2022.11.5 学习周报
文章目录
- 摘要
- 文献阅读
-
- 1、题目
- 2、摘要
- 3、网络结构
-
- 3.1 网络示意图
- 3.2 稠密块
- 3.3 DenseNets结构的网络配置
- 4、问题的提出
- 5、DenseNet
-
- 5.1 普通卷积
- 5.2 残差结构
- 5.3 密集连接
- 6、实验
-
- 6.1 数据集
- 6.2 训练
- 6.3 CIFAR和SVHN的分类结果
- 6.4 ImageNet的分类结果
- 7、结论
- 深度学习
-
- 使用Pytorch实现DenseNet
- 总结
摘要
This week, a paper on Convolutional Neural Networks is analyzed by me, the DenseNet structure is introduced in the article, and the core content is the dense block. DenseNet inherits and carries forward the design of shortcuts in ResNet, so that layers can be densely interconnected, but it doesn’t stop there, because each layer in a dense block takes all the previous layers as input to this layer, and also to the following layers. The advantages of this dense connection are that it alleviates the vanishing gradient problem, enhances feature propagation, encourages feature reuse, and greatly reduces the amount of parameters.
本周,一篇关于卷积神经网络的论文被我分析了,文章中介绍了DenseNet结构,其核心内容是dense block稠密块。DenseNet继承和发扬了ResNet中shortcut的设计,使层与层之间可以稠密互联,但它不仅于此,因为稠密块中的每一层都会把前面所有层作为这一层的输入,并且也会作为后面层的输入。这种稠密连接的优点是减轻了梯度消失的问题,增强了特征传播,鼓励特征重复使用,并且大大减少了参数量。
文献阅读
1、题目
原文链接:Densely Connected Convolutional Networks
2、摘要
Recent work has shown that convolutional networks can be substantially deeper, more accurate, and efficient to trainif they contain shorter connections between layers close to the input and those close to the output. In this paper, we embrace this observation and introduce the Dense Convolutional Network (DenseNet), which connects each layer to every other layer in a feed-forward fashion. Whereas traditional convolutional networks with L layers have_ L connections—one between each layer and its subsequen tlayer—our network has L(L+1)/2 direct connections. Foreach layer, the feature-maps of all preceding layers areused as inputs, and its own feature-maps are used as inputs into all subsequent layers. DenseNets have several compelling advantages: they alleviate the vanishing-gradient problem, strengthen feature propagation, encourage feature reuse, and substantially reduce the number of parameters. We evaluate our proposed architecture on four highly competitive object recognition benchmark tasks (CIFAR-10,CIFAR-100, SVHN, and ImageNet). DenseNets obtain significant improvements over the state-of-the-art on most ofthem, whilst requiring less computation to achieve high performance. Code and pre-trained models are available at https://github.com/liuzhuang13/DenseNet.
3、网络结构
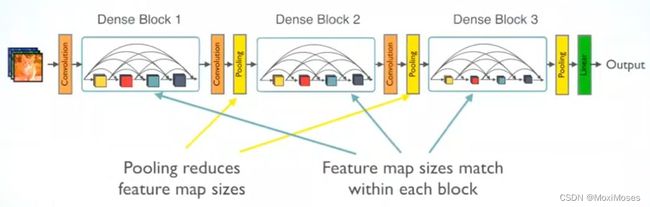
3.1 网络示意图
如下图所示,DenseNet由3个dense block稠密块组成,而稠密块之间的连接叫做Transition layer过渡层,由BN + 卷积层 + 池化层组成。
在论文中,卷积层采用1 * 1的卷积和2 * 2的池化,它的作用是通过1 * 1的卷积改变通道维,以及池化层下采样使feature maps的尺寸减半。
3.2 稠密块
如下图所示,这是一个5层的稠密块结构。Dense block稠密块内部的layer通过复合函数H来连接的,复合函数H的结构由BN + ReLU + 卷积组成。
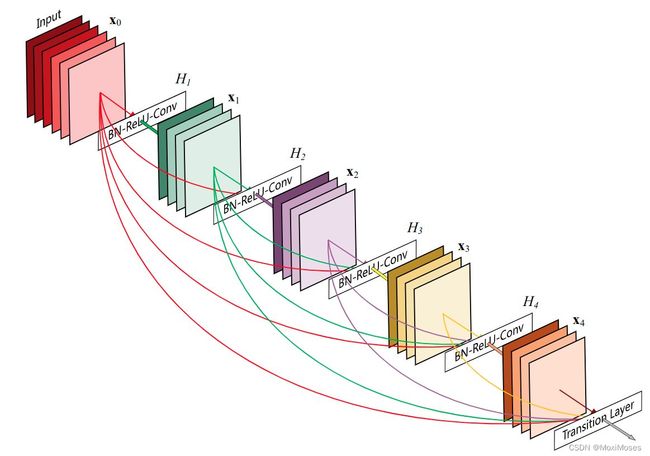
在DenseNet中,复合函数有两种结构:
1)BN + ReLU + 3 * 3卷积
主要作用是特征提取
2)BN + ReLU + 1 * 1卷积 → 输出 → BN + ReLU + 3 * 3卷积
主要作用除了上面的特征提取,还需要通过1 * 1卷积改变通道维数来维持整体维度,提高计算效率。
3.3 DenseNets结构的网络配置
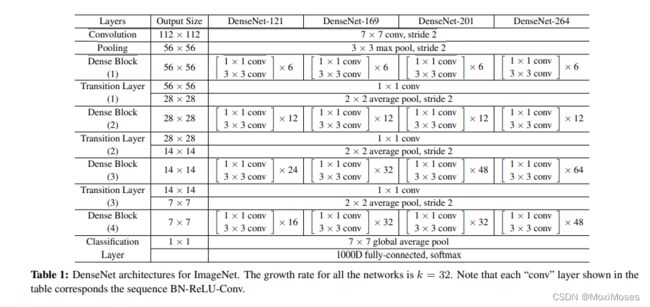
4、问题的提出
问题:随着网络模型的深度越来越深,会导致一些特征和梯度在经过许多层以后,可能会消失殆尽。
解决方案:在输入和输出之间建立尽可能短的连接路径。
于是,为了确保最大的信息流,将所有层直接相互连接,为了保持前馈性,每一层都会把前面所有层的输出作为输入,并且把自身得到的特征图也传入后续的layer中。
5、DenseNet
ResNet在特征传入layer之前,需要经过相加求和,得到组合特征传给下一层。而DenseNet与ResNet不同,它的组合方式不是求和,而是通过叠加的方式组合在一起。
5.1 普通卷积
在传统卷积神经网络的前馈传播中,假设整个网络一共有L层,网络最初的输入是x0,第l - 1层的输入是xl-1,经过非线性函数复合函数处理后得到第l层的输入是xl。
公式:xl = Hl(xl-1)
5.2 残差结构
在ResNets中,因为shortcut/skip connection的机制,所以第l层的输入由恒等映射和残差映射共同组成。
公式:xl = Hl(xl-1) + xl-1
5.3 密集连接
在DenseNet中,因为l层之前的所有层都是其输入,所以第l层的输入公式:xl = Hl([x0, x1, …, xl-1])
6、实验
6.1 数据集
训练使用了CIFAR-10,CIFAR-100,SVHN,ImageNet数据集。
6.2 训练
整体使用了0.0001的权重衰减,0.9的Nesterov动量。
CIFAR和SVHN:
训练采用了随机梯度下降SGD,在CIFAR和SVHN上采用batch size = 64分别训练了300和40轮;学习率初始设为0.1,在迭代总轮数达到50%和75%时,分别除10;在除第一个卷积层以外,其余的每个卷积层都添加了丢弃率0.2的Dropout。
ImageNet:
batch size = 256,epoch = 90,初始学习率0.1,第30轮和第60轮时分别除10,在ImageNet上使用了数据增强。
6.3 CIFAR和SVHN的分类结果
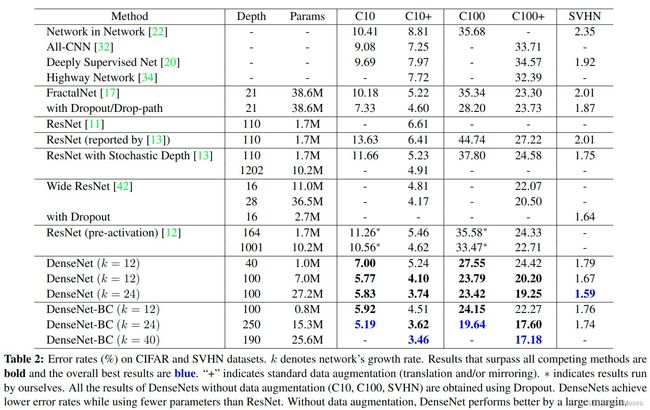
表中的结果显示:
1)在没有压缩或瓶颈层的情况下,DenseNet的总体趋势是随着层数L和k的增加而表现得更好。
2)DenseNet可以利用更大和更深层模型的增强表示能力,也表明DenseNet不存在过拟合的担忧,也不像残差网络存在优化困难的问题。
3)DenseNet比其他体系结构更能有效地利用参数,其中有瓶颈层和过渡层的DenseNet-BC更是能有效减少参数规模。
6.4 ImageNet的分类结果
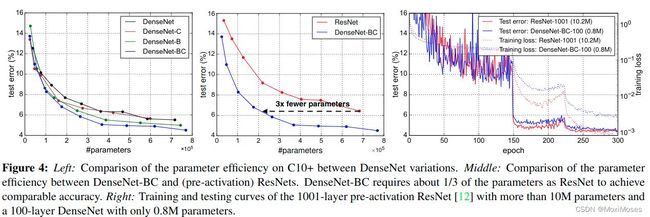
将不同深度的DenseNet-BC和目前最好的ResNet模型相比,其中所有的数据预处理,优化设置等都保持一致。图中的结果表明,DenseNet的性能与最新的ResNet差不多,但DenseNet所需要的参数和计算量却大大减少。
7、结论
1)因为DenseNet不需要重新学习冗余的特征图,于是它与传统的CNN相比,参数更少。
2)DenseNet改善了整个网络中的information flow和梯度,使得网络模型更容易训练。
3)网络模型中的密集连接具有正则化效果,能降低训练集size较小任务的过拟合现象。
深度学习
使用Pytorch实现DenseNet
首先实现DenseBlock中的内部结构,结构为BN + ReLU + 1 * 1 Conv + BN + ReLU + 3 * 3 Conv,最后加入dropout层以用于训练过程。
from collections import OrderedDict
import torch
from torch import nn
import torch.nn.functional as F
class DenseLayer(nn.Sequential):
def __init__(self, num_input_features, growth_rate, bn_size, drop_rate):
super(DenseLayer, self).__init__()
self.add_module("norm1", nn.BatchNorm2d(num_input_features))
self.add_module("relu1", nn.ReLU(inplace=True))
self.add_module("conv1", nn.Conv2d(num_input_features,
bn_size * growth_rate,
kernel_size=1,
stride=1,
bias=False))
self.add_module("norm2", nn.BatchNorm2d(bn_size * growth_rate))
self.add_module("relu2", nn.ReLU(inplace=True))
self.add_module("conv2", nn.Conv2d(bn_size * growth_rate,
growth_rate,
kernel_size=3,
stride=1,
padding=1,
bias=False))
self.drop_rate = drop_rate
def forward(self, x):
new_features = super(DenseLayer, self).forward(x)
if self.drop_rate > 0:
new_features = F.dropout(new_features,
p=self.drop_rate,
training=self.training)
return torch.cat([x, new_features], 1)
实现DenseBlock模块,内部是密集连接方式,其中输入特征数线性增长。
class DenseBlock(nn.Sequential):
def __init__(self, num_layers, num_input_features, bn_size, growth_rate, drop_rate):
super(DenseBlock, self).__init__()
for i in range(num_layers):
layer = DenseLayer(num_input_features + i*growth_rate,
growth_rate,
bn_size,
drop_rate)
self.add_module("denselayer%d" % (i+1,), layer)
实现过渡层,它主要有1个卷积层和1个池化层。
class TransitionLayer(nn.Sequential):
def __init__(self, num_input_feature, num_output_features):
super(TransitionLayer, self).__init__()
self.add_module("norm", nn.BatchNorm2d(num_input_feature))
self.add_module("relu", nn.ReLU(inplace=True))
self.add_module("conv", nn.Conv2d(num_input_feature,
num_output_features,
kernel_size=1,
stride=1,
bias=False))
self.add_module("pool", nn.AvgPool2d(2, stride=2))
实现DenseNet网络模型:
class DenseNet(nn.Module):
def __init__(self, growth_rate=32, block_config=(6, 12, 24, 16), num_init_features=64,
bn_size=4, compression_rate=0.5, drop_rate=0, num_classes=1000):
super(DenseNet, self).__init__()
# first Conv2d
self.features = nn.Sequential(OrderedDict([
("conv0", nn.Conv2d(3, num_init_features, kernel_size=7, stride=2, padding=3, bias=False)),
("norm0", nn.BatchNorm2d(num_init_features)),
("relu0", nn.ReLU(inplace=True)),
("pool0", nn.MaxPool2d(3, stride=2, padding=1))
]))
# DenseBlock
num_features = num_init_features
for i, num_layers in enumerate(block_config):
block = DenseBlock(num_layers, num_features, bn_size, growth_rate, drop_rate)
self.features.add_module("denseblock%d" % (i + 1), block)
num_features += num_layers * growth_rate
if i != len(block_config) - 1:
transition = TransitionLayer(num_features, int(num_features * compression_rate))
self.features.add_module("transition%d" % (i + 1), transition)
num_features = int(num_features * compression_rate)
# final bn+ReLU
self.norm5 = nn.BatchNorm2d(num_features)
self.relu5 = nn.ReLU(inplace=True)
# classification layer
self.classifier = nn.Linear(num_features, num_classes)
# params initialization
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1)
elif isinstance(m, nn.Linear):
nn.init.constant_(m.bias, 0)
def forward(self, x):
features = self.features(x)
out = F.avg_pool2d(features, 7, stride=1)
out = out.view(features.size(0), -1)
out = self.classifier(out)
return out
net = DenseNet()
print(net)
总结
DenseNet是一个非常优秀的网络结构,虽然它借鉴了ResNet中shortcut的设计思想,但它目的不是加深网络,而是想通过功能重复使用去挖掘网络模型的潜力。与ResNet相比,DenseNet的模型更加浓缩,因此DenseNet的表现会更好。下周,我将继续CNN卷积神经网络相关内容,并且尝试用代码实现CNN变体模型。