【深度学习】语义分割-论文阅读:( NeurIPS 2021 )SegFormer
这里写目录标题
- 0.详情
- 1.动机
- 2. 改进点
- 3.相关工作
- 4. Method
-
- 4.1 Hierarchical Transformer Encoder
-
- 4.1.1 分层特性表示(Hierarchical Feature Representation)
- 4.1.2 重叠合并(Overlapped Patch Merging)
- 4.1.3 自注意机制(Efficient Self-Attention)
- 4.1.4 混合前馈网络(Mix-FFN)
- 4.2 Lightweight ALL-MLP Decoder
-
- 4.2.1 ALL-MLP解码结构
- 4.2.2 有效接受视野(Effective Receptive Field Analysis)
- 4.3 Relationship to SETR
- 5 实验
-
- 5.1 实验设置
0.详情
名称:SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers
单位:香港大学, 南京大学, NVIDIA, Caltech.
时间:Published 31 May 2021
论文:添加链接描述
代码:代码
笔记参考:
1.总结简介版
2.简介版
3.翻译版
1.动机
- ViT 在图像分类上的成功,催生了 SETR 网络,该网络说明了 Transformer 也能在分割任务上生效。
**SETR 使用 ViT 作为主干网络,然后使用 CNN 来进行特征图增大。**但是 ViT 有一些不足:
- SETR中使用VIT作为backbone 提取的特征较为单一,PE限制预测的多样性
- 传统CNN的Decoder来恢复特征过程较为复杂
- 基于此,有作者提出了 PVT,是 ViT 的变体,金字塔结构,能进行密集预测。PVT 的提出,超越了基于 CNN 的目标检测和语义分割。还有后续的 Swin 和 Twins,这些方法主要考虑设计 encoder,但忽略了 decoder 能带来的更多提升。
2. 改进点
本文提出了一种 SegFormer,同时考虑了效果、效率、鲁棒性,同时使用了 encoder 和 decoder,
主要提出多层次的Transformer-Encoder和MLP-Decoder,
创新性:
-
包含一个可以输出多尺度信息的transformer编码器(没有使用position embedding,避免了position插值)
-
避免了复杂的解码器。提出的MLP解码器从不同的层聚合信息,从而结合局部关注和全局关注来呈现强大的表示。作者展示了这种简单和轻量级的设计是有效分割transformer的关键。
(本文提出的 encoder,在对分辨率不同的输入进行 inference 的时候, 没使用插值的位置编码,所以,本文提出的 encoder 能够很简单的应用于不同分辨率的测试,也不会影响性能。并且分层级的部分能够产生高分辨率和低分辨率的特征
轻量级的 MLP decoder,能够很好的利用 Transformer 的特征,其中低层能保留局部信息,高层能保留非局部信息。将这些不同层的 MLP decoder 结合后,能够结合 local 和 global 特征,能够得到一个简单且直接的 decoder 来得到有效的特征表达。)
3.相关工作
语义分割:是一种图像分类从图像级别到像素级别上的扩展。FCN是这方面的开山之作,FCN是一种全连接卷积网络,用端到端的方式执行了像素级别的分类。在此之后,研究者集中在不同的方面来改进FCN,比如:
-
扩大感受野(deeplabv2、deeplabv3、deeplabv3+、PSPNet、DenseASPP、improve semantic segmentation by GCN、);
-
精炼上下文信息(Object Context Network for Scene parsing、Context prior for scene segmentation、Object-contextual representations for semantic segmentation、Context encoding for semantic segmentation、Context-reinforced semantic segmentation);
-
引入边界信息的(Boundary-aware feature propagation for scene segmentation. In ICCV, 2019;Improving semantic segmentation via decoupled body and edge supervision. arxiv, 2020;Model-agnostic boundary refinement for segmentation. In ECCV, 2020;Joint semantic segmentation and boundary detection using iterative pyramid contexts. In CVPR,2020;Gated-scnn: Gated shape cnns for semantic segmentation. In ICCV, 2019;)、
-
设计各种注意力模块的变体(Dual attention network for scene segmentation .In CVPR, 2019;Non-local neural networks. In CVPR,2018;Squeeze-and-attention networks for semantic segmentation. In CVPR,2020;Ccnet:Criss-cross attention for semantic segmentation. In ICCV, 2019;Pyramid attention network for semantic segmentation. arXiv,2018;Expectation-maximization attention networks for semantic segmentation.ICCV2019;Gcnet: Non-local networks meet squeeze-excitation networks and beyond. In ICCVW, 2019;Segmenting transparent object in the wild with transformer. IJCAI, 2021;)、
-
使用AutoML技术(Fast neural architecture search for faster semantic segmentation. In ICCVW, 2019;Fasterseg:Searching for faster real-time semantic segmentation. arXiv, 2019;Learning dynamic routing for semantic segmentation. In CVPR, 2020;Auto-deeplab: Hierarchical neural architecture search for semantic image segmentation. In CPVR, 2019;Fast neural architecture search of compact semantic segmentation models via auxiliary cells. In CVPR, 2019)。
以上提到的这些思路显著的提高了语义分割的性能,但是却引入了大量的经验模块,使得生成的框架计算量大且复杂。最近的这两篇文章(Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers. CVPR, 2021;Segmenting transparent object in the wild with transformer. IJCAI, 2021)证明了Transformer。但是这些模型还需要大量的计算。
Transformer backbones:VIT是证明纯Transformer在图像分类方面可以达到SOTA的文章。VIT将图像作用成带有序列的tokens,输入到多层Transformer层中进行分类。DeiT(End-to-End object detection with transformers. In ECCV, 2020)进一步探索了数据高效的培训策略和ViT的精馏方法。最近的一些文章T2T ViT, CPVT, TNT, CrossViT and LocalViT引入ViT的定制更改,进一步提高图像分类性能。
除了分类之外,PVT是在Transformer中引入金字塔结构的第一个作品,与CNN相比它展示了纯Transformer主干网在密集预测任务中的潜力。之后,使用Swin[9]、CvT[58]、CoaT[59]、LeViT[60]、孪生[10]增强了特征的局部连续性,消除了固定尺寸的位置嵌入,提高了transformer在密集预测任务中的性能。
4. Method
SegFormer有两个模块组组成:
1)一个分层的Transformer Encoder:产生高分辨率低级的feature和低分辨率的精细的feature。
2)一个轻量级的ALL-MLP decoder:融合不同层次的feature得到语义分割结果。
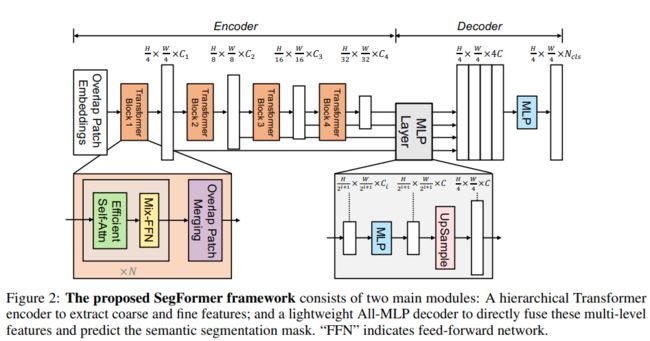

4.1 Hierarchical Transformer Encoder
作者设计了一系列的 Mix Transformer encoders (MiT),MiT-B0 到 MiT-B5,结构相同,大小不同,MiT-B0 是最轻量级的,可以用来快速推理,MiT-B5 是最重量级的,可以取得最好的效果。
MiT 灵感来源于 ViT,但为适应分割做了一些优化。
4.1.1 分层特性表示(Hierarchical Feature Representation)
ViT只能生成单分辨率的特征图,
该模块的目标:对给定输入图像生成类似cnn的多级特征。
意义:这些特征提供了高分辨率的粗特征和低分辨率的细粒度特征,通常可以提高语义分割的性能
输出:生成的特征图分辨率是原图的1/4 1/8 1/16 1/32。
![]()

4.1.2 重叠合并(Overlapped Patch Merging)
ViT的Patch Embedding是无重叠的(non-overlapping),但是non-overlapping对语义分割任务来说,会导致patch边缘不连续。MiT使用overlapped patch embedding,保证patch边缘连续。
VIT中将一个输入NN3的image,合并为11C的向量。利用这种特性,很容易的可以将特征图的分辨率缩小两倍,以获得分层特征映射。
使用此方法,可以将层次结构特性从H /4 × W /4 × C 1 缩小到H /8 × W /8 × C 2 ,然后迭代层次结构中的任何其他特性映射。这个过程最初的设计是为了结合不重叠的图像或特征块,但它不能保持这些斑块周围的局部连续性,所以作者使用有重叠的 patch merging 方法。
此我们设置的三个参数K,S,P。K是patch size,表示相邻两个patch之间的步幅,S是stride,P是padding。在实验中我们分别设K,S,P为(7,4,3)和(3,2,1)的参数来执行overlapping的图像的融合过程并得到和non-overlapping图像融合一样大小的feature。

4.1.3 自注意机制(Efficient Self-Attention)
Transformer的主要计算瓶颈在Attention层,设Q/K/V的维度为[N, C](N=H*W),注意力计算公式如下:

它的计算复杂度是O(N的平方),当对大分辨率的图片,计算量过大,segformer引入一个衰减比率R,利用全连接层减少Attention计算量。
K的维度为[N, C],先将其reshape为[N/R, C*R],通过全连接层将维度变为[N/R, C],那么计算复杂度变为O(NN方/R),从stage1到stage4,R分别设置为[64, 16, 4, 1]。

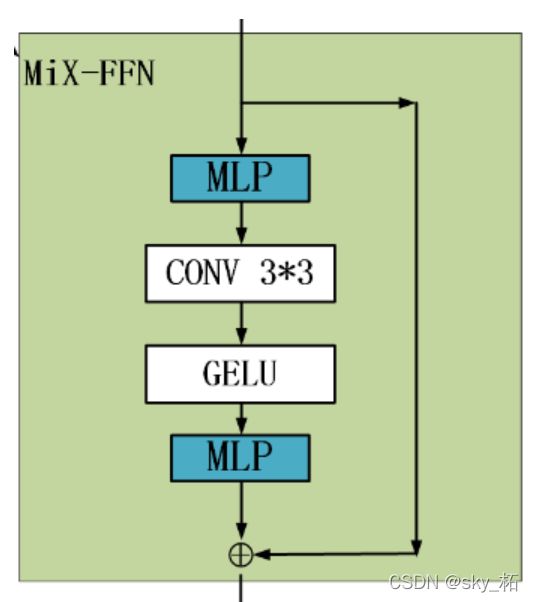
4.1.4 混合前馈网络(Mix-FFN)
问题:
ViT使用位置编码(PE)来引入位置信息。但是PE的分辨率是固定的。因此,当测试分辨率与训练分辨率不同时,位置代码需要插值,这通常会导致精度下降。
作者认为位置编码对于语义分割实际上是不必要的。
改进:
因此SegFormer引入Mix-FFN,它考虑了零填充对泄漏位置信息的影响,直接在前馈网络(FFN)中使用3×3 Conv。
Mix-FFN公式为:
![]()
其中X in是从self-attention中输出的feature。Mix-FFN将3×3卷积和MLP混合到每个FFN中。
过程:
MiX-FFN的顺序为:输入经过MLP,再使用Conv3*3操作,正在经过一个GELU激活函数,再通过MLP操作,最后将输出和原始输入值进行叠加操作,作为MiX-FFN的总输出。
实验证明3x3的卷积可以提供给transformer充分的位置信息。
4.2 Lightweight ALL-MLP Decoder
4.2.1 ALL-MLP解码结构
SegFormer集成了一个轻量级解码器,只包含MLP层。
使用这种简单编码器的关键点是作者提出的多级Transformer Encoder比传统的CNN Encoder可以获得更大的感受野。

ALL-MLP步骤:
第一,从MIT中提取到的多层次的feature,记作Fi,通过MLP层(linear层)统一通道维度。
第二,将特征图上采样为原图大小的 1/4 大小,做concat操作。
第三,使用一层 MLP(linear层) 对特征通道聚合
最后,另一个MLP(linear层)对融合的特征进行预测,输出分辨率为H/4W/4Ncls
整个decoder只有四部分一共6个linear层
没有dilate conv
没有3x3 conv.
所以参数非常少

4.2.2 有效接受视野(Effective Receptive Field Analysis)
对语义分割来说,保持较大的感受野以获取更多的上下文信息一直是一个核心问题。
首先对于CNN encoder来说,有效感受野是比较小且局部的,所以需要一些decoder 的设计来增大有效感受野;
但是对于Transformer encoder来说,**由于 self-attention存在,segformer encoder阶段感受野就足够大了,**因此decoder 不需要更多操作来提高感受野(作者试了一堆分割头,基本没有提升),
使用有效感受野ERF作为一个可视化和解决的工具来说明为什么MLPdecoder表现是非常有效的在Transformer上。
图三所示,对比deeplabv3+和SegFormer的四个解码器阶段和编码器头的部分的可视化图,
得出结论:DeepLabV3+的感受野远小于SegFormer;

- Deeplabv3+ 的 ERF 在每个 stage 都小
- SegFormer 的 encoder 在较低 stage 产生类似于卷积的局部注意,同时也能够在 stage 4 输出非局部的注意,能够有效捕获上下文
- MLP head 的 ERF (蓝框)不同于 stage 4 的红框,蓝框除了 non-local 的attention外,还有更强的局部attention。
CNN的接受域有限,需要借助语境模块扩大接受域,但不可避免地使网络变复杂。
All-MLP译码器设计得益于transformer中的非局部注意力,并在不复杂的情况下导致更大的接受域。
然而,同样的译码器设计在CNN主干上并不能很好地工作,因为整体的接受域是在Stage4的有限域的上限。
更重要的是,All-MLP译码器设计本质上利用了Transformer诱导的特性,同时产生高度局部和非局部关注。通过统一它们,All-MLP译码器通过添加一些参数来呈现互补和强大的表示。这是推动我们设计的另一个关键原因。
所以,MLP 形式的 decoder 能在 Transformer 网络中发挥比 CNN 中更好的作用的原因在于感受野
4.3 Relationship to SETR
与SETR相比,SegFormer含有多个更有效和强大的设计。
- SegFormer只在imageNet-1K上做了预训练,SETR中的ViT在更大的imageNet-22K做了预训练。
- SegFormer的多层编码结构要比ViT的更小,并且能同时处理高分辨率的粗特征和低分辨率的精细特征,相比
SETR的ViT只能生成单一的低分辨率特征。 - SegFormer中去掉了位置编码,所以在test时输入image的分辨率和train阶段分辨率不一致时也可以得到较好的精度,但是ViT采用固定的位置编码,这会导致当test阶段的输入分辨率不同时,会降低精度。
- SegFormer中decoder的计算开销更小更紧凑,而SETR中的decoder需要更多的3*3卷积。
5 实验
5.1 实验设置
Dataset:三个公开数据集:Cityscapes、ADE20K、COCO-Stuff。
储备知识:FLOPS:注意全大写,是floating point operations per second的缩写,意指每秒浮点运算次数,理解为计算速度。是一个衡量硬件性能的指标。
FLOPs:注意s小写,是floating point operations的缩写(s表复数),意指浮点运算数,理解为计算量。可以用来衡量算法/模型的复杂度。在下面对比实验中提到的即为该参数。反映模型浮点运算数。