NNDL 实验六 卷积神经网络(5) 使用预训练resnet18实现CIFAR-10分类
目录
5.5实践:基于ResNet18网络完成图像分类任务
5.5.1 数据处理
5.5.1.1 数据集介绍
5.5.1.2 数据读取
5.5.2 模型构建
1.什么是“预训练模型”?什么是“迁移学习”?(必做)
2.比较“使用预训练模型”和“不使用预训练模型”的效果。(必做)
5.5.3 模型训练
5.5.4 模型评价
5.5.5 模型预测
思考题
1.阅读《Deep Residual Learning for Image Recognition》,了解5种深度的ResNet(18,34,50,101和152),并简单谈谈自己的看法。
2.用自己的话简单评价LeNet、AlexNet、VGG、GoogLeNet、ResNet(选做)
参考文献
5.5实践:基于ResNet18网络完成图像分类任务
在本实践中,我们实践一个更通用的图像分类任务。
图像分类(Image Classification)是计算机视觉中的一个基础任务,将图像的语义将不同图像划分到不同类别。很多任务也可以转换为图像分类任务。比如人脸检测就是判断一个区域内是否有人脸,可以看作一个二分类的图像分类任务。
- 数据集:CIFAR-10数据集,
- 网络:ResNet18模型,
- 损失函数:交叉熵损失,
- 优化器:Adam优化器,Adam优化器的介绍参考NNDL第7.2.4.3节。
- 评价指标:准确率。
5.5.1 数据处理
5.5.1.1 数据集介绍
CIFAR-10数据集包含了10种不同的类别、共60,000张图像,其中每个类别的图像都是6000张,图像大小均为32×3232×32像素。CIFAR-10数据集的示例如下图所示。

5.5.1.2 数据读取
在本实验中,将原始训练集拆分成了train_set、dev_set两个部分,分别包括40 000条和10 000条样本。将data_batch_1到data_batch_4作为训练集,data_batch_5作为验证集,test_batch作为测试集。
最终的数据集构成为:
- 训练集:40 000条样本。
- 验证集:10 000条样本。
- 测试集:10 000条样本。
读取一个batch数据的代码如下所示:
import os
import pickle
import numpy as np
def load_cifar10_batch(folder_path, batch_id=1, mode='train'):
if mode == 'test':
file_path = os.path.join(folder_path, 'test_batch')
else:
file_path = os.path.join(folder_path, 'data_batch_'+str(batch_id))
# 加载数据集文件
with open(file_path, 'rb') as batch_file:
batch = pickle.load(batch_file, encoding = 'latin1')
imgs = batch['data'].reshape((len(batch['data']),3,32,32)) / 255.
labels = batch['labels']
return np.array(imgs, dtype='float32'), np.array(labels)
imgs_batch, labels_batch = load_cifar10_batch(folder_path='C:\\Users\\PycharmProjects\\pythonProject\\cifar-10-batches-py', batch_id=1, mode='train')查询数据维度
# 打印一下每个batch中X和y的维度
print("batch of imgs shape: ",imgs_batch.shape, "batch of labels shape: ", labels_batch.shape)结果
batch of imgs shape: (10000, 3, 32, 32) batch of labels shape: (10000,)
可视化观察其中的一张样本图像和对应的标签,代码如下:
# 打印一下每个batch中X和y的维度
print("batch of imgs shape: ", imgs_batch.shape, "batch of labels shape: ", labels_batch.shape)
import matplotlib.pyplot as plt
image, label = imgs_batch[2], labels_batch[2]
print("The label in the picture is {}".format(label))
plt.figure(figsize=(2, 2))
plt.imshow(image.transpose(1, 2, 0))
plt.savefig('cnn.pdf')
The label in the picture is 9
数据集划分:
class CIFAR10Dataset(Dataset):
def __init__(self, folder_path='./cifar10/cifar-10-batches-py', mode='train'):
if mode == 'train':
self.imgs, self.labels = load_cifar10_batch(folder_path=folder_path, batch_id=1, mode='train')
for i in range(2, 5):
imgs_batch, labels_batch = load_cifar10_batch(folder_path=folder_path, batch_id=i, mode='train')
self.imgs, self.labels = np.concatenate([self.imgs, imgs_batch]), np.concatenate(
[self.labels, labels_batch])
elif mode == 'dev':
self.imgs, self.labels = load_cifar10_batch(folder_path=folder_path, batch_id=5, mode='dev')
elif mode == 'test':
self.imgs, self.labels = load_cifar10_batch(folder_path=folder_path, mode='test')
self.transform = transforms.Compose(
[transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])
def __getitem__(self, idx):
img, label = self.imgs[idx], self.labels[idx]
img = img.transpose(1, 2, 0)
img = self.transform(img)
return img, label
def __len__(self):
return len(self.imgs)
train_dataset = CIFAR10Dataset(folder_path='./cifar10/cifar-10-batches-py', mode='train')
dev_dataset = CIFAR10Dataset(folder_path='./cifar10/cifar-10-batches-py', mode='dev')
test_dataset = CIFAR10Dataset(folder_path='./cifar10/cifar-10-batches-py', mode='test')
5.5.2 模型构建
使用pyotorch高层API中的resnet18进行图像分类实验。
from torchvision.models import resnet18
resnet18_model = resnet18()1.什么是“预训练模型”?什么是“迁移学习”?(必做)
预训练模型:预训练模型是深度学习架构,已经过训练以执行大量数据上的特定任务(例如,识别图片中的分类问题)。这种训练不容易执行,并且通常需要大量资源,超出许多可用于深度学习模型的人可用的资源,我就没有大批次GPU。在谈论预训练模型时,通常指的是在Imagenet上训练的CNN(用于视觉相关任务的架构)。ImageNet数据集包含超过1400万个图像,其中120万个图像分为1000个类别(大约100万个图像含边界框和注释)。
迁移学习:迁移学习是一种机器学习方法,就是把为任务 A 开发的模型作为初始点,重新使用在为任务 B 开发模型的过程中。
2.比较“使用预训练模型”和“不使用预训练模型”的效果。(必做)
resnet = models.resnet18(pretrained=True)
resnet = models.resnet18(pretrained=False)
5.5.3 模型训练
复用RunnerV3类,实例化RunnerV3类,并传入训练配置。
使用训练集和验证集进行模型训练,共训练30个epoch。
在实验中,保存准确率最高的模型作为最佳模型。代码实现如下:
import torch.nn.functional as F
import torch.optim as opt
from nndl import RunnerV3, Accuracy
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)
lr = 0.001
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
dev_loader = DataLoader(dev_dataset, batch_size=batch_size)
test_loader = DataLoader(test_dataset, batch_size=batch_size)
model = resnet18_model
model.to(device)
optimizer = opt.SGD(model.parameters(), lr=lr, momentum=0.9)
loss_fn = F.cross_entropy
metric = Accuracy()
runner = RunnerV3(model, optimizer, loss_fn, metric)
log_steps = 3000
eval_steps = 3000
runner.train(train_loader, dev_loader, num_epochs=30, log_steps=log_steps, eval_steps=eval_steps, save_path="best_model.pdparams")运行结果
cpu
[Train] epoch: 0/30, step: 0/18750, loss: 6.97701
[Train] epoch: 4/30, step: 3000/18750, loss: 0.85450
[Evaluate] dev score: 0.60330, dev loss: 1.16656
[Evaluate] best accuracy performence has been updated: 0.00000 --> 0.60330
[Train] epoch: 9/30, step: 6000/18750, loss: 0.29281
[Evaluate] dev score: 0.62940, dev loss: 1.44578
[Evaluate] best accuracy performence has been updated: 0.60330 --> 0.62940
[Train] epoch: 14/30, step: 9000/18750, loss: 0.17818
[Evaluate] dev score: 0.63910, dev loss: 1.70278
[Evaluate] best accuracy performence has been updated: 0.62940 --> 0.63910
[Train] epoch: 19/30, step: 12000/18750, loss: 0.02657
[Evaluate] dev score: 0.64540, dev loss: 1.80198
[Evaluate] best accuracy performence has been updated: 0.63910 --> 0.64540
[Train] epoch: 24/30, step: 15000/18750, loss: 0.04895
[Evaluate] dev score: 0.63760, dev loss: 2.00975
[Train] epoch: 28/30, step: 18000/18750, loss: 0.02457
[Evaluate] dev score: 0.64760, dev loss: 2.08300
[Evaluate] best accuracy performence has been updated: 0.64540 --> 0.64760
[Evaluate] dev score: 0.63870, dev loss: 2.08529
[Train] Training done!可视化观察训练集与验证集的准确率及损失变化情况。
def plot(runner, fig_name):
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
train_items = runner.train_step_losses[::30]
train_steps = [x[0] for x in train_items]
train_losses = [x[1] for x in train_items]
plt.plot(train_steps, train_losses, color='#8E004D', label="Train loss")
if runner.dev_losses[0][0] != -1:
dev_steps = [x[0] for x in runner.dev_losses]
dev_losses = [x[1] for x in runner.dev_losses]
plt.plot(dev_steps, dev_losses, color='#E20079', linestyle='--', label="Dev loss")
# 绘制坐标轴和图例
plt.ylabel("loss", fontsize='x-large')
plt.xlabel("step", fontsize='x-large')
plt.legend(loc='upper right', fontsize='x-large')
plt.subplot(1, 2, 2)
# 绘制评价准确率变化曲线
if runner.dev_losses[0][0] != -1:
plt.plot(dev_steps, runner.dev_scores,
color='#E20079', linestyle="--", label="Dev accuracy")
else:
plt.plot(list(range(len(runner.dev_scores))), runner.dev_scores,
color='#E20079', linestyle="--", label="Dev accuracy")
# 绘制坐标轴和图例
plt.ylabel("score", fontsize='x-large')
plt.xlabel("step", fontsize='x-large')
plt.legend(loc='lower right', fontsize='x-large')
plt.savefig(fig_name)
plt.show()
plot(runner, fig_name='cnn-loss4.pdf')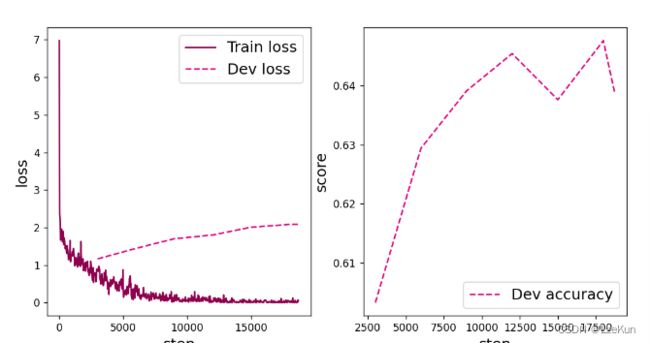
在本实验中,使用了第7章中介绍的Adam优化器进行网络优化,如果使用SGD优化器,会造成过拟合的现象,在验证集上无法得到很好的收敛效果。可以尝试使用第7章中其他优化策略调整训练配置,达到更高的模型精度。
5.5.4 模型评价
使用测试数据对在训练过程中保存的最佳模型进行评价,观察模型在测试集上的准确率以及损失情况。代码实现如下:
# 加载最优模型
runner.load_model('best_model.pdparams')
# 模型评价
score, loss = runner.evaluate(iter(test_loader))
print("[Test] accuracy/loss: {:.4f}/{:.4f}".format(score, loss))结果
[Test] accuracy/loss: 0.7270/1.82125.5.5 模型预测
同样地,也可以使用保存好的模型,对测试集中的数据进行模型预测,观察模型效果,具体代码实现如下:
#获取测试集中的一个batch的数据
X, label = next(iter(test_loader))
X = X.cpu()
logits = runner.predict(X)
#多分类,使用softmax计算预测概率
pred = F.softmax(logits)
#获取概率最大的类别
pred_class = torch.argmax(pred[2]).numpy()
print(label[2].numpy())
label = label[2].numpy()
#输出真实类别与预测类别
print("The true category is {} and the predicted category is {}".format(label, pred_class))
#可视化图片
plt.figure(figsize=(2, 2))
imgs, labels = load_cifar10_batch(folder_path='C:\\Users\\崔嘉诚\\PycharmProjects\\pythonProject\\cifar-10-batches-py', mode='test')
plt.imshow(imgs[2].transpose(1,2,0))
plt.savefig('cnn-test-vis.pdf')The true category is 8 and the predicted category is 8思考题
1.阅读《Deep Residual Learning for Image Recognition》,了解5种深度的ResNet(18,34,50,101和152),并简单谈谈自己的看法。
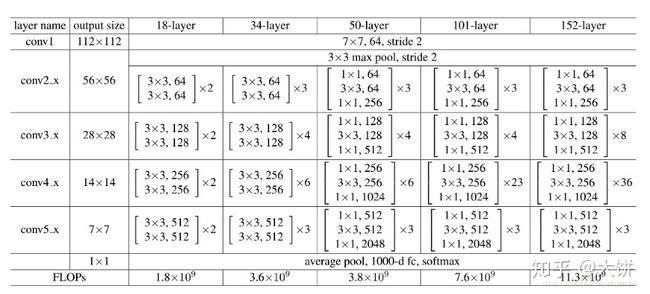
上面是5种深度的ResNet,分别是18,34,50,101和152,拿ResNet50来看:第一层为7x7x64的卷积,然后是3+4+6+3=16个building block,每个block为3层,所以有16x3=48层。最后有个fc层,所以总共为1+1+48=50层。
左边的残差结构是针对层数较少的网络,例如ResNet18层和ResNet34层网络。右边的是针对网络层数较多的网络,例如ResNet101,ResNet152等。
深层网络使用右侧的残差结构能够减少网络参数与运算量。
同样输入一个channel为256的特征矩阵,如果使用左侧的残差结构,需要大约1170648个参数,使用右侧的残差结构只需要69632个参数。明显搭建深层网络时,使用右侧的残差结构更合适。
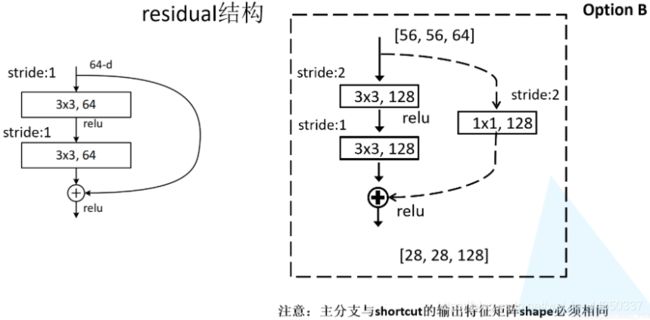
如上图ResNet34网络结构中存在虚线的残差结构。虚线的残差结构具有降维的作用,并在捷径分支上通过1x1的卷积核进行降维处理。注意步距stride,以及捷径分支上的卷积核的个数(与主分支上的卷积核个数相同)
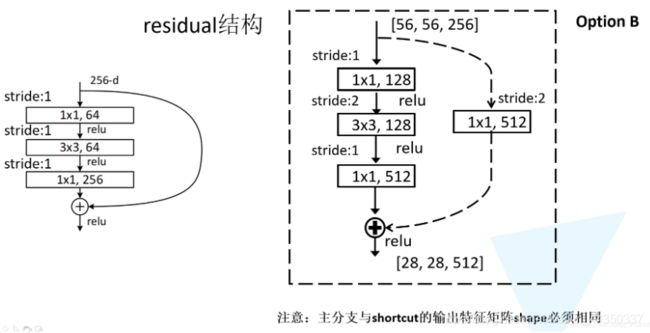
针对ResNet50/101/152的残差结构如上图。在该残差结构中,主分支使用了三个卷积层。
第一层使用1x1的卷积层来压缩channel维度,第二层是3x3卷积层,第三层是1x1的卷积层用来还原channel维度(注意主分支上第一层卷积层和第二次卷积层所使用的卷积核个数是相同的,第三次是第一层的4倍)。
该残差结构所对应的虚线残差结构如下图右侧所示,同样在捷径分支上有一层1x1的卷积层,它的卷积核个数与主分支上的第三层卷积层卷积核个数相同,注意每个卷积层的步距。
2.用自己的话简单评价LeNet、AlexNet、VGG、GoogLeNet、ResNet(选做)
LeNet:
LeNet-5(-5表示具有5个层)是一种用于手写体字符识别的非常高效的卷积神经网络。其结构:输入的二维图像,先经过两次卷积层到池化层,再经过全连接层,最后使用softmax分类作为输出层,LeNet-5包含七层。LeNet-5跟现有的conv->pool->ReLU的套路不同,它使用的方式是conv1->pool->conv2->pool2再接全连接层,但是不变的是,卷积层后紧接池化层的模式依旧不变。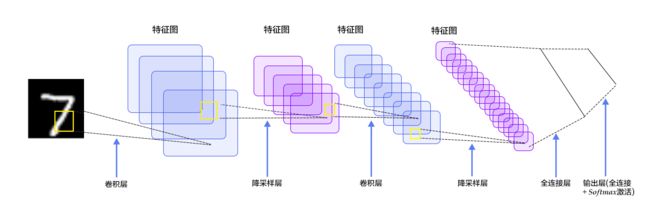
AlexNet:
AleXNet使用了ReLU方法加快训练速度,并且使用Dropout来防止过拟合,通过多GPU的训练降低训练时间。
AleXNet (8层) 是首次把卷积神经网络引入计算机视觉领域并取得突破性成绩的模型。
和之前的LeNet相比,AlexNet通过堆叠卷积层使得模型更深更宽,同时借助GPU使得训练再可接受的时间范围内得到结果,推动了卷积神经网络甚至是深度学习的发展。
AlexNet的论文中着重解释了Tanh激活函数和ReLu激活函数的不同特点,解释了多个GPU是如何加速训练网络的,也说明了防止过拟合的一些方法。
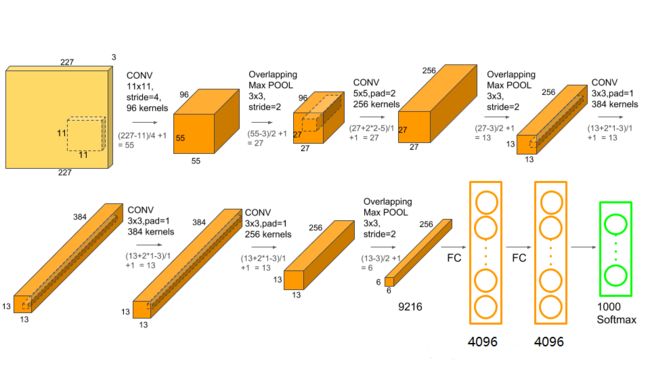
AlexNet总共有6230万个参数(大约),一次前馈计算需要11亿的计算。这里的卷积参数实际只有370万,只占6%左右,但是消耗了95的计算量。
VGG:
VGG中根据卷积核大小和卷积层数目的不同,可分为A,A-LRN,B,C,D,E共6个配置(ConvNet Configuration),其中以D,E两种配置较为常用,分别称为VGG16和VGG19。
VGG有A,A-LRN,B,C,D,E6种配置
- A:是最基本的模型,8个卷基层,3个全连接层,一共11层。
- A-LRN:忽略
- B:在A的基础上,在stage1和stage2基础上分别增加了1层3X3卷积层,一共13层。
- C:在B的基础上,在stage3,stage4和stage5基础上分别增加了一层1X1的卷积层,一共16层。
- D:在B的基础上,在stage3,stage4和stage5基础上分别增加了一层3X3的卷积层,一共16层。
- E:在D的基础上,在stage3,stage4和stage5基础上分别增加了一层3X3的卷积层,一共19层。
以VGG16为例
13个卷积层(Convolutional Layer),分别用conv3-XXX表示
3个全连接层(Fully connected Layer),分别用FC-XXXX表示
5个池化层(Pool layer),分别用maxpool表示
其中,卷积层和全连接层具有权重系数,因此也被称为权重层,总数目为13+3=16,这即是VGG16中16的来源。(池化层不涉及权重,因此不属于权重层,不被计数)。
GoogleNet:
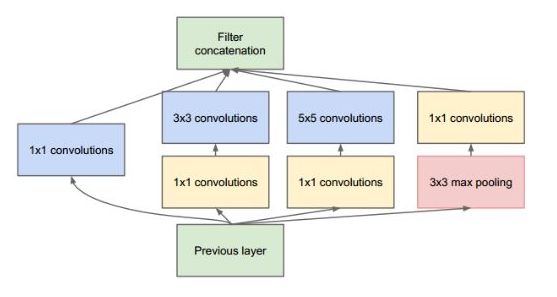
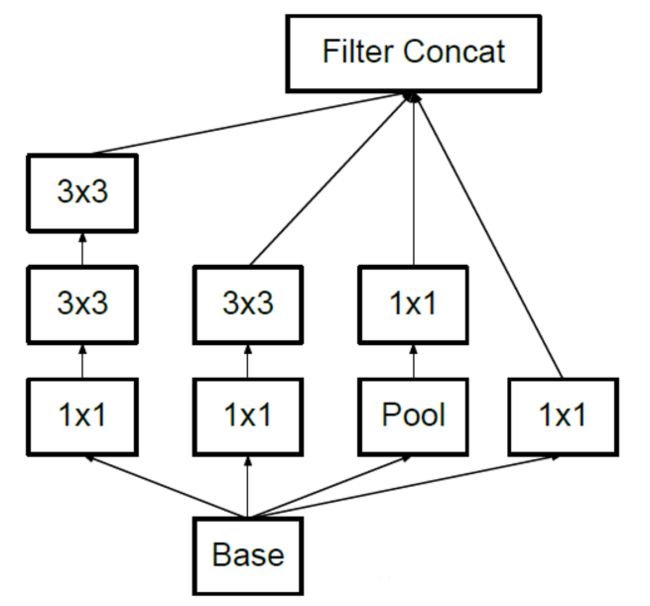
GoogleNet 即 Inception 结构。
Inception网络即是Inception模块的重复拼接,其中插有额外的有池化层来改变模型的宽度和高度。 所有卷积和池化操作均使用Padding=”SAME”卷积/池化方式 。
结构就是Inception,结构里的卷积stride都是1,另外为了保持特征响应图大小一致,都用了零填充。最后每个卷积层后面都立刻接了个ReLU层。在输出前有个叫concatenate的层,直译的意思是“并置”,即把4组不同类型但大小相同的特征响应图一张张并排叠起来,形成新的特征响应图。
Inception结构里主要做了两件事:
通过3×3的池化、以及1×1、3×3和5×5这三种不同尺度的卷积核,一共4种方式对输入的特征响应图做了特征提取。
为了降低计算量。同时让信息通过更少的连接传递以达到更加稀疏的特性,采用1×1卷积核来实现降维。


ResNet:
ResNet的残差结构如下:


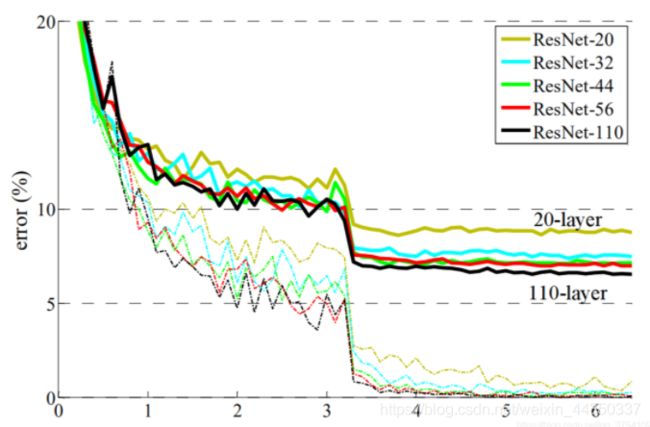
ResNet主要解决的问题,就是在深度网络中的退化的问题。在深度学习的领域中,常规网络的堆叠并不会是越深效果则越好,在超过一定深度以后,准确度开始下降,并且由于训练集的准确度也在降低,证明了不是由于过拟合的原因。
使用思维导图全面总结CNN(必做)
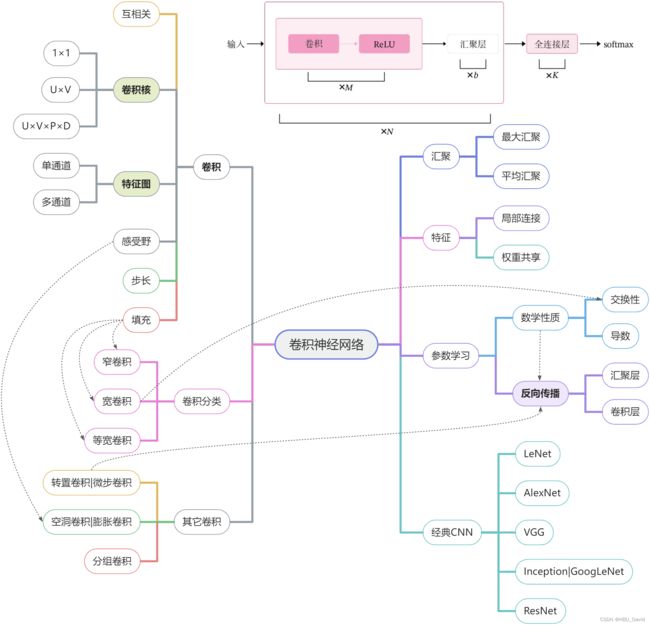
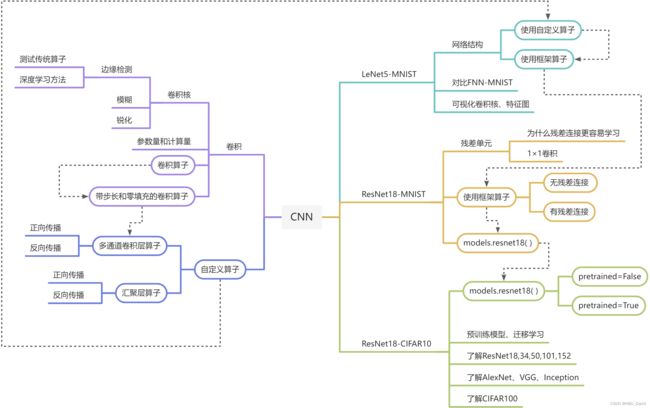
用的老师的
参考文献
什么是预训练模型
迁移学习
NNDL 实验5(上) - HBU_DAVID - 博客园 (cnblogs.com)
NNDL 实验5(下) - HBU_DAVID - 博客园 (cnblogs.com)
6. 卷积神经网络 — 动手学深度学习 2.0.0-beta1 documentation (d2l.ai)
7. 现代卷积神经网络 — 动手学深度学习 2.0.0-beta1 documentation (d2l.ai)