2022.11.13 第七次周报
文章目录
- 前言
- 一、文献阅读 《Convolutional Networks with Dense Connectivity》
-
- DenseNet提出
- DenseNet介绍
- 影响因子
-
- 生长速率
- 瓶颈层宽度
- 压缩因子
- DenseNet细节--数据存储方式
-
- 向前传播时
- 向后传递时
- DenseNet与ResNet对比
- DenseNet的优势与不足
-
- 优势
- 不足
- 二、模型分析
-
- 1.VGGNet
-
- 1.1感受野与网络深度
- 1.2 VGGNet框架
- 1.3VGGNet的优势
- 1.4VGGNet的不足
- 2.GoogleNet
-
- 2.1Google框架
- 2.2 inception模型
- 1.3VGGNet的优势
- 3.ResNet
-
- 3.1 ResNet提出的必要性
- 3.2 残差结构
- 3.3 ResNet结构
- 三、Tensorflow学习
- 总结
前言
This week the paper 《Convolutional Networks with Dense Connectivity》 has analyzed and studied, and this paper was published in IEEE Transactions on Pattern Analysis and Machine Intelligence in 2019. Of course, it is impossible to understand all the knowledge of the paper, so learning the construction and thinking of the new model DenseNet is my main assignment. At the same time ,the model VGGNet, GoogleNet, and ResNet were analyzed and compared to understand their advantages and disadvantages. And I also learned some of the usage methods and tips of Tensorflow.
在这周这论文《Convolutional Networks with Dense Connectivity》被阅读和学习了,这篇论文于2019年被发表于IEEE Transactions on Pattern Analysis and Machine Intelligence ,可想而知其含金量。当然,未能对论文全部知识都融汇贯通,只是对新模型DenseNet的构建的和思维进行学习。同时也对VGGNet,GoogleNet,和ResNet进行了分析和对比,了解它们的优缺点和如何一步步发展的。并且还学习了tensorflow的一些使用方法和技巧。
一、文献阅读 《Convolutional Networks with Dense Connectivity》
DenseNet提出
ResNets的最新变体表明,许多层的贡献非常小,实际上可以在训练过程中随机丢弃。
这使得ResNets的状态类似于(展开的)循环神经网络[8],但是ResNets的参数数量要大得多,因为每一层都有自己的权重。我们提出的DenseNet体系结构明确区分了添加到网络中的信息和保留的信息。DenseNet层非常窄(例如,每层12个特征映射),只在网络的“集体知识”中添加一小组特征映射,并保持剩余的特征映射不变,使最终的分类器能够基于网络中的所有特征映射进行决策。
除了更好的参数效率,DenseNets的另一个巨大优势是它们更容易训练,因为它们改进了整个网络的信息流和梯度。每一层都可以直接访问来自损失函数和原始输入信号的梯度,促进了隐式的深度监督[9]。最后,密集的连接在网络中产生了许多短路径,具有很强的正则化效果,减少了在较小训练集上的过拟合。
DenseNet介绍
在这篇论文中介绍了密集卷积网络(DenseNet),它以前馈方式连接每一层到每一层。
DenseNet整体结构:

传统的有L层的卷积网络有L个连接——每层和它的下一层之间有一个连接——而我们的网络有L(L+1) 2个直接连接。对于每一层,前面所有层的特征映射被用作输入,它自己的特征映射被用作后面所有层的输入。densenet有几个引人注目的优点:它们缓解了消失梯度问题,加强了特征传播,鼓励特征重用,并大幅提高了参数效率。
DenseNet中间层结构:
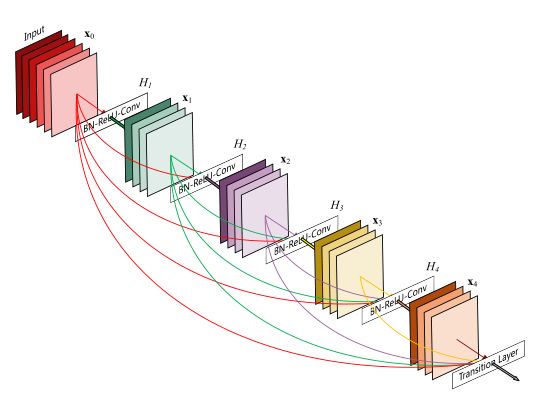
DenseNet没有从极深或极宽的体系结构中获取表示能力,而是通过特征重用来开发网络的潜力,生成易于训练和参数高效的浓缩模型。将不同层学习到的特征映射连接起来,增加了后续层输入的变化,提高了效率。
影响因子
DenseNets的性能。具体来说,我们检查了N三个超参数:增长率k,瓶颈宽度(1×1瓶颈层中的过滤器数量)和过渡层的压缩率θ。
生长速率
生长速率即产生的特征图的数量,生长速率决定了每一层的宽度。但由于密集的连通性,即使是非常窄的层(如k = 8)的densenet也可以被有效训练。尽管每一层只产生8个特征图,模型仍然产生了高度竞争性的结果。事实上,小的增长率对于densenet实现高计算效率是必不可少的。例如,要实现24%的验证错误,增长率为24DenseNet大约需要0.50×1010 flops;而增长率为40的类似架构需要0.88×1010的失败。然而,随着网络的深入,更高的增长率似乎显示出更大的潜力。这表明,要实现高效率的DenseNet,必须保证其深度和宽度兼容。值得注意的是,由于更好的并行性,更宽的卷积层可以在gpu上更有效地计算。
瓶颈层宽度
在变换H '中引入滤波器大小为1×1的卷积层,显著提高了DenseNets的参数效率。它在将连接的特征映射传递到更昂贵的3×3卷积层之前,对它们执行降维。其中,颈层宽度也应与网络深度相适应,以使DenseNets的参数效率最大化。
压缩因子
在之前的DenseNets实验中,两个密集块之间的每一个过渡层都使通道数量减半,即我们始终设置θ = 0.5。一般来说,DenseNets的参数效率对压缩率不敏感。当flops大于0.8×1010时,θ = 0.3, θ = 0.5, θ = 0.7三条曲线之间差异不显著。然而,我们确实观察到,当模型尺寸较小时,具有较小压缩因子的densenet始终优于具有较大压缩因子的densenet。这在某种程度上是违反直觉的,因为我们期望较小的压缩因子(更多的减少)在较大的模型中更有益,这往往会在特征映射中产生更多的冗余,因为二次增长的连接。
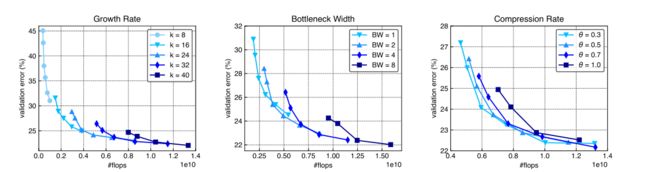
其增长速度(左)不同,瓶颈层的宽度(中)不同,过渡层的压缩比(右)不同。
DenseNet细节–数据存储方式
向前传播时
值得提一下的是DenseNet的数据存储方式。在训练过程中,网络不仅需要中间特征映射来计算输出特征,还需要中间特征映射来计算参数梯度。大多数深度学习库会将所有中间特征映射存储在GPU内存中,直到向前和向后传递完成。如果在每一层分配新的空间来存储连接的特征,导致内存消耗的快速增长。为了避免这种冗余,我们可以预先分配一个内存缓冲区,它最终将包含一个密集块的所有输出特征映射。单个层的计算包括从共享内存缓冲区读取相关特征映射,计算该层的输出,并将这些输出存储在内存缓冲区的连续部分中。在支持对跨张量操作的张量库中(如cudnn),所有这些操作都可以就地执行,这导致了特征映射逻辑的高效内存实现,而不需要复杂的内存管理,而其他卷积网络体系结构则需要高效内存。
向后传递时
尽管共享连接的特征的内存可以避免保存冗余的输出特征,但每一层的预激活批归一化仍然需要存储所有先前输出特征的归一化副本。这也说明了相对于网络深度的二次型内存消耗。与卷积相比,批处理归一化层(以及后续的ReLU)的计算成本要低得多。当需要进行梯度计算时,可以动态地重新计算标准化的特征映射,而不是为向后传递存储所有的特征映射。因此,我们只需要分配一个由所有批处理归一化层共享的全局内存(后期BN层只是覆盖早期BN层的输出)。这种策略通常可以应用于其他体系结构,而它对DenseNet尤其有用,因为它允许我们用非常小的内存消耗来训练DenseNet。通过这种优化,我们能够使用相同的内存训练三倍大的模型,同时引入很少的计算时间开销。
DenseNet与ResNet对比
因为DenseNet模型的提出是在ResNet的基础上的,所以也大量关注与ResNet之间的比较。
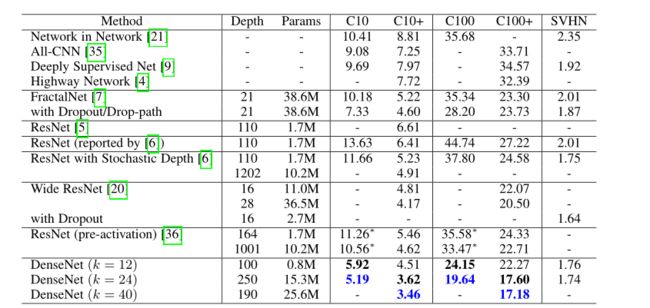
DenseNet与Res Net对比
•ResNet(深度残差网络,Deep residual network, ResNet):通过建立前面层与后面层之间的“短路连接”,这有助于训练过程中梯度的反向传播,从而能训练出更深的CNN网络。
DenseNet :采用密集连接机制,即互相连接所有的层,每个层都会与前面所有层在channel维度上连接(concat)在一起,实现特征重用,作为下一层的输入。这样,不但减缓了梯度消失的现象,也使
其可以在参数与计算量更少的情况下实现比ResNet更优的性能。
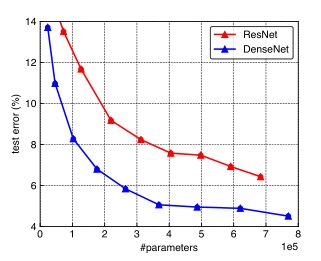
DenseNet的优势与不足
优势
- 更强的梯度流动:由于密集连接方式,DenseNet提升了梯度的反向传播,使得网络更容易训练。由于每层可以直达最后的误差信号,实现了隐式的"deep supervision”。误差信号可以很容易地传播到较早的层所以较早的层可以从最终分类层获得直接监管(监督)减轻了vanishing-gradient(梯度消失)过梯度消失问题在网络深度越深的时候越容易出现,原因就是输入信息和梯度信息在很多层之间传递导致的,而现在这种dense connection相当于每一层都直接连接input和loss,因此就可以减轻梯度消失现象,这样更深网络不是问题。
- 减少了参数。
- 保存了低维度的特征:在标准的卷积网络中,最终输出只会利用提取最高层次的特征,但DenseNet中,它使用了不同层次的特征,倾向于给出更平滑的决策边界,这有利于在训练数据不足的情况下,依然表现良好。
不足
DenseNet的不足在于由于需要进行多次Concatnate操作,数据需要被复制多次,显存容易增加得很快,需要一定的显存优化技术。另外,DenseNet是一种更为特殊的网络,ResNet则相对一般化一些,因此ResNet的应用范国更广泛。
二、模型分析
1.VGGNet
1.1感受野与网络深度
首先是在学习VGGNet时,重新理解了什么是感受野和网络深度。
网络深度指的是神经网络的层数。
个人理解就是神经元在工作的时候,所关注图片的位置。
更深的网络能带来更大的感受野,而更大的感受野能带来更好的模型效果。
关于网络深度有三个特性:
1.输入图像的尺寸会限制模型可以选择的深度
2.卷积和池化的操作可以轻松快速的将特征图缩小
3.深度的增加会伴随训练的参数也在增加

由图片可知道,浅层的神经元关注的是一张图片的局部信息,随着池化层不断地缩小图片的尺寸,神经元所能关注图片的范围越来越大,在深层的神经元中,神经元已经可以完全关注中心,而模糊周围。其中位于图像中间的像素有更多可以影响最终特征图的路径,他们对最终特征图影响更大,对卷积的分类影响也更大。
1.2 VGGNet框架
vggnet是一种重复化架构卷积加持的神经网络模型,用多个小卷积核代替大的卷积核。
vggnet-16的架构:
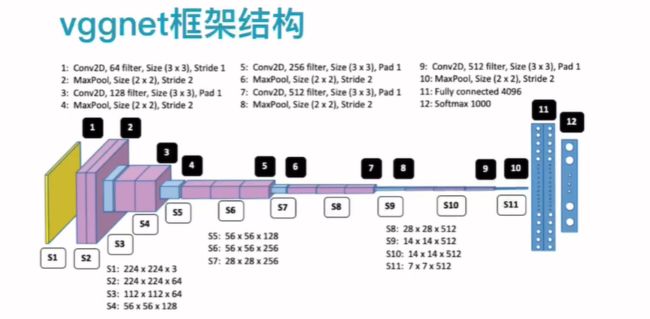
可以清晰的看出,在卷积的过程中,是用来双层卷积核,活着三层卷积核,然后用maxpool对图像进行缩小,最后用dropout,随机让神经元失效,防止过拟合。其中除了输出层外,所有的激活函数都是relu。
1.3VGGNet的优势
为什么使用多层小卷积核呢?明明层卷积核的感受野更大。
答案有两个:
1.小卷积核的所用的参数更少。
卷积核用到的参数量:(size^2×channel+noise)×filter
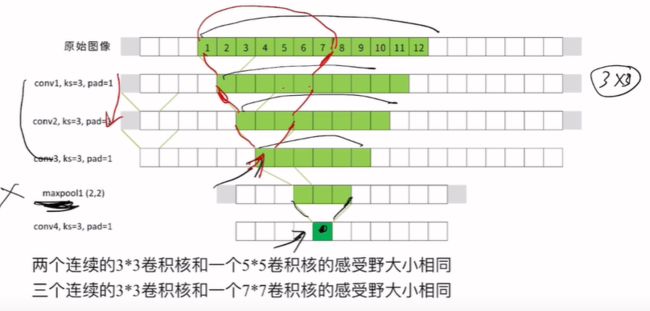
在上图中,从原始图片的1到7位置中,用3层3×3的卷积核卷积3次之后得到的结果和一层7×7的卷积核的效果是一样的。(3×3×3=27) < (7×7=49),所以在在保证具有相同感知野的条件下,提升了网络的深度,在一定程度上提升了神经网络的效果。
2.能提取更角度的特征值
相比于单层的卷积层,多层的卷积核能从多个角度提取不同的特征,使得最终的特征图更加全面。
1.4VGGNet的不足
虽然在卷积核上减少了参数的数量,但是参数的量依然十分庞大;在进行反向传播时,中间的卷积层可能会导致占用更多的内存。
2.GoogleNet
2.1Google框架

特点:1.添加两个辅助分类器帮助训练
2.丢弃全连接层,而使用平均池化层,这大大的减少了模型参数
下面是每层结构的参数量:

在上图的params一列可见,虽然参数量在不断上涨,但相对于VGGNet的1亿多个,这个数量已经少太多了。至于为什么会这样,一切得益于Google 团队的奇思妙想,提出了inception模型。
2.2 inception模型
由于其他模型的卷积核大小单一,信息提取也比较受限,所以Google团队提出了用大小不一的卷积核采取并联的方式,对图像进行特征提取。
inception初始版本:
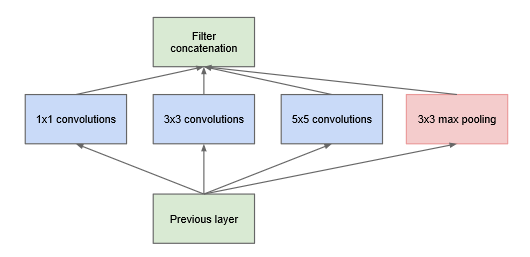
分别用1×1,3×3,5×5的卷积核和3×3的池化层对图像进行特征提取,的确解决了信息提取单一的问题,但这个模型被做实现之后,发现其参数远比VGGNet的1.3亿还要大,于是不得不另谋出路。
inception 改进版本:
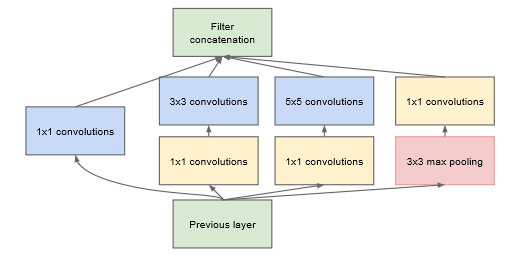
在原基础上加入了1×1的卷积核,其作用是在不减少上一层提取到的特征量的情况下,减少进入下一层的通道数。
这是因为,卷积核当前层特征的提取希望越多越好,但是下一层的输入希望越少越好,所以在卷积核参数的计算中(size^2×channel+noise)×filter产生了矛盾之处,接受的channel需要小才能让参数少,但filter大才能为下一层提供更多的特征。
所以1×1的卷积核被提出来了,我理解1×1的卷积核就像一个漏斗,就是把大的输入挤成小的输出,在保持量不变的情况下,改变了下一层输入channel的大小。这无疑是一个伟大的想法。
1.3VGGNet的优势
一:同时使用多种卷积核可以确保各种类型和层次的信息都被提取出来
二:并联的卷积池化层计算效率更高。
三:大量使用1×1卷积核实现了大规模降低参数,让特征图的数量实现了前所未有的
增长。拉开了1×1卷积广泛应用序幕
四:使用全局平均池化(GAP)代替全连接层,解決了全连接层参数过于巨大的问题
五:使用辅助分类器,实现了集成两个浅层网络和一个深层网络的结果来进行预判
3.ResNet
3.1 ResNet提出的必要性
对于前面学习的卷积模型,已经能很好从处理图像特征提取的问题,但是网络能达到的最大深度依然很浅,VGG是19层,GoogleNet也没有突破25层,所以在理论上cnn还可以通过加深网络层数以更好的提取特征,训练网络。
但是事实并非如此,主要有两大难点:
1.深度网络往往收敛困难,损失很高,往往面临梯度爆炸,活着梯度消失的问题。(但可以被正则化控制)
2.退化现象:深度网络实际上比浅层网络精度更低,效果更差。
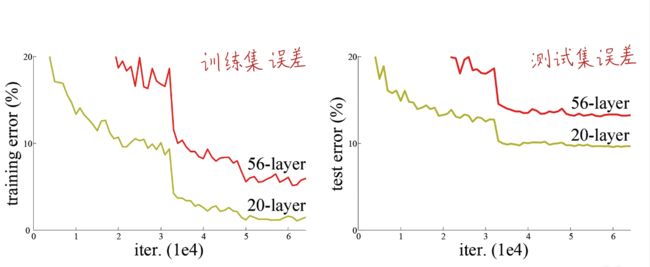
无论是训练集的错误率还是测试集的错误率都比浅层的差。
这里可以用一个例子解释,这就好比一个报了补习班的孩子(强行堆积卷经层),考不过一个没报补习班的孩子(浅层神经网络),其原因是补习班的教学习方法改变了原来老师教的学习内容。
于是提出了残差机构(真tm聪明)
3.2 残差结构
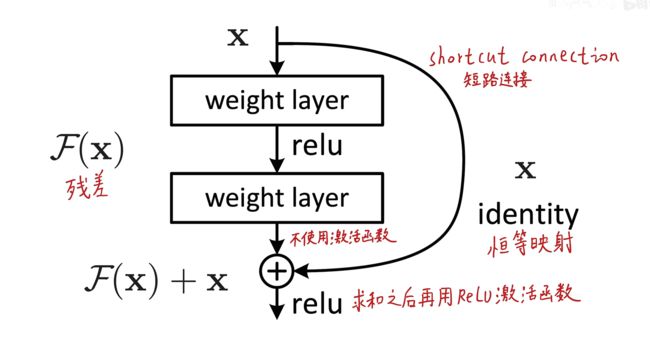
在残差结构中引入了残差和恒等映射两个概念。
也就是在原图像的基础上,通过恒等映射把原来输入给了输出,然后再通过两层普通卷积核对输入进行了偏移修改后再给输出,也就是有两个输出了。一句话说完:输出=输入+残差。
比喻:报了补习班的孩子不仅掌握了原来老师教的知识,还在不改变原来知识的情况下,学习了其他的知识。这样就保证了至少不会比没报补习班的孩子差,最差最差也和他们一样保留了原来的知识。
残差块的优点:
1.首先,跳跃连接不带有任何参数,普通卷积层的结构也不复杂,因此残差块的增加不会给模型带来太多额外的参数负担。同时,由于残差单元比普通网络更容易训练,并且在理论上能够保持网路的精度,因此残差网络的深度可以大幅增加,令整体架构自由享受加深深度所带来的福利。
2.在进行参数初始化时,我们常常使用0初始化。如果恒等函数就是最优的加深网络深度的结构,那许多残差单元在初始化时就被设置在了自己的最优结果上。对于残差块来说,最优状況下,训练的部分输出的结果应该非常接近0. 因此即便卷积层还没有经过训练 我们直接将原始的通过跳跃连接传递到下一层,对下层而言应该也是介不错的输入。因此在残差单元中,信息的传递速度会异常快速。因为卷积层接近于恒等函数,在对残差网络进行反向传播时,梯度也可以更快速地通过跳跃链接从后往前传递。
3.3 ResNet结构
ResNet结构是借鉴了VGGNet的双层卷积核的思想,将其运用到残差块中。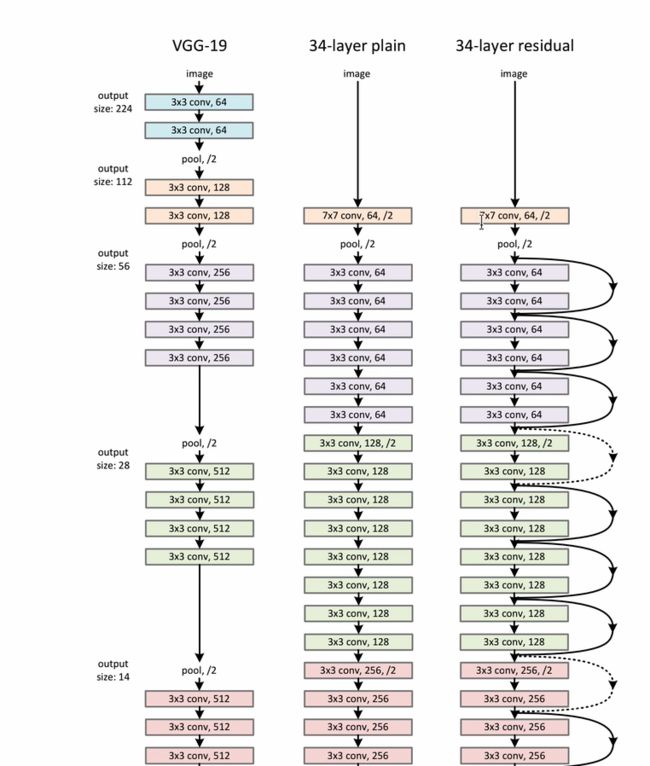
但残差块的设计很好的解决了由于卷积增多,导致梯度相关性成指数级别下降的难题,所以残差的连接可以极大地保留梯度的空间结构,从此解放了深层神经网络。
三、Tensorflow学习
以前都是从底层代码直接实现函数使用,损失函数,梯度下降等,在Tensorflow中直接有现成的库可以调用,实在太方便了。
非线性回归学习:
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
tf.compat.v1.disable_eager_execution()
x_data = np.linspace(-0.5,0.5,200)[:,np.newaxis]
noise = np.random.normal(0,0.02,x_data.shape)
y_data = np.square(x_data) + noise
x = tf.compat.v1.placeholder(tf.float32,[None,1])
y = tf.compat.v1.placeholder(tf.float32,[None,1])
weights_L1 = tf.Variable(tf.compat.v1.random_normal([1,10]))
biases_L1 = tf.Variable(tf.zeros([1,10]))
Wx_plus_b_L1 = tf.matmul(x,weights_L1) + biases_L1
L1 = tf.nn.tanh(Wx_plus_b_L1)
weights_L2 = tf.Variable(tf.compat.v1.random_normal([10,1]))
biases_L2 = tf.Variable(tf.zeros([1,1]))
Wx_plus_b_L2 = tf.matmul(L1,weights_L2) + biases_L2
prediction = tf.nn.tanh(Wx_plus_b_L2)
loss = tf.reduce_mean(tf.square(y-prediction))
train_step = tf.compat.v1.train.GradientDescentOptimizer(0.1).minimize(loss)
with tf.compat.v1.Session() as sess:
sess.run(tf.compat.v1.global_variables_initializer())
for _ in range(201):
sess.run(train_step,feed_dict={x:x_data,y:y_data})
prediction_value = sess.run(prediction,feed_dict={x:x_data})
plt.figure()
plt.scatter(x_data,y_data)
plt.plot(x_data,prediction_value,'r-',lw=5)
plt.show()
总结
本周学习了三大经典模型VGGNet,GoogleNet,和ResNet,同时也对ResNet的进一步改进模型DenseNet进行了学习。VGGNet模型从双层乃至多层的卷积层提出了创新;GoogleNet模型从inception(并联多个不同大小的卷积核)处提出了创新;ResNet模型从残差机构(保留原来的,增加优化的)提出了创新,学术大神天马行空的想法真让人耳目一新,醍醐灌顶。tensorflow还没有学完,下周会继续学习。