CVPR2020_Cost Volume Pyramid Based Depth Inference for Multi-View Stereo
一、核心思想
1.以前算法的问题
内存消耗过高,或者增加了时间损耗。
MVSNet内存消耗是分辨率的三次方,PointMVSNet运行时间增长为迭代次数的线性倍,这篇文章对比的对象主要是PointMVSNet。
2.主要改进方向
加快运行速度
3.与PointMVSNet的不同
1.后者是在3D点云上执行卷积,而前者是在图像坐标上定义的规则网络上构建成本量,运行更快。
2.随着分辨率的提高,代价体变得越来越紧凑。
3.使用多尺度3D-CNN正则化从而覆盖大的感受野
4.可以用小分辨率图像输出小分辨率深度图
4.核心思想
直接把图像变成图像金字塔,上一层深度图的输出为下一层的深度残差构建提供参考。
二、算法框架
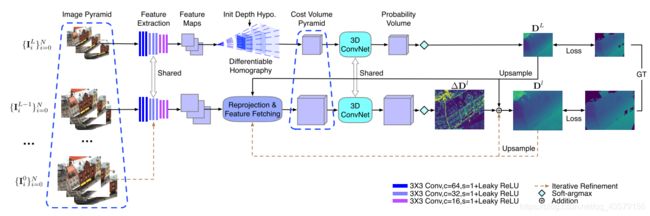
1. 算法概述
首先为每个输入图像构建一个图像金字塔。然后对于图像的最低分辨率,通过在场景的整个深度范围采样深度来构建成本量;在此基础上,在下一个金字塔级别,从当前深度估计的邻居执行残差深度搜索,使用3DCNN进行正则化构建部分成本量。
分析网络结构:首先把图像序列构建为图像序列的金字塔,最低分辨率这层的网络结构实际上就是MVSNet的网络结构。其余分辨率的图像金字塔,按照顺序,从小到大逐渐对深度图进行迭代。更高一层分辨率的构建特征图之后,利用上一层深度图,在其附近深度采样构建costvolume(reprojection&Feature Fetching),在此基础上对3DCNN回归得到深度残差图,融合后得到该层金字塔回归后的深度图。之后的迭代步骤与这个类似。
2.具体方法
①特征金字塔的构建
首先构建L+1层的图像金字塔,最底层代表原图。 I i 0 = I i I^0_i=I_i Ii0=Ii
接下来使用CNN在 l l l层得到特征表示。第 l l l层特征图表示为 ( f i l ) i = 0 N , f i l ∈ R H / 2 l ∗ W / 2 l ∗ F , F = 16 {(f_i^l)_{i=0}^N},f_i^l\in R^{H/2^l*W/2^l*F},F=16 (fil)i=0N,fil∈RH/2l∗W/2l∗F,F=16
这种特征提取方式由于都是权值共享的,减小了内存需求。
②代价体金字塔
构建代价体金字塔,通过迭代估计和改进深度图体实现高分辨率深度推理。
Cost Volume for Coarse Depth Map Inference
首先基于图像金字塔的最低分辨率图像和场景中垂直光轴的均匀采样,为低精度深度图估计构建代价体。

![]()
λ i \lambda_i λi代表了 x ~ i \tilde{x}_i x~i在源视角i上的深度值

这一步与MVSNet中完全相同,最终得到的代价体大小为
C L ∈ R W / 2 L ∗ H / 2 L ∗ M ∗ F C^L \in R^{W/2^L*H/2^L*M*F} CL∈RW/2L∗H/2L∗M∗F M代表深度采样间隔,F代表通道数,L代表当前位于金字塔的层数。
然后基于粗略估计和深度残差假设迭代构建部分成本量,从而实现具有更高分辨率和精度的深度图。
Cost Volume for Multi-scale Depth Residual Inference
为多尺度深度残差推导来构建代价体,这也是文章的核心部分。
从第 l + 1 l+1 l+1层到第 l l l层的深度推导。
D l = D ↑ l + 1 + Δ D D^{l}=D^{l+1}_{\uparrow}+\Delta D Dl=D↑l+1+ΔD其中 D ↑ l + 1 D^{l+1}_{\uparrow} D↑l+1代表 D l + 1 D^{l+1} Dl+1使用双三次插值算法上采样得到图像,需要估计的深度残差也就是 Δ D \Delta D ΔD
令深度残差假设间隔为 Δ d p = s p / M \Delta d_p=s_p/M Δdp=sp/M,其中 s p s_p sp代表了在p点搜索的范围,M代表采样数
故单应矩阵变成了

m ∈ ( − M / 2 , . . . , M / 2 − 1 ) m \in (-M/2,...,M/2-1) m∈(−M/2,...,M/2−1)
特征体的构建仍然使用的是基于方差的度量方法。
③深度图推导
这部分内容包括深度采样以及深度图估计
Depth Sampling for Cost Volume Pyramid
证明深度采样过于密集是没有必要的。

Depth Map Estimator
使用的方法是通过三维卷积把构造的代价体回归成概率体,最终仍然是通过argmax的方式得到深度图的。


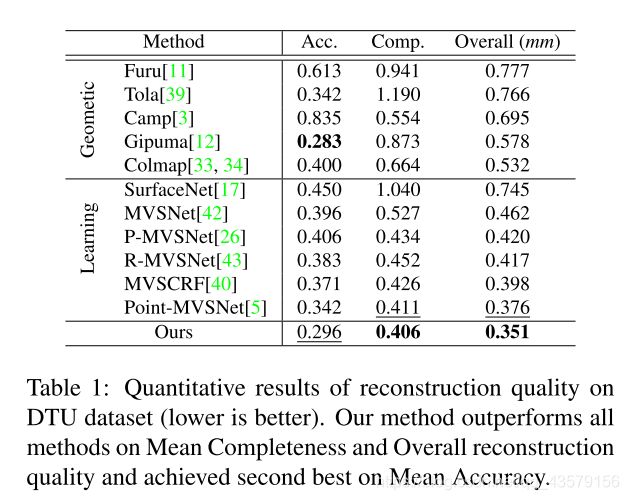
实验结果