【数据分析】用户价值分析
RFM模型是衡星客户价值和客户创利能力的重要工具和手段。通过一个客户的近期购买行为、购买的总体频率以及花了多少钱三项指标来描该客户的价值状况。
●R:最近一次消费时间(最近一次消费到参考时间的间隔)
●F:消费的频次
●M:消费的金额(总消费金额)
数据清洗
数据格式
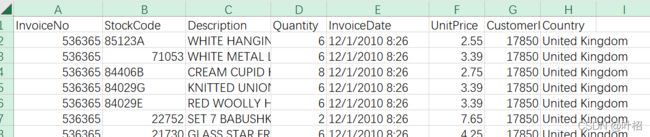
- InvoiceNo: 订单编号,每笔交易有6个整数,退货订单编号开头有字母’C’。
- StockCode: 产品编号,由5个整数组成。
- Description: 产品描述。
- Quantity: 产品数量,负号表示退货
- InvoiceDate: 订单日期和时间。
- UnitPrice: 单价(英镑),单位产品的价格。
- CustomerID:客户编号,每个客户编号由5位数字组成。
- Country: 国家的名称,每个客户所在国家/地区的名称。
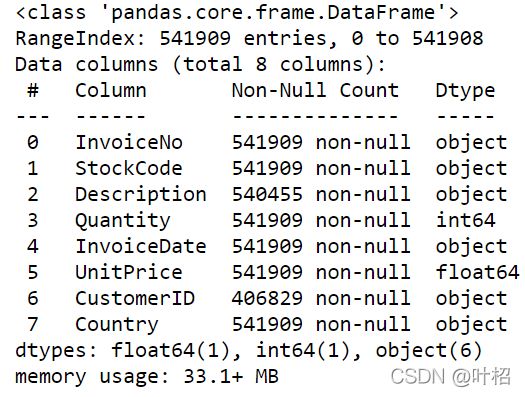
df.shape
(541909, 8)
df.info()
统计缺失率
df.apply(lambda x:sum(x.isnull())/len(x),axis=0)

商品描述用处不大直接删除这一列,然后删除用户id缺失的行
df.drop(['Description'],axis=1,inplace=True)
# how {‘any’, ‘all’}, default ‘any’,any:删除带有nan的行;all:删除全为nan的行
df = df.dropna(how='any')
数据标准化
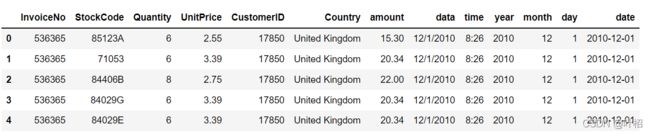
#增加合计购买金额 (amount) =数量*金额
df['amount']= df['Quantity']*df['UnitPrice']
#订单日期切分
df['data']=[x.split(' ')[0] for x in df['InvoiceDate']]
df['time']=[x.split(' ')[1] for x in df['InvoiceDate']]
df.drop(['InvoiceDate'],axis=1,inplace=True)
df['year']=[x.split('/')[2] for x in df['data']]
df['month']=[x.split('/')[0] for x in df['data']]
df['day']=[x.split('/')[1] for x in df['data']]
#转换日期格式
df['date'] = pd.to_datetime(df['data'])
df.head()
删除重复数据
df = df.drop_duplicates()
观察是否有异常值
df.describe()
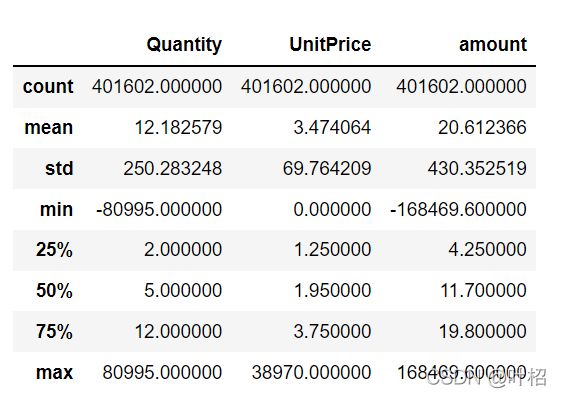
存在退货的订单和价格为0的商品(可能为赠品
退货订单比例
df1 = df.loc[df['Quantity'] <= 0]
print(df1.shape[0]/df.shape[0])
0.022091523448588404
价格为0商品比例
df2 = df.loc[df['UnitPrice'] <= 0]
print(df2.shape[0]/df.shape[0])
0.0000996010976040956
价格为0商品个数
df2['UnitPrice'].groupby(df2['UnitPrice']).count()
UnitPrice
0.0 40
Name: UnitPrice, dtype: int64
计算退货率
退货数/总订单数
t_num = df1['Quantity'].sum()
sale_num = df[df['Quantity']>0]['Quantity'].sum()
t_rate = abs(t_num/sale_num)
print(t_rate)
0.05285657011028571
按月计算退货率
tt = df1.groupby(df1['date'])['Quantity'].sum()
tt = tt.resample('M').sum()
sale = df[df['Quantity']>0].groupby(df['date'])['Quantity'].sum()
sale = sale.resample('M').sum()
rate = abs(tt/sale)
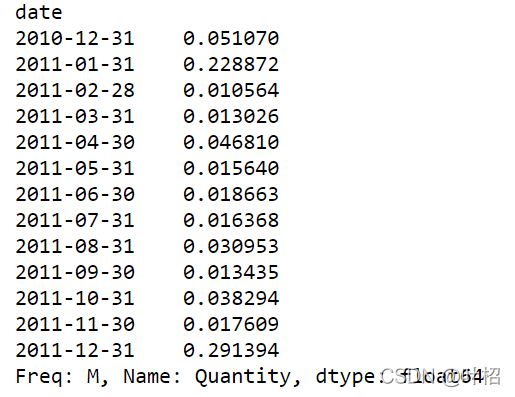
可视化
import plotly.express as px
_y = rate.values
_x = rate.index
fig = px.line(rate, x=_x, y=_y)
fig.show()
用户分类
df2 = df[(df['Quantity'] > 0)&(df['UnitPrice'] > 0)]
# 最近购买的日期
R_value=df2.groupby('CustomerID')['date'].max()
# 计算客户最后一次消费距离截止日期的天数
R = (df2['date'].max()- R_value).dt.days
print(R)
print('-'*50)
#客户消费频率,nunique:去重后计算个数
F = df2.groupby('CustomerID')['InvoiceNo'].nunique()
print(F)
print('-'*50)
#客户消费金额
M = df2.groupby('CustomerID')['amount'].sum()
print(M)
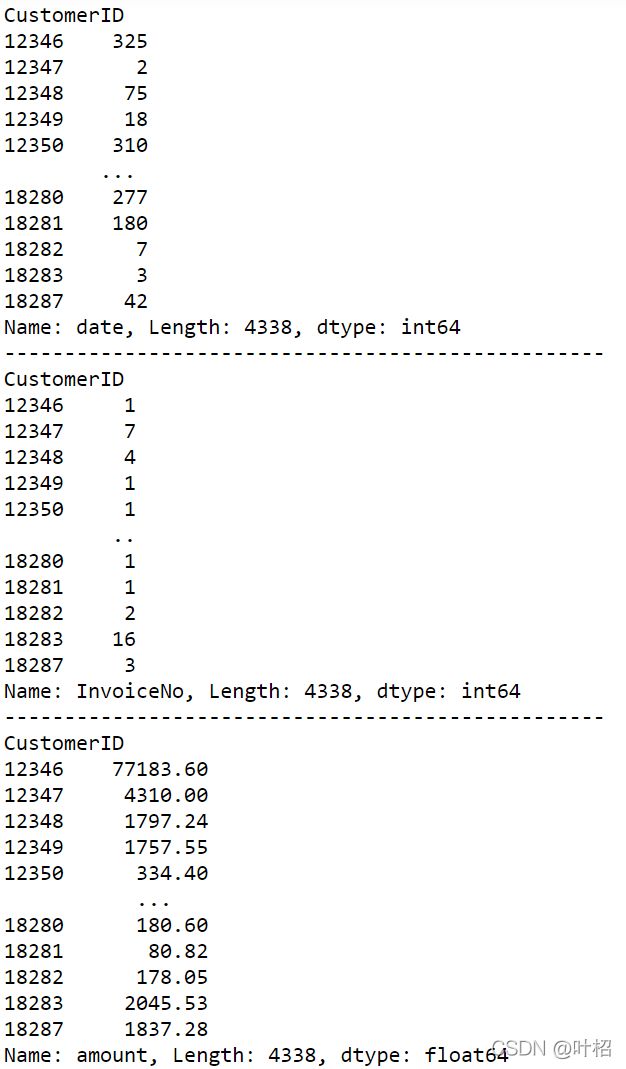
分别使用describe()方法寻找阈值
可视化
直观显示数据的分布
plt.rcParams['font.sans-serif'] = ['SimHei']
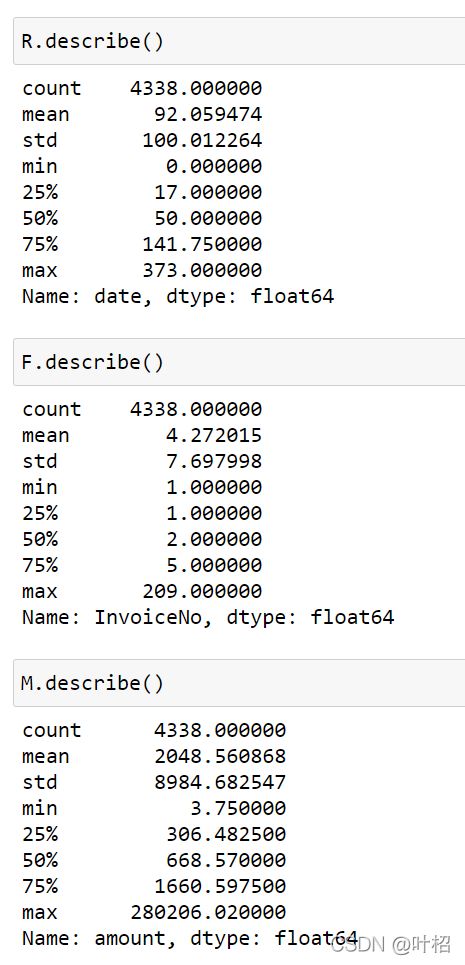
plt.rcParams['axes.unicode_minus'] = False
plt.hist(R,bins =30)
plt.show()
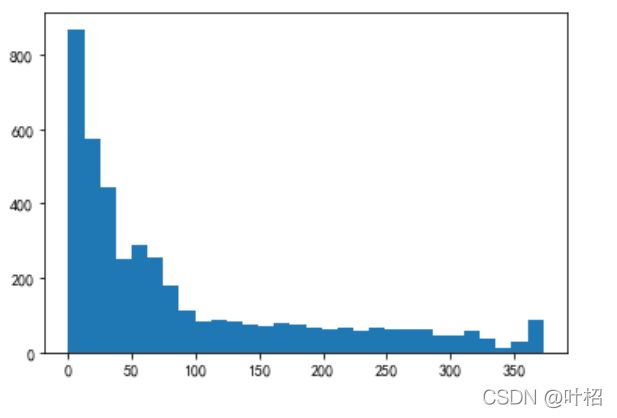
plt.hist(F,bins =30)
plt.show()
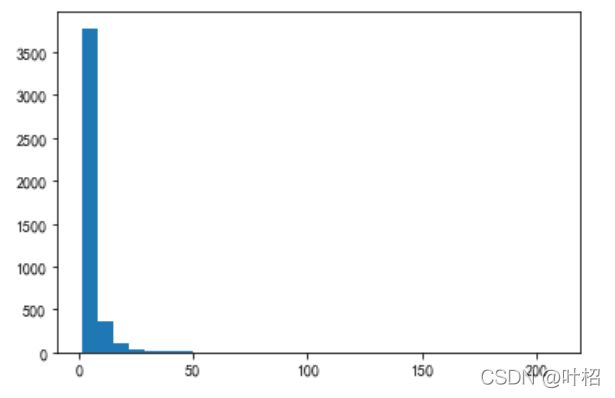
受极值影响可视化不明显,取10以内观察
print(F[F<10].count()/F.count())
plt.hist(F[F<10],bins =10)
plt.show
0.9098662978331028
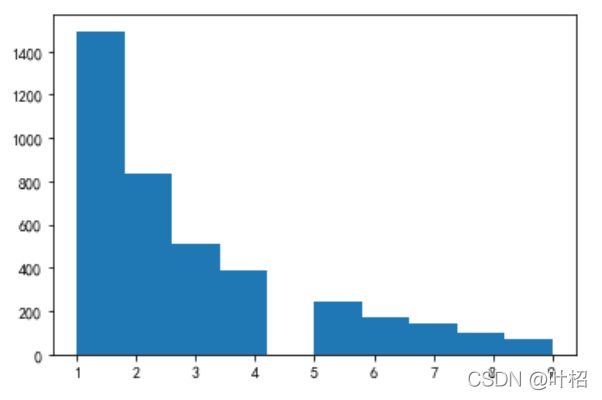
plt.hist(M,bins =30)
plt.show
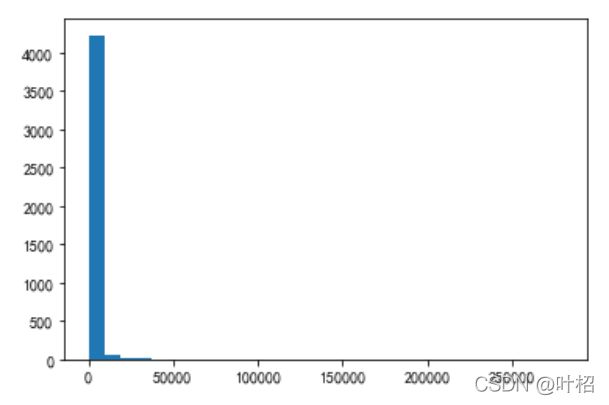
print(M[M<5000].count()/M.count())
plt.hist(M[M<5000],bins=100)
plt.show()
0.9368372521899493
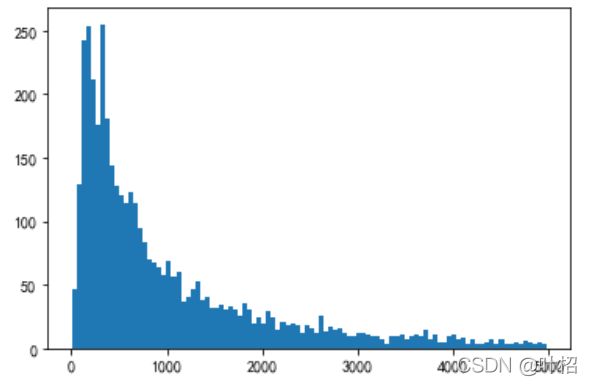
计算rfm得分
pd.cut()分区间统计数量
根据上述RFM分布情况划分数据
R_bins = [0,30,90,180,360,720] #越小越好
F_bins = [1,2,5,10,20,500] #越大越好
M_bins = [0,500,2000,5000,10000,300000] #越大越好
R_score = pd.cut(R,R_bins, labels = [5,4,3,2,1], right=False)
F_score = pd.cut(F,F_bins, labels = [1,2,3,4,5], right=False)
M_score = pd.cut(M,M_bins, labels = [1,2,3,4,5], right=False)
数据合并
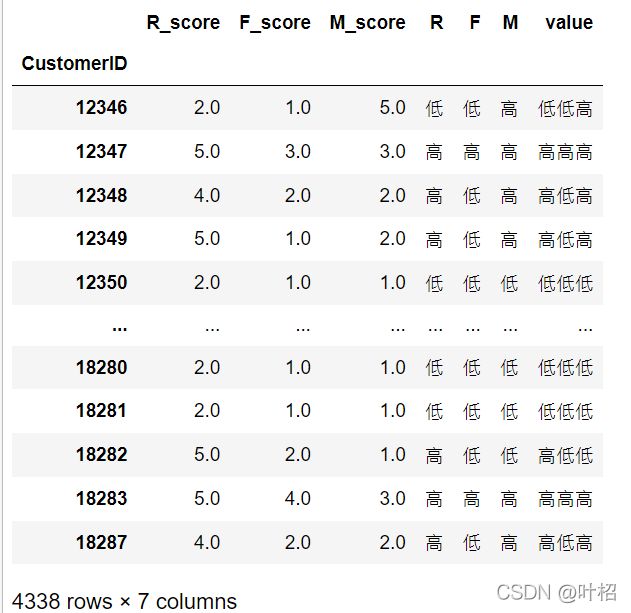
rfm = pd.concat([R_score,F_score,M_score],axis=1)
print(rfm)
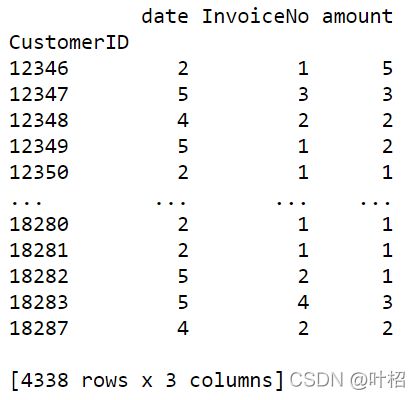
rfm.rename(columns={'date':'R_score','InvoiceNo':'F_score','amount':'M_score'},inplace = True)
数据类型转换
for i in ['R_score','F_score','M_score']:
rfm[i] = rfm[i].astype(float)
查看RFM得分信息
rfm.describe()
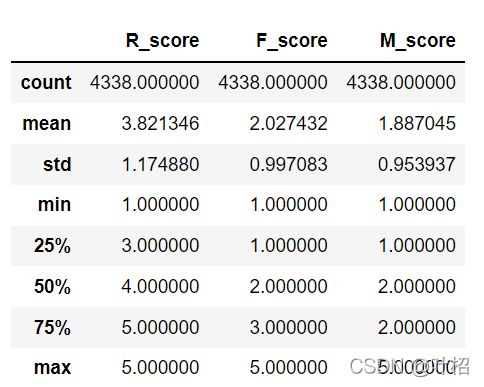
划分等级
rfm['R'] = np.where(rfm['R_score']>3.82,'高','低')
rfm['F'] = np.where(rfm['F_score']>2.03,'高','低')
rfm['M'] = np.where(rfm['M_score']>1.89,'高','低')
rfm['value'] = rfm['R'].str[:] + rfm['F'].str[:]+rfm['M'].str[:]
# 去除空格
rfm['value'] = rfm['value'].str.strip()
def trans_value(x):
if x=='高高高':
return '重要价值客户'
elif x =='高低高':
return '重要发展客户'
elif x =='低高高':
return '重要保持客户'
elif x =='低低高':
return '重要挽留客户'
elif x == '高高低':
return '一般价值客户'
elif x =='高低低':
return '一般发展客户'
elif x =='低高低':
return '一般保持客户'
else:
return '一般挽留客户'
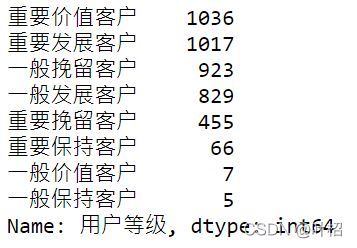
rfm['用户等级'] = rfm['value'].apply(trans_value)
rfm['用户等级'].value_counts()
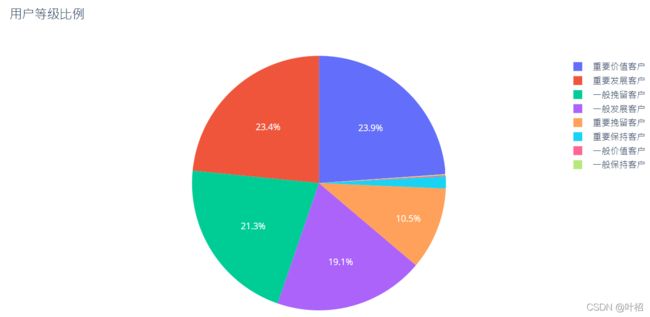
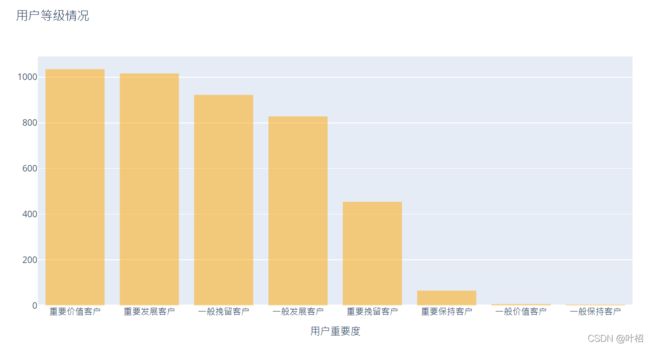
可视化用户等级
trace_basic = [go.Bar(x =rfm['用户等级'].value_counts().index.tolist(),
y =rfm['用户等级'].value_counts().values.tolist(),
marker=dict(color='orange'),opacity=0.50)] #透明度
layout = go.Layout(title = '用户等级情况',xaxis =dict(title ='用户重要度'))
figure_basic = go.Figure(data = trace_basic,layout=layout)# data与layout组成一个图象对象
pyplot(figure_basic)
trace = [go.Pie(labels = rfm['用户等级'].value_counts().index,values=rfm['用户等级'].value_counts().values,
textfont =dict(size=12,color ='white'))]
layout = go.Layout(title ='用户等级比例')
fig = go.Figure(data = trace,layout=layout)
pyplot(fig)