2022.9.4 第二十二次周报(假期总结)
目录
前言
学习总结
内容总览
deep learning
反向传播
seqence-to-sequence model
GAN
Self-supervised Learning
auto-encoder
model attack
强化学习(Reinforcement Learning, RL)
模型压缩 network compression
终身学习
Meta Learning
总结
前言
从四月开始到九月份,已经开始尝试周报学习五个月时间。慢慢的从生疏到得心应手,个人感觉在写作方面得到了小小的提升。这五个月期间主要学习了机器学习的相关知识,主要了解了各种各样的模型,例如CNN,RNN,sequence to sequence,自注意力机制等等。
学习总结
内容总览
学习了台大李宏毅老师的机器学习网课,总共分为十五个章节:
1-5:监督式学习 supervised learning
6:生成对抗网络 generative adversarial network
7:自我监督学习 self-supervised learning
8:异常检测 anomaly detection
9:可解释性AI explainable AI
10:模型的攻击 model attack
11:领域适应 domain adaptation
12:强化学习 reinforcement learning(RL)
13:模型压缩 network compression
14:终身学习 life-long learning
15:元学习 meta learning
下面我们分别回忆一下各知识点内容
deep learning
我们都知道机器学习有三个step,对于deep learning其实也是3个步骤:
Step1:神经网络(Neural network)
Step2:模型评估(Goodness of function)
Step3:选择最优函数(Pick best function)
在神经网络中计算损失最好的方法就是反向传播,我们可以用很多框架来进行计算损失,比如说TensorFlow,theano,Pytorch等等。
反向传播
损失函数(Loss function)是定义在单个训练样本上的,也就是就算一个样本的误差,比如我们想要分类,就是预测的类别和实际类别的区别,是一个样本的,用L表示。
代价函数(Cost function)是定义在整个训练集上面的,也就是所有样本的误差的总和的平均,也就是损失函数的总和的平均,有没有这个平均其实不会影响最后的参数的求解结果。
总体损失函数(Total loss function)是定义在整个训练集上面的,也就是所有样本的误差的总和。也就是平时我们反向传播需要最小化的值。
seqence-to-sequence model
transformer 是一种seqence-to-sequence model。
通常Seq2Seq模型会分成两部分,一个是Encoder另一个是Decoder。
Encoder(编码器)要做的事情就是给一排向量,输出一排向量。
像RNN、CNN等都能完成这个任务。而在Transformer中用的是Self-attention来实现的。
Transformer的Encoder乍看起来非常复杂,首先它是由很多个Block组成的,每个Block都是输入一排向量,输出一排向量。最下面的Block的输出又可以作为它上面那个Block的输入,这样叠加起来。最上面一个Block就会输出最终的向量序列。而每个Block里面是由好几层组成的。在Transformer的Encoder里面,每一个Block做的事情是,一排向量,输入到Self-attention中,然后得到另外一排向量,然后给全连接网络(FC),再得到Block的输出。
Decoder有两种,一种是Autoregressive Decoder(AT),另一种是Non-autoregressive (NAT)。
GAN
生成式对抗网络(GAN, Generative Adversarial Networks )是一种深度学习模型,是近年来复杂分布上无监督学习最具前景的方法之一。模型通过框架中(至少)两个模块:生成模型(Generative Model)和判别模型(Discriminative Model)的互相博弈学习产生相当好的输出。
Self-supervised Learning
supervised:比如说现在输入一篇文章,判断它是正面还是负面文章。我们就需要文章和label(它是正面还是负面)才能够进行train。
self-supervised:在没有label的情况下,自己想办法做supervised。假设现在只有一堆文章,没有标注,想办法让一部分文章作为model的输入,另一部分作为label,让y与x1越接近越好。
auto-encoder
自编码器(auto-encoder, AE)是一类在半监督学习和非监督学习中使用的人工神经网络(Artificial Neural Networks, ANNs),其功能是通过将输入信息作为学习目标,对输入信息进行表征学习(representation learning) 。
自编码器包含编码器(encoder)和解码器(decoder)两部分 。
自编码器模型跟Cycle GAN很像,输入的高维度特征通过编码器还原成低维度的向量,向量再通过解码器转成新特征,encoder的输入和decoder的输出越接近越好。
Cycle GAN是用生成器将x转成y,再将y用生成器还原成x,比较输入和输出相似度。
把高纬度的东西转化为低维度的东西就叫做Dimension reduction。
model attack
black box attack:不知道model参数是什么
我们可以通过同一组训练集来训练一个network proxy,来模拟network black
从而通过攻击network proxy观察,就可以来攻击network black。但是我们如果完全没有训练资料怎么办呢?
可以把一堆图片丢到NN中,得到输出的图片,把输入和输出图片丢到network proxy来训练出一个模型。

防御的话有些思路是十分直观的。例如,前面提到的攻击都是对图像进行一定的扰动,那么我们可以在将图片输入网络前先进行一些预处理,这样就可以消掉图像中的恶意信息。这么做有两个问题。首先就是由于训练的时候是没有这些“数据增强”的,因此会对模型的性能造成影响;第二就是如果这些防御措施也泄露了的话,那么攻击者可以直接把这些预处理步骤视为网络的一部分一起攻击。
强化学习(Reinforcement Learning, RL)
强化学习(Reinforcement Learning, RL),又称再励学习、评价学习或增强学习,是机器学习的范式和方法论之一,用于描述和解决智能体(agent)在与环境的交互过程中通过学习策略以达成回报最大化或实现特定目标的问题。
强化学习是智能体(Agent)以“试错”的方式进行学习,通过与环境进行交互获得的奖赏指导行为,目标是使智能体获得最大的奖赏,强化学习不同于连接主义学习中的监督学习,主要表现在强化信号上,强化学习中由环境提供的强化信号是对产生动作的好坏作一种评价(通常为标量信号),而不是告诉强化学习系统RLS(reinforcement learning system)如何去产生正确的动作。由于外部环境提供的信息很少,RLS必须靠自身的经历进行学习。通过这种方式,RLS在行动-评价的环境中获得知识,改进行动方案以适应环境。
强化学习把学习看作试探评价过程,Agent选择一个动作用于环境,环境接受该动作后状态发生变化,同时产生一个强化信号(奖或惩)反馈给Agent,Agent根据强化信号和环境当前状态再选择下一个动作,选择的原则是使受到正强化(奖)的概率增大。选择的动作不仅影响立即强化值,而且影响环境下一时刻的状态及最终的强化值。
模型压缩 network compression
网络剪枝:神经网络的参数有很多,但其中有些参数对最终的输出结果贡献并不大,相反就显得冗余,将这些冗余的参数剪掉的技术称为剪枝。剪枝可以减小模型大小、提升运行速度,同时还可以防止过拟合。简单来说,network有多余的参数,将这些多余的参数减掉,实现network的compression。
知识蒸馏:
整个知识蒸馏过程中会用到两个模型:大模型 Teacher Net 模型和小模型Student Net模型。
用小的network去模拟大的network:
训练一个大网络,用小网络学习大网络。并计算两者之间的cross-entropy,使其最小化,从而可以使两者的输出分布相近。
参数量化:
less bits:使用更少bit来存储数据,例如一般默认是64位或者32位,那我们可以用16或者8位来存数据。
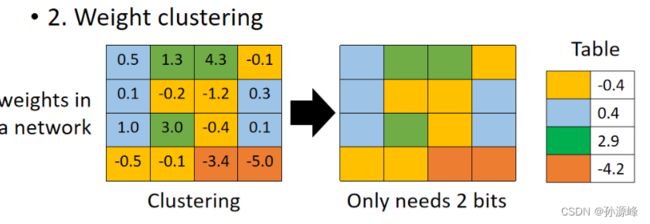
weight clustering:如图所示,最左边表示网络中正常权重矩阵,之后我们对这个权重参数做聚类,比如将16个参数做聚类,最后得到了4个聚类,那么为了表示这4个聚类我们只需要2个bit,即用00,01,10,11来表示不同聚类。之后每个聚类的值就用均值来表示。这样的一个缺点就是误差可能会比较大。
huffman encding:对于常出现的聚类用少一点的bit来表示,而那些很少出现的聚类就用多一点的bit来表示。
Network架构设计:
动态计算:
该方法的主要思路是如果目前的资源充足,那么算法就尽量做到最好,比如训练更久,或者训练更多模型等;反之,如果当前资源不够,那么就先算出一个过得去的结果。
一个Network可以自由的调整它的运算量。
终身学习
人们希望机器可以通过学习一个又一个的任务,来获得更多的技能。
Life Long Learning就是让机器可以持续学习,能处理各种各样的任务。也就是模型通过不断看新的资料,得到反馈,然后更新自身,变得更厉害,能处理更多事情。
Meta Learning
meta learning = learn to learn
元学习其实就是阐释训练模型的一种算法。
元学习是通过一系列task的训练,让机器成为一个更好的学习者,当机器遇到新的学习任务时,就能更快的完成。类比到现实生活中,元学习不是指某一类的知识内容,更像是学习一种学习方法。
Meta learning指的是找到产生f的函数F,向F输入训练数据,可以产生满足需求的f。
总结
学习了这几个月的时间,感觉自己还有很多的不足。希望在接下来的时间里,可以学习到更深层次的知识,在某一方面有更好的发展。