Diffusion Model一发力,GAN就过时了???
金磊 Alex 发自 凹非寺
来源 | 量子位 QbitAI
曾经大红大紫的GAN已过时。
马里兰大学副教授Tom Goldstein最近发表的一个推文,可谓是一石激起千层浪。
就连科技圈的大佬们也纷纷前来关注:

话题里“剑指”的关键词则是Diffusion Model,用Tom的话来说就是:
在2021年,它甚至可以说是闻所未闻。
但其实这个算法并不陌生,因为它正是AI作画神器DALL·E的核心。
而且DALL·E的作者打一开始就“没看上”GAN,直接将其放弃。
无独有偶,同样的话题在国内也引发了不小的讨论:
那么图像生成领域的这波“后浪推前浪”,究竟是为何?
咱们这就来盘一盘。
什么是Diffusion Model?
Diffusion Model这次被拉进聚光灯之下,不得不归功于各类“AI一句话作图”神器的火爆。
例如OpenAI家的DALL·E 2:

谷歌家的Imagen:

不难看出,这些近期大流行的图像生成神器,不论是真实程度亦或是想象、理解能力,都是比较符合人类的预期。
因此它们也成为了这届网友们把玩的“新宠”(当年GAN出道的时候也是被玩坏了)。
而如此能力背后的关键,便是Diffusion Model。
它的研究最早可以追溯到2015年,当时,斯坦福和伯克利的研究人员发布了一篇名为Deep Unsupervised Learning using Nonequilibrium Thermodynamics的论文:

但这篇研究和目前的Diffusion Model非常不一样;而真正使其发挥作用的研究是2020年,一项名为Denoising Diffusion Probabilistic Models的研究:

我们可以先来看一下各类生成模型之间的对比:

不难看出,Diffusion Model和其它模型的不同点在于,它的latent code(z)和原图是同尺寸大小的。
若是简单来概括Diffusion Model,就是存在一系列高斯噪声(T轮),将输入图片x0变为纯高斯噪声xT。
再细分来看,Diffusion Model首先包含一个前向过程(Forward diffusion process)。
这个过程的目的,就是往图片上添加噪声;但在这一步中还无法实现图片生成。

其次是一个逆向过程(Reverse diffusion process),这个过程可以理解为Diffusion的去噪推断过程。
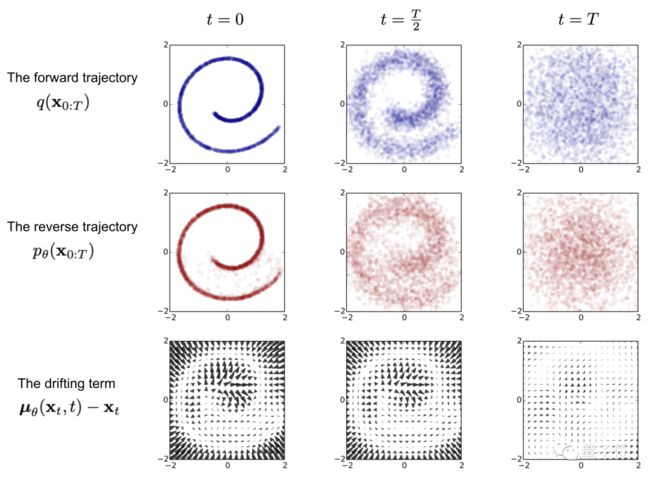
最后在训练阶段,则是通过对真实数据分布下,最大化模型预测分布的对数似然。
上述的过程是基于DDPM这项研究展开。
不过知乎用户“我想唱high C”(TSAIL博士)认为:
DDPM提出的时候,领域里的研究者其实并不完全清楚这个模型背后的数学原理,所以文章里的描述没有探寻到更本质的数学原理。
在他看来,直到斯坦福大学Yang Song等在Score-Based Generative Modeling through Stochastic Differential Equations中,才首次揭示了diffusion model的连续版本对应的数学背景。
并且将统计机器学习中的denoising score matching方法与DDPM中的去噪训练统一起来。

更多细节过程可以参考文末链接中的论文详情。
那么接下来需要探讨的一个问题是:
为什么GAN这么快会被取代?
用OpenAI的一篇论文内容来讲,用Diffusion Model生成的图像质量明显优于GAN模型。
DALL·E是个多模态预训练大模型,“多模态”和“大”字都说明,训练这个模型的数据集十分庞大冗杂。
发表这篇推特的Tom Goldstein教授提到,GAN模型训练过程有个难点,就是众多损失函数的鞍点(saddle-point)的最优权重如何确定,这其实是个蛮复杂的数学问题。

在多层深度学习模型的训练过程中,需通过多次反馈,直至模型收敛。
但在实际操作中发现,损失函数往往不能可靠地收敛到鞍点,导致模型稳定性较差。即使有研究人员提出一些技巧来加强鞍点的稳定性,但还是不足以解决这个问题。
尤其面对更加复杂、多样化的数据,鞍点的处理就变得愈加困难了。
与GAN不同,DALL·E使用Diffusion Model,不用在鞍点问题上纠结,只需要去最小化一个标准的凸交叉熵损失(convex cross-entropy loss),而且人已经知道如何使其稳定。
这样就大大简化了模型训练过程中,数据处理的难度。说白了,就是用一个新的数学范式,从新颖的角度克服了一道障碍。
此外,GAN模型在训练过程中,除了需要“生成器”,将采样的高斯噪声映射到数据分布;还需要额外训练判别器,这就导致训练变得很麻烦了。
和GAN相比,Diffusion Model只需要训练“生成器”,训练目标函数简单,而且不需要训练别的网络(判别器、后验分布等),瞬间简化了一堆东西。
目前的训练技术让Diffusion Model直接跨越了GAN领域调模型的阶段,而是直接可以用来做下游任务。

△Diffusion Model直观图
从理论角度来看,Diffusion Model的成功在于训练的模型只需要“模仿”一个简单的前向过程对应的逆向过程,而不需要像其它模型那样“黑盒”地搜索模型。
并且,这个逆向过程的每一小步都非常简单,只需要用一个简单的高斯分布(q(x(t-1)| xt))来拟合。
这为Diffusion Model的优化带来了诸多便利,这也是它经验表现非常好的原因之一。
Diffushion Model是否就是完美?
不见得。
从趋势上来看,Diffushion Model领域确实正处于百花齐放的状态,但正如“我想唱high C”所述:
这个领域有一些核心的理论问题还需要研究,这给我们这些做理论的人提供了个很有价值的研究内容。>
并且,哪怕对理论研究不感兴趣,由于这个模型已经很work了,它和下游任务的结合也才刚刚起步,有很多地方都可以赶紧占坑。我相信Diffusion Model的加速采样肯定会在不久的将来彻底被解决,从而让Diffusion Model占据深度生成模型的主导。
而对于Diffusion Model的有效性以及很快取代GAN这件事,马毅教授认为充分地说明了一个道理:
几行简单正确的数学推导,可以比近十年的大规模调试超参调试网络结构有效得多。
不过对于这种“前浪推后浪”的火热,马毅教授也有不一样的观点:
希望年轻的研究员端正研究的目的和态度,千万不要被目前热的东西忽悠。
包括Diffusion Process,这其实也是好几百年old的想法,只是老树发新芽,找到新的应用。
“我想唱high C”知乎回答:
https://www.zhihu.com/question/536012286/answer/2533146567
参考链接:
[1]https://twitter.com/tomgoldsteincs/status/1560334207578161152?s=21&t=QE8OFIwufZSTNi5bQhs0hQ
[2]https://www.zhihu.com/question/536012286
[3]https://arxiv.org/pdf/2105.05233.pdf
[4]https://arxiv.org/abs/1503.03585
[5]https://arxiv.org/abs/2006.11239
[6]https://arxiv.org/abs/2011.13456
[7]https://weibo.com/u/3235040884?topnav=1&wvr=6&topsug=1&is_all=1
— 完 —
高温暑热送清凉
HOT WEATHER COOL
