Vision Transformer论文精读
论文:An Image Is Worth 16x16 Words: Transformers For Image Recognition At Scale
目录
摘要
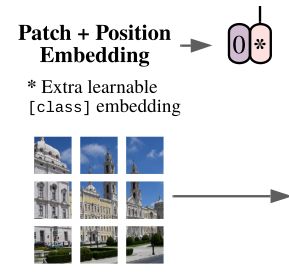
Vision Transformer模型结构
Embedding层
Position Embedding
class embedding
Transformer Eencoder
layer norm
Multi-Head Attention
Dropout/DropPath
MLP
归纳偏置
总结
效果
展望
摘要
很多任务将attention加入原来的CNN中保持,原有框架不变,例如resnet50每一个layer都保留,只在堆叠的block中添加attention,他们表面这种操作是不必要的,直接使用纯的transformer架构用于视觉任务中也能获得一个比较好的结果。
并且只需要相对较少的计算资源,当然他说的‘少’指的是2500天TPUv3,只是对于谷歌其他大模型来说相对少。

Vision Transformer模型结构
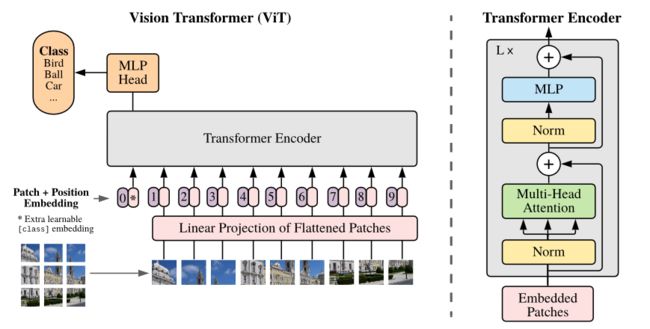
Embedding层
transformer的输入token是向量,所以要先将图像通过Embedding转换成一串向量
具体的转换方式很多,在论文的引言中有介绍前人为了降低序列长度使图像能够作为transformer输入所做的工作(分析该方向前人工作做了那些,再说自己的创新是那些,分析清楚更有可能被接受,不用担心前人工作跟你的很相似,引言就提到了许多将transformer往视觉领域融合的论文,然后说他们是尽可能不改变transformer原有结构,不做针对视觉任务的特定改变,实验transformer架构的可扩展性好不好,讲故事的思路+1)
例如直接将图像划分成多个小块(patch),再展平成向量
也有结合cnn来做的,先将图像送入传统的卷积神经网络,提取出小块的比较深层的特征后再将其展平成向量
本文是直接用的一个16*16的卷积核768个,步长为16进行一次卷积获取的patch,输入特征通过预处理成224,卷积后图像大小变为14*14*768,将高宽展平成196,输出就为196*768,将每个通道的同一位置串起来串成一个维度为通道数的向量,构造出196个向量作为输入,每个向量长768维。
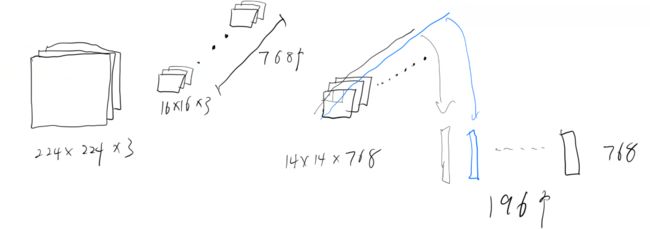
(这里我第一次看理解错了,直观理解的是对每个通道展开成向量,添加注意力求每个通道之间的关联性,做成768个196维的向量。通过不同卷积核的不同权重,每个通道会提取出一个不同的特征,求各个特征之间的相关性,埋个坑留意一下有人做过没,看看效果)
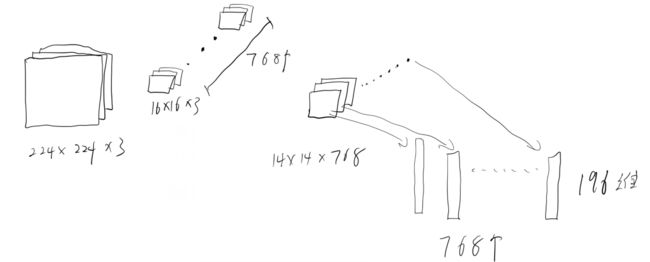
在将获取的向量输入Encoder之前,还要先做Position Embedding和添加一个分类头。
Position Embedding
添加位置编码,使得模型可以学习到每一串向量之间的位置关系,
相比不添加位置编码可以提升三个点左右
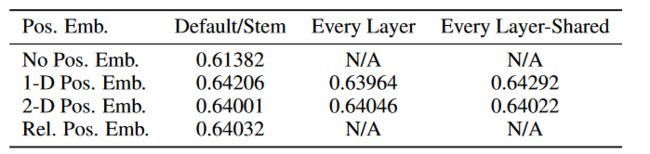
但是添二维或者相对位置编码和一维相比并没什么提升
class embedding
上述总流程图中0号位对应的[class]token就是额外添加的分类头,是可学习向量,长度与patch的长度相同为768
添加[class]token后维度从196*768变为197*768
计算注意力的时候也会计算其他所有由图像Embedding得来的向量和[class]token的关系,最后只输出[class]token到MLP中得出一个类别
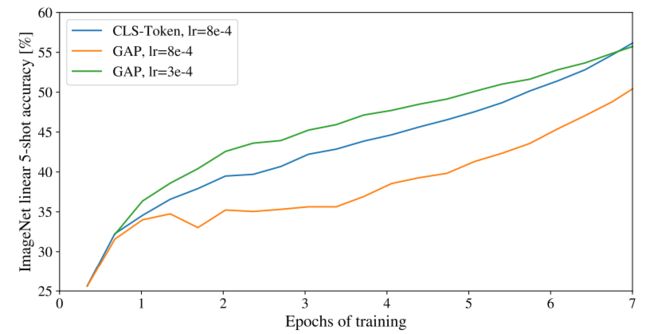
此处做输出的方式也不是唯一的,可以不加[class]token,直接输出每一个向量,然后做一个GAP(全局平均池化global average pooling)+fc全连接层来分类。
文章中也给出了这两种输出方式的效果,直接将cls-token的学习率搬过来效果是不好的, 所以调参很重要。
Transformer Eencoder
Transformer Eencoder具体结构就是将右图模块堆叠L次,由于本文是希望直接将transformer结构拿过来做图像处理,证明它也能得到一个很好的结果,所以很多地方都是尽量不改动transformer的原有结构的,但是这些地方都是可以改动后实验效果的。
更加具体的Encoder Block结构如下
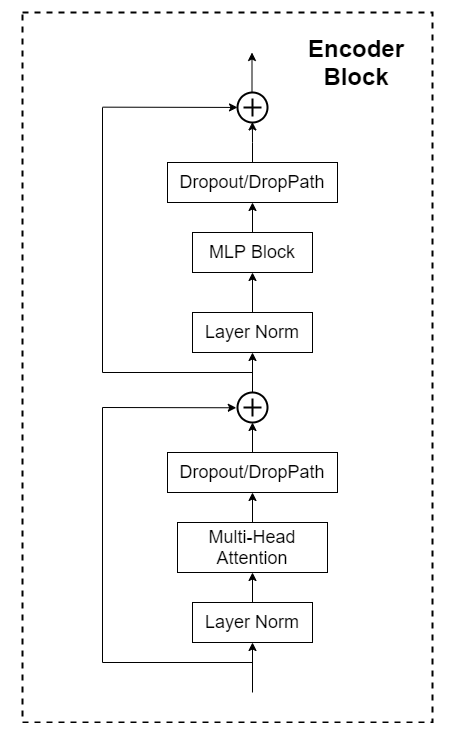
layer norm
对同一个样本的不同维度计算均值方差(batch norm是对不同样本的同一纬度计算)
参考链接
Multi-Head Attention
计算每个输入的多头注意力参考链接
补充一下,此处是用nn.Linear实现的
先看一下线性变化怎么转换为上述连接中注意力中的矩阵乘法
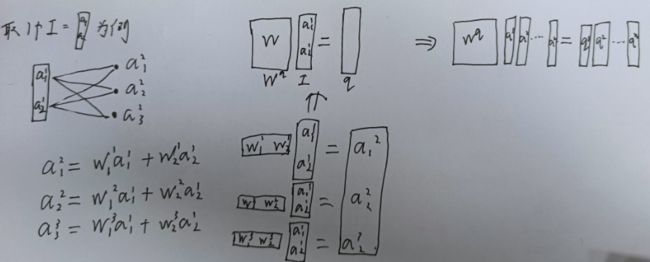
然后用在VIT中,Encoder的输入是196个768维的向量,将输入的197*768直接放入线性层,并将输出维度扩充为原来三倍(qkv一起计算)
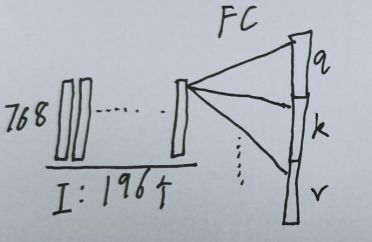
对其中一个的计算示意图如下
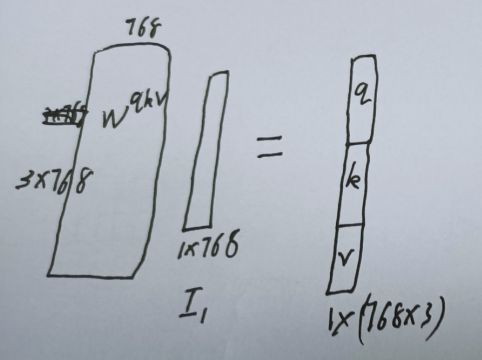
对197个向量都进行如下运算即可得到q k v矩阵
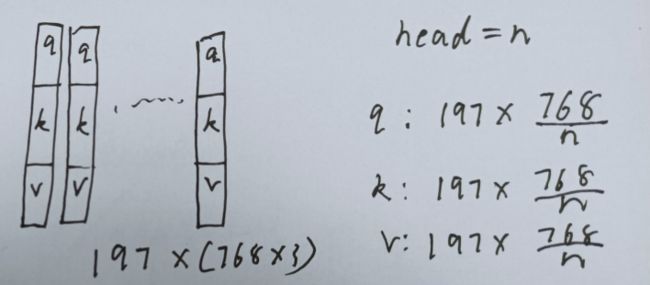
如果是普通注意力,q k v分别取前768个,中间,和最后768个即可
如果是多头注意力,还需要将q k v均分成n份
Dropout/DropPath
在原论文的代码中是直接使用的Dropout层,可以替换为后者看看效果,后续代码实现用的后者
MLP
MLP结构如下
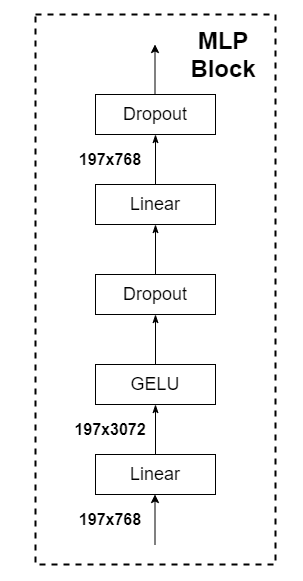
经过Encoder Block后的[class]token长度是不变的,还是1*768
将添加的分类头也就是[class]token向量输入MLP经过一些线性层和激活后输出
第一个全连接层会把输入节点增加4倍,第二个全连接层再还原
归纳偏置
在使用cnn时有一些注定的先验知识,例如卷积时窗口滑动,给每两个相邻块之间都有位置信息locality,局部性和平移等变性贯穿整个模型。
在vit中只有mlp是局部的,其他的如attention encoder等都是全局的,每个向量之间的注意力计算可以独立进行,就是具备F(g(x))=G(f(x))的可交换性,没有添加先验信息

总结
效果
作者跟自家的几个比较大的模型做了比较,VIT-huge基本都取得了最好结果,但领先很少
于是从训练成本上突出VIT效果,最后一排为TPUv3训练需要的天数,是优于最后两个大模型的
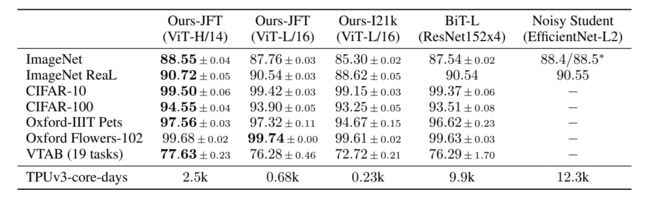
随着数据量的增大,模型acc图如下
BIT指的是各种不同深度的ResNet,灰色部分就是不同ResNet的精度范围
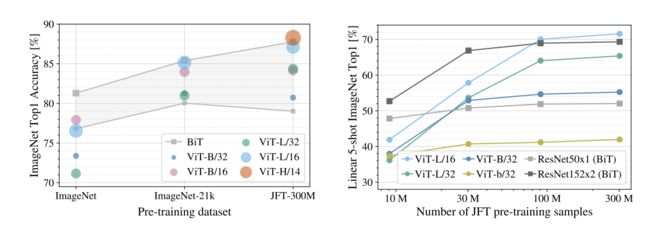
resnet vit hybrid三种模型的性能比较
hybrid混合模型,就是先用resnet-50提取深层特征,再将提取的内容放入transformer中添加注意力
训练样本少时混合模型会比resnet和vit都要好一些,样本增大后就被反超了
随着样本增加resnet和vit并没有一个趋于平缓的趋势,相当于还没有饱和可以继续增加数据集尝试
展望
VIT埋下了许多可做的方向的坑
Vision Transformer做的是分类,后面出了很多用注意力做目标检测语义分割的
例如Vision Transformer是从bert参考过来的,但是做的是有监督视觉任务,而没体现出bert在遮挡已知句子的词来做预测的自监督的感觉,所以后来有了用transformer做自监督的MAE(何凯明)
或者魔改输入encoder之前的输入向量的获取方式,或者改encoder结构
metaformer:认为transformer起作用的原因不是注意力等具体的算子,而是这整个架构,于是将注意力替换为一个池化,也能取得好的效果