ‘onnx’]
YOLOv5 2022-6-20 Python-3.7.0 torch-1.10.0+cu113 CPU
Fusing layers…
Model summary: 213 layers, 7047883 parameters, 0 gradients, 15.9 GFLOPs
PyTorch: starting from runs\train\exp44\weights\best.pt with output shape (1, 25200, 19) (13.8 MB)
TorchScript: starting export with torch 1.10.0+cu113…
TorchScript: export success, saved as runs\train\exp44\weights\best.torchscript (27.3 MB)
requirements: onnx not found and is required by YOLOv5, attempting auto-update…
ONNX: starting export with onnx 1.12.0…
ONNX: export success, saved as runs\train\exp44\weights\best.onnx (27.3 MB)
Export complete (17.14s)
Results saved to E:\PycharmProjects\yolo\yolov5-master\runs\train\exp44\weights
Detect: python detect.py --weights runs\train\exp44\weights\best.onnx
PyTorch Hub: model = torch.hub.load(‘ultralytics/yolov5’, ‘custom’, ‘runs\train\exp44\weights\best.onnx’)
Validate: python val.py --weights runs\train\exp44\weights\best.onnx
Visualize: https://netron.app
就好了!hhh
使用netron可以查看onnx结构
- 安装onnx-simplifier简化模型
【为什么要简化?】在训练完深度学习的pytorch或者tensorflow模型后,有时候需要把模型转成 onnx,但是很多时候,很多节点比如cast节点,Identity 这些节点可能都不需要,我们需要进行简化,这样会方便我们把模型转成ncnn或者mnn等这些端侧部署的模型格式或者通过tensorRT进行部署。
pip install onnx coremltools onnx-simplifier
简化:
python -m onnxsim 路径/best.onnx yolov5s-best-sim.onnx
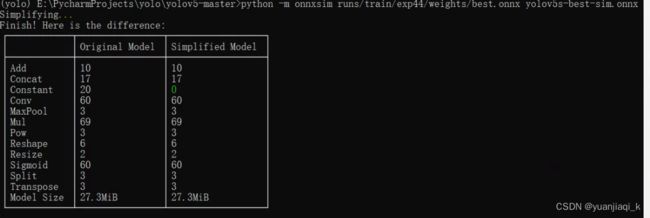
好像并没有简化多少哈
接下来就是先把onnx转化为TensorRT的trt文件,然后让c++环境下的TensorRT直接加载trt文件,从而构建engine。
两种方法:
- tensorRT自带文件进行转化
/usr/src/tensorrt/bin/trtexec --onnx=input.onnx --saveEngine=out.engine --fp16 --workspace=1024
- 直接使用python代码实现转化
import tensorrt as trt
import sys
import os
TRT_LOGGER = trt.Logger(trt.Logger.WARNING)
EXPLICIT_BATCH = 1 << (int)(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH)
def printShape(engine):
for i in range(engine.num_bindings):
if engine.binding_is_input(i):
print("input layer: {}, shape is: {} ".format(i, engine.get_binding_shape(i)))
else:
print("output layer: {} shape is: {} ".format(i, engine.get_binding_shape(i)))
def onnx2trt(onnx_path, engine_path):
with trt.Builder(TRT_LOGGER) as builder, builder.create_network(EXPLICIT_BATCH) as network, trt.OnnxParser(network, TRT_LOGGER) as parser:
#builder.max_workspace_size = 1 << 28 # 256MB
config = builder.create_builder_config()
config.max_workspace_size = 1 << 28
with open(onnx_path, 'rb') as model:
parser.parse(model.read())
#engine = builder.build_cuda_engine(network)
profile = builder.create_optimization_profile()
config = builder.create_builder_config()
config.add_optimization_profile(profile)
engine = builder.build_engine(network, config)
printShape(engine)
with open(engine_path, "wb") as f:
f.write(engine.serialize())
if __name__ == "__main__":
input_path = "E:/PycharmProjects/yolo/yolov5-master/yolov5s-best-sim.onnx"
output_path = input_path.replace('.onnx', '.engine')
onnx2trt(input_path, output_path)
tensorRT将yolov5部署至c++
上述步骤转成engine文件后卡住了,发现不会用c++对其进行处理
于是寻找了另一个部署方法,使用的代码为https://github.com/Monday-Leo/Yolov5_Tensorrt_Win10具体参照教程这里
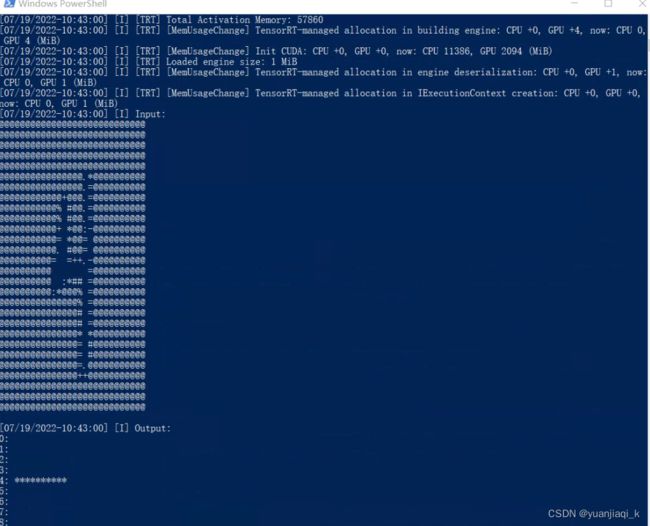
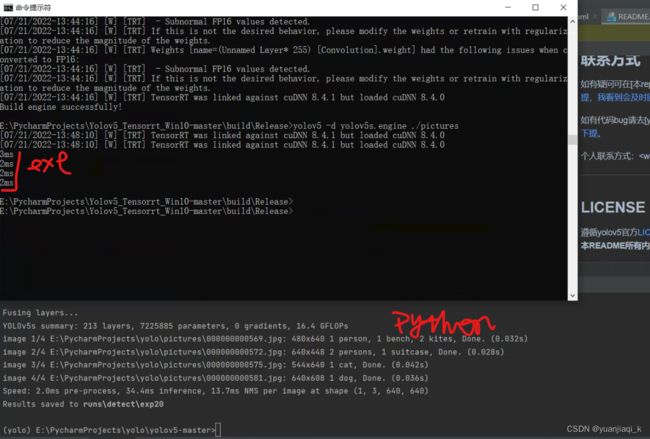
按照此方法成功运行exe文件
获得数据如下,与python进行对比,快了很多
!](https://img-blog.csdnimg.cn/162beec7fa034b56b8be86c1f9356041.png)
接下来对自己训练的权重模型进行部署,同样步骤即可完成
但是存在疑问就是如何能把项目封装起来合并入c++项目呢?