深入浅出读懂ResNet原理与实现
背景介绍
如果缺少数据的可解释性,所有微调的结果都将成为玄学。这也是本文为了打破深度学习黑箱子操作而撰写的学习内容,让你对Backbone有更深刻的理解。初学者在进入深度学习领域或多或少都会遇到障碍,过程曲折,千万不要气馁,这是初学者普遍存在的现象,特别在CV方向,感觉很多东西无法理解,仅会调参只会让你感觉到玄学,不是把代码跑一遍就可以了,仍需要花时间研究内部细节,特别是对一个学科领域来说缺少数据可解释性是无法支撑你今后应对的各种问题。本文深入浅出讲解ResNet原理和实现,以揭开其神秘面纱,让深度玩家一窥究竟。所有知识点都与这篇论文密切相关,当然也掺杂着自己的理解,一家之言仅供参考^_^。
ResNet在深度学习历史上是里程碑式的模型,在ResNet之前,我们知道深度学习的模型一般都是在20-30层之间,但是在ResNet出现之后,把深度学习的模型层数提高到一百层以上,获得质的提升,其实ResNet可以实现一千层以上的网络模型。
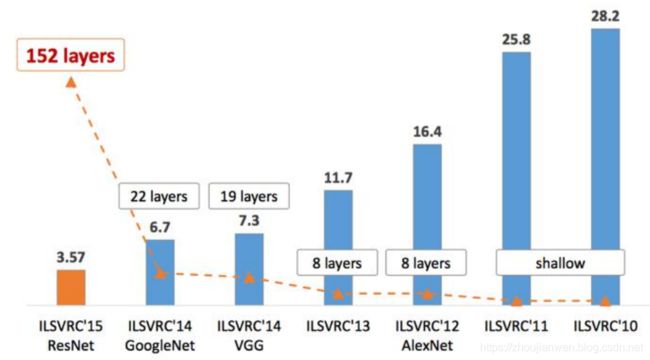
图 1-1
ResNet原理
ResNet主要解决深层网络的退化问题,并不是为了解决过拟合的问题,也不是为了解决梯度消失和梯度爆炸的问题,这个问题已经可以通过在初始化的时候归一化输入得到解决,而是当你的网络层次进一步加深以后,它的表现还不如浅层网络,这就叫做退化(Degradation)。图 1-2 所示。
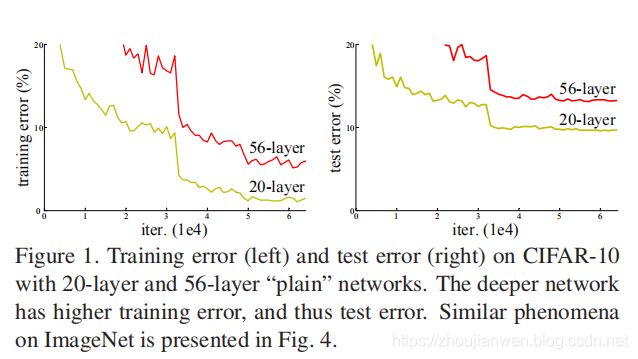
图 1-2
导致退化现象发生的主要原因有哪些?
与传统的机器学习相比,深度学习的关键特征在于网络层数更深、非线性转换(激活)、自动特征提取和特征转换。其中,非线性转换是关键目标,它将数据映射到高纬空间以便于更好的完成“数据分类”。随着网络深度的不断增大,所引入的激活函数也越来越多,数据被映射到更加离散的空间,此时已经难以让数据回到原点(恒等变换)。或者说,神经网络将这些数据映射回原点所需要的计算量,已经远远超过我们所能承受。
我们来看一下 F ( L − 1 ) ( x , w ( L ) ) F^{(L-1)}(x,{w^{(L)}}) F(L−1)(x,w(L))对下层激活值的输入。这里面涉及到正向传播的概念,如图 1-3 所示。我们知道relu是非线性函数,函数 F ( L − 1 ) F^{(L-1)} F(L−1)经过relu非线性转换映射到 [ 0 , + ∞ ] [0,+\infty] [0,+∞],那么能否对激活函数的输出结果实现逆向求参,另一种叫法是实现线性转换。虽然非线性转换极大的提高了数据分类能力,但是随着网络的深度不断的加大,实现线性转换求参是非常困难。为了在线性与非线性转换之间寻求一个平衡,在ResNet模型当中增加快捷连接分支成为一个很好的选择办法。

图 1-3
如图 1-4 所示,我们来看一下 F ( L ) ( x , w ( L ) ) F^{(L)}(x,{w^{(L)}}) F(L)(x,w(L))对上层激活值的敏感度。这里面涉及到反向传播的概念。假设某个神经元之间的层数很深,网络模型学习参数已经变得非常困难的情况下,在函数 F ( L − 1 ) F^{(L-1)} F(L−1)与 F ( L ) F^{(L)} F(L)之间增加一个快捷连接的参数 x x x,使网络变得更加容易被优化,每k层网络就增加一个快捷连接的网络单元称为一个残差块(residual block)。
无残差块公式定义: H 0 H_{0} H0 = a L ( w L a L − 1 + b L ) a^L(w^La^{L-1}+b^L) aL(wLaL−1+bL)
有残差块公式定义:
F L − 1 F^{L-1} FL−1 = H 0 H_{0} H0 - x i n p u t x_{input} xinput,梯度求出最优解映射 x x x的参数 ( w i L − 1 , b i L − 1 ) (w^{L-1}_i,b^{L-1}_i) (wiL−1,biL−1),而不通过 F L F^{L} FL反向求出参数( w L , a L − 1 , b L w^L,a^{L-1},b^L wL,aL−1,bL),而是在 F L − 1 F^{L-1} FL−1 与 F L F^{L} FL层的神经元之间搭建一个快捷连接 x x x ,该快捷连接在前馈网络就已经实现,以便于反向传播学习参数。
F L F^L FL = F L − 1 + x F^{L-1} + x FL−1+x ====> 如果 F L F^L FL不输入到下一层,到这里可看作 H 0 H_0 H0 的期望值
H 0 H_0 H0 = a L ( F L ) a^L(F^{L}) aL(FL)
整个网络依然可以用SGD+反向传播来做端到端的训练。

图 1-4
ResNet实现解决网络退化现象,最主要提出:
(1)残差学习(Residual Learning)
所谓的残差网络就是本来要学习H(x),但是由于随着层次越来越深学习H(x)就变得越来越困难,那么就直接改学习为F(x):=H(x)- x x x,F(x)是H(x)- x x x的差值,所以F(x)就是残差,经过简单的四则运算就能求出H(x):=F(x)+ x x x,H(x)正是拟合的结果,这就是残差学习的概念。
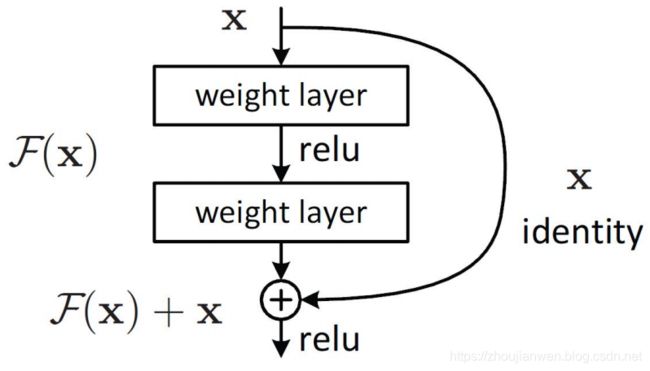
图 1-5
图1-4 参数传递路径有两种走法,如果沿着一条路径走不通,可以沿着另一条路径走。随着层次越来越深,从层 w n − 1 w^{n-1} wn−1 到层 w n w^{n} wn 直接求出H(x)是很困难,可以另辟蹊径,直接绕过前面的ReLU和偏差,让F(x)直接到达F(x)+ x x x,相当于从层 w n − 1 w^{n-1} wn−1 到层 w n w^{n} wn之间找到一个具有identity的标识映射参数 x x x,使得F(x)+ x x x满足H(x)期望值,言外之意就是增加一条通往H(x)的路径,把这条路径看作快捷连接的通道,而不是只有一条路走到黑,使得网络有更多的选择,让网络自己去学习究竟走哪条路更便捷。因为你要模拟的东西不知道是简单还是复杂的,如果你模拟的东西是简单的,可以选择抄近道走。如果你模拟的东西是很复杂的,你就必须走很复杂的路径。 注意最后一个relu输出是relu(F(x)+ x x x)
(2)恒等映射(Identity Mapping Shortcut)
恒等映射就是对每个堆叠层都采用残差学习,构建块公式定义
y = F ( x , w i ) + x y=F(x,{w_i})+x y=F(x,wi)+x
其中函数 F ( x , w i ) F(x,{w_i}) F(x,wi)表示要学习的残差映射,函数 F ( x , w i ) F(x,{w_i}) F(x,wi)可能涉及到多层的可能性,如果函数 F ( x , w i ) F(x,{w_i}) F(x,wi)只有一层,那么它没有多层获得的优势明显。另外 F ( x , w i ) F(x,{w_i}) F(x,wi)与 x x x的维度信息要保持一致,否则在通过快捷连接获得的标识映射参数 x x x就一定要执行线性投影 W s W_s Ws以保持输入输出尺寸一致,构建块公式定义
y = F ( x , w i ) + W s x y=F(x,{w_i})+W_sx y=F(x,wi)+Wsx
网络架构比较
vgg-19的网络只有19层,34-layer plain的网络只是简单地堆叠卷积块,这样一个深层的网络性能还不如vgg-19。通过增加恒等映射(Identity Mapping Shortcut)的结构就能把像34-layer plain的网络结构变成残差网络——ResNet-34,这样一个网络结构准确率就比vgg-19提升很多。
VGG-19, 34-layer plain, 34 layer residual三种网络结构如图 1-6 所示。
卷积层参数表示为
图 1-6
注意:虚线是维度信息发生变化,当主路的维度信息 x x x发生变化也要与快捷连接通道的维度信息 W s x W_sx Wsx保持一致,只有维度信息一样才能相加。实线就是维度信息没有发生变化。与vgg相比,其参数少得多,因为vgg有3个全连接层,这需要大量的参数,而resnet用 avg pool 代替全连接,节省大量参数。参数少,残差学习,训练效率高。
ResNet不同层次网络结构图,如图 1-7 所示。仔细观察你会发现下面不同层次的ResNet都统一分成五个部分。这里面的每一个部分都叫做Stage,Stage由Block组成,而Block是由Conv组成的。其层次表达关系公式
S t a g e = { B l o c k = { C o n v } } Stage = \{Block=\{Conv\}\} Stage={Block={Conv}}
举个例子,Stage = [[3x3,64],[3x3,64]]x2,Block=[[3x3,64],[3x3,64]],conv = [3x3,64]
不管残差网络有多少层,网络结构基本上都是这样的构造成分,通过这种规律可以写成具有良好扩展性的网络结构。
如图 1-7 所示,一共提出了5种深度的ResNet,分别是18,34,50,101和152,首先看下图最左侧,我们发现所有的网络都分成5部分,分别是:conv1,conv2_x,conv3_x,conv4_x,conv5_x,之后其他论文也会专门用这个称呼指代ResNet50或者101的每部分。
如101-layer那列,我们先看看101-layer是不是真的是101层网络,首先输入7x7x64的conv1,然后经过3 + 4 + 23 + 3 = 33个building block,每个block为3层,所以有33 x 3 = 99层,最后有个fc层(用于分类),所以1 + 99 + 1 = 101层,确实有101层网络。注意101层网络仅仅指卷积和全连接层,而激活层和Pooling层并没有计算在内。这里我们关注50-layer和101-layer这两列,可以发现,它们唯一的不同在于conv4_x,ResNet50有6个block,而ResNet101有23个block,差了17个block,也就是17 x 3 = 51层。
图 1-7
第二列的outputsize尺寸是如何计算出来的?通过 112 x 112 反推出输入层的神经元尺寸为 229 x 229。
input size = 229
conv1 output size 112 = (n + 2 * 0 - conv) / 2 +1 ,若conv = 1,3,5,7 而 padding=0 , stride=2 则 n = 223,225,227,229
conv2_x output size 56 = (112 + 2 * 0 - 3) / 2 + 1 , 向上取整
conv3_x output size 28 = (56 + 2 * 0 - 3) / 2 + 1 , 向上取整
conv4_x output size 14 = (28 + 2 * 0 - 3) / 2 + 1 , 向上取整
conv5_x output size 7 = (14 + 2 * 0 - 3) / 2 + 1 , 向上取整
将上面输出的神经元再输入到全局平均池化层处理
将上面输出的池化层神经元再输入到全连接层 1000-d fc处理,即FC(1,1000)
最后一层经过softmax计算得到各神经元的概率值。
在ResNet网络结构里面使用了全局平均池化(Global Average Pooling),全局平均池化能起到取替全连接层的作用,并不影响其精确度,整个网络结构就能实现全卷积的结构。而使用全连接层会增加整个网络的参数数量,容易造成过拟合的现象发生。如图1-8,图1-9所示。
图 1-8
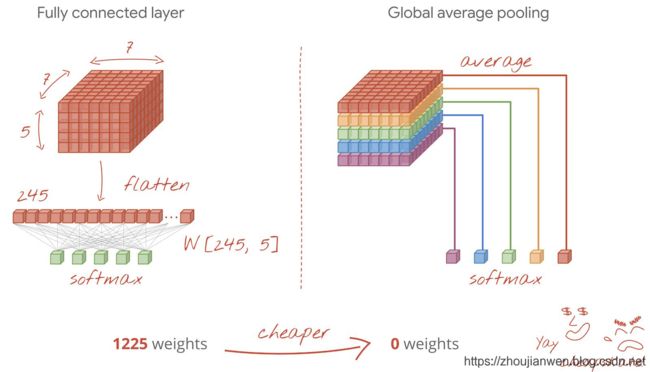
图 1-9
深度学习框架平台Global Average Pooling实现api函数,
Pytorch: torch.nn.AdaptiveAvgPool2d(output_size)
TensorFlow: tf.keras.layers.GlobalAvgPool2D
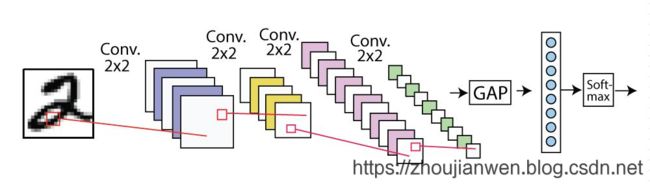
图 1-10
BottleNeck
不同深度的ResNet使用的残差学习单元层数不同,左边是50层以下使用普通Block结构,针对ResNet34浅层网络,右边是50层以上使用BottleNeck结构,针对的是ResNet50/101/152深层网络,卷积层数一般是2或3组成,思考一下Block能否只有一层卷积组成?
如图 1-11 所示,下面两种结构分别针对ResNet34(图左边)和ResNet50/101/152(图右边),其目的主要就是为了降低参数的数目。

图 1-11
为了方便比较两者之间的区别,如图 1-12 所示。左图是两个3x3x256的卷积,参数数目: 256x3x3x256+256x3x3x256 = 1179648,右图是第一个1x1的卷积把256维通道降到64维,然后在最后通过1x1卷积恢复,整体上用的参数数目:1x1x256x64 + 3x3x64x64 + 1x1x64x256 = 69632,右图的参数数量比左图减少了16.94倍,因此,右图的主要目的就是为了减少参数量,从而减少计算量。 对于常规的ResNet,可以用于34层或者更少的网络中(左图);对于更深的网络(如101层),则使用右图,其目的是减少计算和参数量。作者使用更多的3层残差学习单元来构建101层和152层网络。值的注意的是,ResNet-152深度增加了许多,但其复杂性(113亿FLOPs)仍比VGG-16/19(153/196亿FLOPs)低。

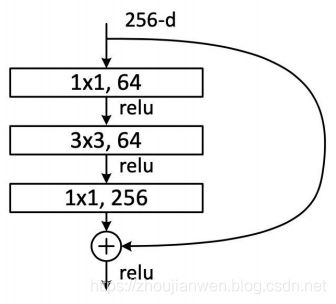
图 1-12
为什么BottleNeck结构设计要使用1×1卷积?为什么非要用 1x1 来增加深度呢?增加网络深度有什么好处?
在论文中解释,大概有下面两层意义:
(1)增加网络的深度,添加非线性
这涉及到感受野的问题,我们知道卷积核越大,它生成的 featuremap 上单个节点的感受野就越大,随着网络深度的增加,越靠后的 featuremap 上的节点感受野也越大。因此特征也越来越形象,也就是更能看清这个特征是个什么东西。层数越浅,就越不知道这个提取的特征到底是个什么东西。举个简单的例子,如图 1-13 所示为一个三层卷积网络,每一层我的卷积核心为3X3,步长为1,可以看到第一层对应的感受野是3X3,第二层是5X5,第三层则是7X7。

图 1-13 感受野示意图
卷积层和池化层都会影响感受野,而激活函数层通常对于感受野没有影响。对于一般的卷积神经网络,感受野可由公式 R F l + 1 RF_{l +1} RFl+1 = R F l RF_{l} RFl + ( k l + 1 − 1 ) (k_{l+1}-1) (kl+1−1)x S l S_{l} Sl计算得到, S l S_l Sl代表前 l l l层的步长之积, R F l + 1 RF_{l +1} RFl+1 与 R F l RF_{l} RFl 分别代表第 l l l+1层与 l l l层的感受野, k k k代表第 l + 1 l+1 l+1层卷积核的大小。比如我要计算出第三层 R F 3 RF_3 RF3的感受野,利用公式可以推导出
R F 2 + 1 RF_{2+1} RF2+1 = R F 2 RF_{2} RF2 + ( k 2 + 1 − 1 ) (k_{2+1}-1) (k2+1−1)x S 2 S_{2} S2 = 5+(3-1)x1 = 7
R F 1 + 1 RF_{1+1} RF1+1 = R F 1 RF_{1} RF1 + ( k 1 + 1 − 1 ) (k_{1+1}-1) (k1+1−1)x S 1 S_{1} S1 = 3+(3-1)x1 = 5
R F 0 + 1 RF_{0+1} RF0+1 = R F 0 RF_{0} RF0 + ( k 0 + 1 − 1 ) (k_{0+1}-1) (k0+1−1)x S 0 S_{0} S0 = 1+(3-1)x1 = 3
注意,当前层的步长并不影响当前层的感受野,在实践过程中,有效感受野往往小于理论感受野。
在不增加感受野的情况下,让网络加深,为的就是引入更多的非线性函数,而1x1卷积核,恰巧可以办到。卷积后生成图片的尺寸受卷积核的大小和卷积核个数影响,但如果卷积核是 1x1 ,个数也是 1,那么生成后的图像长宽不变,厚度为1。通常一个卷积层是包含激活和池化的,也就是多了激活函数,比如 Sigmoid 和 Relu。所以,在输入不发生尺寸的变化下,加入卷积层的同时引入了更多的非线性,这将增强神经网络的表达能力。
(2)改变维度信息
卷积后的的 featuremap 通道数是与卷积核的个数相同的,如图 1-14 维度信息所示,如图输入一张二维图片通道是 3,卷积核的数量是 2,每个卷积核通道是3 ,那么生成的 feature map 通道就是 2,这就是降维。如图输入一张二维图片通道是 3,卷积核的数量是 6,每个卷积核通道是3 ,那么生成的 feature map 通道就是 6,这就是升维。如果卷积核的数量是 1,那么生成的 feature map 只有 1 个通道,这就是降维度。降低维度信息就相当于成倍数减少网络参数,使得层数更深,参数更小。值得注意的是,所有尺寸的卷积核都可以达到这样的目的。
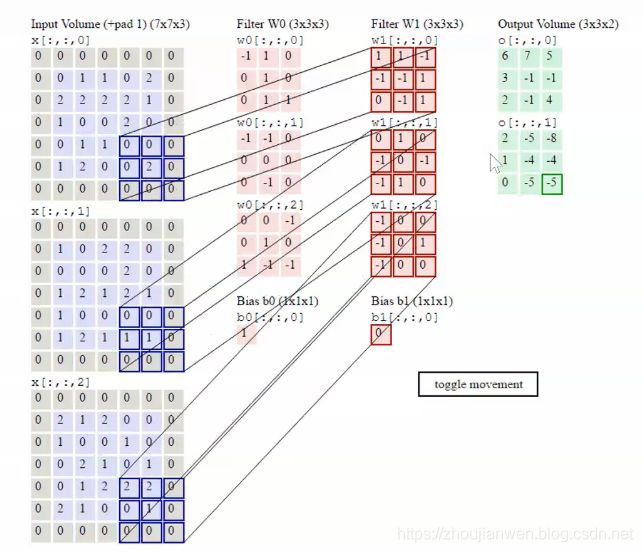
图 1-14 维度信息
ResNet实现
PyTorch官方实现ResNet在原版基础上增加很多东西,例如组卷积(groups),dilation(膨胀卷积),为了方便理解只实现原版的ResNet-34,参考图 1-7 实现代码。
定义卷积层
import torch
import torch.nn as nn
def conv3x3(in_planes,out_planes,stride=1,padding=1):
return nn.Conv2d(in_planes,out_planes,kernel_size=3,stride=stride,padding=padding,biase=False)
# biase=False 与 bn层是有关联的,特别是卷积层后面是bn层,就可以不用设置biase,即使设置偏置,bn层也会调整。
def conv1x1(in_planes,out_planes,stride=1):
return nn.Conv2d(in_planes,out_planes,kernel_size=3,stride=stride,padding=padding,biase=False)
定义BasicBlock结构
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None,norm_layer=None):
super(BasicBlock, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
self.conv1 = conv3x3(inplanes, planes, stride)
# 在卷积层之后增加一个bn层,bn层对每一层的均值和方差都重新计算,这样可以不用设置偏差biase
self.bn1 = norm_layer(planes) # batch normalization(批标准化)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes, stride) # 第一个planes代表上层输出是本层的输入
self.bn2 = norm_layer(planes)
self.downsample = downsample
self.stride = stride
# 在__init__函数里面只是定义这些网络结构层,真正要执行在forward函数
def forward(self, x):
identity = x # 快捷连接标识符,输入的参数要保存下来,否则下面执行更新参数会发生变化
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None: #downsample下采样,输入输出维度信息保持一致
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
以上代码主要实现如图 1-15 BasicBlock结构,注意bn层并没有在结构图里面显示出来,bn层在weight layer与relu之间。如何调整bn层?

图 1-15 BasicBlock
定义Bottleneck结构
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None, norm_layer=None):
super(Bottleneck, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
self.conv1 = conv1x1(inplanes, planes)
self.bn1 = norm_layer(planes)
self.conv2 = conv3x3(planes, planes, stride,)
self.bn2 = norm_layer(planes)
self.conv3 = conv1x1(planes, planes * self.expansion)
self.bn3 = norm_layer(planes * self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
以上代码主要实现如图 1-16 Bottleneck结构
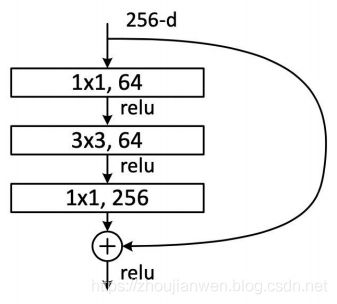
图 1-16 BottleNeck
前面已经定义两种不同Block结构,分别是BasicBlock和Bottleneck。
class ResNet(nn.Module):
# num_classes 整个网络结构可分类类别的数量,为什么是默认1000?是因为ImageNet数据集有1000个分类,如果你要使用自己的数据集,类别数量可以根据自己数据集设定。
def __init__(self, block, layers, num_classes=1000, norm_layer=None):
super(ResNet, self).__init__()
self._norm_layer = norm_layer
self.inplanes = 64 # 这些参数设定都是根据论文的设计图纸而来,如图1-17所示。
### Stage-Start
# conv1
self.conv1 = nn.Conv2d(3, self.inplanes, kernel_size=7, stride=2, padding=3,bias=False)
elf.bn1 = norm_layer(self.inplanes)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
# conv2._x
self.layer1 = self._make_layer(block, 64, layers[0])
# conv3._x
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
# conv4._x
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
# conv5._x
self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
### Stage-End
# output
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512 * block.expansion, num_classes)
# 模型参数初始化
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
#
def _make_layer(self, block, planes, blocks, stride=1):
norm_layer = self._norm_layer
downsample = None
previous_dilation = self.dilation
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
conv1x1(self.inplanes, planes * block.expansion, stride),
norm_layer(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample,norm_layer))
self.inplanes = planes * block.expansion
for _ in range(1, blocks):
layers.append(block(self.inplanes, planes, norm_layer=norm_layer))
return nn.Sequential(*layers)
def _forward_impl(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
def forward(self, x):
return self._forward_impl(x)

图 1-17
根据前面定义好的层分别生成ResNet-34和ResNet-152,大于50层要使用BottleNeck结构。
def resnet34():
return ResNet(BasicBlock, [3, 4, 6, 3])
def resnet152():
return ResNet(BottleNeck, [3, 8, 36, 3])
如何验证生成的模型?就是使用预训练参数。
‘resnet34’: ‘https://download.pytorch.org/models/resnet34-333f7ec4.pth’,
‘resnet152’: ‘https://download.pytorch.org/models/resnet152-b121ed2d.pth’
前面编写的代码都是为了方便理解论文,现在参考pytorch官方文档验证ResNet-34
import torch
model = torch.hub.load('pytorch/vision:v0.5.0', 'resnet34', pretrained=True)
# or any of these variants
# model = torch.hub.load('pytorch/vision:v0.5.0', 'resnet18', pretrained=True)
# model = torch.hub.load('pytorch/vision:v0.5.0', 'resnet50', pretrained=True)
# model = torch.hub.load('pytorch/vision:v0.5.0', 'resnet101', pretrained=True)
# model = torch.hub.load('pytorch/vision:v0.5.0', 'resnet152', pretrained=True)
model.eval()
# Download an example image from the pytorch website
import urllib
url, filename = ("https://github.com/pytorch/hub/raw/master/dog.jpg", "dog.jpg")
try: urllib.URLopener().retrieve(url, filename)
except: urllib.request.urlretrieve(url, filename)
# sample execution (requires torchvision)
from PIL import Image
from torchvision import transforms
input_image = Image.open(filename)
preprocess = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
input_tensor = preprocess(input_image)
input_batch = input_tensor.unsqueeze(0) # create a mini-batch as expected by the model
# move the input and model to GPU for speed if available
if torch.cuda.is_available():
input_batch = input_batch.to('cuda')
model.to('cuda')
with torch.no_grad():
output = model(input_batch)
# Tensor of shape 1000, with confidence scores over Imagenet's 1000 classes
print(output[0])
# The output has unnormalized scores. To get probabilities, you can run a softmax on it.
print(torch.nn.functional.softmax(output[0], dim=0))
高效实现神经网络结构
由于神经网络对于噪声不敏感,所以许多早期经典模型的参数其实是存在很大冗余度的,这样的模型很难部署在存储有限的边缘设备,因此学术界开始追求一些轻量级的网络设计(这代表着更少的参数,更少的乘法操作,更快的速度)。
(1)减小卷积核大小
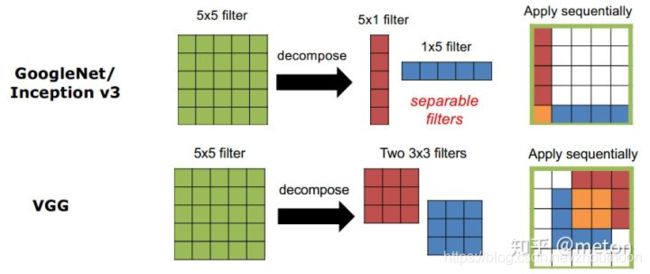
主要的做法包括使用更小的3x3卷积(加深网络来弥补感受野变小);将大卷积核分解成一系列小的卷积核的操作组合。
(2)减少通道数

第一种方式:1x1卷积的应用。在大卷积核前应用1X1卷积,可以灵活地缩减feature map通道数(同时1X1卷积也是一种融合通道信息的方式),最终达到减少参数量和乘法操作次数的效果。
第二种方式:group convolution,将feature map的通道进行分组,每个filter对各个分组进行操作即可,像上图这样分成两组,每个filter的参数减少为传统方式的二分之一(乘法操作也减少)。
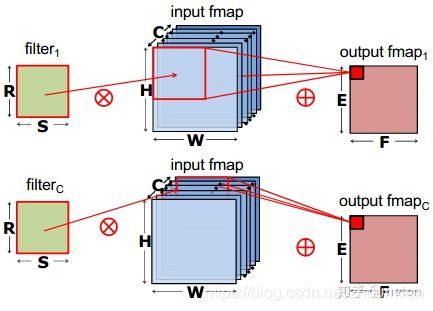
第三种方式:depthwise convolution,是组卷积的极端情况,每一个组只有一个通道,这样filters参数量进一步下降。
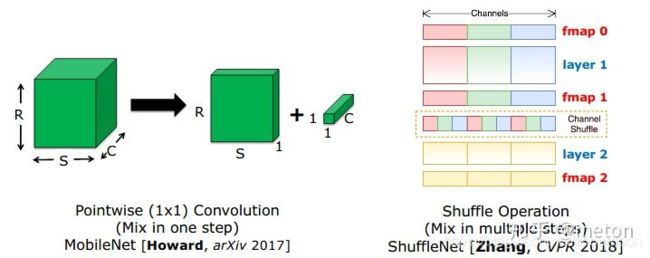
如果只采用分组卷积操作,相比传统卷积方式,不同组的feature map信息无法交互,因此可以在组卷积之后在feature map间进行Shuffle Operation来加强通道间信息融合。或者更巧妙的是像Pointwise convolution那样将原本卷积操作分解成两步,先进行 depthwise convolution,之后得到的多个通道的feature map再用一个1X1卷积进行通道信息融合,拆解成这样两步,卷积参数也减少了。
-
减少filter数目
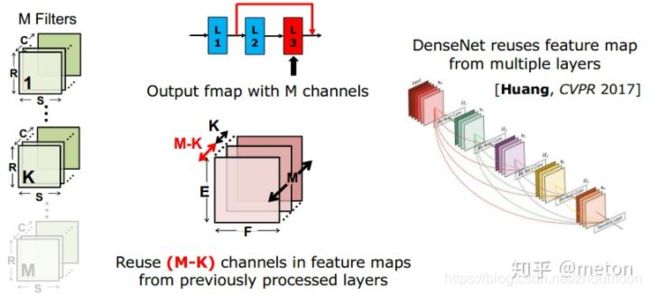
直接减少的filter数目虽然可以减少参数,但是导致每层产生的feature map数目减少,网络的表达能力也会下降不少。一个方法是像DenseNet那样,一方面减少每层filter数目,同时在每层输入前充分重用之前每一层输出的feature map。 -
池化操作
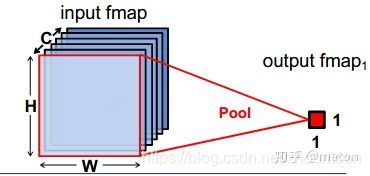
池化操作是操作卷积神经网络的标准操作,池化层没有参数,同时又可以灵活缩减上一级的feature map大小,从而减少下一级卷积的乘法操作。
参考
[1]https://www.cv-foundation.org/openaccess/content_cvpr_2016/papers/He_Deep_Residual_Learning_CVPR_2016_paper.pdf
[2]https://arxiv.org/pdf/1512.03385.pdf
[3]https://github.com/pytorch/vision/blob/master/torchvision/models/resnet.py
[4]https://www.cnblogs.com/aiblbns/p/11143978.html
[5]https://blog.csdn.net/yaochunchu/article/details/95527760
[6]https://www.cnblogs.com/yanshw/p/10576354.html
[7]http://www.freesion.com/article/6696114352/
[8]https://zhuanlan.zhihu.com/p/101544149
[9]VGG(2014),3x3卷积的胜利