【论文解读】BERT和ALBERT
文章目录
- 1.前言
- 2. BERT
-
- 2.1 引入
- 2.2 以前的工作
-
- 2.2.1 feature-based 方法
- 2.2.2 fine-tuning 方法
- 2.2.3 迁移学习方法
- 2.3 BERT架构
-
- 2.3.1 MLM
- 2.3.2 NSP
- 2.4 实验
-
- 2.4.1 BERT模型的效果
- 2.4.2 验证性实验
- 3.ALBERT
-
- 3.1 引入
- 3.2 相关工作
-
- 3.2.1 cross-layer parameter sharing(交叉层的参数共享)
- 3.2.2 sentence-order prediction (SOP,句子顺序预测)
- 3.3 ALBERT的模型
-
- 3.3.1 factorized embedding parameterization
- 3.3.2 Cross-layer parameter sharing
- 3.3.3 Inter-sentence coherence loss.
- 3.4 实验
-
- 3.4.1 BERT和ALBERT的对比
- 3.4.2 交叉层参数共享实验
- 3.4.2 SOP
- 4. 参考
1.前言
最近重新阅读了BERT和ALBERT文章,所以写下自己的一些感悟。这两篇文章都是Google发出来的。其中BERT是2018年,在Transformer的基础上进行扩展;而ALBERT发表在2020年ICLR上,它是基础BERT来进行改进。
- BERT论文
- ALBERT论文
2. BERT
BERT全称是Bidirectional Encoder Representations from Transformers,它通过连接从左到右和从右到左的文本,设计了一个预处理的深度双向表达模型。在fine-tuned阶段,只需要增加简单的输出层,就可以在BERT模型基础上达到SOTA的效果。
BERT在GLUE数据集上能够达到80.4%,在MultiNLI上则有86.7%,在SQuAD v1.1则有93.2%。
2.1 引入
在NLP场景中,预处理的模型往往能够提升下游任务的效果。在natural language inference(语言推断)、relation classification、NER和QA任务中,预处理的语言模型都是有效果的。
预处理的语言模型到下游任务中,主要有两种策略方法:
- feature-based方法:类似于ELMO那样,设计了一个比较精细的结构,作为额外的特征进行输入。
- fine-tuning 方法:类似于Transformer和GPT那样的模型,它们可以在下游任务中进行简单的调节参数,使得模型适应于下游任务。
这些方法都是单方向(unidirectional)的语言模型。
BERT引入了两个预处理时的学习目标,包括:Masked language model(MLM)、next sentence predicton(NSP)。
- MLM:随机掩盖一部分的tokens,然后对这些词语进行预测。这可以使得模型因为不知道是要预测哪些词语,所以必须要学习“从左到右”和“从右到左”的文本信息。
- NSP:输入两个句子,判断这两个句子是否是连贯性的句子。
2.2 以前的工作
2.2.1 feature-based 方法
预处理得到的词向量能够作为模型的输入,这会带来大量的特征信息,提升之后的任务效果。
在ELMO中,生成了比较传统的词向量。它们提出上下文敏感的特征,能够表征复杂语境下的词语语义。
2.2.2 fine-tuning 方法
在有监督的下游任务微调模型之前,预先训练一些关于LM目标的模型架构。这种方法就是提前训练好了一个模型(提前训练的模型通常是用无监督的方法训练的),在下游任务中几乎不需要从头开始学习模型参数。GPT模型就是这种做法。
2.2.3 迁移学习方法
在有监督的数据集中训练一个模型,然后把训练好的模型迁移到另一个数据集中进行训练学习。这种方法也不需要模型从新训练,但是需要大量的有监督数据集。
2.3 BERT架构
论文中训练了两个基础的BERT:
| 名称 | Transformer的层数 L L L | 隐藏层大小 H H H | self-attention head的数量 A A A | 总参数数量 |
|---|---|---|---|---|
| BERT_base | 12 | 768 | 12 | 110M |
| BERT_large | 24 | 1024 | 16 | 340M |
可以看到BERT模型的参数量是很大的。它在输入表达中构建了三层的词语嵌入,同时设计了两个预训练时的任务(MLM,NSP)
- BERT的输入:
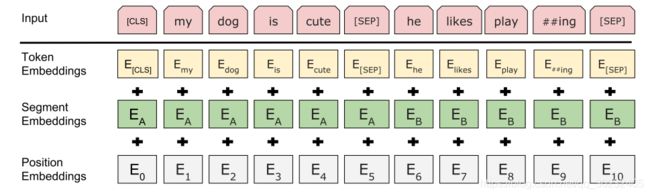
(1)Token embedding:句子中每个词语的词向量输入,使用了wordpiece方法。[CLS]和[SEP]代表的是输入句子的开头和结尾;[SEP]则分割了两个输入句子
(2)Segment embedding:句子向量,在代码实现中,把第一个句子设计成0,第二个句子设计成1,然后随机初始化
(3)Position embedding:词语的位置向量。
接下来介绍两个预训练的任务:MLM,SNP
2.3.1 MLM
为了实现真正的深度双向模型,所以使用了随机掩码。使用mask的原因是为了防止模型在双向循环训练的过程中“预见自身”。于是,文章中选取的策略是对输入序列中15%的词使用[MASK]标记掩盖掉,然后通过上下文去预测这些被mask的词语。但是为了防止模型过拟合地学习到【MASK】这个标记,对15%mask掉的词进一步优化:
- 以80%的概率用[MASK]替换:my dog is hairy ----> my dog is [MASK]
- 以10%的概率随机替换:my dog is hairy ----> my dog is apple
- 以10%的概率不进行替换:my dog is hairy ----> my dog is hairy
2.3.2 NSP
为了让模型能够学习到句子之间关系,则预训练任务中加入了“预测下一句”的任务,这是一个二值分类任务。也即是说输入句子中包括了两个句子A和B。
- 50%的B句子是A句子的下一个句子
- 另外50%的句子则是从数据集中随机抽取出来的。
例如例子:
Input = [CLS] the man went to [MASK] store [SEP] he bought a gallon [MASK] milk [SEP]
Label = IsNext
Input = [CLS] the man [MASK] to the store [SEP] penguin [MASK] are flight ##less birds [SEP]
Label = NotNext
2.4 实验
接下来看一下实验部分。首先需要说明BERT在不同数据集中输出的部分都不一致。

- (a)图主要用来适应两个句子的输入。获取[CLS]位置的输出,把它作为句子向量,然后预测类别。(适合句子推断等任务)
- (b)图主要用来适应单个句子的输入。获取[CLS]位置的输出,把它作为句子向量,然后预测类别。(适合句子分类等任务)
- (c)图主要用来适应QA任务,输入的是question和paragraph,输出找到的answer。
- (d)图主要用来做序列标注。
2.4.1 BERT模型的效果

上面可以看出,对比几个模型,BERT的效果都大于现有的模型

在CoNLL-2003的NER任务中,也比传统的LSTM+CRF要高。
2.4.2 验证性实验
(1)主要验证MLM的效果。
- no NSP:没有使用NSP任务训练,仅仅使用MLM任务
- LTR & NO NSP:把MLM任务换成left to right(LTR)任务,也就是放弃了随机mask,改成按照顺序预测每一个词语
- +BiLSTM:在LTR & NO NSP任务上,输出层加了BiLSTM。

从图上的实验效果可以看出,使用MLM的模型会比LTR模型的效果要好很多。这侧面证实了MLM可以让模型保持双向的上下文内容的学习。
(2)参数实验

BERT的层数L越多,隐藏层大小H越多,效果越好
(3)MNLI数据集上的收敛速度

MLM的收敛速度确实比LTR模式稍慢。然而,就绝对准确度而言,MLM几乎立刻就开始超越LTR模式
(4)BERT当feature-based来用(在Conll-2003数据集上)

实验中在BERT输出之后加一层BLSTM进行分类。如果把所有层的输出加起来,得到的效果最好。
3.ALBERT
ALBERT模型是在BERT模型的基础上进行改进的。它设计了参数减少的方法,用来降低内存消耗,同时加快BERT的训练速度。同时使用了self-supervised loss(自监督损失函数)关注构建句子中的内在连贯性(coherence )。实验在GLUE、RACE、SQuAD数据集上取得了最好的效果。
3.1 引入
在NLP任务中,一个好的预训练模型能够提升模型的效果。当前一个SOTA的模型,它有几百万或者十亿以上的参数,如果要扩大模型规模,就会遇到这些计算机内存上的限制,同时训练速度会受到限制。目前存在的解决方法有两种:模型并行化、好的内存管理机制。但这两种方法都会存在通信开销。因此本论文设计了一个A lite BERT(ALBERT),它比BERT使用更少的参数。
ALBERT使用了两种参数减少的方法:
- factorized embedding parameterization(词嵌入的因式分解):把词嵌入矩阵进行分解,分解成更少的两个矩阵。
- cross-layer parameter sharing(交叉层的参数共享):这种技术在深层的网络中更能减少参数。
总的来说,参数减少技术像是一种正则化方法。ALBERT会比BERT-large的参数量少18倍,同时训练速度快1.7倍。
ALBERT还提出了另一种方法,用来代替NSP技术,这种新技术叫sentence-order prediction (SOP)。SOP是一种self-supervised loss。
因此ALBERT利用了三种技术:
- factorized embedding parameterization(词嵌入的因式分解)
- cross-layer parameter sharing(交叉层的参数共享)
- sentence-order prediction (SOP,句子顺序预测)
3.2 相关工作
3.2.1 cross-layer parameter sharing(交叉层的参数共享)
参数共享的思想来自于Transformer模型中。在多个研究工作中,发现交叉层的参数共享确实能够提升模型的效果,且模型层与层之间通常是震荡的,而这种做法也能够使得层与层之间收敛。
3.2.2 sentence-order prediction (SOP,句子顺序预测)
ALBERT设计两个一个新的loss,来预测两个连续的文本段的顺序。语篇中的连贯性(coherence)和衔接性(cohesion)已得到广泛研究,并且已发现许多现象将相邻的文本片段连接在一起。比如:Skip-thought和FastSent利用句子向量预测相邻句子的词语。
3.3 ALBERT的模型
ALBERT的骨干结构是BERT模型,同时使用了GELU激活函数。定义词典的大小为 E E E,encoder的层数为 L L L,隐藏层的大小为 H H H,attention head为 H / 64 H/64 H/64。
3.3.1 factorized embedding parameterization
在BERT、XLBERT和RoBERTa中wordpiece embedding的大小为 E E E,同时隐藏层大小为 H H H,它们两个之间是相等的: E = H E=H E=H。
从建模的观点来看,wordpiece embedding主要学习上下文相关的表征,而隐藏层则学习上下文无关的表征。。显然后者更加复杂,需要更多的参数,也就是说模型应当增大隐层大小 H H H,或者说满足 H ≫ E H \gg E H≫E.
从实际角度来看,通常词典大小 V V V是非常大的,如果 E = H E=H E=H,增加 H H H的大小,会使得 V × E V \times E V×E的矩阵非常大,从而造成模型参数过大,训练速度减慢。
因此,ALBERT使用了隐式分解的方法,把embedding矩阵参数分解成两个矩阵。也即是把参数量 O ( V × E ) O(V \times E) O(V×E)变为 O ( V × E + E × H ) O(V \times E + E \times H) O(V×E+E×H)
在实现时,随机初始化 V × E V \times E V×E和 E × H E \times H E×H的矩阵,计算某个单词的表示需用一个单词的one-hot向量乘以 V × E V \times E V×E维的矩阵(也就是lookup),再用得到的结果乘 E × H E \times H E×H维的矩阵即可。两个矩阵的参数通过模型学习。
3.3.2 Cross-layer parameter sharing

在交叉层中使用了参数共享操作,可以看到层与层之间的距离相似。在上图中ALBERT的层间距离是收敛的,不是震荡状态。
3.3.3 Inter-sentence coherence loss.
在BERT模型中,NSP是一个binary分类,用来预测两段文字是否是连续的。然而,随后的研究(Yang等人,2019;Liu等人,2019)发现NSP的影响不可靠,并决定消除它,这一决定得到了几个任务下游任务绩效改进的支持。NSP不可靠的原因在于:对比于MLM任务,它是一项缺乏难度的任务。NSP包含了两种任务:主题预测、连贯性预测。然而主题预测比连贯性预测要容易,所以NSP是缺乏难度的任务。
而ALBERT使用的sentence-order prediction(SOP),避免主题预测(topic prediction)并且专注于构建句子之间的连贯性。SOP loss使用了和BERT一样的技术来抽取positive examples(在同一个文档中抽取两个连续的句子),同时把这两个句子的顺序进行交换,用来作为negative 样本。 SOP能够合理的是:一定程度上解决NSP任务,因为NSP大概率是基于没有对齐连续性线索
3.4 实验
使用了BOOKCORPUS (Zhu et al., 2015) and English Wikipedia数据用来作为原始测词典。限制了最大句子长度为512。同时也使用了MLM预测任务和SOP任务。
3.4.1 BERT和ALBERT的对比

- ALBERT-xxlarge的参数量比BERT-large参数量要少,同时它的效果也比BERT的好。
- BERT-large和ALBERT-large使用了相同的层数,和相同的embedding大小。参数量确实是ALBERT的少,并且运行速度要更快。在效果上对比中BERT-large会比ALBERT-large要好
3.4.2 交叉层参数共享实验

-如果全部的层都进行参数共享,参数量会变得很少,但模型的效果不会降低太多。
3.4.2 SOP

- SOP在下游任务中表现很出色,比NSP要好。
4. 参考
(1)BERT源码分析PART II:https://blog.csdn.net/Kaiyuan_sjtu/article/details/90288178
(2)BERT论文:《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》
(3)ALBERT论文:《ALBERT: A LITE BERT FOR SELF-SUPERVISED LEARNING OF LANGUAGE REPRESENTATIONS》