Detecting Deepfakes with Self-Blended Images翻译
摘要
在本文中,我们提出了一种称为自混合图像(SBI)的新型合成训练数据来检测深度伪造。SBI是通过从单个原始图像中混合伪造源图像和目标图像,再现常见的伪造伪迹(例如,混合边缘、源图像与目标图像之间的统计不一致性)。SBI背后的关键思想是,更通用且难以识别的假样本鼓励分类器学习泛化且健壮的表征,而不会过拟合于特定操作的伪迹。我们遵循标准交叉数据集和交叉操作协议,将我们的方法与在FF++、CDF、DFD、DFDC、DFDCP和FFIW数据集上的最新方法进行了比较。大量实验表明,我们的方法提高了模型对未知操做和陌生场景的泛化能力。特别是,在DFDC和DFDCP上,现有方法存在训练集和测试集之间的差距,我们的方法在交叉数据集评估上分别优于基线4.90%和11.78%。点击查看代码
1、引言
最近计算机视觉中生成对抗网络[11,26,32,33,46,52,64](GAN)的快速发展使得生成逼真的面部图像成为可能。特别是,被称为“深度伪造”的技术,它操做对象的身份、表情或属性,用于娱乐目的,例如智能手机应用程序或电影;然而,它们也可能被用于恶意目的,例如制造假新闻或伪造证据。因此,视觉界正在积极研究深度伪造检测技术。
大多数以前的检测方法[9,17,27,31,37,49,54,65]在数据集场景中表现良好,在该场景中,他们用他们在训练中学习到的技术来检测假货;然而,一些研究[16,22,34,62]发现,在未知操作伪造的假样本的交叉数据集场景中,检测性能显著下降。
这个问题最有效的解决方法是用合成数据来训练模型,这鼓励模型学习用于深度伪造检测的泛化表征。例如,模糊面部区域以复现GAN合成源图像的质量下降[42],从成对的两个原始图像上生成混合图像以再现混合伪迹[40,66]。然而,多年来随着深度伪造的质量的提高,这导致了以前的方法在最近的基准测试中的失败[43,53]。尽管后来的方法在一些数据集上表现良好,但是低质量视频在这些由于在高压缩或者极端曝光下产生了很难辨认的伪迹的富有挑战性的数据集上导致这些算法产生了不可接受的检测性能(降低)。

Figure 1. 假冒样本合成概述 以前的方法混合两个不同的脸,并基于选定的源图像和目标图像之间的差异生成伪影。相比之下,我们的方法混合了来自单个图像的稍微变化的脸,并通过变换主动生成伪影。在本例中,我们对源图像应用颜色抖动、锐化、调整大小和平移,而不对目标图像进行任何变换。

Figure 2. 伪造脸上的典型伪影我们将伪迹分为四种类型:(a)位置标志不匹配,(b)混合边界,(c)颜色不匹配,和(d)频率不一致。
在本文中,我们提出了一种称为自混合图像(SBI)的新型合成训练数据来检测深度伪造。我们的方法和以前的方法[40,66]的概述Fig. 1所示,关键思想是包含常见人脸伪造痕迹的更难以识别的假样本鼓励模型学习用于人脸伪造检测的更通用和鲁棒的表征。如Fig. 2所示,我们从以前的工作中分析了伪造的人脸,并定义了四种典型的伪迹(例如混合边界[40]、源特征不一致[66]和频域统计异常)。为了基于我们的关键思想合成这些伪迹,我们开发了源-目标生成器(STG)和掩模生成器(MG)。STG使用简单的图像处理从单个原始图像生成成对的伪源图像和目标图像,MG从输入图像的面部标志生成各种混合掩模。通过将源图像和目标图像与掩模混合,我们获得SBIs。使用SBI进行训练的模型鼓励学习泛化表征,因为模型学习我们在STG中主动生成的伪造痕迹。此外,我们的方法在计算成本方面提高了训练效率。尽管以前成功的工作[40,66]使用最近的位置标志搜索来选择源-目标对,但这在计算上是昂贵的,SBI的生成没有这个过程。因此,我们的方法不会遇到数据集大小的问题。
我们按照两种评估协议评估我们的方法: 交叉数据集评估和交叉操作评估。在交叉数据集评估中,我们在FF++[53]上训练我们的模型,并在CDF[43]、DFD[2]、DFDC[20]、DFDCP[21]和FFIW[68]上进行评估。这种实验设置类似于真实检测场景中的设置,其中防御者暴露在看不见的域中。尽管我们的方法很简单,但在所有测试集上,我们的方法都超过或至少可以与最先进的方法相媲美。特别是,在DFDC和DFDCP上,以前的方法在训练集和测试集之间存在领域差距,我们的方法分别优于最先进的无监督基线[66]4.90%和11.78%。在交叉操作评估中,我们评估了我们的模型在看不见操作方法的FF++的上的泛化性;在DF[4]、F2F[57]、FS[6]和NT[56]上,我们的方法在DF、F2F、FS和NT上分别达到99.99%、99.88%、99.91%和98.79%的AUC。尽管FF++上的性能已经饱和,但我们的方法在整个FF++上仍优于现有技术(99.64%对99.11%)。
2、相关工作
深度伪造检测 尽管已经介绍过了许多检测方法,但研究的主要主题是开发最佳神经网络架构(例如,高效的浅层网络[9]、多任务自动编码器[22,49]、胶囊网络[50]、递归卷积网络[27,54]和注意力网络[17,65])。一些研究[24,38,44,45,51]专注于频域,以更有效地捕获伪造痕迹。这些方法在高压缩的视频上实现了令人印象深刻的性能。另一个值得注意的方向是关注特定的表征(例如,头部姿势[63]、眨眼[31,41]、嘴巴动作[28]、神经元行为[61]、光流[10]和隐写分析特征[25])。面部X射线[40]引入了基于改变的面部和背景图像之间的边界的面部表征。PCL[66]测量输入图像的图像块之间的相似性,以检测源图像和目标图像之间的一致性。
训练数据合成 尽管大多数现有方法在检测已知操作方面表现良好,但一些研究[16,22,34,62]发现,这些方法不能泛化到由未知操作伪造的假脸上,因为它们往往会与训练中能够看到的特定方法的伪影过拟合。解决这一问题的最有效方法是使用合成数据训练模型;这鼓励模型学习人脸伪造检测的泛化特征。FWA[42]关注GAN合成脸和自然脸之间的质量差距,并通过模糊面部区域在真实图像上复现。然而,近年来,随着深度伪造技术的进步,这种方法无法在最近的基准点上检测出伪造点[2,53]。引入BI[40]和I2G[66]来生成混合脸,该混合脸从具有相似面部标志的两个原始图像对中再现混合伪影。
这些混合图片作为伪造样本能很好的用来训练更具泛化性的模型。然而,一些担忧仍然存在。首先,由于这些混合伪影取决于位置标志匹配所选择的源图像和目标图像对,因此有时会在生成的图像中看到不规则的交换[58]。这些简单的样本可能会阻止模型学习鲁棒的表征。第二,因为引入这些方法是为了学习定向表征,即BI中的混合边界和I2G中的源特征一致性,所以可能要学习用于鲁棒的深度伪造检测的伪影不足以仅用于混合图像中的伪影。
3、自混合图片(SBIs)
我们的目标是检测深度伪造上改变的人脸和背景图像之间的统计不一致性。为了训练更通用、更鲁棒的检测器,我们生成由常见的伪造痕迹组成的合成假样本,并且很难识别。我们的重点观察的是,如果深度伪造生成技术继续提高,GAN合成的源图像在其属性上将更接近原始目标图像,例如面部位置标志和像素统计。因此,我们开发了一种合成数据生成管道,其中通过混合来自单个图像的伪源图像和目标图像来生成伪图像,从而为模型提供更泛化和更困难的人脸伪造检测任务。
Figure 3. 生成一个SBI的概述 基础图像I被输入源目标生成器(STG)和掩模生成器(MG)。STG使用一些图像变换从基础图像生成伪源图像和目标图像,而MG从面部界标生成混合掩模并改变其形状以增加掩模的多样性。最后,将源图像和目标图像与掩模混合。

为了实现这一点,我们引入了自混合图像(SBI)。如图Fig. 3,所示,一个SBI由三个步骤生成;(1) 源-目标生成器生成用于混合的伪源和目标图像。源图像和目标图像被增强以在它们之间产生统计不一致(例如,颜色和频率)。源图像也会调整大小并平移,以再现混合边界和位置标志不匹配。(2) 掩模生成器生成具有一些变形的灰度掩模图像。(3) 我们用掩模将源图像和目标图像混合以获得SBI。尽管SBI生成的一般流程如Fig. 3所示,但我们在Alg. 1中显示了伪代码。其中为了训练效率伪代码中的处理过程和Fig. 3稍有不同(比如:在预处理中提取面部标志,但在训练中不提取)。无论数据集大小如何,我们生成伪样本的管道都具有恒定的运行时间,而之前的方法[40,66]由于源图像和目标图像的配对选择,在预处理中的运行时间为O(NK),其中N和K分别是视频数和每个视频的帧数。
3.1、源-目标生成器(STG)
给定输入图像I,STG通过复制I来初始化伪源图像和目标图像。为了在源图像与目标图像之间产生统计不一致性,STG将一些图像变换随机地应用于其中任何一个。这里,我们将输入图像的RGB通道、色调、饱和度、值、亮度和对比度的值作为颜色变换进行随机移位。然后我们将输入图像降采样或锐化为频率变换。
为了再现混合边界和位置标志不匹配,STG调整源图像的大小。设I的高度和宽度分别为H和W。我们定义调整后的图片的高度 H r H_r Hr和宽度 W r W_r Wr分别为 H r = u h H H_r = u_hH Hr=uhH和 W r = u w W W_r = u_wW Wr=uwW其中 u h 和 u w u_h 和 u_w uh和uw是从连续的范围为 [ u m i n , u m a x ] [u_{min}, u_{max}] [umin,umax]的均匀分布 U [ u m i n , u m a x ] U[u_{min}, u_{max}] U[umin,umax]中独立采样。调整图像大小采用零填充或中心裁切,以与原始图像具有相同的大小。然后,STG转换调整源图像大小。我们定义了一个转换向量 t = [ t h , t w ] t = [t_h, t_w] t=[th,tw]其中 t h = v h H , t w = v w W t_h = v_hH, t_w = v_wW th=vhH,tw=vwW。 v h 和 v w 独 立 采 样 于 U [ v m i n , v m a x ] . v_h和v_w独立采样于U[v_{min}, v_{max}]. vh和vw独立采样于U[vmin,vmax].
3.2、掩模生成器 (MG)
MG提供灰度掩模图像以混合源图像和目标图像。为此,MG将位置坐标检测器应用于输入图像以预测面部区域,并通过从预测的面部位置标志计算凸包来初始化掩模。然后用BI[40]中使用的位置标志变换使掩模变形。为了增加混合掩模的多样性,掩模的形状和混合比率是随机改变的。首先,掩模采用[66]中的弹性变形来变形。其次,通过两个具有不同参数的高斯滤波器对掩模进行平滑。第一次平滑后,小于1的像素值变为0。这意味着,如果第一个高斯滤波器的核大小大于第二个高斯滤波器,则掩模会被侵蚀,反之则会被扩展。最后,MG改变源图像的混合比率。这可以通过将掩模图像乘以常数r来实现,其中 r ∈ ( 0 , 1 ] r \in (0,1] r∈(0,1] 从{0.25,0.5,0.75,1,1,1}均匀采样r。
3.3、混合
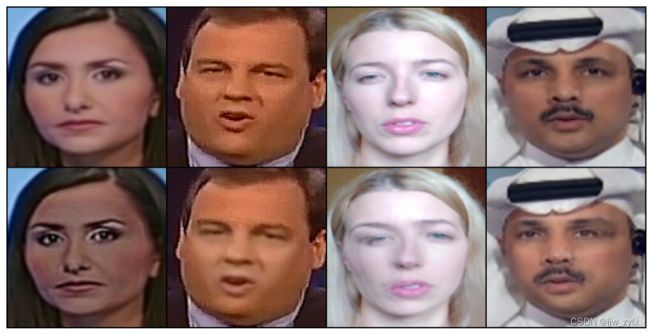
Figure 4. 原始图像的样本(顶行)及其对应的SBI(底行)。
通过使用混合掩模M混合源图像 I s I_s Is和目标图像 I t I_t It,我们获得自混合图像 I S B I_{SB} ISB: I S B = I s ⊙ M + I t ⊙ ( 1 − M ) . ( 1 ) I_{SB} = I_{s}\odot M + I_{t}\odot (1-M). \quad\quad\quad\quad\quad(1) ISB=Is⊙M+It⊙(1−M).(1)
我们在Fig. 4中展示了SBI的一些代表性示例。尽管SBI的目的不是造假,但它们包含伪迹能在伪造人脸上看出来。
3.4用SBIs训练
一旦生成了SBIs,我们就可以训练任何二进制分类器,无论它是否为深度伪造检测而设计。给定输入图像 X = [ x 0 , x 1 , ⋅ ⋅ ⋅ , x N − 1 ] X = [x_0, x_1, · · · , x_{N-1}] X=[x0,x1,⋅⋅⋅,xN−1]、大小为(N, H, W, 3),对应的二进制标签 T = [ t 0 , t 1 , ⋅ ⋅ ⋅ , t N − 1 ] T = [t_0, t_1, · · · , t_{N-1}] T=[t0,t1,⋅⋅⋅,tN−1],大小为N, 分类器F在二进制交叉熵损失L上优化如下:
L = − 1 N ∑ i = 0 N − 1 { t i log F ( x i ) + ( 1 − t i ) log ( 1 − F ( x i ) ) } , ( 2 ) L \!=\! - \frac {1}{N}\! \sum _{i=0}^{N-1} \{~\!t_i \log F(x_i) \!+\! (1\!-\!t_i) \log (1\!-\!F(x_i))\},\quad\quad\quad\quad\quad (2) L=−N1i=0∑N−1{ tilogF(xi)+(1−ti)log(1−F(xi))},(2)其中F(x)是x为假的概率。我们将目标图像输入为“真实”,而不是使用基础图像来鼓励模型只关注SBI上的伪影。由于MG提供了混合掩码,我们还可以采用基于掩码的多任务学习[40,49,66]。
4、实验
4.1、实现细节
预处理 我们采用Dlib[35]和RetinaFace[19]分别从每个视频帧中提取面部标志和边界框。我们在Dlib中使用了81个面部标志形状预测器[1]。对于从边界框计算脸的宽度和高度,将以4–20%的随机边距裁剪面部区域以进行训练,以12.5%的固定值进行推理。注意,在推断过程中不需要位置标记;因此我们在推断时仅使用RetinaFace。
源目标增强 对于颜色和频率变换,我们采用了广泛使用的图像处理工具箱中的RGBShift、HueSaturationValue、RandomBrightnessContrast、Downscale和Sharpen[12]。
训练 我们在ImageNet[18] 上采用最先进的预训练卷积网络架构EfficientNet-b4[55](EFNB4)作为分类器,并使用SAM[23]优化器对其进行100个轮的训练。批量大小和学习率分别设置为32和0.001。我们每个视频只采样八帧进行训练。如果在一个帧中检测到两个或多个脸,则会提取具有最大边界框的脸。每一批都由真实图像及其SBIs组成,并且每个真实图像及其SBI都用相同的增强。我们还使用了一些数据增强,例如ImageCompression、RGBShift、HueSaturationValue和RandomBrightnessContrast。
模型验证 考虑到实际情况,在没有附加评估数据集的情况下验证模型是很重要的。我们使用一个验证集,该验证集由真实视频及其每轮后的SBIs组成,并在AUC最高的五个权重周期中选择权重最高的。因此,在我们的方法中,即使是模型验证,也没有操作图像。
推理策略 我们对每个视频采样32帧进行推断。如果在一个帧中检测到两个或多个人脸,则分类器对所有人脸做预测,并且将伪造置信度最高的作为该帧的预测置信度。一旦获得了所有帧的预测,我们就对它们进行平均来获得视频的预测。为了公平比较,我们使用所有测试集的所有视频进行评估,将所有帧中未检测到人脸的视频的置信度设置为0.5。
4.2、实验设置
数据集 按照惯例,我们采用广泛使用的基准FaceForensics++[53](FF++)进行训练。它包含1000个原始视频和4000个通过四种操作方法伪造的假视频,即Deep fakes[4](DF)、Face2Face[57](F2F)、Face Swap[6](FS)和NeuralTextures[56](NT)。对于我们的交叉数据集验证,我们使用了五个最近的深度伪造数据集。Celeb DF v2[43](CDF)将更先进的深度伪造技术应用到从YouTube下载的名人视频上。Deep FakeDetection[2](DFD)提供了经演员同意生成的几千个深度伪造视频。与比赛[3]一起发布的DeepFake Detection Challenge Preview [21] (DFDCP) 和 DeepFake Detection Challenge开源测试集[20](DFDC)包含大量干扰视频,例如压缩、下采样和噪声。我们进一步在最近的大规模基准FFIW-10K[68](FFIW)上提供了一个新的交叉数据集基线,该基准侧重于多人场景。我们按照官方的训练/测试方法分割所有数据集(除了FFIW),因为官方测试集尚未发布,所以我们使用原始验证集作为测试集。尽管FaceShifter[39]和DeeperForensic-1.0[30]提供了复杂的深度伪造视频,但我们在交叉数据集评估中没有采用它们,因为它们从FF++的真实视频中生成深度伪造的视频,这与训练中使用的相同。有关更多统计信息,请参见补充材料。
帧级基线 我们参考了五种目前最好的帧级检测方法,包括:(1)DSP FWA[42]提出了一种基于GAN合成源图像质量退化的训练数据生成方法。(2) 面部X射线[40]通过分割源图像和目标图像之间的混合边界来检测深度伪造。该模型是用称为BI的合成假样本来训练的,这些假样本是混合来自不同视频的两个图像生成。(3) 局部关系学习[14](LRL)和(4)Fusion + RSA + DCMA + Multi-scale [45] (FRDM)融合了来自RGB和频域的两种不同表征。(5) Pair-wise self-consistency learning [66] (PCL) 通过测量输入图像块之间的一致性来检测深度伪造。使用与BI[40]类似的不一致图像生成器(I2G)训练模型。
视频级基线 我们进一步将我们的方法与视频级方法进行了比较,这些方法为一些视频帧输出个伪造得分。与帧级方法不同,视频级方法可以检测跨帧的不连贯性,尽管它们需要在一定的间隔内拍摄多帧对象。我们参考了四种最先进的方法,包括:(1)Two-branch[48]提出了高斯核的拉普拉斯方法来增强输入图像的频率分量。(2)Discriminative attention model[68] (DAM)提出了一种用于多人场景的基于注意力[60]的网络。(3) LipForensics [28]使用预训练的唇读模型检测嘴的动作的时间不一致性[47]。(4) Fully temporal convolution network [67] (FTCN) 通过将卷积的空间核大小减小到1来增强时间表征。
评估指标 我们报告了与以前的工作做了比较,是在视频级下对比了ROC曲线下的面积(AUC)。通常,帧级预测平均高于视频帧。我们在补充材料中还提供了平均精度(AP)。
4.3、交叉数据集评估
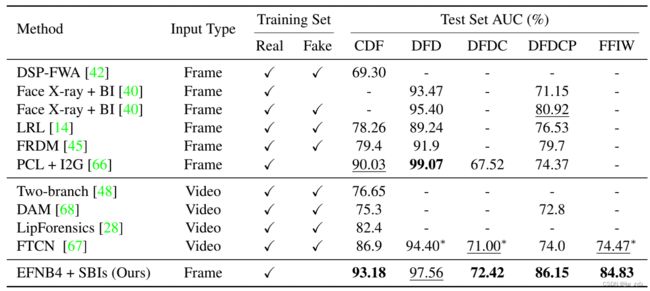
Table 1.在CDF、DFD、DFDC、DFDCP和FFIW数据集上的交叉数据集评估 先前方法的结果直接引自原始论文及其子序列,以进行公平比较。粗体值和下划线值分别对应于最佳值和次最佳值。表示我们用官方代码进行的实验。我们的方法在CDF、DFDC、DFDCP和FFIW方面优于目前最好的方法,并且在DFD上取得了第二好的成绩,并且没有使用任何用于深度伪造检测的特殊网络架构。
为了展示我们的方法的通用性,我们进行了交叉数据集评估,其中模型在FF++上进行训练,并在其他数据集上进行评估。尽管许多研究人员都考虑过这项任务,但他们每个人在实验中使用的测试集因工作而异,因此很难进行全面的比较。因此,我们仔细检查了先前工作中的实验设置,并将其编入Table 1。
帧级方法比较 这里,我们将我们的方法与其他帧级方法[14,40,42,45,66]进行了比较。我们的方法在CDF、DFDC和DFDCP上分别优于目前最好的方法6.08%、5.17%和5.23%,平均提高基线4.58%(87.33%vs82.75%)。我们的结果与DFD上的PCL+I2G[66](97.56%对99.07%)相当,其中伪造脸有时与其他原始脸一起放置在操做帧中,并且对象在整个操作视频中的帧数百分比小于其他测试集。因此,我们的方法可以通过将任何对象跟踪过程结合到我们的推理策略中来改进,如PCL+I2G[66],而不是像我们的简单策略那样以相等的间隔从视频中提取帧。
视频级方法比较 我们将我们的方法与视频级方法进行了比较[28,48,67,68]。为了进行更全面的比较,我们在未考虑的测试集上对FTCN[67]进行了额外的实验,即DFD、DFDC和FFIW,并使用官方开源的代码[7]。结果如Table 1中的所示。我们的方法在CDF、DFD、DFDC、DFDCP和FFIW方面仍分别优于现有技术6.28%、3.16%、1.42%、12.15%和10.36%,并平均提高了6.68%的基线(86.83%对80.15%)。我们还对用于LipForensics实验的DFDC子集进行了评估[28],优于竞争对手(76.78%对73.5%)。视频列表可在作者的仓库中找到[8]。
4.4、交叉操做评估
在真实的检测场景中,防御者通常不知道攻击者的伪造方法。因此,验证模型对各种伪造方法的泛化能力是很重要的。按照[40,66]中使用的评估协议,我们对FF++的四种操作方法(即DF、F2F、FS和NT)进行了评估。我们使用原始版本和竞争对手进行评估。

Table 2.在FF++上的交叉操作评估 我们的方法在 F2F, FS, NT上和在整个 FF++上达到了目前最好的成绩。
Table 2给出了我们对FF++的交叉操作评估结果。我们的方法在四种操作(DF上的99.99%、F2F上的99.88%、FS上的99.91%和NT上的98.79%)上优于或几乎等于现有方法,并且在整个FF++上达到了最好(99.64%对99.11%)。该结果表明,我们的方法不仅适用于深度伪造,而且适用于其他脸部操作。
4.5、数据质量评估

Table 3.AUC与BI的比较[40]

Table 4.AUC与I2G 的比较[66]
这里,我们将我们的方法与目前最好的合成训练数据[40,66]进行了比较,消除了分类器差异的影响。为了实现这一点,我们训练了与竞争对手在其原始论文中使用的相同的模型和优化器。Table 3给出了与BI[40]的比较。我们使用Adam[36]优化器训练Xception[15]。就AUC而言,我们的方法和在FF++上的所有操作方法上都优于BI[40]。特别是,FS基线从89.29%提高到98.79%。接下来,Table 4给出了与I2G[66]的比较结果。我们使用Adam优化器训练ResNet-34[29]。我们的方法在CDF、DFDC和DFDCP上的表现都优于I2G[66],并且平均分别高于8.86%, 14.69%, 12.23%, and 11.93%个百分点。这些结果清楚地表明,无论网络架构如何,我们的方法都优于竞争对手的合成训练数据。
4.6、消融

Table 5.STG每个步骤的效果 跳过任何步骤都会导致严重的性能下降。
STG每个步骤的效果 在STG中,我们使用一些图像处理来生成伪,源和目标图像。相反,由于学习到的表征是基于我们在STG中积极提供的伪迹,因此生成过程的消融实验能够探索深度伪造基准上的有效线索。在这里,我们训练我们的模型,在这个训练过程中没有做其他的处理即:源增强、目标增强、源目标增强或调整大小和平移变换,并在FF++、CDF、DFDCP和FFIW上进行评估。如Table 5所示,源和目标增强在检测深度伪造方面确实有效,而且两者都是提高性能所必需的。我们还观察到,调整大小和平移会复现重要的伪迹,因为没有它们时性能很差。通过消融实验,可以得出结论,在不同的数据集上不同的线索对检测器来说是有用的,因为它们具有不同的深度伪造生成过程。

Table 6.在不同训练数据集上的性能 我们的方法在每个训练数据集上都有很好的结果, “#Real”代表训练数据集真视频的数量、不包括验证集的真视频数。
训练数据集概述 从实际角度来看,证明我们的方法可以在各种真实人脸数据集上表现良好。我们在这里使用FF++、CDF、DFDCP和FFIW的原始视频中的SBI训练模型。然后我们在测试集上评估它们。在CDF和FFIW上,我们将原始训练集拆分为alter native训练/验证集。Table 6 给出了结果。我们的方法能泛化到所有数据集,而没有严重的性能下降。我们观察到大的FFIW数据集有助于模型的泛化性。然而,FFIW和DFDCP之间的视频场景差异导致DFDCP的性能略有下降;FFIW包含的视频是从YouTube收集的,而DFDCP包含的视频是从招募对象得到的。结果还表明,学习原始视频可以帮助检测和训练相同区域的伪造人脸,即使模型没有学习操做视频,如表6中棕色突出显示的分数所示,这支持我们在交叉数据集评估中不采用FaceShifter[39]和DeeperForensic-1.0[30],如第4.2节所提到的。
 Table 7.不同网络架构的性能 具有更大容量的架构往往具有更好的泛化性。
Table 7.不同网络架构的性能 具有更大容量的架构往往具有更好的泛化性。
网络架构的选择 尽管我们采用EfficientNet-b4[55]作为标准分类器,但我们的方法也可以应用于其他网络架构。在这里,我们研究了不同目前最好的架构的性能,即ResNet-50、-152[29]、Xception[15]、EfficientNet-b1和-b4[55],这些架构都使用SBI进行训练。如表Table 7所示,所有架构在FF++、CDF、DFDCP和FFIW上都取得了良好的结果,而没有严重的性能下降。值得注意的是,即使是我们使用普通的ResNet-50,其在CDF、DFDCP和FFIW上的表现也优于所有以前的方法,如Tables 1 和 7所示。我们观察到,更大的网络往往导致更大的通用性,这表明SBI提供了多种训练样本。
4.7、定性分析
为了获得定性见解,我们可视化模型的特征图和特征空间。通过分析,我们使用了两个模型;一个在FF++(基线)上训练,另一个在SBI(我们的模型)上训练。
Figure 5. 基线模型和我们的模型的显著性可视化图 基线捕获特定方法的伪迹是广泛分布在交叉伪脸上的,而我们的模型检测的是与操做无关的次要伪影。
显著性图 为了可视化模型将注意力放在了伪造脸上,在 FF++的操作帧上我们将Grad CAM++[13]应用到模型上,即DF、F2F、FS和NT,如图5所示。可以观察到,我们的方法鼓励模型使其注意力比基线稀疏。这是因为我们的模型检测微小的伪迹不依赖与操作,例如混合边界,而基线捕获特定方法的像素分布是广泛分布在伪造脸中的。
Figure 6. 基线模型(a)和我们的模型(b)的特征空间可视化 基线无法区分真实图像和SBI(因为特征向量落入相同的特征空间),而我们的模型不仅成功区分真实图像与SBI,还成功区分伪造图像。
特征空间 我们使用t-SNE[59]可视化模型最后一层的特征向量。我们再次强调,基线很容易识别伪造的人脸,因为它们在训练中可以看到,我们的目标是将真实的人脸与其他人脸区分开来,而不是对操作类型进行分类。如图6所示,基线无法从真实图像区分SBI,尽管在训练中它能看到4中操作,另一方面,我们的模型不仅能区分SBI,还能区分伪造的人脸和真实的人脸。我们还观察到,SBI分布在特征空间中的四个操作上。这些结果表明,SBI是通用合成数据用来训练脸伪造检测器。
5、局限性
尽管我们的结果在交叉数据集和交叉操作评估中是较好的,但我们观察到了我们方法的一些局限性。首先,与其他帧级方法类似,我们的模型无法捕获视频帧之间的时间不一致。因此,具有较少空间伪迹的复杂深度伪造生成技术可能会通过我们的检测器。此外,我们的方法在整个图像合成中表现不佳,因为我们将“假图像”定义为操做过的脸部区域或背景的图像。我们在从FFHQ数据集和Style GAN[33]合成的数据集中采样的20k图像集上评估我们的模型,其AUC仅为69.11%。
6、结论
在本文中,我们提出了一种新的合成训练数据,即自混合图像(SBI),基于这样一种思想,即更一般和难以识别的假样本鼓励分类器学习更泛化和鲁棒的表征。SBI是通过混合伪造的源图像和目标图像来生成的,这些伪造的源图像与目标图像是从单个真实图像稍微变换来再现伪造伪迹的。使用SBI,我们可以训练没有伪造人脸图像的探测器。大量实验表明,在看不见的操做和场景中,我们的方法优于目前最好的方法,并能泛化到不同的网络架构和训练数据集中。