【DL】第 11 章:自动驾驶汽车的深度学习
大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流
个人主页-Sonhhxg_柒的博客_CSDN博客
欢迎各位→点赞 + 收藏⭐️ + 留言
系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟
文章目录
自动驾驶汽车简介
AV研究简史
自动化水平
视音频系统的组件
环境感知
传感
本土化
运动物体检测与跟踪
路径规划
3D数据处理简介
模仿驾驶政策
使用 PyTorch 进行行为克隆
生成训练数据集
实现代理神经网络
训练
让代理开车
把它们放在一起
使用 ChauffeurNet 的驾驶政策
输入和输出表示
模型架构
训练
概括
让我们想想自动驾驶汽车 ( AV )将如何发展 影响我们的生活。一方面,我们可以在旅途中做其他事情,而不是把注意力集中在驾驶上。满足这些旅行者的需求本身可能会催生一个完整的行业。但这只是一个额外的好处。如果我们在旅行期间可以更有效率或只是放松一下,那么我们很可能会开始更多地旅行,更不用说对自驾能力有限的人的好处了。让交通这样一种必不可少的基本商品变得更容易获得,有可能改变我们的生活。这只是对我们个人的影响——从交付服务到准时制造,自动驾驶汽车也可以对经济产生深远的影响。简而言之,让 AV 工作是一项非常高风险的游戏。那么难怪,近年来,该领域的研究已从学术界转向实体经济。从 Waymo、Uber 和 NVIDIA 到几乎所有主要汽车制造商,公司都在争相开发 AV。
但是,我们还没有到达那里。原因之一是自动驾驶是一项复杂的任务,由多个子问题组成,每个子问题本身就是一项主要任务。为了成功导航,车辆程序需要一个准确的环境 3D 模型。构建这种模型的方法是将来自多个传感器的信号组合起来。一旦我们有了模型,我们仍然需要解决实际的驾驶任务。想想驾驶员必须克服的许多意外和独特的情况而不会撞车。但即使我们创建了一个驾驶策略,它也需要几乎 100% 准确。假设我们的 AV 将成功停在 100 个红绿灯中的 99 个。99% 的准确率对于任何其他机器学习(ML ) 任务; 自动驾驶并非如此,即使是一个错误也可能导致撞车。
在本章中,我们将探讨深度学习在 AV 中的应用。我们将研究如何使用深度网络来帮助车辆了解其周围环境。我们还将了解如何在实际控制车辆时使用它们。
本章将涵盖以下主题:
- 自动驾驶汽车简介
- 视音频系统的组件
- 3D数据处理简介
- 模仿驾驶政策
- 使用 ChauffeurNet 的驾驶政策
自动驾驶汽车简介
我们将从 AV 研究的简史开始本节(令人惊讶的是很久以前就开始了)。我们还将尝试根据汽车工程师协会( SAE ) 定义不同级别的 AV 自动化。
AV研究简史
实施自动驾驶汽车的第一次认真尝试 始于 1980 年代的欧洲和美国。自 2000 年代中期以来,进展迅速加快。该领域的第一个重大努力是Eureka Prometheus 项目 ( https://en.wikipedia.org/wiki/Eureka_Prometheus_Project ),该项目从 1987 年到 1995 年。它在 1995 年达到顶峰,当时一辆自动驾驶的梅赛德斯-奔驰 S-Class 使用计算机视觉从慕尼黑到哥本哈根进行了 1,600 公里的旅行,然后返回。在某些时候,这辆车在德国高速公路上的速度高达 175 公里/小时(有趣的事实:高速公路的某些路段没有速度限制)。这辆车能够自行超越其他汽车。人工干预之间的平均距离为 9 公里,在没有干预的情况下,它曾一度行驶 158 公里。
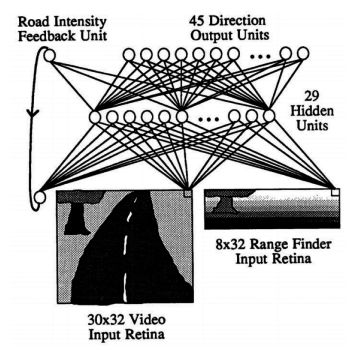
1989 年,卡内基梅隆大学的院长 Pomerleau 发表了ALVINN: An Autonomous Land Vehicle in a Neural Network ( https://papers.nips.cc/paper/95-alvinn-an-autonomous-land-vehicle-in-a-neural -network.pdf ),一篇关于在 AV 中使用神经网络的开创性论文。这项工作特别有趣,因为它应用了我们在 30 年前的 AV 中讨论过的许多主题。让我们看看 ALVINN 最重要的属性:
- 它使用一个简单的神经网络来决定车辆的转向角度(它不控制加速和刹车)。
- 该网络由一个输入层、一个隐藏层和一个输出层全连接。
- 输入包括以下内容:
- 来自安装在车辆上的前置摄像头的 30 × 32 单色图像(他们使用 RGB 图像中的蓝色通道)。
- 来自激光测距仪的 8 × 32 图像。这只是一个网格,其中每个单元格包含到视野中该单元格覆盖的最近障碍物的距离。
- 一个标量输入,表示道路强度,即道路比摄像头图像中的非道路更亮还是更暗。该值递归地来自网络输出。
- 具有 29 个神经元的单个全连接隐藏层。
- 具有 46 个神经元的全连接输出层。道路的曲率由 45 个神经元以类似于 one-hot 编码的方式表示——也就是说,如果中间的神经元具有最高的激活,那么道路是直的。相反,左右神经元代表增加的道路曲率。最终输出单位表示道路强度。
- 该网络在 1200 张图像的数据集上训练了 40 个 epoch:
接下来,让我们看一下(主要是)商业 AV 进展的最新时间表:
- DARPA 大挑战赛 ( https://en.wikipedia.org/wiki/DARPA_Grand_Challenge ) 于 2004 年、2005 年和 2007 年组织。第一年,参赛队伍的 AV 必须在莫哈韦沙漠中导航 240 公里的路线. 性能最好的 AV 只跑了 11.78 公里的路线,然后就被挂在了岩石上。2005 年,车队必须在加利福尼亚州和内华达州克服 212 公里的越野路线。这一次,有五辆车成功行驶了整条路线。2007 年的挑战是在一个建于空军基地的模拟城市环境中导航。总路线长度为89公里,参与者必须遵守交通规则。六辆车完成了整个过程。
- 2009 年,谷歌开始开发自动驾驶技术。这一努力促成了 Alphabet(谷歌的母公司)子公司 Waymo(https://waymo.com/ )的创建。2018 年 12 月,他们在亚利桑那州凤凰城推出了首个使用 AV 的商业按需乘车服务。2019 年 10 月,Waymo 宣布推出首批真正无人驾驶汽车,作为其机器人出租车服务的一部分(此前,一直有安全司机在场)。
- Mobileye ( Mobileye | Driver Assist and Autonomous Driving Technologies ) 使用深度神经网络来提供驾驶员辅助系统(例如,车道保持辅助)。该公司开发了一系列片上系统( SOC ) 设备,专门针对运行汽车所需的低能耗神经网络进行了优化。其产品被许多主要汽车制造商使用。2017 年,Mobileye 被英特尔收购 153 亿美元。此后,宝马、英特尔、菲亚特克莱斯勒、上汽、大众、蔚来以及汽车供应商德尔福(现为安波福)就联合开发自动驾驶技术展开合作。2019 年前三个季度,Mobileye 的总销售额为 8.22 亿美元,而 2016 年四个季度的总销售额为 3.58 亿美元。
- 2016 年,通用汽车以超过 5 亿美元的价格收购了自动驾驶技术开发商Cruise Automation( https://getcruise.com/ )(具体数字未知)。从那时起,Cruise Automation 已经在旧金山测试并展示了多个 AV 原型。2018 年 10 月,宣布本田也将参与该合资企业,投资7.5 亿美元换取 5.7% 的股份。2019 年 5 月,Cruise 从一群新老投资者那里获得了 11.5 亿美元的额外投资。
- 2017 年,福特汽车公司收购了自动驾驶初创公司 Argo AI 的多数股权。2019 年,大众汽车宣布将向 Argo AI 投资 26 亿美元,作为与福特达成更大交易的一部分。大众汽车将提供 10 亿美元的资金,并为其位于慕尼黑的拥有 150 多名员工的自动智能驾驶子公司提供 16 亿美元的资金。
自动化水平
当我们谈论 AV 时,我们通常会 想象 完全无人驾驶的车辆。但实际上,我们的汽车需要司机,但仍提供一些自动化功能。
SAE 开发了一个包含六个自动化级别的规模:
- 0 级:驾驶员处理车辆的转向、加速和制动。此级别的功能只能为驾驶员的行为提供警告和即时帮助。此级别的功能示例包括:
- 车道偏离警告只是在车辆越过其中一个车道标记时警告驾驶员。
- 当另一辆车位于汽车的盲区区域(车辆后端的左侧或右侧区域)时,盲区警告会向驾驶员发出警告。
- 1 级:为驾驶员提供转向或加速/制动辅助的功能。当今车辆中最受欢迎的这些功能如下:
- 车道保持辅助 ( LKA ):车辆可以检测车道标记并使用转向将自身保持在车道中心。
- 自适应巡航控制 ( ACC ):车辆可以检测到 其他 车辆并根据情况使用制动和加速来保持或降低预设速度。
- 自动紧急制动(AEB):如果车辆检测到障碍物并且驾驶员没有反应,车辆可以自动停止。
- 2 级:为驾驶员提供转向和制动/加速辅助的功能。其中一项功能是 LKA 和自适应巡航控制的组合。在这个级别,汽车可以随时将控制权交还给驾驶员,而无需提前警告 。因此,他或她必须始终关注道路状况。例如,如果车道标记 突然消失,LKA 系统可以提示驾驶员立即控制转向。
- 第 3 级:这是我们可以谈论真正自治的第一个级别。类似于2级,汽车可以在一定的限制条件下自行行驶,并能提示驾驶员进行控制;但是,这可以保证提前发生,并有足够的时间让注意力不集中的人熟悉路况。例如,假设汽车在高速公路上自行行驶,但云连接的导航会获取有关前方道路建设工程的信息。在到达施工区域之前,将提示驾驶员进行控制。
- 4 级:与 3 级相比,处于 4 级的车辆在更广泛的情况下是完全自主的。例如,本地地理围栏(即仅限于某个区域)的出租车服务可能处于 4 级。没有要求以便驾驶员控制。相反,如果车辆驶出该区域,它应该能够安全地中止行程。
- 5 级:在任何情况下完全自主。方向盘是可选的。
今天所有的商用车辆最多都具有 2 级的功能(甚至是特斯拉的自动驾驶仪)。唯一的例外(根据制造商的说法)是 2018 年的奥迪 A8,它具有称为 AI Traffic Jam Pilot 的 3 级功能。该系统负责在多车道道路上以高达 60 公里/小时的速度行驶,两个交通方向之间有物理障碍。 可以通过 10 秒的提前警告提示驾驶员进行控制。此功能在车辆发布期间已展示,但在撰写本章时,奥迪引用了监管限制,并未将其包含在所有市场中。我没有关于此功能在哪里(或是否)可用的信息。
在下一节中,我们将了解构成 AV 系统的组件。
视音频系统的组件
在本节中,我们将从软件架构的角度概述两种类型的 AV 系统。第一种类型使用具有多个组件的顺序架构,如下图所示:
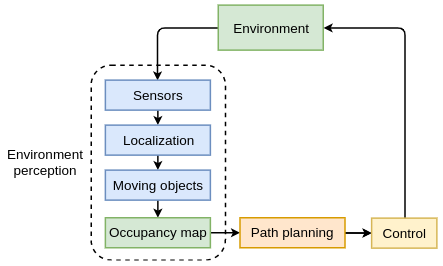
该系统类似于我们在第 10 章“元学习”中简要讨论过的强化学习框架。我们有一个反馈循环,其中环境(物理世界或模拟)为代理(车辆)提供其当前状态。反过来,代理决定它的新轨迹,环境对其做出反应,等等。让我们从环境感知子系统开始,它具有以下模块(我们将在以下部分更详细地讨论它们):
- 传感器:物理设备,例如相机和雷达。
- 定位:确定车辆在高清地图中的准确位置(精确到厘米)。
- 移动物体检测和跟踪:检测和跟踪其他交通参与者,例如车辆和行人。
感知系统的输出结合了来自其各个模块的数据,以产生周围环境的中级虚拟表示。这种表示通常是环境的自上而下(鸟瞰)2D 视图,称为占用图。以下屏幕截图显示了 ChauffeurNet 系统的示例占用地图,我们将在本章后面讨论。它包括路面(白线和黄线)、交通信号灯(红线)和其他车辆(白色矩形)。最好以彩色方式查看图像:
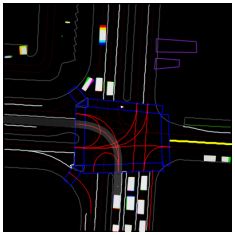
占用图用作路径规划模块的输入,该模块使用它来确定车辆的未来轨迹。控制模块采用所需的轨迹并将其转换为车辆的低级控制输入。
中层表示方法有几个优点。首先,它非常适合路径规划和控制模块的功能。此外,我们可以使用模拟器生成它,而不是使用传感器数据来创建自上而下的图像。通过这种方式,收集训练数据会更容易,因为我们不必驾驶真正的汽车。更重要的是,我们将能够模拟现实世界中很少发生的情况。例如,我们的 AV 必须不惜一切代价避免崩溃,但现实世界的训练数据将很少(如果有的话)崩溃。如果我们只使用真实的传感器数据,最重要的驾驶情况之一将被严重低估。
第二种类型的 AV 系统使用单个端到端组件,它将原始传感器数据作为输入,并以转向控制的形式生成驾驶策略,如下图所示:
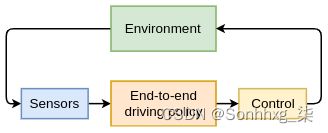
端到端的视音频系统
事实上,我们在讨论 ALVINN 时已经提到了端到端系统(在 AV 研究简史部分)。接下来,我们将关注顺序系统的不同模块。我们将在本章后面更详细地介绍端到端系统。
环境感知
要使任何自动化功能发挥作用, 车辆需要对其周围环境有良好的感知。环境感知系统必须识别移动物体(例如行人、骑自行车者和其他车辆)的准确位置、距离和方向。此外,它必须创建路面的精确映射以及车辆在该路面和整个环境中的准确位置。让我们讨论帮助 AV 创建这个虚拟环境模型的硬件和软件组件。
传感
建立良好环境模型的关键是车辆传感器。以下是最重要的传感器列表:
- 摄像头:其图像用于 检测 路面、车道标线、行人、骑自行车的人、其他车辆等。汽车环境中的一个重要相机属性(除了分辨率)是视野。它测量相机在任何给定时刻看到的可观察世界的多少。例如,在 180 o的视野下,它可以看到前面的一切,而后面什么也看不见。凭借 360 度的视野,它可以看到它前面的一切和车辆后面的一切(全面观察)。存在以下不同类型的相机系统:
- 单声道摄像头:使用单个前置摄像头,通常安装在挡风玻璃顶部。 大多数自动化功能都依赖于这种类型的相机来工作。单声道相机的典型视场为 125 o。
- 立体摄像头:由两个前置摄像头组成的系统,彼此略微分开。相机之间的距离使它们能够从稍微不同的角度捕捉到同一张照片,并将它们组合成 3D 图像(以我们使用眼睛的相同方式)。立体系统可以测量到图像中某些物体的距离,而单声道相机仅依靠启发式来完成这项工作。
- 360 o周围环境 视图:一些车辆具有四个摄像头(前、后、左、右)的系统。
- 夜视摄像头:一种系统,其中车辆包括一种特殊类型的前照灯,除了其常规功能外,它还会发出红外光谱中的光。红外摄像机记录的光线可以向驾驶员显示增强的图像并在夜间检测障碍物。
- 雷达:使用发射器向不同方向发射电磁波(在无线电或微波频谱中)的系统。当波到达一个物体时,它们通常会被反射,其中一些反射到雷达本身的方向。雷达可以 探测到 它们带有特殊的接收器天线。由于我们知道无线电波以光速传播,我们可以通过测量发射和接收信号之间经过的时间来计算到反射物体的距离。我们还可以通过测量出射波和入射波的频率差(多普勒效应)来计算物体(例如,另一辆车)的速度。与摄像机图像相比,雷达的“图像”噪声更大、更窄且分辨率更低。例如,远程雷达可以在 160 m 的距离内探测到物体,但在 12 o的狭窄视野内。雷达可以检测到其他车辆和行人,但无法检测路面或车道标记。它通常用于ACC和AEB,而LKA系统则使用摄像头。大多数车辆都有一个或两个前置雷达,在极少数情况下,还有一个后置雷达。
- 激光雷达 (光探测和测距):这种传感器 有点 类似于 雷达,但它不是无线电波,而是发射近红外光谱的激光束。正因为如此,一个发射的脉冲可以准确地测量到单个点的距离。激光雷达以一种非常快速的模式发射多个信号,从而创建环境的 3D 点云(传感器可以非常快速地旋转)。下图显示了车辆如何使用激光雷达观察世界:
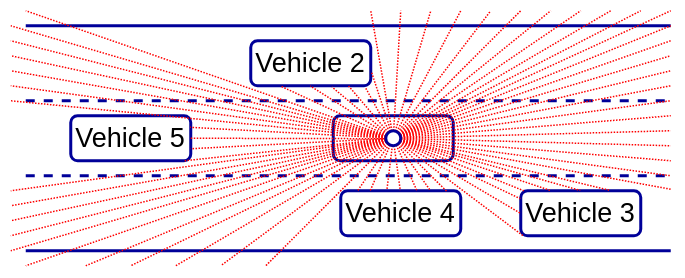
- 声纳(声音和导航测距) :该传感器发出超声波脉冲,并通过听取周围物体反射的波的回声来绘制环境图。与雷达相比,声纳价格低廉,但有效探测范围有限。因此,它们通常用于停车辅助功能。
来自多个传感器的数据可以通过称为传感器融合的过程合并到一个环境模型中。传感器融合通常使用卡尔曼滤波器 ( https://en.wikipedia.org/wiki/Kalman_filter )实现。
本土化
定位是确定车辆 在 地图上的准确位置的过程。为什么这很重要?HERE ( HERE Technologies | The world's #1 location platform ) 等公司专注于创建极其精确的道路地图,其中道路表面的整个区域已知在几厘米以内。这些地图还可以包括有关静态感兴趣对象的信息,例如车道标记、交通标志、交通信号灯、限速、斑马线、减速带等。因此,如果我们 知道车辆在道路上的准确位置,就不难计算出最优轨迹。
一种明显的解决方案是使用 GPS。但是,在完美的条件下,GPS 可以精确到 1-2 米以内。在有高层建筑或山区的地区,精度可能会受到影响,因为 GPS 接收器无法从足够数量的卫星获得信号。解决此问题的一种方法是使用同步定位和映射 ( SLAM ) 算法。这些算法超出了本书的范围,但我鼓励 你 对这个主题进行自己的研究。
运动物体检测与跟踪
我们现在对车辆使用的传感器有所了解,并且我们已经简要提到了了解其在地图上的确切位置的重要性。有了这些知识,车辆理论上可以通过简单地跟踪细粒度点的面包屑路径导航到目的地。然而,自动驾驶的任务并没有那么简单,因为环境是动态的,因为它包括移动的物体,如车辆、行人、骑自行车的人等。自动驾驶汽车必须不断了解移动物体的位置,并在规划其轨迹时对其进行跟踪。这是我们可以将深度学习算法应用于原始传感器数据的一个领域。首先,我们将为相机执行此操作。第5章,目标检测和图像分割 ,我们讨论了如何 在两个高级视觉任务——对象检测和语义分割中使用卷积网络 ( CNN )。
回顾一下,对象检测会在图像中检测到的不同类别的对象周围创建一个边界框。语义分割为图像的每个像素分配一个类标签。我们可以使用分割来检测路面的确切形状和摄像头图像上的车道标记。我们可以使用物体检测对环境中感兴趣的运动物体进行分类和定位;但是,我们已经在第 5 章,目标检测和图像分割中介绍了这些主题。在本章中,我们将重点关注激光雷达传感器,并讨论如何在该传感器产生的 3D 点云上应用 CNN。
现在我们已经概述了感知子系统组件,在下一节中,我们将介绍路径规划子系统。
路径规划
路径规划(或驾驶策略)是计算 车辆 轨迹和速度的过程。尽管我们可能有准确的地图和车辆的确切 位置 ,但我们仍然需要牢记环境的动态。汽车被其他移动的车辆、行人、红绿灯等包围。如果前面的车辆突然停下来怎么办?或者如果它移动得太慢?我们的 AV 必须做出超车决定,然后执行机动。这是一个机器学习和深度学习特别有用的领域,我们将在本章讨论两种实现它们的方法。更具体地说,我们将讨论在端到端学习系统中使用模仿驾驶策略,以及由 Waymo 开发的称为 ChauffeurNet 的驾驶策略算法。
AV 研究的一个障碍是构建 AV 并获得必要的许可来测试它是非常昂贵和耗时的。值得庆幸的是,我们仍然可以在 AV 模拟器的帮助下训练我们的算法。
一些最受欢迎的模拟器如下:
- Microsoft AirSim ,基于虚幻引擎 ( https://github.com/Microsoft/AirSim/ )
- CARLA,基于虚幻引擎 ( GitHub - carla-simulator/carla: Open-source simulator for autonomous driving research. )
- Udacity 的自动驾驶汽车模拟器,使用 Unity 构建 ( https://github.com/udacity/self-driving-car-sim )
- OpenAI Gym 的环境(我们将在模仿驾驶政策部分看到一个示例) CarRacing-v0
我们对 AV 系统组件的描述到此结束。接下来,我们将讨论如何处理 3D 空间数据。
3D数据处理简介
激光雷达产生一个点云——三维空间中的一组数据点。请记住,激光雷达会发射激光束。从表面反射并返回接收器的光束会生成点云的单个数据点。如果我们假设激光雷达设备是坐标系的中心,并且每个激光束是一个矢量,那么一个点由矢量的方向和大小定义。因此,点云是一组无序的向量。或者,我们可以通过它们在空间中的笛卡尔坐标来定义点 ,如下图左侧所示。在这种情况下,点云是一组向量
,如下图左侧所示。在这种情况下,点云是一组向量 ,其中每个向量
,其中每个向量 包含点的三个坐标。为了清楚起见,每个点都表示为一个立方体:
包含点的三个坐标。为了清楚起见,每个点都表示为一个立方体:
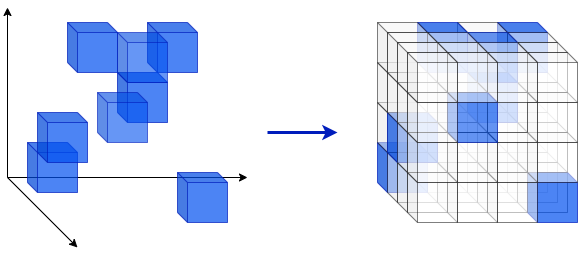
接下来,让我们关注神经网络的输入数据格式,特别是 CNN。2D 彩色图像表示为具有三个切片(每个通道一个)的张量,每个切片是由像素组成的矩阵(2D 网格)。CNN 使用 2D 卷积(参见第 2 章,了解卷积网络)。直觉上,我们可能会认为我们可以为 3D 点云使用类似的 3D 体素网格(体素是 3D 像素),如上图的右图所示。假设点云点没有颜色,我们可以将网格表示为 3D 张量,并将其用作具有 3D 卷积的 CNN 的输入。
但是,如果我们仔细观察这个 3D 网格,我们会发现它是稀疏的。例如,在上图中,我们有一个包含 8 个点的点云,但网格包含 4 x 4 x 4 = 64 个单元。在这个简单的例子中,我们将数据的内存占用增加了八倍,但在现实世界中,情况可能会更糟。在本节中,我们将介绍 PointNet(参见PointNet:Deep Learning on Point Sets for 3D Classification and Segmentation,https ://arxiv.org/abs/1612.00593 ),它提供了该问题的解决方案。
PointNet 将点云向量p i集合作为输入,而不是它们的 3D 网格表示。为了理解它的架构,我们将从导致网络设计的点云向量集的属性开始(以下项目符号包含原始论文的引用):
- 无序:与图像中的像素阵列或 3D 网格中的体素阵列不同,点云是一组没有特定顺序的点。因此,一个消耗N个 3D 点集的网络需要对N保持不变!数据馈送顺序中输入集的排列。
- 点之间的交互:类似于图像的像素,3D 点之间的距离可以指示它们之间的关系级别——也就是说,与远处的点相比,附近的点更有可能是同一对象的一部分。因此,模型需要能够从附近的点捕获局部结构以及局部结构之间的组合相互作用。
- 变换下的不变性:作为一个几何对象,点集的学习表示应该对某些变换是不变的。例如,一起旋转和平移点不应该修改全局点云类别,也不应该修改点的分割。
现在我们知道了这些先决条件,让我们看看 PointNet 如何解决它们。我们将从网络架构开始,然后更详细地讨论它的组件: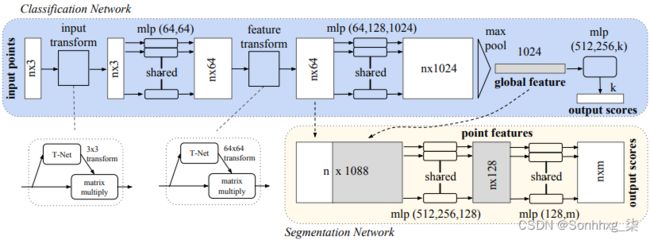
PointNet 是一个多层感知器( MLP )。这是一个前馈网络,仅由完全连接的层(和最大池,但稍后会详细介绍)组成。正如我们所提到的,输入点云向量p i的集合表示为一个n × 3 张量。重要的是要注意网络(直到最大池化层)在集合的所有点之间共享。也就是说,尽管输入大小为n × 3,但我们可以将 PointNet 视为在 n 上应用相同的网络n次输入向量大小为 1 × 3。换句话说,网络权重在点云的所有点之间共享。这种顺序排列还允许任意数量的输入点。
输入通过输入变换(稍后我们将更详细地讨论),它输出另一个n × 3 张量,其中每个n个点由三个分量定义(类似于输入张量)。该张量被馈送到一个上采样全连接层,该层将每个点编码为一个 64 维向量,用于n × 64 输出。网络继续进行另一个转换,类似于输入转换。然后用 64、128、最后 1,024 个全连接层逐渐对结果进行上采样,以产生最终的n × 1024 输出。该张量用作最大池化层的输入,该层取所有n中同一位置的最大元素点并产生一个 1,024 维的输出向量。该向量是整个点集的聚合表示。
但是为什么首先使用最大池呢?请记住,最大池化是一种对称操作——也就是说,无论输入的顺序如何,它都会产生相同的输出。同时,点集也是无序的。使用最大池确保网络将产生相同的结果,而不管点的顺序如何。该论文的作者选择了最大池而不是其他对称函数,例如平均池和求和,因为最大池在基准数据集中展示了最高的准确性。
在最大池化之后,网络根据任务的类型分为两个网络(参见上图):
- 分类:1024D 聚合向量作为几个全连接层的输入,这些全连接层以k路 softmax 结束,其中k是类的数量。这是一个标准的分类管道。
- 分割:这为集合的每个点分配一个类。分类网络的扩展,他的任务需要结合本地和全局知识。如图所示,我们将n 个64D 中间点表示中的每一个与全局 1024D 向量连接起来,以获得一个组合的n × 1088 张量。与网络的初始段一样,该路径也在所有点之间共享。每个点的向量通过一系列(1088 到 512,然后到 256,最后到 128)全连接层被下采样到 128D。最后的全连接层有m个单元(每个类一个)和 softmax 激活。
到目前为止,我们已经通过最大池化操作明确地解决了输入数据的无序性质,但我们仍然需要解决点之间的不变性和交互性。这就是输入和特征转换将有所帮助的地方。让我们从输入变换开始(在上图中,这是 T-net)。T-net 是一个 MLP,类似于完整的 PointNet(它被称为 mini-PointNet),如下图所示:
输入变换 T-net 将n × 3 点集(与完整网络相同的输入)作为输入。与完整的 PointNet 一样,T-net在所有点之间共享。首先,输入被上采样到n × 1024,有 64 个,然后是 128 个,最后是 1024 个单元的全连接层。上采样的输出被馈送到最大池操作,该操作输出 1 × 1024 向量。然后,使用两个 512 和 256 单元的全连接层将向量下采样到 1 × 256。1 × 256 向量乘以 256 × 9 全局(共享)可学习权重矩阵。结果被重新整形为一个 3 × 3 矩阵,在所有点上乘以原始输入点p i以产生最终的n× 3 输出张量。中间的 3 × 3 矩阵在点集上充当一种可学习的仿射变换矩阵。通过这种方式,这些点被归一化为一个熟悉的关于网络的视角——也就是说,网络在变换下变得不变。第二个 T-net(特征变换)与第一个几乎相同,不同之处在于输入张量是n × 64,这会产生一个 64 × 64 的矩阵。
尽管全局最大池化层确保网络不受数据顺序的影响,但它还有另一个缺点,因为它创建了整个输入点集的单一表示;但是,这些点可能属于不同的对象(例如,车辆和行人)。在这种情况下,全局聚合可能会出现问题。为了解决这个问题,PointNet 的作者介绍了 PointNet++(参见PointNet++:Deep Hierarchical Feature Learning on Point Sets in a Metric Space at https://arxiv.org/abs/1706.02413),它是一种分层神经网络,将 PointNet 递归应用于输入点集的嵌套分区。
在本节中,我们研究了 AV 环境感知系统背景下的 3D 数据处理。在下一节中,我们将把注意力转移到具有模仿驾驶策略的路径规划系统上。
模仿驾驶政策
在AV 系统的组件部分,我们概述了自动驾驶系统所需的几个模块。在本节中,我们将了解如何在 DL 的帮助下实施其中之一——驱动策略。一种方法是使用 RL,其中汽车是代理,环境就是环境。另一种流行的方法是模仿学习,其中模型(网络)学习模仿专家(人类)的行为。让我们看看模仿学习在 AV 场景中的属性:
- 我们将使用一种模仿学习,称为行为克隆。这仅仅意味着我们将以有监督的方式训练我们的网络。或者,我们可以在强化学习 (RL) 场景中使用模仿学习,这被称为逆 RL。
- 网络的输出是驾驶策略,由所需的转向角和/或加速或制动表示。例如,我们可以有一个用于转向角的回归输出神经元和一个用于加速或制动的神经元(因为我们不能同时拥有两者)。
- 网络输入可以是以下任意一种:
- 端到端系统的原始传感器数据——例如,来自前置摄像头的图像。单个模型使用原始传感器 输入 并输出驾驶策略的 AV 系统被称为端到端。
- 顺序复合系统的中级环境表示。
- 我们将在专家的帮助下创建训练数据集。我们将让专家在现实世界或模拟器中手动驾驶车辆。在旅程的每一步,我们都会记录以下内容:
- 环境的当前状态。这可能是原始传感器数据或自上而下的视图表示。我们将使用当前状态作为模型的输入。
- 专家在当前环境状态下的动作(转向角和制动/加速)。这将是网络的目标数据。在训练期间,我们将简单地使用熟悉的梯度下降来最小化网络预测和驾驶员行为之间的误差。这样,我们将教网络模仿驱动程序。
行为克隆场景如下图所示:
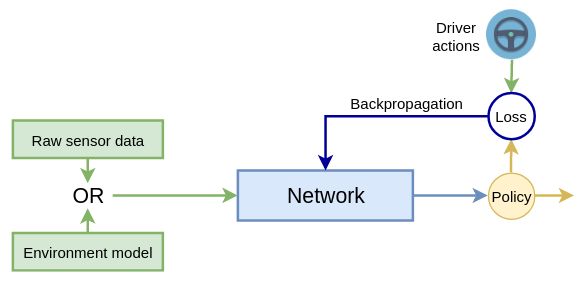
正如我们已经提到的,ALVINN(来自 AV 研究简史部分)是一个行为克隆端到端系统。最近,论文End to End Learning for Self-Driving Cars ( https://arxiv.org/abs/1604.07316 ) 介绍了一个类似的系统,该系统使用具有五个卷积层的 CNN,而不是完全连接的网络。在他们的实验中,车辆上前置摄像头的图像作为输入输入到 CNN。CNN 的输出是单个标量 值,代表汽车所需的转向角。网络不控制加速和制动。为了构建训练数据集,该论文的作者收集了大约 72 小时的真实驾驶视频。在评估期间,该车能够在郊区 98% 的时间内自行驾驶(不包括变道和从一条道路转向另一条道路)。此外,它还设法在一条多车道分隔的高速公路上无干预地行驶了 16 公里。在下一节中,我们将实现一些有趣的东西——一个使用 PyTorch的行为克隆示例。
使用 PyTorch 进行行为克隆
在本节中,我们将使用 PyTorch 1.3.1实现一个 行为克隆示例。 为了帮助我们完成这项任务,我们将使用 OpenAI Gym ( Gym Documentation ),这是一个用于开发和比较强化学习算法的开源工具包。它允许我们教代理承担各种任务,例如走路或玩乒乓球、弹球、其他一些 Atari 游戏甚至 Doom 等游戏。
我们可以安装它: pip
pip install gym[box2d]在本例中,我们将使用OpenAI Gym 环境,如以下屏幕截图所示: CarRacing-v0

目标是让红色赛车(称为代理)在不滑离路面的情况下尽可能快地在赛道上行驶。我们可以使用四种动作来控制汽车:加速、刹车、左转和右转。每个动作的输入是连续的——例如,我们可以指定全油门值为 1.0,半油门值为 0.5(其他控件也是如此)。
为了简单起见,我们假设我们只能指定两个离散的动作值:0 表示无动作,1 表示完全动作。由于最初这是一个 RL 环境,因此代理将在沿轨道前进的每一步获得奖励;但是,我们不会使用它,因为代理会直接从我们的操作中学习。我们将执行以下步骤:
- 通过自己在赛道上驾驶汽车来创建一个训练数据集(我们将使用键盘箭头控制它)。换句话说,我们将成为智能体试图模仿的专家。在剧集的每一步,我们都会记录当前游戏帧(状态)和当前按下的按键,并将它们存储在一个文件中。此步骤的完整代码可在https://github.com/PacktPublishing/Advanced-Deep-Learning-with-Python/blob/master/Chapter11/imitation_learning/keyboard_agent.py获得。您所要做的就是运行文件,游戏就会开始。在您播放时,剧集将被记录在文件中(每五集一次) 。如果你想重新开始,你可以简单地删除它。您可以通过按Escape退出游戏并使用 imitation_learning/data/data.gzip空格键。您也可以按Enter开始新剧集。在这种情况下,当前剧集将被丢弃,其序列将不会被存储。我们建议您至少播放 20 集以获得足够大小的训练数据集。更频繁地使用刹车会很好,否则数据集将变得过于不平衡。在正常比赛中,加速比刹车或转向更频繁地使用。或者,如果您不想玩,GitHub 存储库已经包含一个现有的数据文件。
- 代理由 CNN 表示。我们将使用我们刚刚生成的数据集以监督方式对其进行训练。输入将是单个游戏帧,输出将是转向方向和制动/加速的组合。目标(标签)将是为操作员记录的动作。如果您想省略此步骤,存储库已经有一个训练有素的 PyTorch 网络,位于https://github.com/PacktPublishing/Advanced-Deep-Learning-with-Python/tree/master/Chapter11/imitation_learning/data/model。点。
- 让 CNN 代理通过使用网络输出来确定要发送到环境的下一个动作。您可以通过简单地运行https://github.com/PacktPublishing/Advanced-Deep-Learning-with-Python/blob/master/Chapter11/imitation_learning/nn_agent.py文件来做到这一点。如果您尚未执行前两个步骤中的任何一个,则此文件将使用现有代理。
介绍完之后,让我们继续准备训练数据集。
生成训练数据集
在本节中,我们将了解如何生成训练数据集并将其作为 PyTorchtorch.utils.data.DataLoader类的实例加载。我们将突出显示代码中最相关的部分,但完整的源代码位于https://github.com/PacktPublishing/Advanced-Deep-Learning-with-Python/blob/master/Chapter11/imitation_learning/train。 py
我们将分几个步骤创建训练数据集:
- 该函数读取两个数组:一个用于游戏帧,另一个用于与其关联的键盘组合。 read_data imitation_learning/data/data.gzip numpy
- 环境接受由三元素数组组成的动作,其中以下为真:
- 第一个元素有一个范围内的值[-1, 1],表示转向角(-1对于右,1对于左)。
- 第二个元素在[0, 1]范围内,代表油门。
- 第三个元素在[0, 1] 范围内,代表制动力。
- 我们将使用七种最常见的组合键:[0, 0, 0] 无动作(汽车在滑行)、[0, 1, 0]加速、刹车、左键、左刹车组合键、右键组合键、右刹车组合键。我们故意防止同时使用加速和左或右,因为汽车变得非常不稳定。其余的组合是不可信的。该短语会将这些数组转换为从to的单个类标签。这样,我们将简单地解决一个有七个类别的分类问题。 [0, 0, 1][-1, 0, 0] [-1, 0, 1] [1, 0, 0] [1, 0, 1] read_data06
- 该read_data函数还将平衡数据集。正如我们所提到的,加速是最常见的组合键,而其他一些组合键,例如刹车,是最罕见的。因此,我们将删除一些加速度样本,并乘以一些制动(以及左/右 + 制动)。然而,作者以启发式的方式通过尝试删除/倍增比率的多种组合并选择最有效的组合来做到这一点。如果您记录自己的数据集,您的驾驶风格可能会有所不同,您可能需要修改这些比率。
一旦我们有了训练样本的数组,我们将使用该函数将它们转换为实例。这些类只允许我们以小批量提取数据并应用数据增强。 numpy create_datasetstorch.utils.data.DataLoader
但首先,让我们实现data_transform转换列表,在将图像输入网络 之前 对其进行修改。完整的实现可在Advanced-Deep-Learning-with-Python/util.py at master · PacktPublishing/Advanced-Deep-Learning-with-Python · GitHub获得。我们将图像转换为灰度,标准化[0, 1]范围内的颜色值,并裁剪框架的底部(黑色矩形, 显示 奖励和其他信息)。实现如下:
data_transform = torchvision.transforms.Compose([
torchvision.transforms.ToPILImage(),
torchvision.transforms.Grayscale(1),
torchvision.transforms.Pad((12, 12, 12, 0)),
torchvision.transforms.CenterCrop(84),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize((0,), (1,)),
])接下来,让我们将注意力转移到create_datasets函数上。我们将从声明开始:
def create_datasets():然后,我们将实现帮助类,以便能够对输入图像应用转换。实现如下(请记住缩进,因为这段代码仍然是函数的一部分):TensorDatasetTransforms data_transform create_datasets
class TensorDatasetTransforms(torch.utils.data.TensorDataset):
def __init__(self, x, y):
super().__init__(x, y)
def __getitem__(self, index):
tensor = data_transform(self.tensors[0][index])
return (tensor,) + tuple(t[index] for t in self.tensors[1:])接下来,我们将完整读取之前生成的数据集:
x, y = read_data()
x = np.moveaxis(x, 3, 1) # channel first (torch requirement)然后,我们将创建训练和验证数据加载器(train_loader和val_loader)。最后,我们将它们作为create_datasets函数的结果返回:
# train dataset
x_train = x[:int(len(x) * TRAIN_VAL_SPLIT)]
y_train = y[:int(len(y) * TRAIN_VAL_SPLIT)]
train_set = TensorDatasetTransforms(torch.tensor(x_train), torch.tensor(y_train))
train_loader = torch.utils.data.DataLoader(train_set, batch_size=BATCH_SIZE,
shuffle=True, num_workers=2)
# test dataset
x_val, y_val = x[int(len(x_train)):], y[int(len(y_train)):]
val_set = TensorDatasetTransforms(torch.tensor(x_val), torch.tensor(y_val))
val_loader = torch.utils.data.DataLoader(val_set, batch_size=BATCH_SIZE,
shuffle=False, num_workers=2)
return train_loader, val_loader接下来,让我们关注代理 NN 架构。
.
实现代理神经网络
代理由具有以下属性的 CNN 表示:
- 单输入 84 × 84 切片。
- 三个卷积层,跨步用于下采样。
- ELU 激活。
- 两个全连接层。
- 七个输出神经元(每个神经元一个)。
- 批量归一化和 dropout,在每一层(甚至是卷积层)之后应用,以防止过度拟合。这个任务中的过度拟合特别夸张,因为我们不能使用任何有意义的数据增强技术。例如,假设我们随机水平翻转图像。在这种情况下,我们还必须更改标签以反转转向值。因此,我们将尽可能多地依赖正则化。
以下代码块显示了网络 实现:
def build_network():
return torch.nn.Sequential(
torch.nn.Conv2d(1, 32, 8, 4),
torch.nn.BatchNorm2d(32),
torch.nn.ELU(),
torch.nn.Dropout2d(0.5),
torch.nn.Conv2d(32, 64, 4, 2),
torch.nn.BatchNorm2d(64),
torch.nn.ELU(),
torch.nn.Dropout2d(0.5),
torch.nn.Conv2d(64, 64, 3, 1),
torch.nn.ELU(),
torch.nn.Flatten(),
torch.nn.BatchNorm1d(64 * 7 * 7),
torch.nn.Dropout(),
torch.nn.Linear(64 * 7 * 7, 120),
torch.nn.ELU(),
torch.nn.BatchNorm1d(120),
torch.nn.Dropout(),
torch.nn.Linear(120, len(available_actions)),
)实现了训练数据集和代理后,我们可以继续训练。
训练
我们将在函数的帮助下实现训练本身,该train 函数将网络和设备作为参数。我们将使用交叉熵损失和 Adam 优化器(分类任务的常用组合)。该函数简单地迭代时间并为每个时期调用and函数。以下是实现: cuda EPOCHS train_epoch test
def train(model: torch.nn.Module, device: torch.device):
loss_function = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters())
train_loader, val_order = create_datasets() # read datasets
# train
for epoch in range(EPOCHS):
print('Epoch {}/{}'.format(epoch + 1, EPOCHS))
train_epoch(model, device, loss_function, optimizer, train_loader)
test(model, device, loss_function, val_order)
# save model
model_path = os.path.join(DATA_DIR, MODEL_FILE)
torch.save(model.state_dict(), model_path)然后,我们将实现train_epoch 单个 epoch 训练。此函数迭代所有小批量并为每个小批量执行前向和后向传递。以下是实现:
def train_epoch(model, device, loss_function, optimizer, data_loader):
model.train() # set model to training mode
current_loss, current_acc = 0.0, 0.0
for i, (inputs, labels) in enumerate(data_loader):
inputs, labels = inputs.to(device), labels.to(device) # send to device
optimizer.zero_grad() # zero the parameter gradients
with torch.set_grad_enabled(True):
outputs = model(inputs) # forward
_, predictions = torch.max(outputs, 1)
loss = loss_function(outputs, labels)
loss.backward() # backward
optimizer.step()
current_loss += loss.item() * inputs.size(0) # statistics
current_acc += torch.sum(predictions == labels.data)
total_loss = current_loss / len(data_loader.dataset)
total_acc = current_acc / len(data_loader.dataset)
print('Train Loss: {:.4f}; Accuracy: {:.4f}'.format(total_loss, total_acc))我们将运行大约 100 个 epoch 的训练,但您可以将其缩短到 20 或 30 个 epoch 以进行快速实验。使用默认训练集,一个 epoch 通常需要不到一分钟的时间。现在我们已经熟悉了训练,让我们看看如何在我们的模拟环境中使用代理 NN 来驾驶赛车。
让代理开车
我们将从实现nn_agent_drive 允许代理玩游戏的功能开始(在https://github.com/PacktPublishing/Advanced-Deep-Learning-with-Python/blob/master/Chapter11/imitation_learning/nn_agent 中定义。 py )。该 函数 将以初始状态(游戏帧)启动环境。我们将使用它作为网络的输入。然后,我们将 softmax 网络输出从 one-hot 编码转换为基于数组的动作,并将其发送到环境以进行下一步。我们将重复这些步骤,直到剧集结束。该功能还允许用户通过按Escape 退出。请注意,我们仍然使用与训练相同的转换。 env nn_agent_drivedata_transform
首先,我们将实现初始化部分,它绑定Esc键并初始化环境:
def nn_agent_drive(model: torch.nn.Module, device: torch.device):
env = gym.make('CarRacing-v0')
global human_wants_exit # use ESC to exit
human_wants_exit = False
def key_press(key, mod):
"""Capture ESC key"""
global human_wants_exit
if key == 0xff1b: # escape
human_wants_exit = True
state = env.reset() # initialize environment
env.unwrapped.viewer.window.on_key_press = key_press接下来,我们将实现主循环,其中代理(车辆)获取一个action,环境返回新的state,等等。这种动态反映在无限while循环中(请注意缩进,因为这段代码仍然是 的一部分nn_agent_play):
while 1:
env.render()
state = np.moveaxis(state, 2, 0) # channel first image
state = torch.from_numpy(np.flip(state, axis=0).copy()) # np to tensor
state = data_transform(state).unsqueeze(0) # apply transformations
state = state.to(device) # add additional dimension
with torch.set_grad_enabled(False): # forward
outputs = model(state)
normalized = torch.nn.functional.softmax(outputs, dim=1)
# translate from net output to env action
max_action = np.argmax(normalized.cpu().numpy()[0])
action = available_actions[max_action]
action[2] = 0.3 if action[2] != 0 else 0 # adjust brake power
state, _, terminal, _ = env.step(action) # one step
if terminal:
state = env.reset()
if human_wants_exit:
env.close()
return我们现在拥有运行程序的所有要素,我们将在下一节中进行。
把它们放在一起
最后,我们可以运行整个事情。完整代码可在Advanced-Deep-Learning-with-Python/main.py at master · PacktPublishing/Advanced-Deep-Learning-with-Python · GitHub获得。
以下 代码 段构建和恢复(如果可用)网络、运行训练并评估网络:
# create cuda device
dev = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# create the network
model = build_network()
# if true, try to restore the network from the data file
restore = False
if restore:
model_path = os.path.join(DATA_DIR, MODEL_FILE)
model.load_state_dict(torch.load(model_path))
# set the model to evaluation (and not training) mode
model.eval()
# transfer to the gpu
model = model.to(dev)
# train
train(model, dev)
# agent play
nn_agent_drive(model, dev)虽然我们无法在此处显示代理的运行情况,但您可以按照本节中的说明轻松查看它的运行情况。尽管如此, 我们可以说它学得很好,并且能够定期(但并非总是)在赛道上跑完整圈。有趣的是,网络的驾驶风格与生成数据集的操作员的风格非常相似。这个例子还表明我们不应该低估监督学习。我们 能够 用一个小数据集创建一个表现不错的代理,并且训练时间相对较短。
至此,我们结束了我们的模仿学习示例。接下来,我们将讨论一种更复杂的驾驶策略算法,称为 ChauffeurNet。
使用 ChauffeurNet 的驾驶政策
在本节中,我们将讨论最近发表的一篇名为ChauffeurNet:通过模仿最佳和综合最差来学习驾驶( https://arxiv.org/abs/1812.03079 ) 的论文。它由 AV 领域的领导者之一 Waymo 于 2018 年 12 月发布。让我们看一下ChaffeurNet模型的一些属性:
- 它是两个相互连接的网络的组合。第一个是称为 FeatureNet 的 CNN,它从环境中提取特征。这些特征作为 输入馈送 到称为 AgentRNN 的第二个循环网络,该网络确定驾驶策略。
- 它以与我们在模仿驾驶策略 部分中描述的算法类似的方式使用模仿监督学习。训练集是根据真实世界驾驶事件的记录生成的。ChauffeurNet 可以处理复杂的驾驶情况,例如变道、红绿灯、交通标志、从一条街道到另一条街道的变化等等。
我们将从输入和输出数据表示开始讨论 ChauffeurNet。
输入和输出表示
端到端方法将原始传感器数据(例如,相机图像)提供给 ML 算法 (NN),进而生成驾驶策略(转向角和加速度)。相比之下,ChauffeurNet 使用我们在AV 系统的组件部分中介绍的中级输入和输出。让我们先看看 ML 算法的输入。这是一系列自上而下(鸟瞰)视图的 400 × 400 图像,类似于CarRacing-v0环境图像,但要复杂得多。 时间t的 一个时刻由多个图像表示,其中每个图像都包含环境的不同元素。
我们可以在下图中看到一个 ChauffeurNet 输入/输出组合的示例:

让我们按字母顺序查看输入元素((a)到(g)):
- (a) 是路线图的精确表示。它是一个 RGB 图像,它使用不同的颜色来表示各种道路特征,例如车道、人行横道、交通标志和路缘石。
- (b) 是交通信号灯的灰度图像的时间序列。与 (a) 的特征不同,交通信号灯是动态的——也就是说,它们在不同时间可以是绿色、红色或黄色。为了正确传达它们的动态,该算法使用一系列图像,显示每个车道在过去T场景 秒内直到当前时刻的交通灯状态。每个图像中线条的颜色代表每个交通灯的状态,其中最亮的颜色为红色,中间为黄色,最暗为绿色或未知。
- (c) 是具有已知每条车道限速的灰度图像。不同的颜色强度代表不同的速度限制。
- (d) 是起点和终点之间的预定路线。把它想象成谷歌地图生成的方向。
- (e) 是表示代理当前位置的灰度图像(显示为白框)。
- (f) 是灰度图像的时间序列,表示环境的动态元素(显示为框)。这些可能是其他车辆、行人或骑自行车的人。随着这些对象随时间改变位置,该算法通过一系列快照图像传达它们的轨迹,代表它们在最后T个场景 秒内的位置。这与交通信号灯 (b) 的工作方式相同。
- (g) 是直到当前时刻的过去T姿势秒的代理轨迹的单个灰度图像。 代理位置在图像上显示为一系列点。请注意,我们将它们显示在单个图像中,而不是像其他动态元素那样使用时间序列。时刻t的代理在同一个自上而下的环境中表示
 ,其中
,其中 是坐标,
是坐标, 是方向(或航向),
是方向(或航向), 是速度。
是速度。 - (h) 是算法中层输出:代理的未来轨迹,表示为 一系列点。这些点与过去的轨迹 (g) 具有相同的含义。通过使用直到当前时刻 t 的过去轨迹 (g) 生成时间t+1的未来位置输出。我们将 ChauffeurNet 表示为:

这里,I是所有前面的输入图像,pt 是时间t的代理位置,δt 是 0.2 s 的时间增量。δt的值是任意的,由论文作者选择。一旦我们有了t+δt,我们就可以将它添加到过去的轨迹 (g) 中,并且我们可以使用它在步骤t+2δt以循环方式生成下一个位置。新生成的轨迹被馈送到车辆的控制模块,该模块尽力通过车辆控制(转向、加速和制动)来执行它。
正如我们在AV 系统的组件部分中提到的,这种中级输入表示允许我们轻松使用不同来源的训练数据。它可以通过融合车辆传感器输入(如摄像头和激光雷达)和地图数据(如街道、交通信号灯、交通标志等)从现实世界的驾驶中生成。但我们也可以在模拟环境中生成相同格式的图像。这同样适用于中级输出,其中控制模块可以连接到各种类型的物理车辆或模拟车辆。使用模拟可以从现实世界中很少发生的情况中学习,例如紧急制动甚至碰撞。为了帮助代理了解这种情况,论文的作者使用模拟明确地合成了多个罕见的场景。
现在我们已经熟悉了数据表示,让我们将注意力转移到模型的核心组件上。
模型架构
下图说明了ChauffeurNet 模型架构:
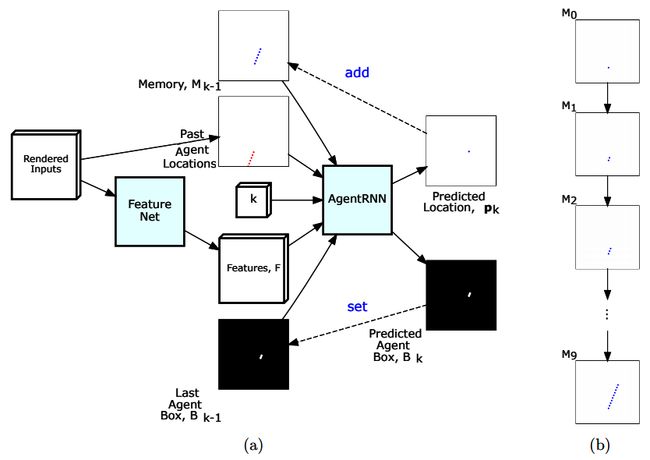
首先,我们有 FeatureNet(在上图中,这由 (a) 标记)。这是一个带有残差连接的 CNN,其输入是我们在输入和输出表示部分中看到的自上而下的图像。FeatureNet 的输出是一个特征向量F ,它代表了合成网络对当前环境的理解。该向量作为循环网络 AgentRNN 的输入之一,它迭代地预测驾驶轨迹中的连续点。假设我们想在步骤k预测智能体轨迹的下一个点。在这种情况下,AgentRNN 具有以下输出:
- p k是在该步骤中预测的行驶轨迹的下一个点。从图中我们可以看出,AgentRNN 的输出实际上是一个与输入图像具有相同维度的热图。它表示空间坐标上的概率分布P k (x, y),它表示下一个航点在热图的每个单元(像素)上的概率。我们使用该arg-max操作从该热图中获得粗略的姿态预测p k。
- B k是第 k 步代理的预测边界框。像路点输出一样,B k是一个热图,但是,在这里,每个单元都使用 sigmoid 激活并表示代理占据该特定像素的概率。
- 还有两个未显示在图表中的附加输出:θ k代表智能体的航向(或方向),s k代表所需速度。
ChauffeurNet 还包括一个附加记忆,用M表示(在上图中,用 (b) 标记)。M是我们在输入和输出表示部分中定义的单通道输入图像 (g) 。它表示过去步骤k的航路点预测 ( p k, p k-1 , ...., p 0 ) 。当前航路点p k 在每一步都被添加到内存中,如上图所示。
输出p k 和B k作为下一步k+1的 AgentRNN 的输入递归地反馈。AgentRNN 输出的公式如下:
![]()
接下来,让我们检查一下 ChauffeurNet 如何在顺序 AV 管道中集成:

该系统类似于我们在AV 系统组件部分介绍的反馈回路。让我们看看它的组成部分:
- 数据渲染器:接收来自环境和动态路由器的输入。它的作用是将这些信号转换为我们在输入和输出表示部分中定义的自上而下的输入图像。
- 动态路由器:根据代理是否能够到达先前的目标坐标,提供动态更新的预期路线。将其视为导航系统,您可以在其中输入目的地,并为您提供前往目标的路线。您开始导航这条路线,如果您偏离路线,系统将根据您当前的位置和目的地动态计算一条新路线。
- 神经网络:ChauffeurNet 模块,输出期望的未来轨迹。
- 控制优化:接收未来轨迹并将其转换为驱动车辆的低级控制信号。
ChauffeurNet 是一个相当复杂的系统,所以现在让我们看看如何训练它。
训练
ChauffeurNet 使用模仿监督学习训练了 3000 万个专家驾驶示例。模型输入是我们在输入和输出表示部分中定义的自上而下的图像,如下面的扁平(聚合)输入图像所示:

最好以彩色方式查看图像。来源:https : //arxiv.org/abs/1812.03079
接下来,我们看一下ChauffeurNet训练过程的组成部分: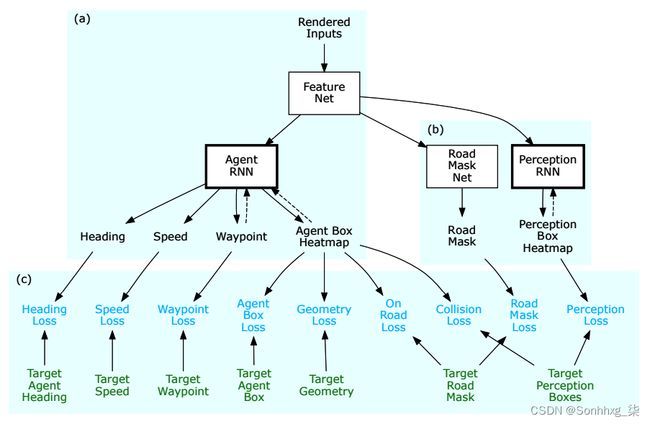
ChauffeurNet 训练组件:(a) 模型本身,(b) 附加网络,以及 (c) 损失。来源:https : //arxiv.org/abs/1812.03079
我们已经熟悉了ChauffeurNet 模型本身(在上图中标记为 (a))。让我们关注该过程中涉及的两个附加网络(在上图中标记为(b)):
- Road Mask N et:在当前输入图像上输出具有路面精确区域的分割掩码。为了更好地理解这一点,下图说明了目标道路掩码(左)和网络的预测道路掩码(右):

来源:https : //arxiv.org/abs/1812.03079
- PerceptionRNN:输出一个分割掩码,其中包含环境中每个其他动态对象(车辆、骑自行车的人、行人等)的预测未来位置。PerceptionRNN 的输出如下图所示,显示了其他车辆的预测位置(浅色矩形):

这些网络不 参与 最终的车辆控制,仅在训练期间使用。使用它们的目的是,与简单地从 AgentRNN 获得反馈相比,如果 FeatureNet 网络从树任务(AgentRNN、Road Mask Net 和 PerceptionRNN)接收反馈,它将学习更好的表示。
现在,让我们关注各种损失函数(ChauffeurNet 模式的底部 (c))。我们将从模仿损失开始,它反映了未来智能体位置的模型预测与人类专家基础事实的不同之处。以下列表显示了AgentRNN输出及其相应的损失函数:
- 预测航路点p k的空间坐标上的概率分布P k (x, y)。我们将使用以下损失来训练这个组件:

这里, 是交叉熵损失,
是交叉熵损失, 是预测分布,
是预测分布, 是真实分布。
是真实分布。
- 代理边界框B k的热图。我们可以使用以下损失来训练它(沿着热图的单元格应用):

这里,W和H是输入图像的尺寸, 是预测的热图,
是预测的热图, 是地面实况热图。
是地面实况热图。
- 具有以下损失的代理θ k的航向(方向) :

这里,θ k是预测方向, 是地面实况方向。
是地面实况方向。
该论文的作者还介绍了过去的运动丢失。我们可以通过引用论文来最好地解释这一点:
他们还观察到,当驾驶情况与专家驾驶训练数据没有显着差异时,模仿学习方法效果很好。但是,代理必须为许多不属于训练的驾驶情况做好准备,例如碰撞。如果代理只依赖于训练数据,它将不得不隐式学习碰撞,这并不容易。为了解决这个问题,本文针对最重要的情况提出了明确的损失函数。其中包括:
- 路点损失:地面实况与预测的代理未来位置p k之间的误差。
- 速度损失:地面实况与预测的智能体未来速度 sk 之间的误差。
- 航向损失:地面实况与预测的代理未来方向θ k之间的误差。
- Agent-box loss:ground truth 和预测的 agent bounding box B k之间的误差。
- 几何损失:强制代理明确地遵循目标轨迹,与速度曲线无关。
- 道路损失:强制代理仅在道路表面区域上导航,并避开环境的非道路区域。如果代理的预测边界框与道路掩模网络预测的图像的非道路区域重叠,这种损失将增加。
- 碰撞损失:明确强制代理避免碰撞。如果代理的预测边界框与环境中任何其他动态对象的边界框重叠,这种损失将会增加。
概括
在本章中,我们探讨了深度学习在 AV 中的应用。我们从对 AV 研究的简要历史概述开始,并讨论了不同程度的自治。然后我们描述了 AV 系统的组件,并确定了何时适合使用 DL 技术。接下来,我们研究了 3D 数据处理和 PointNet。然后我们介绍了使用行为克隆实现驾驶策略的主题,并使用 PyTorch 实现了一个模仿学习示例。最后,我们查看了 Waymo 的 ChauffeurNet 系统。