paddle篇---用yolov3训练自己的数据集
用yolov3训练自己的数据集
- 1、生成数据集
- 2、修改配置文件
- 3、训练
- 4、模型评估
- 5、模型预测
-
- 5.1、坐标和类别获取
- 6、模型可视化
- 7、模型导出
- 8、模型部署
-
- 8.1 获得目标的类别,置信度和坐标
1、生成数据集
可看我的另一篇博客 添加链接描述
2、修改配置文件
由于paddle固定了数据集的名字,如果用自己的数据集命名的话就会出现如下的报错
ValueError: Dataset ./app/yyq/slifeProject/interest/paddle/waste is not valid and cannot parse dataset type 'waste' for automaticly downloading, which only supports 'voc' , 'coco', 'wider_face', 'fruit', 'roadsign_voc' and 'mot' currently
那如何解决这个问题呢?
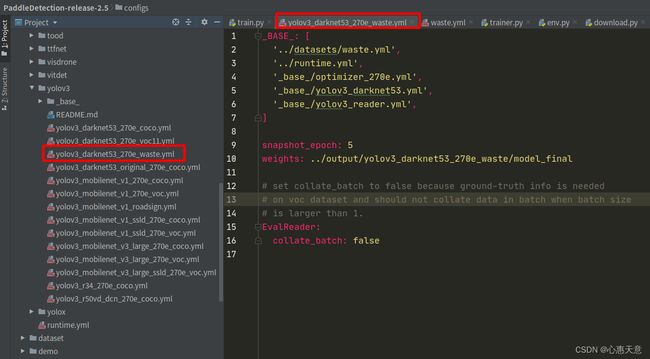
首先:我在 /app/yyq/slifeProject/interest/paddle/PaddleDetection-release-2.5/configs/yolov3/yolov3_darknet53_270e_waste.yml ,yml不是以paddle所固定的数据集的格式
我的yml配置如下:
_BASE_: [
'../datasets/waste.yml',
'../runtime.yml',
'_base_/optimizer_270e.yml',
'_base_/yolov3_darknet53.yml',
'_base_/yolov3_reader.yml',
]
snapshot_epoch: 5
weights: ../output/yolov3_darknet53_270e_waste/model_final
# set collate_batch to false because ground-truth info is needed
# on voc dataset and should not collate data in batch when batch size
# is larger than 1.
EvalReader:
collate_batch: false
其次:/app/yyq/slifeProject/interest/paddle/PaddleDetection-release-2.5/configs/datasets/waste.yml
metric: VOC
map_type: 11point
num_classes: 20
TrainDataset:
!VOCDataSet
dataset_dir: /app/yyq/slifeProject/interest/paddle/waste # 用终端运行的话改成 dataset/waste
anno_path: trainval.txt
label_list: label_list.txt
data_fields: ['image', 'gt_bbox', 'gt_class', 'difficult']
EvalDataset:
!VOCDataSet
dataset_dir: /app/yyq/slifeProject/interest/paddle/waste # 用终端运行的话改成 dataset/waste
anno_path: test.txt
label_list: label_list.txt
data_fields: ['image', 'gt_bbox', 'gt_class', 'difficult']
TestDataset:
!ImageFolder
anno_path: /app/yyq/slifeProject/interest/paddle/waste/label_list.txt
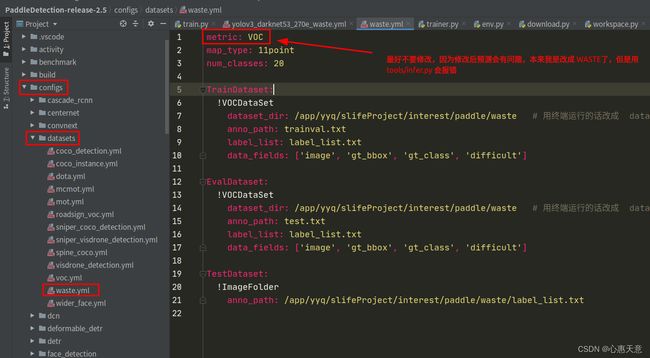 注意:
注意: dataset_dir 和 anno_path 的路径不要写错
再次:/app/yyq/slifeProject/interest/paddle/PaddleDetection-release-2.5/configs/yolov3/base/optimizer_270e.yml
可以修改 epoch 和 base_lr

3、训练
python tools/train.py -c configs/yolov3/yolov3_darknet53_270e_waste.yml --use_vdl=true --vdl_log_dir=vdl_dir/scalar
直接运行会报错,意思是没有 waste的数据集
怎么修改
文件: /app/yyq/slifeProject/interest/paddle/PaddleDetection-release-2.5/ppdet/utils/download.py
1、先加上 自己的数据集的路径
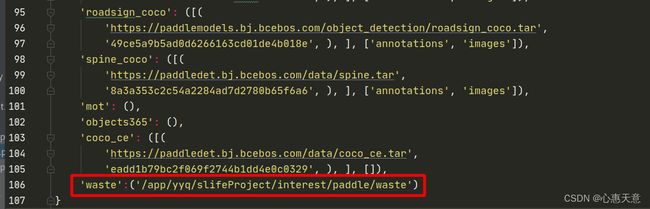 2、加上 waste的数据
2、加上 waste的数据
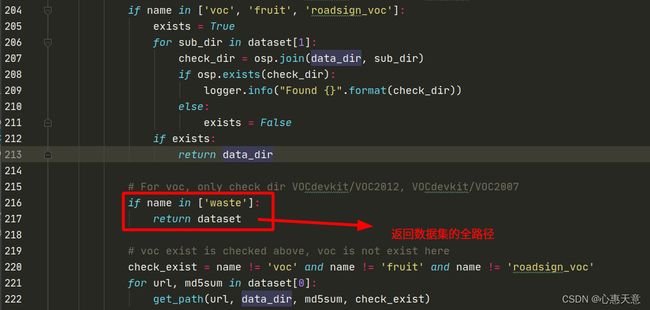
两步操作后就可以正常运行了

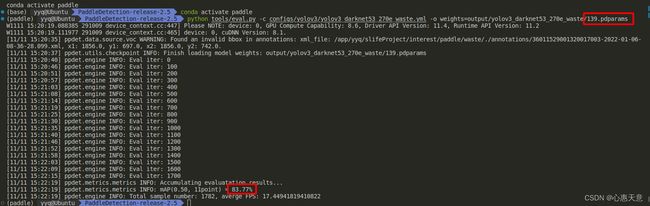
4、模型评估
python tools/eval.py -c configs/yolov3/yolov3_darknet53_270e_waste.yml -o weights=output/yolov3_darknet53_270e_waste/139.pdparams
5、模型预测
python tools/infer.py -c configs/yolov3/yolov3_darknet53_270e_waste.yml --infer_img=demo/31011529001320014341-2021-05-11-15-22-55.892.jpg -o weights=output/yolov3_darknet53_270e_waste/139.pdparams

5.1、坐标和类别获取
6、模型可视化
# 下述命令会在127.0.0.1上启动一个服务,支持通过前端web页面查看,可以通过--host这个参数指定实际ip地址
visualdl --logdir vdl_dir/scalar/


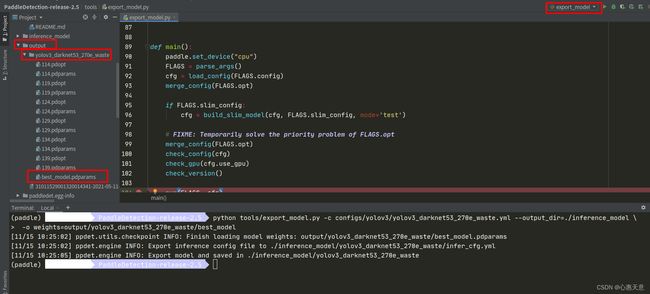
7、模型导出
在模型训练过程中保存的模型文件是包含前向预测和反向传播的过程,在实际的工业部署则不需要反向传播,因此需要将模型进行导成部署需要的模型格式。 在PaddleDetection中提供了 tools/export_model.py 脚本来导出模型
python tools/export_model.py -c configs/yolov3/yolov3_darknet53_270e_waste.yml --output_dir=./inference_model \
> -o weights=output/yolov3_darknet53_270e_waste/best_model
注意: weights=output/yolov3_darknet53_270e_waste/best_model 是指在weights=output/yolov3_darknet53_270e_waste/路径下有一个 best_model.pdparams的权重
我是将139.pdparams 重命名成 best_model.pdparams
终端运行:
 配置文件运行:
配置文件运行:
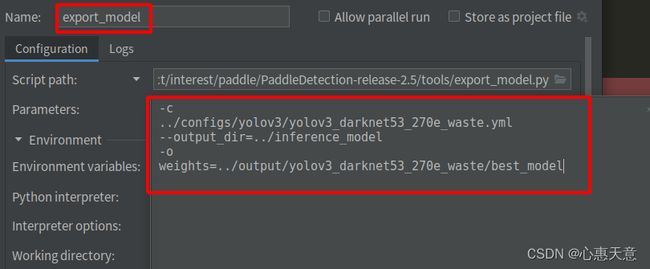
预测模型会导出到 inference_model/yolov3_darknet53_270e_waste 目录下,分别为 infer_cfg.yml, model.pdiparams, model.pdiparams.info,model.pdmodel 如果不指定文件夹,模型则会导出在 output_inference
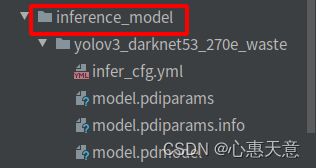
8、模型部署
python deploy/python/infer.py --model_dir=./inference_model/yolov3_darknet53_270e_waste --image_file=./demo/31011529001320014341-2021-05-11-15-22-55.892.jpg --device=GPU
注意: paddledetection官网上是model_dir=output_inference,但是如果自己指定路径的话,按照自己指定的路径填写
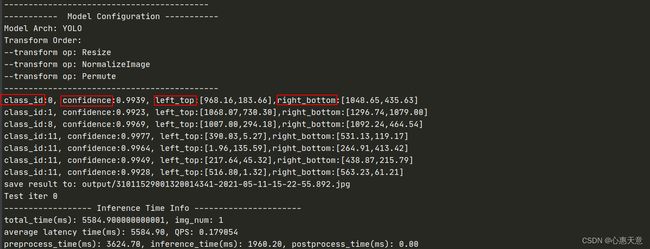
8.1 获得目标的类别,置信度和坐标
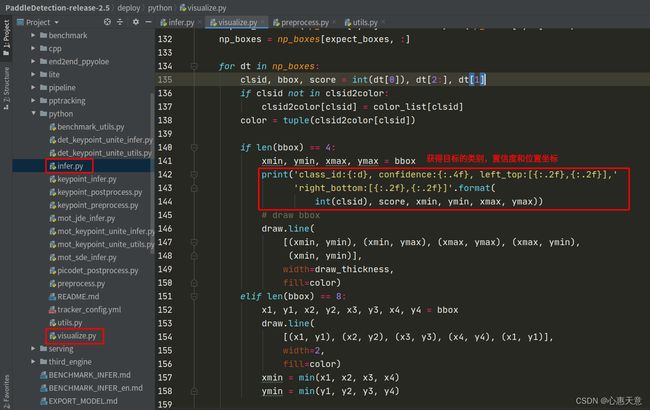
具体代码如下:
具体的code