ALBERT: A LITE BERT FOR SELF-SUPERVISEDLEARNING OF LANGUAGE REPRESENTATIONS
原文链接:https://openreview.net/pdf?id=H1eA7AEtvS
概述
越大的模型在自然语言表征上进行预训练后通常能在下游任务中表现更好,这样下区会加重GPU/TPU的负担,并且训练时间会更长。于是,我们提出了两种方法来降低硬件消耗并增加BERT的训练速度。综合来看,我们提出的方法比原始的BERT规模更好,并且加入了自监督损失,对句子间的连贯性进行建模,实验表明该模型有助于多句子输入的下游任务。
介绍
问题:
往往大规模的模型会带来更好的效果,但由于硬件的限制不能再对BERT进行加深加宽。尽管目前存在分布式训练、模型并行、以及内存管理等方法,但都不能很好的解决大模型引起的内存限制问题,并且会额外带来通信的开销。因此作者就想找方法来减少训练的参数,可以对更深更宽的bert进行训练。
IDEA:
作者提出ALBERT,主要通过两个方法来减少模型的参数。
1)分解embedding参数 通过将大的词嵌入矩阵分解为两个小矩阵,并将隐藏层的大小与词嵌入的大小分开,这样就能在不增加词嵌入参数大小的情况下增加隐藏层的大小。
2)跨层参数共享 作者提出三种参数共享的方法,FFN层参数共享、attention层参数共享以及所有参数共享,该方法有效防止参数随着网络的深度增加。
另外引入了SOP(句子排序)任务损失来提高该模型的性能,实验证明,能够在该结构上进行扩展,在比BERT-large参数更少的情况下拥有更好的性能,在多个数据集上都达到了最好的效果。
方法
分解embedding参数
在之前的模型中,embedding size和隐藏层大小都是相等的,但对于实际问题来说这是不太好的,主要有两个原因。
- WordPiece embedding(E)是用来学习context-independent的表征,而隐藏层embedding(H)是为了学习context-dependent的表征。在最初的BERT_base中,Embedding层的维度与隐层的维度一样都是768,但是对于词的分布式表示,往往并不需要这么高的维度,所以如果将WordPiece embedding和隐藏层大小分开考虑,就能使得H>>E.
- 从实用的角度来看,自然语言的处理也需要比较大的词表V,如果要求E=H,在增加H的时候时就会同步增加embedding矩阵(V*E)的大小,这样一来模型的参数就成倍的增加,而且其中大部分参数在训练期间也不怎么更新。
所以作者将参数分为两个较小的矩阵,将one-hot向量先投影到大小为E的低维空间后,再映射到大小为H的隐藏空间。通过这样分解,将embedding的参数从O(V × H)减少到了O(V × E + E × H)。
跨层参数共享
作者提出了多种跨层参数共享方式,比如只跨层共享前馈神经网络(FFN)的参数、只共享注意力层的参数、共享所有参数。使用L2 distance和余弦相似度对每一层的输入输出embedding进行衡量,实验结果如下所示。

可以看出ALBERT中层与层之间的过渡要比BERT的平滑得多,即共享权重对稳定网络参数是有用的。另外两个指标虽然与BERT相比呈下降趋势,但24层后也没有下降到0,这表明ALBERT中的参数与DQE(共享参数的transformer)所说的平衡点(输入输出embedding保持不变)。
句子间的连贯性损失
BERT中使用了掩码语言模型(MLM)损失和下一句预测(NSP)损失。其中NSP是一种二元分类损失,用于预测两个片段是否在原文中连续。然而,有研究者发现NSP的影响并不可靠,清除该任务后,在某几个下游任务的表现得到了提升。
作者猜测NSP任务没有效果是因为该任务和MLM相比过于简单,因为NSP任务中的负样本是由两个不同文章中的句子组成的,往往这两个不连续的句子都不属于同一个主题(所以对于句子的连续性的预测会偏向对主题进行预测)。因此作者提出了SOP任务,聚焦于句子的连贯性进行建模。该任务中正样本跟NSP一样,负样本将两个句子顺序进行翻转。
后续作者进行实验证明,NSP不能解决SOP任务,它最终学习了更容易的话题预测信号,而在SOP的任务中表现为随机基线水平,而SOP可以在合理的程度上解决NSP的任务。因此,ALBERT模型持续改善了多句子编码任务的下游任务表现。
实验
ALBERT与BERT各个版本之间在多个数据集上的实验结果,如下图所示:

可以看出ALBERT-xxlarge的参数只有BERT-large的70%左右,但其精度明显比BERT-large更好。并且ALBERT模型比相应的BERT模型的吞吐速度更快。
对不同的vocabulary embedding size进行实验,结果如下:
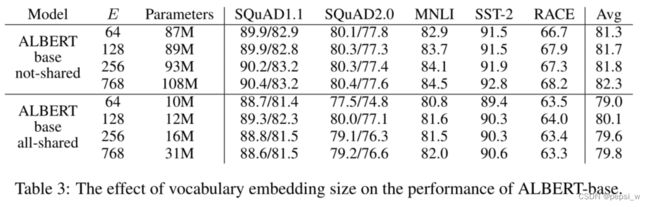
可以看出在不共享的条件下,词的embedding size越大,其表现越好,在共享的条件下,size=128是最好的情况,而且在共享的条件下,参数少了很多,但其精度也没有下降很多。
对不同的共享策略进行实验,结果如下:

可以发现,全共享策略都不利于性能,但其在E=128的情况下,精度降低的幅度较小,另外大部分的性能下降都与FFN层共享参数有关。
对模型的各个损失进行了比较,实验结果如下:

可以看出,在intrinsic 任务上,NSP损失对于SOP任务没有什么效果,但SOP损失对于NSP任务却有一定的效果。而且在多句子编码任务中,SOP损失似乎一直在改善下游的任务表现。
由前面的实验可知,ALBERT的速度比BERT-large快,较长的训练时间通常会导致更好的性能。所有作者在不控制吞吐量控制训练时间的情况下进行了一个比较。结果如下,很明显,相同的训练时间下,ALBERT的效果比BERT-large更好。

在GLUE、SQuAD、RECA上与SOTA模型进行对比结果:


总结
虽然作者通过共享权重参数、分解embedding参数来降低参数量,在训练过程中确实也带来了更快的速度。但实际计算量并没有减少,所以在做预测时速度并不会有提升(反而由于在分解参数那里多了一个矩阵运算应该是要慢一点?)。