NNDL 实验二 pytorch入门
一. 概念:张量、算子
写出定义,并用通俗易懂的语言描述自己的理解。
二. 使用pytorch实现张量运算
1.2 张量
1.2.1 创建张量
1.2.1.1 指定数据创建张量
(1)通过指定的Python列表数据[2.0, 3.0, 4.0],创建一个一维张量。
import numpy as np
import torch
Tensor=torch.Tensor(np.array([1.0,2.0,3.0]));#np生成再转换成tensor
print(Tensor)![]()
(2)通过指定的Python列表数据来创建类似矩阵(matrix)的二维张量。
Tensor=torch.Tensor(np.array([[1.0,2.0,3.0],[4.0,5.0,6.0]]));#np生产再转换成tensor
print(Tensor) 
1.2.1.2 指定形状创建
(1)创建数据全为0,形状为[3, 4]的Tensor
Tensor=torch.zeros([3,4]);
print(Tensor) 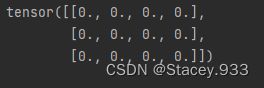
(2)创建数据全为1,形状为[m, n]的Tensor
Tensor=torch.ones([2,3]);
print(Tensor)

(3)创建数据全为指定值,形状为[m, n]的Tensor,这里我们指定数据为10
Tensor=torch.full([3,4],10);
print(Tensor) 
1.2.1.3 指定区间创建
(1)创建以步长step均匀分隔数值区间[start, end)的一维Tensor
Tensor=torch.arange(start=1,end=5,step=1);#结束用end
print(Tensor) ![]()
(2) 创建以元素个数num均匀分隔数值区间[start, stop]的Tensor
Tensor=torch.linspace(1,5,5)
print(Tensor)
1.2.2 张量的属性
1.2.2.1 张量的形状
张量具有如下形状属性:
Tensor.ndim:张量的维度,例如向量的维度为1,矩阵的维度为2。Tensor.shape: 张量每个维度上元素的数量。Tensor.shape[n]:张量第n维的大小。第n维也称为轴(axis)。Tensor.size:张量中全部元素的个数。
为了更好地理解ndim、shape、axis、size四种属性间的区别,创建一个四维张量,并打印出shape、ndim、shape[n]、size属性。
Tensor=torch.ones([2,3,4,5])
print("Number of dimensions:", Tensor.ndim)
print("Shape of Tensor:", Tensor.shape)
print("Elements number along axis 0 of Tensor:", Tensor.shape[0])
print("Elements number along the last axis of Tensor:", Tensor.shape[-1])
print('Number of elements in Tensor: ', Tensor.numel()) #用.numel表示元素个数 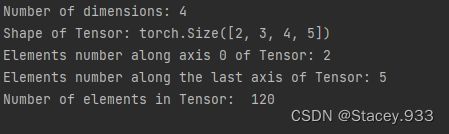
1.2.2.2 形状的改变
import torch
Tensor =torch.tensor([[[1, 2, 3, 4, 5],
[6, 7, 8, 9, 10]],
[[11, 12, 13, 14, 15],
[16, 17, 18, 19, 20]],
[[21, 22, 23, 24, 25],
[26, 27, 28, 29, 30]]])
print("the shape of Tensor:", Tensor.shape)
reshape_Tensor = torch.reshape(Tensor, [2, 5, 3])#利用.reashape改变形状
print("After reshape:", reshape_Tensor) 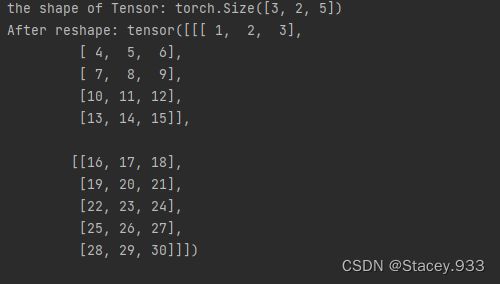
从输出结果看,将张量从[3, 2, 5]的形状reshape为[2, 5, 3]的形状时,张量内的数据不会发生改变,元素顺序也没有发生改变,只有数据形状发生了改变。
分别对上文定义的Tensor进行reshape为[-1]和reshape为[-1, 5, 2]两种操作,观察新张量的形状。
Tensor1 = Tensor.reshape([-1])
print('new Tensor 1 shape: ', Tensor1.shape)
Tensor2 = Tensor.reshape([-1, 5, 2])
print('new Tensor 2 shape: ', Tensor2.shape) 
将张量中的一个或多个维度中插入尺寸为1的维度。
Tensor = torch.ones([5, 10])
Tensor1 = torch.unsqueeze(Tensor, dim=0)
print('new Tensor 1 shape: ', Tensor1.shape)
Tensor2 = torch.unsqueeze(Tensor, dim=1)
Tensor2 = torch.unsqueeze(Tensor2, dim=1)
print('new Tensor 2 shape: ', Tensor2.shape) 
1.2.2.3 张量的数据类型
1)通过Python元素创建的张量,可以通过dtype来指定数据类型,如果未指定:
- 对于Python整型数据,则会创建int64型张量。
- 对于Python浮点型数据,默认会创建float32型张量。
2)通过Numpy数组创建的张量,则与其原来的数据类型保持相同。通过paddle.to_tensor()函数可以将Numpy数组转化为张量。
print("Tensor dtype from Python integers:", torch.tensor(1).dtype)
print("Tensor dtype from Python floating point:", torch.tensor(1.0).dtype) 
如果想改变张量的数据类型
# 定义dtype为float32的Tensor
float32_Tensor = torch.tensor(1.0)
int64_Tensor =float32_Tensor.to(torch.int64)
print("Tensor after cast to int64:", int64_Tensor.dtype) 
1.2.2.4 张量的设备位置
初始化张量时可以通过place来指定其分配的设备位置,可支持的设备位置有三种:CPU、GPU和固定内存。
固定内存也称为不可分页内存或锁页内存,它与GPU之间具有更高的读写效率,并且支持异步传输,这对网络整体性能会有进一步提升,但它的缺点是分配空间过多时可能会降低主机系统的性能,因为它减少了用于存储虚拟内存数据的可分页内存。当未指定设备位置时,张量默认设备位置和安装的飞桨版本一致,如安装了GPU版本的飞桨,则设备位置默认为GPU。
如下代码分别创建了CPU、GPU和固定内存上的张量,并通过Tensor.place查看张量所在的设备位置。
1.2.3 张量与Numpy数组转换
Tensor=torch.tensor([1,2])
print('Tensor to convert: ', Tensor.numpy()) 
1.2.4 张量的访问
1.2.4.1 索引和切片
我们可以通过索引或切片方便地访问或修改张量。飞桨使用标准的Python索引规则与Numpy索引规则,具有以下特点:
1.基于0−n的下标进行索引,如果下标为负数,则从尾部开始计算。
2.通过冒号“:”分隔切片参数start:stop:step来进行切片操作,也就是访问start到stop范围内的部分元素并生成一个新的序列。其中start为切片的起始位置,stop为切片的截止位置,step是切片的步长,这三个参数均可缺省。
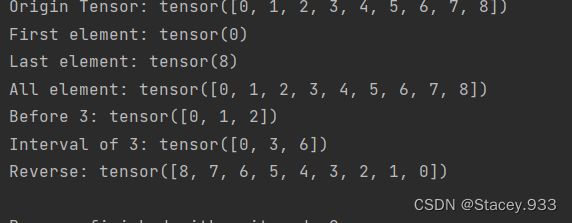
# 定义1个一维Tensor
Tensor = torch.tensor([0, 1, 2, 3, 4, 5, 6, 7, 8])
print("Origin Tensor:", Tensor)
print("First element:", Tensor[0])
print("Last element:", Tensor[-1])
print("All element:", Tensor[:])
print("Before 3:", Tensor[:3])
print("Interval of 3:", Tensor[::3])
# pytorch中张量不支持step为小于0的数,这里使用flip来代替
print("Reverse:", Tensor.flip(-1))
1.2.4.3 修改张量
与访问张量类似,可以在单个或多个轴上通过索引或切片操作来修改张量。
ndim_2_Tensor = torch.ones([2, 3])
ndim_2_Tensor = ndim_2_Tensor.to(torch.float32)
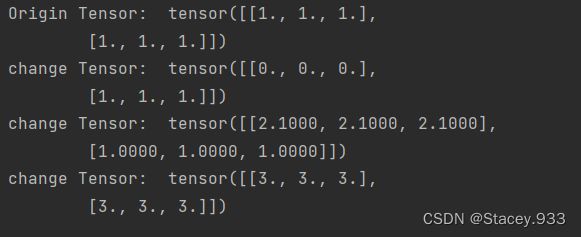
print('Origin Tensor: ', ndim_2_Tensor)
# 修改第1维为0
ndim_2_Tensor[0] = 0
print('change Tensor: ', ndim_2_Tensor)
# 修改第1维为2.1
ndim_2_Tensor[0:1] = 2.1
print('change Tensor: ', ndim_2_Tensor)
# 修改全部Tensor
ndim_2_Tensor[...] = 3
print('change Tensor: ', ndim_2_Tensor)
1.2.5 张量的运算
张量支持包括基础数学运算、逻辑运算、矩阵运算等100余种运算操作
1.2.5.1 数学运算
x.abs() # 逐元素取绝对值
x.ceil() # 逐元素向上取整
x.floor() # 逐元素向下取整
x.round() # 逐元素四舍五入
x.exp() # 逐元素计算自然常数为底的指数
x.log() # 逐元素计算x的自然对数
x.reciprocal() # 逐元素求倒数
x.square() # 逐元素计算平方
x.sqrt() # 逐元素计算平方根
x.sin() # 逐元素计算正弦
x.cos() # 逐元素计算余弦
x.add(y) # 逐元素加
x.subtract(y) # 逐元素减
x.multiply(y) # 逐元素乘(积)
x.divide(y) # 逐元素除
x.mod(y) # 逐元素除并取余
x.pow(y) # 逐元素幂
x.max() # 指定维度上元素最大值,默认为全部维度
x.min() # 指定维度上元素最小值,默认为全部维度
x.prod() # 指定维度上元素累乘,默认为全部维度
x.sum() # 指定维度上元素的和,默认为全部维度
1.2.5.2 逻辑运算
x.isfinite() # 判断Tensor中元素是否是有限的数字,即不包括inf与nan
x.equal_all(y) # 判断两个Tensor的全部元素是否相等,并返回形状为[1]的布尔类Tensor
x.equal(y) # 判断两个Tensor的每个元素是否相等,并返回形状相同的布尔类Tensor
x.not_equal(y) # 判断两个Tensor的每个元素是否不相等
x.less_than(y) # 判断Tensor x的元素是否小于Tensor y的对应元素
x.less_equal(y) # 判断Tensor x的元素是否小于或等于Tensor y的对应元素
x.greater_than(y) # 判断Tensor x的元素是否大于Tensor y的对应元素
x.greater_equal(y) # 判断Tensor x的元素是否大于或等于Tensor y的对应元素
x.allclose(y) # 判断两个Tensor的全部元素是否接近
1.2.5.3 矩阵运算
张量类还包含了矩阵运算相关的函数,如矩阵的转置、范数计算和乘法等。
x.t() # 矩阵转置
x.transpose([1, 0]) # 交换第 0 维与第 1 维的顺序
x.norm('fro') # 矩阵的弗罗贝尼乌斯范数
x.dist(y, p=2) # 矩阵(x-y)的2范数
x.matmul(y) # 矩阵乘法
有些矩阵运算中也支持大于两维的张量,比如matmul函数,对最后两个维度进行矩阵乘。比如x是形状为[j,k,n,m]的张量,另一个y是[j,k,m,p]的张量,则x.matmul(y)输出的张量形状为[j,k,n,p]。
1.2.5.4 广播机制
飞桨的广播机制主要遵循如下规则(参考Numpy广播机制):
1)每个张量至少为一维张量。
2)从后往前比较张量的形状,当前维度的大小要么相等,要么其中一个等于1,要么其中一个不存在。
# 当两个Tensor的形状一致时,可以广播
x = torch.ones((2, 3, 4))
y = torch.ones((2, 3, 4))
z = x + y
print('broadcasting with two same shape tensor: ', z.shape)
x = torch.ones((2, 3, 1, 5))
y = torch.ones((3, 4, 1))
# 从后往前依次比较:
# 第一次:y的维度大小是1
# 第二次:x的维度大小是1
# 第三次:x和y的维度大小相等,都为3
# 第四次:y的维度不存在
# 所以x和y是可以广播的
z = x + y
print('broadcasting with two different shape tensor:', z.shape)

三. 使用pytorch实现数据预处理
1. 读取数据集 house_tiny.csv、boston_house_prices.csv、Iris.csv
import pandas as pd #导入pandas包
# 读取数据集
data_house_tiny = pd.read_csv('house_tiny.csv')
data_boston_house_prices = pd.read_csv('boston_house_prices.csv')
data_Iris = pd.read_csv('Iris.csv')
# 输出数据集
print(data_house_tiny)
print(data_boston_house_prices)
print(data_Iris)结果
NumRooms Alley Price
0 NaN Pave 127500
1 2.0 NaN 106000
2 4.0 NaN 178100
3 NaN NaN 140000
CRIM ZN INDUS CHAS NOX ... RAD TAX PTRATIO LSTAT MEDV
0 0.00632 18.0 2.31 0 0.538 ... 1 296 15.3 4.98 24.0
1 0.02731 0.0 7.07 0 0.469 ... 2 242 17.8 9.14 21.6
2 0.02729 0.0 7.07 0 0.469 ... 2 242 17.8 4.03 34.7
3 0.03237 0.0 2.18 0 0.458 ... 3 222 18.7 2.94 33.4
4 0.06905 0.0 2.18 0 0.458 ... 3 222 18.7 5.33 36.2
.. ... ... ... ... ... ... ... ... ... ... ...
501 0.06263 0.0 11.93 0 0.573 ... 1 273 21.0 9.67 22.4
502 0.04527 0.0 11.93 0 0.573 ... 1 273 21.0 9.08 20.6
503 0.06076 0.0 11.93 0 0.573 ... 1 273 21.0 5.64 23.9
504 0.10959 0.0 11.93 0 0.573 ... 1 273 21.0 6.48 22.0
505 0.04741 0.0 11.93 0 0.573 ... 1 273 21.0 7.88 11.9
[506 rows x 13 columns]
Id SepalLengthCm ... PetalWidthCm Species
0 1 5.1 ... 0.2 Iris-setosa
1 2 4.9 ... 0.2 Iris-setosa
2 3 4.7 ... 0.2 Iris-setosa
3 4 4.6 ... 0.2 Iris-setosa
4 5 5.0 ... 0.2 Iris-setosa
.. ... ... ... ... ...
145 146 6.7 ... 2.3 Iris-virginica
146 147 6.3 ... 1.9 Iris-virginica
147 148 6.5 ... 2.0 Iris-virginica
148 149 6.2 ... 2.3 Iris-virginica
149 150 5.9 ... 1.8 Iris-virginica2. 处理缺失值
import pandas as pd # 导入pandas包
# 读取数据集
data_house_tiny = pd.read_csv('house_tiny.csv')
data_boston_house_prices = pd.read_csv('boston_house_prices.csv')
data_Iris = pd.read_csv('Iris.csv')
inputs, outputs = data_house_tiny.iloc[:, 0:2], data_house_tiny.iloc[:, 2]
print(inputs) 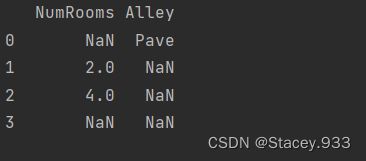
3. 转换为张量格式
import pandas as pd # 导入pandas包
import numpy as np
# 读取数据集
data_house_tiny = pd.read_csv('house_tiny.csv')
data_boston_house_prices = pd.read_csv('boston_house_prices.csv')
data_Iris = pd.read_csv('Iris.csv')
inputs, outputs = data_house_tiny.iloc[:, 0:2], data_house_tiny.iloc[:, 2]
x, y = np.array(inputs.values), np.array(outputs.values)
print(x, y)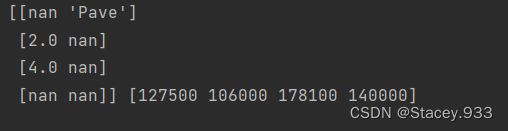
实验心得:第二次实验是关于pytorch的一些基础的操作,对于其中某些函数转化掌握并不是很熟悉,通过查找资料和请教同学解决了部分问题,关于对数据集进行数据预处理的操作,在以前接触过,但对于一些函数的运用有遗忘,通过本次实验巩固一些基础内容。