【Python】数据分析 聚类分析-RFM模型-KMeans聚类
K-Means聚类:
中心思想是不断调整中心点来计算聚类,生成新的中心点,直到达到平衡为止。
随机选取K个中心点,计算其他点到中心点的位置,并选择最近的归类,重复该过程,直到中心点不再变化。服从高斯(正态)分布。
优点:
- 只有需要调整一个参数k
- 操作简单
- 可解释性高
缺点:
- 受异常值影响,如离群点
- k值先验,很难确定
- 两个类别距离较近,效果不会太好
- 初始值对结果影响大,可能每次结果不一样
- 可能是局部最优,而不是全局最优
RFM模型:
最近一次消費(Recency)
消費頻率(Frequency)
消費金額(Monetary)

图片来源:https://blog.csdn.net/lll1528238733/article/details/75115999
Python实现过程
数据探索→数据选择→数据清洗→数据整理→数据转换→K-Means聚类→聚类结果绘图→客户价值分析
data数据源样式:
数据探索
#对数据进行基本的探索
#返回缺失值个数以及最大最小值
import pandas as pd
import numpy as np
data = pd.read_excel(r'C:\Users\Susu\Desktop\data.xls',encodig = 'utf-8')
data = data[['支付时间','用户名称','支付金额','数据采集时间']]
# T为转置,describe自动计算非空值
view = data.describe(percentiles=[],include='all').T
#查看空值,最大值,最小值
view['null'] = len(data)-view['count']
view = view[['null','max','min']]
#表头重命名
view.columns = [u'空值数',u'最大值',u'最小值']
#导出结果
view.to_excel(r'C:\Users\Susu\Desktop\data_new.xlsx')
数据选择
数据规约(选择表和字段范围)
数据规约是指再接近或保持原始数据完整性的同时将数据集规模减小,以提高数据处理的速度。
df = pd.DataFrame(pd.read_excel(r'C:\Users\Susu\Desktop\data.xls'))
df1 = df[['支付时间','用户名称','支付金额','数据采集时间']]
数据清洗
#去除空值,订单付款时间非空值才保留
#去除买家实际支付金额为0的记录
#不能少第一个df1 df1[]
df1 = df1[df1['支付时间'].notnull() & df1['支付金额'] !=0]
数据整理
from pandas import to_datetime
# R:最近消费时间距数据采集时间的间隔
# 利用to_datatime()转换时间格式:'yyyy-MM-dd HH:mm:ss'
# numpy.datedelta64() 时间差 (数据采集时间-支付时间)/1天 (1,'M')月 (1,'W')星期 (1,'h')小时
df1['R'] = (pd.to_datetime(df1['数据采集时间'])- pd.to_datetime(df1['支付时间'])).values/np.timedelta64(1,'D')
df1 = df1[['支付时间','用户名称','支付金额','R']]
df2 = df1.groupby('用户名称').agg({'R':'min','支付金额':'mean'})
# F: 消费频次,客户一定时间内的购买次数
df2['F']=df1.groupby(["用户名称"])['用户名称'].size() #count
df2.to_excel(r'C:\Users\Susu\Desktop\data_group.xls') #导出结果
数据转换
# 标准化处理
data = pd.read_excel('C:/Users/Susu/Desktop/data_group.xlsx')
data = data[['R','F','支付金额']]
#标准化转换:标准分数=(x-μ)/σ
data = (data - data.mean(axis = 0))/(data.std(axis = 0))
#表头重新命名
data.columns=['R','F','M']
#写入数据
data.to_excel('C:/Users/Susu/Desktop/transform.xlsx',index=False)
K-Means聚类
#客户聚类
#sklearn模块 K-mwans聚类方法对客户数据进行分类
# -*- coding: utf-8 -*-
# 引入sklearn框架,导入k-means聚类算法
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
# 读取数据并进行聚类分析
data = pd.read_excel('C:/Users/Susu/Desktop/transform.xlsx')
# 利用k-means聚类算法对客户数据进行客户分列,聚成4类;如要将客户分成8类,则写为k=8
#需要进行聚类类别数
k = 4
#聚类最大迭代次数
iteration = 500
#调用KMeans语句
kmodel = KMeans(n_clusters= k, max_iter = iteration)
#训练模型
kmodel.fit(data)
#统计聚类个数
r1 = pd.Series(kmodel.labels_).value_counts()
#找出聚类中心
r2 = pd.DataFrame(kmodel.cluster_centers_)
#连接数据,1,横向连接,得到聚类中心对应类别下的数目
r = pd.concat([r1,r2],axis=1)
#重命名表头
r.columns = list(data.columns)+[u'聚类数量']
#输出每个样本对应的类别
r3 = pd.Series(kmodel.labels_,index=data.index)
#合并r1,r2,r3
r = pd.concat([data,r3],axis=1)
#重命r3名表头
r.columns = list(data.columns)+[u'聚类类别']
r.to_excel('C:/Users/Susu/Desktop/output.xlsx')
kmodel.cluster_centers_
kmodel.labels_
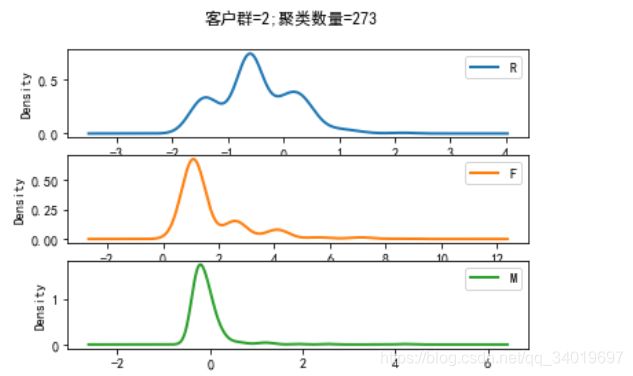
聚类结果绘图
#绘制客户类别图表
# 配置rc默认属性:默认字体
plt.rcParams['font.sans-serif'] = ['SimHei']
# 配置rc默认属性:字符显示;正常显示负号
plt.rcParams['axes.unicode_minus'] = False
#调用plot时加上kind='kde'即可生成密度图(标准混合正态分布KDE)
#4个分类,有4张图,使用循环
for i in range(k):
cls = data[r[u'聚类类别']==i]
cls.plot(kind = 'kde',linewidth = 2,subplots = True,sharex=False)
plt.suptitle('客户群=%d;聚类数量=%d' %(i,r1[i]))
plt.legend()
plt.show()
部分图例:客户群=2,客户数量=273
客户价值分析

重要保持客户:
这类客户价值高,是理想的客户类型,对产品认可度高,贡献值最大,多占比例也最小。可以进行VIP客户进行维护,提高忠诚度和满意度,延长这类用户高水平消费。
一般保持客户:
消费频次多,忠诚客户,可多传递促销活动,品牌信息,新品信息等。
潜在客户:
可进行密集的push,增加消费数量和金额。
一般发展客户:
可能只有店铺打折或促销活动才会消费,需要办法激活,否则可能会流失。