Mlp-Mixer 阅读笔记
本文会做对文章的解读,以及和卷积的一些对比
- 论文链接: https://arxiv.org/pdf/2105.05537.pdf
- 代码:GitHub - google-research/vision_transformer
摘要
Mlp-mixer是谷歌最近提出的基于纯mlp结构的cv框架。它使用多层感知机(MLP)来代替传统CNN中的卷积操作(Conv)和Transformer中的自注意力机制(Self-Attention)。MLP-Mixer整体设计简单,在ImageNet上的表现接近于近年最新的几个SOTA模型,注意并没有超过。
介绍
CNN成为CV的de-facto standard,但最近Vision Transformers (ViT),基于Self atttention 成为了一个可选项,达到了新的SOTA性能。
我们提出了MLP-Mixer,based entirely on multi-layer perceptrons (MLPs) that are repeatedly applied across either spatial locations 空间位置 or feature channels 特征通道。(听起来很类似深度可分离卷积:包括 Depthwise卷积与Pointwise卷积)
Mixer relies only on basic matrix multiplication routines, changes to data layout (reshapes and transpositions), and scalar nonlinearities.仅依赖于基本的矩阵乘法例程, 数据布局(reshape和转置)以及标量非线性。
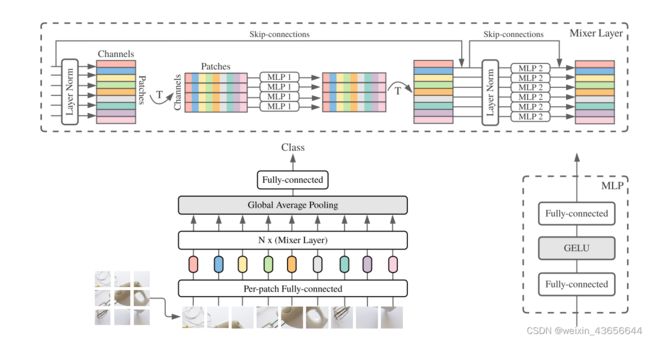
图一是整个结构:
- 首先进行“Per-patch Fully-connected”,即embedding。输入a sequence of linearly projected image patches,然后将其映射为 (also referred to as tokens) 大小为“patches × channels” , 然后一直保持this dimensionality. 比方说有9个32x32x3的patch,全连接映射到9个128维度的token。
- 然后进入mixer- layer。一共有两种MLP层:
这两个结合起来类似深度可分离卷积,但是表达能力没有深度可分离卷积强。
深度可分离卷积把传统卷积分成逐点卷积(point-wise)和逐通道卷积(depth-wise),逐点卷积采用1x1的卷积核,改变了特征映射的通道数;然后逐通道卷积不同于传统卷积,对每个通道单独卷积,结果只改变图像分辨率不改变通道数。
token-mixing MLPs:允许不同空间位置之间的交流。类似depth-wise卷积,对所有token的相同通道进行混合。但token-mixing对不同通道都共享权重。而depth-wise卷积不同通道的卷积核参数都不一样,所以说表达能力没有深度可分离卷积强;
channel-mixing MLPs:允许不同channels特征之间的交流。类似point-wise卷积,对同一个token的不同通道进行混合,其实就是用了patch_size的卷积核(比较大),并在不同token之间共享权重;
与Per-patch Fully-connected相同,MLP1和MLP2在不同列、行中的映射过程中共享权重。除此之外,Mixer Layer还加入了LN和跳接来提高模型性能。
- 这个矩阵先经过LayerNorm,对每个token的所有通道,即C这个维度上求均值和方差,然后归一化;(每个颜色的横条代表一个token)
- 然后矩阵经过转置,变成CxS的样式;
- 经过第一个全联接层,MLP1是token-mixing,对相同通道的不同token进行空间上的混合(此处输入是对位置敏感的,所以不需要transformer的位置嵌入);
- 然后再转置成SxC,与原始输入x进行跨层直连得到x2, 再进行layer norm;
- 然后MLP2,channel-mixing,对相同Token的不同通道进行混合计算; 与x2跨层直连,得到SxC的最终输出
此外,MLP 都有下面的结构
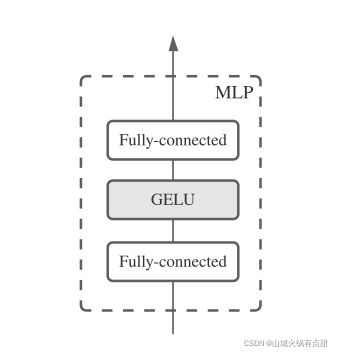
GELU激活函数即高斯误差单元(Gaussian Error Linear Unit),它是dropout、zoneout、relu属性的混合。其中relu对输入确定性的乘0或1;而dropout依概率对输出乘0;zoneout用于rnn中,依概率对上一个cell输出状态乘1,即随机失活这个cell,把上一个cell的状态向量跨cell直接输出到下一个cell。

3. classfier head,包括一个GAP和FC
单层全连接,输入是SxC经全局平均池化(对各个channel求平均)后C维的向量,输出是num_classes维。
详细解释一下 MLP-Mixer 的几个结构到底和卷积如何对应
从原则上来说,卷积和全连接层可以按照如下的方式互相转化:
- 如果卷积核的尺寸大到包含了所有输入,以至于无法在输入上滑动,那么卷积就变成了全连接层。
- 反过来,如果全连接层足够稀疏,后一层的每个神经元只跟前一层对应位置附近的少数几个神经元连接,并且这些连接的权重在不同的空间位置都相同,那么全连接层也就变成了卷积层。
在 MLP-Mixer 中,主要有三个地方用到了全连接层,而这些操作全部可以用卷积实现,方法如下:
第一步是Per-patch Fully-connected。我们要把输入切分成若干 16x16 的 patch,然后对每个 patch 使用相同的投影。
最简单的实现/官方实现就是采用 16x16 的卷积核,然后 stride 也取 16x16,计算二维卷积。
等同于,全连接层:首先把每个 16x16 的 patch 中的像素通过 permute/reshape 等操作放在最后一维得到 x_mlp,然后再做一层线性变换。
import torch
import torch.nn.functional as F
# i) non-overlapping patch projection
batch_size, height, width, in_channels = 32, 224, 224, 3
out_channels, patch_size = 8, 16
x = torch.randn(batch_size, in_channels, height, width)
w1 = torch.randn(out_channels, in_channels, patch_size, patch_size)
b1 = torch.randn(out_channels)
conv_out1 = F.conv2d(x, w1, b1, stride=(patch_size, patch_size))
#torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1)
#torch.nn.functional.conv2d(input(batch,inchannel,H,W), weight-filters of shape
#(out_channel,inchannel/groups,fH,fW), bias:shape as outchannel, stride=single number/a tuple)
#所以实际上就是 nn.Conv2d(3, 8, kernel_size=(16, 16),stride=(16, 16)) 应用在 (224, 224, 3)的tensor上
print(conv_out1.size()) # [batch_size, out_channels, num_patches_per_column, num_patches_per_row]
x_mlp = x.view(batch_size, in_channels, height // patch_size, patch_size, width // patch_size, patch_size).\
permute(0, 2, 4, 1, 3, 5).reshape(batch_size, -1, in_channels * patch_size ** 2)
mlp_out1 = x_mlp @ w1.view(out_channels, -1).T + b1
print(mlp_out1.size()) # [batch_size, num_patches, out_channels]
print(torch.allclose(conv_out1.view(-1), mlp_out1.transpose(1, 2).reshape(-1), atol=1e-4))
可以看到,在对结果进行重新排列后(这一步繁琐但是意义不大,不展开讲了),conv_out1 和 mlp_out1 是相同的。
torch.Size([32, 8, 14, 14])
torch.Size([32, 196, 8])
True
第二步是token-mixing MLPs,对同一通道内不同位置的像素信息进行整合。
如果用 MLP 来实现,就是把同一个通道的像素值都放到最后一维,然后接一个线性变换即可
如果用卷积来实现,实质上是一个 depthwise conv,并且各个通道/深度要共享参数(因为每个通道都要按相同的方式整合不同位置的信息)。这就是 F.conv2d 的卷积核里 w2 和 b2 进行 repeat 的原因。
# ii) cross-location/token-mixing step
in_channels = out_channels # Use previous outputs as current inputs
out_hidden_dim = 7 # `C` in the paper
x = torch.randn(batch_size, in_channels, height // patch_size, width // patch_size)
# (32,8,14,14)
w2 = torch.randn(out_hidden_dim, 1, height // patch_size, width // patch_size)
# (7,1,14,14) 对输入多个channel只有一个卷积,即共享参数。且大小与featuremap相同,即为全连接
b2 = torch.randn(out_hidden_dim)
# This is a depthwise conv with shared parameters
conv_out2 = F.conv2d(x, w2.repeat(in_channels, 1, 1, 1), #在第1维上拼接,重复in_channels次
b2.repeat(in_channels), groups=in_channels)
print(conv_out2.size()) # [batch_size, in_channels * out_hidden_dim, 1, 1]
mlp_out2 = x.view(batch_size, in_channels, -1) @ w2.view(out_hidden_dim, -1).T + b2
print(mlp_out2.size()) # [batch_size, in_channels, out_hidden_dim], or [B, S, C] in the paper
print(torch.allclose(conv_out2.view(-1), mlp_out2.view(-1), atol=1e-4))
torch.Size([32, 56, 1, 1])
torch.Size([32, 8, 7])
True
第三步是channels-mixing MLPs,对同一位置内不同通道的像素信息进行整合。显然这个操作就是一个逐点卷积(pointwise/1x1 conv)。当然,也可以利用 permute 把相同位置不同通道的元素丢到最后一维去,然后统一做一个线性变换,如下
# iii) channel-mixing step
out_channels = 28
x = torch.randn(batch_size, in_channels, height // patch_size, width // patch_size)
#(32,7,14,14)
w3 = torch.randn(out_channels, in_channels, 1, 1)
#(28,7,1,1)
b3 = torch.randn(out_channels)
# This is a pointwise conv
conv_out3 = F.conv2d(x, w3, b3)
print(conv_out3.size()) # [batch_size, out_channels, num_patches_per_column, num_patches_per_row]
mlp_out3 = x.permute(0, 2, 3, 1).reshape(-1, in_channels) @ w3.view(out_channels, -1).T + b3
print(mlp_out3.size()) # [batch_size * num_patches, out_channels], or [B*C, S] in the paper
print(torch.allclose(conv_out3.permute(0, 2, 3, 1).reshape(-1), mlp_out3.view(-1), atol=1e-4))
这里解释如何用 F.conv2d 实现 MLP-Mixer
因此,当 MLP-Mixer 对每个 patch 做相同的线性变换的时候,已经在用卷积了(这一点在 ViT 里同样成立)。因为卷积的本质是局部连接+参数共享,而划分 patch = 局部连接,对各个 patch 应用相同的线性变换 = 参数共享。只不过,它用的卷积核大一点儿而已,有一个 patch 那么大。
而 token-mixing 和 channel mixing ,实际就是把普通的卷积拆成了 depthwise conv with shared parameters 和 pointwise conv —— 在不考虑卷积核大小的情况下,这甚至比深度可分离卷积(depthwise separable conv)的表达能力还要弱: MLP-Mixer 里的 depthwise conv 在每个 depth/channel 上共享参数。于是,达不到 SOTA 也很好理解了。
Depthwise Separable Convolution
是将一个完整的卷积运算分解为两步进行,即Depthwise Convolution与Pointwise Convolution。其参数量和运算成本较低。所以在一些轻量级网络中会碰到这种结构
Depthwise Convolution(token-mixing MLPs)
不同于常规卷积操作,Depthwise Convolution的一个卷积核负责一个通道,一个通道只被一个卷积核卷积。上面所提到的常规卷积每个卷积核是同时操作输入图片的每个通道。Depthwise Convolution完成后的Feature map数量与输入层的通道数相同,无法扩展Feature map。而且这种运算对输入层的每个通道独立进行卷积运算,没有有效的利用不同通道在相同空间位置上的feature信息。因此需要Pointwise Convolution来将这些Feature map进行组合生成新的Feature map。
Pointwise Convolution(channels-mixing MLPs)
与常规卷积运算非常相似,它的卷积核的尺寸为 1×1×M,M为上一层的通道数。所以这里的卷积运算会将上一步的map在深度方向上进行加权组合,生成新的Feature map。有几个卷积核就有几个输出Feature map。如下图所示。

参考文献
Depthwise卷积与Pointwise卷积_干巴他爹的博客-CSDN博客_depthwise
如何评价Google提出的MLP-Mixer:只需要MLP就可以在ImageNet上达到SOTA?_初识-CV的博客-CSDN博客