2022.11.13 第8次周报
目录
- 摘要
- 经典卷积神经网络学习
-
- VGGNets
- GoogleNet
- ResNEts
- 区别
- 阅读文献
-
- 亮点
- 内容介绍
- 可解释的深度学习方法
-
- 基于归因的方法
- 基于非归因的方法
- 通过模型压缩和加速实现高效的深度学习
- 深度学习中的鲁棒性和稳定性
- 小结
- 总结
摘要
This week, I learnt three classical convolutional neural networks and briefly analysed the differences between the five classical neural networks I learnt in the two weeks. In addition, I read a paper on interpretable deep learning this week, in which I learned about CAM, Grad-CAM, Monte Carlo methods, and learned about the importance of interpretability in deep learning.
本周学习了3个经典卷积神经网络,简要分析了这两周学习的5个经典神经网络的区别。另外,本周阅读了一篇有关可解释性深度学习的论文,在文章中学习了CAM、Grad-CAM、蒙特卡洛方法等知识,了解了深度学习可解释性的重要性。
经典卷积神经网络学习
VGGNets
VGGNet模型有A-E五种结构网络,深度分别为11,11,13,16,19,其中VGG16和VGG19较为典型。VGG网络结构如下图所示。

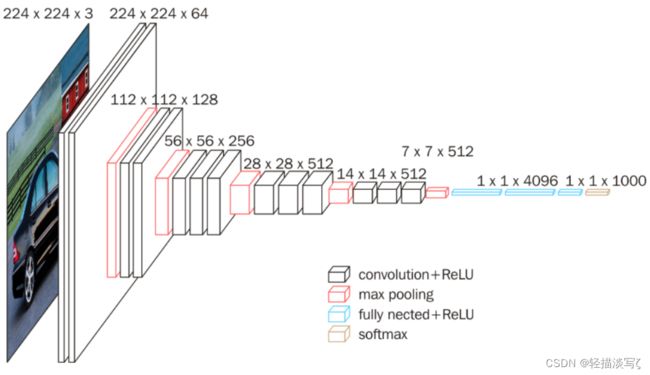
具体为:
-
卷积-卷积-池化-卷积-卷积-池化-卷积-卷积-卷积-池化-卷积-卷积-卷积-池化-卷积-卷积-卷积-池化-全连接-全连接-全连接 。
-
通道数分别为64,128,512,512,512,4096,4096,1000。卷积层通道数翻倍,直到512时不再增加。通道数的增加,使更多的信息被提取出来。全连接的4096是经验值,当然也可以是别的数,但是不要小于最后的类别。1000表示要分类的类别数。
-
所有的激活单元都是Relu 。
-
用池化层作为分界,VGG16共有6个块结构,每个块结构中的通道数相同。因为卷积层和全连接层都有权重系数,也被称为权重层,其中卷积层13层,全连接3层,池化层不涉及权重。所以共有13+3=16权重层。
-
对于VGG16卷积神经网络而言,其13层卷积层和5层池化层负责进行特征的提取,最后的3层全连接层负责完成分类任务。
GoogleNet
- 引入了Inception结构(融合不同尺度的特征信息)
- 使用1x1的卷积核进行降维以及映射处理
- 添加两个辅助分类器帮助训练
- 丢弃全连接层,使用平均池化层(大大减少模型参数)
左图是论文inception原始结构,右图是inception加上降维功能的结构:
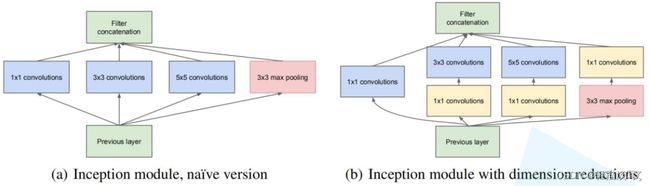
先看左图,inception结构一共有4个分支,也就是说我们的输入的特征矩阵并行的通过这四个分支得到四个输出,然后在将这四个输出在深度维度(channel维度)进行拼接得到我们的最终输出(注意,为了让四个分支的输出能够在深度方向进行拼接,必须保证四个分支输出的特征矩阵高度和宽度都相同)。
分支1是卷积核大小为1x1的卷积层,stride=1,
分支2是卷积核大小为3x3的卷积层,stride=1,padding=1(保证输出特征矩阵的高和宽和输入特征矩阵相等),
分支3是卷积核大小为5x5的卷积层,stride=1,padding=2(保证输出特征矩阵的高和宽和输入特征矩阵相等),
分支4是池化核大小为3x3的最大池化下采样,stride=1,padding=1(保证输出特征矩阵的高和宽和输入特征矩阵相等)
再看右图,对比左图,就是在分支2,3,4上加入了卷积核大小为1x1的卷积层,目的是为了降维,减少模型训练参数,减少计算量。
从右图可以看到有多个黄色的1x1卷积模块,这样的卷积有什么用处呢?
1、在相同尺寸的感受野中叠加更多的卷积,能提取到更丰富的特征。
2、使用1x1卷积进行降维,降低了计算复杂度。
ResNEts
- 提出residual结构(残差结构),并搭建超深的网络结构(突破1000层)
- 使用Batch Normalization加速训练(丢弃dropout)
下图是使用residual结构的卷积网络,可以看到随着网络的不断加深,效果并没有变差,反而变的更好了。

残差(residual)指的是什么?
下图是两种残差结构。左边的残差结构是针对层数较少网络,例如ResNet18层和ResNet34层网络。右边是针对网络层数较多的网络,例如ResNet101,ResNet152等。为什么深层网络要使用右侧的残差结构呢?因为,右侧的残差结构能够减少网络参数与运算量。同样输入一个channel为256的特征矩阵,如果使用左侧的残差结构需要大约1170648个参数,但如果使用右侧的残差结构只需要69632个参数。明显搭建深层网络时,使用右侧的残差结构更合适。
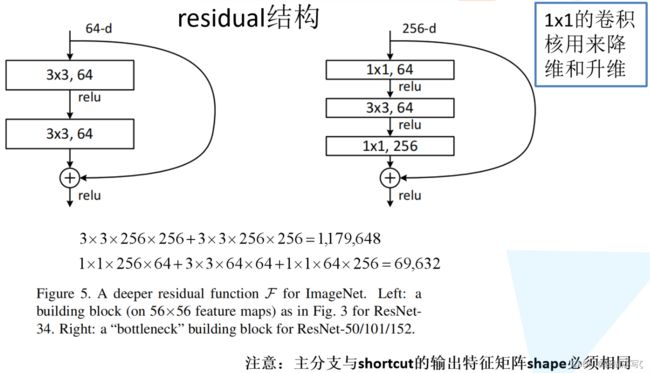
区别
AlexNet本质上就是扩展 LeNet 的深度,并应用一些 ReLU、Dropout 等技巧。与 Inception 同年提出的优秀网络还有 VGG-Net,它相比于 AlexNet 有更小的卷积核和更深的层级。
VGG-Net的泛化性能非常好,常用于图像特征的抽、目标检测候选框生成等,最大的问题就在于参数数量。
GoogLeNet最大的特点就是使用了 Inception 模块,它的目的是对输入图像并行地执行多个卷积运算或池化操作,并将所有输出结果拼接为一个非常深的特征图。与VGGNet模型相比较,GoogleNet模型的网络深度已经达到了22层(有参数的层),而且在网络架构中引入了Inception单元,从而进一步提升模型整体的性能。虽然深度达到了22层,但大小却比AlexNet和VGG小很多,GoogleNet参数为500万个( 5M ),VGG16参数是138M,是GoogleNet的27倍多,而VGG16参数量则是AlexNet的两倍多。
ResNet在网络结构上做了大创新,而不再是简单的堆积层数,主要解决了在深度网络中的退化的问题。通过使用Residual Unit成功训练152层深的神经网络,top-5错误率为3.57%,同时参数量却比VGGNet低很多。
阅读文献
论文:Explainable deep learning for efficient and robust pattern recognition: A survey of recent developments
地址:https://www.sciencedirect.com/science/article/pii/S0031320321002892
亮点
- 详细介绍了用于高效和稳健模式识别的可解释深度学习。
- 对深度神经网络的可解释方法,包括可视化和不确定性估计,进行了分类和介绍。
- 对高效深度学习的模型压缩和加速方法进行了回顾。
- 涵盖了与鲁棒性深度学习相关的两个主要话题,即对抗性鲁棒性和训练神经网络的稳定性。
- 可解释的深度学习用于高效和稳健的模式识别特刊所接受的论文显示了最近的进展并促进了进一步的研究。
内容介绍
最近,深度学习在许多视觉识别任务中取得了巨大成功。然而,深度神经网络(DNNs)往往被认为是黑箱,使得它们的决定不容易被人类理解,并禁止它们在安全关键的应用中使用。这篇文章主要分为三个类别:可解释的深度学习方法,通过模型压缩和加速的高效深度学习,以及深度学习的稳健性和稳定性。
可解释的深度学习方法
目前大部分的解释方法都集中在将DNN的预测归因于它的输入特征。这种基于归因的方法涵盖了计算机视觉中的大多数可视化方法,它们通过定位对决策贡献最大的区域,直接在输入图像领域给出解释。此外,许多其他非归因的方法在概念、训练数据、内在的注意机制等方面提供解释。
基于归因的方法
基于传播的方法: 利用推理或反向传播过程中的信息流来生成可视化解释。基于传播的方法囊括了基于响应和基于梯度(反向传播)的方法,它们分别在推理过程和反向传播过程中使用特征图。一个有代表性的基于反应的可视化方法是类激活图(CAM),像热图一样(如下图所示),CAM被叠加在输入图像上,以直观地解释图像中的哪些区域对特定类别的网络预测贡献最大。一个缺点是,CAM只能应用于分类网络,在全连接层之前的特征图上直接应用全局平均池化。

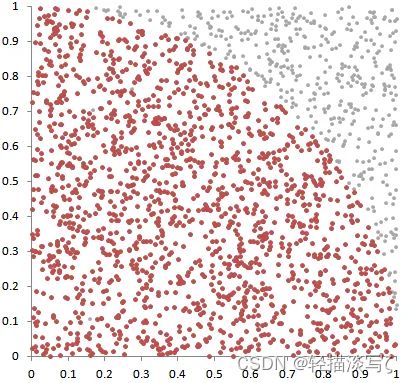
基于扰动的方法: 与传播型方法(主要是从输出到输入)不同,扰动型方法选择改变输入,通过比较扰动前后的输出产生解释。从形式上看,一个解释可以被定义为一个元预测器,一个预测黑盒网络的输出到特定输入的规则。解释的随机输入取样通过蒙特卡洛抽样给出了另一种扰动,输入图像的元素与各种随机掩码相乘,并送入分类网络以获得输出分数。
蒙特卡洛方法计算“Π”:Pi = 4 × 阴影内的样本点数量 ÷ 总数量
其他基于归因的方法: Ablation-CAM将作为Grad-CAM中梯度的 "斜率 "定义为特定激活神经元停用时输出分数的相对下降。Score-CAM使用输入图像的激活作为掩码,对输入图像本身产生扰动。信心的增加 "被定义为被扰动图像的激活图与基线激活之间的差异,它作为一个重要的指标,取代了Grad-CAM中的梯度。这种可视化方法弥补了基于扰动和基于传播的方法之间的差距,并提供了更清晰的视觉解释。
基于非归因的方法
概念激活向量(CAV)被认为是超平面的法线,该超平面将某一概念的例子和其他随机例子在层的激活中分开。由于TCAV在人类定义的概念层面上解释了最终的决定,它对人类来说更容易理解。
通过模型压缩和加速实现高效的深度学习
深度神经网络在各种任务中取得了最高的精度,但却牺牲了许多参数,需要大量的计算资源和训练时间。因此,在部署到资源有限的设备和实时应用之前,对模型压缩和加速技术有巨大需求。大多数方法可以分为以下几类:参数修剪、网络量化、低秩因子化、模型蒸馏和紧凑型网络设计。
深度学习中的鲁棒性和稳定性
稳健性揭示了模型在数据噪声下提供可靠决策的能力。最热门的话题是对抗性鲁棒性,因为它与应用中的安全问题密切相关。稳定性是深度神经网络的另一个关键问题,它决定了一个网络是否成功收敛。
鲁棒性: 也就是健壮和强壮的意思。它也是在异常和危险情况下系统生存的能力。虽然深度神经网络在精度上取得了显著的进步,但安全和保障问题在应用中也是非常重要的,深度神经网络很容易受到输入数据上的小扰动的影响,这些扰动大多是人眼无法感知的,因此,就需要解决这些小的扰动带来的不可控的影响。
稳定性: 在深度神经网络取得显著成绩的同时,一些深度网络,如生成式对抗网络,存在不稳定的问题,使其难以训练,有一些技术可以处理深度神经网络优化的稳定性问题。例如:批量规范化(BN)可以解决训练问题,提高深度网络的训练稳定性。
小结
这篇文章全面回顾了用于高效和稳健模式识别的可解释深度学习的代表性工作和最新进展,提供了在提高深度学习方法的可解释性、在特定模式识别问题中设计紧凑高效的网络架构、设计新型对抗性攻击和研究训练稳定性方面的最新进展。
总结
这两周学习了5个经典卷积神经网络,并将这些经典神经网络做了简单的对比,简要分析了它们之间的大致区别。下周,我将学习tensorflow2.0中keras模块,并进入RNN的学习。