【SCIR笔记】多模态摘要简述
作者:哈工大SCIR 冯夏冲
1. 摘要
多模态摘要(Multi-modal Summarization)是指输入多种模态信息,通常包括文本,语音,图像,视频等信息,输出一段综合考虑多种模态信息后的核心概括。目前的摘要研究通常以文本为处理对象,一般不涉及其他模态信息的处理。然而,不同模态的信息是相互补充和验证的,充分有效的利用不同模态的信息可以帮助模型更好的定位关键内容,生成更好的摘要。本文首先按照任务类型与模态信息是否同步对多模态摘要进行分类;接着介绍多模态表示中的一些基础知识;最后按照任务类型分类,简述了近几年多模态摘要在教学型视频、多模态新闻、多模态输入多模态输出以及会议中的相关工作,最后给出一些思考与总结。
2. 多模态摘要分类
本文按照多模态摘要(1)面向的任务类型(2)模态信息是否同步对该任务进行分类。
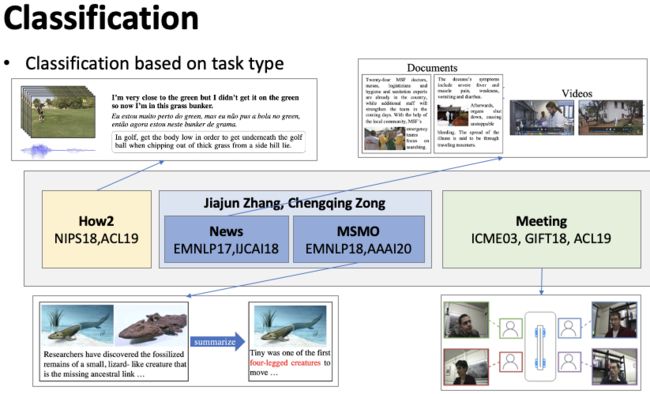
根据多模态摘要面向的任务类型进行分类,如图1所示。(1)教学型视频摘要(How2),How2是一个教学型视频多模态摘要数据集,同时具有视频信息,作者讲解的音频信息,以及对应的文字信息,目标是生成一段教学摘要。(2)多模态新闻摘要旨在对一个包含文字,图片,视频的新闻进行摘要。(3)多模态输入多模态输出摘要(MSMO)是指输入是多模态的,包括了一段文字和一些相关的图片,输出不仅仅要输出文字摘要,还要从输入的图片中选择一个最合适的图片。(2、3)主要为中科院宗成庆老师和张家俊老师的工作。(4)多模态会议摘要,指给定一段会议,包含了会议的视频,每个参与者说话的音频信息,需要生成一个会议摘要。
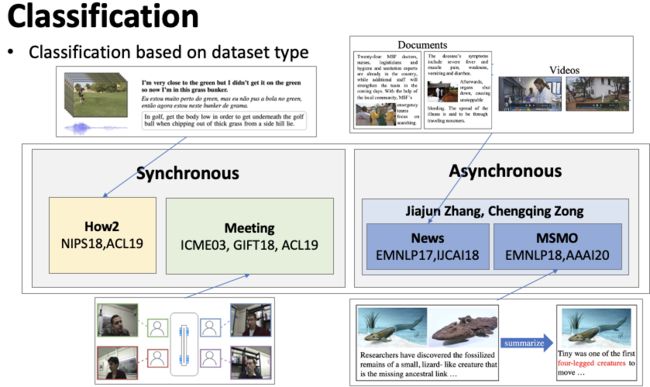
根据模态信息是否同步进行分类,如图2。(1)模态信息同步的多模态摘要,同步是指在每一个时刻,视频,音频,文字唯一对应。例如在一个会议中,某一个时刻,说话人的视频,说的词语,都是唯一对应的。(2)模态信息异步的多模态摘要,也就是多模态信息并非一一对应。例如一个多模态新闻,往往是最开始有一个视频,中间是文本信息,在段落之间会穿插一些图片,因此多模态信息是异步的。
3. 多模态表示基础
这一小节,我们将引入一些多模态表示的基础知识,包括多模态序列到序列模型中的注意力机制,多模态词表示以及多模态预训练模型。
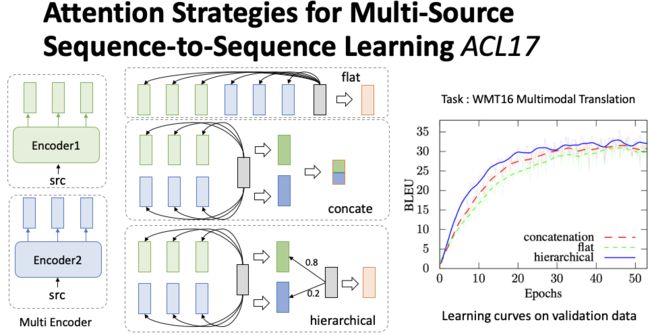
首先是一篇 ACL17 的 Paper Libovický and Helcl, 2017[1],提出了如何在序列到序列框架下对多模态源数据进行 attention。如图3,绿色和蓝色分别代表两种模态的编码端隐层表示,灰色为解码器隐层状态,橙色为注意力向量。假设我们有多种模态的 Encoder,叫做 Multi Encoder,在编码之后,每一个模态会有一个向量序列隐层表示。论文共提出三种注意力机制:(1)第一种方法是flat,即平滑所有编码器端隐层表示。使用解码器隐层状态对平滑后的编码器隐层表示计算注意力得分,最终得到注意力向量;(2)第二种方法是 concat,利用解码器隐层状态分别对两个序列计算得分,并得到分别的注意力向量,然后将多个注意力向量进行拼接并转换到统一维度。(3)第三种方法是 hierarchical,首先得到两个模态对应的注意力向量,然后再利用解码器隐层表示对两个注意力向量计算权重分布,最后根据权重融合多个注意力向量。作者在多模态机器翻译任务上进行实验,发现 hierarchical 的方式是效果最好的,后人的工作基本采用的也都是 hierarchical 的注意力机制。

然后是一篇多模态词表示的工作,是清华大学和 CMU 发表在 AAAI19 上的 paper Wang et al., 2019[2]。核心想法是利用非语言的特征,例如视频和音频来调整词语的表示。举个例子,对于词语讨厌,讨厌在中文中是可以有很多含义的,比如真的讨厌,是一个负向的情感,也可能是女朋友的撒娇,是正向的情感。因此,仅仅根据文本,给定固定的词语表示可能会使得词语语义表示不充分,无法很好地利用到下游任务之中。论文认为引入多模态信息可以缓解这一问题,如图4。当我们提供一个白眼图片信息,讨厌词语表示可以被调整到蓝色点位置。当我们提供另一个图片信息,讨厌词语表示可以被调整到橙色位置。也就是利用非语言模态中的信息补充词语表示的语义信息,使得词语表示更加的合适,或者换一种说法:更加的多模态信息上下文敏感(context sensitive)。
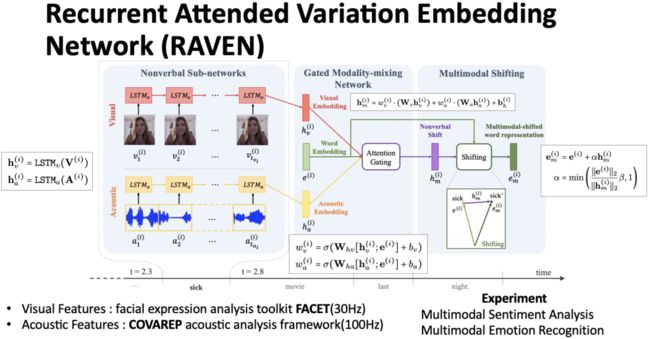
整个多模态词表示模型被称为 RAVEN,分为三个模块。如图5,对于一个词语 sick,有一段对应的连续的视频和音频,分别利用现有的特征抽取工具进行特征抽取(FACET 和 COVAREP),最后得到每一个模态对应的特征表示,红色为视频特征表示,黄色为音频特征表示,绿色为词语特征表示。分别利用视频和音频表示与词语表示计算一个得分,根据该得分进行特征融合,得到一个非语言的偏移向量(紫色)。最终将该向量归一化之后加到词语向量上得到融入多模态信息的词语表示。作者在多模态情感分析和多模态对话情绪识别两个任务上进行实验,相较而言,在情感分析上结果较为显著。

最后这篇是周明老师组在 AAAI20 上提出来的多模态预训练模型 Li et al., 2020[3]。输入部分包括了图片和文本两种模态的信息。对于图片,首先使用工具 Faster R-CNN 抽取其中的具体意义部分,例如卡车,树,马路等,同时会得到对应的特征向量表示及位置信息表示。如图6,模型输入分为三个部分。对于图片,词向量都是 [IMG],segment 都是 img,position 都是 1,除此以外,在进入模型之前需要额外输入:(1)每一个图片的特征向量;(2)图片位置特征。文本部分与 BERT 一致。预训练任务共有三个,其中 MLM 和 MOC 分别是遮盖文字和遮盖图片然后进行预测,VLM使用 [CLS] 标签表示判断输入的图片和文本是否是匹配的。
4. 教学型视频摘要
本小节介绍教学型视频(How2)多模态摘要的相关论文。

How2 数据集 Sanabria et al., 2018[4],发表于 NIPS18,名字来源于 how to do sth,该数据集主要描述教学型视频,如图7,为一个高尔夫教学视频。该数据集包括了视频信息,作者讲解的音频信息,文本信息以及最终的摘要。一共包括了 2000 小时的视频,主题包括运动,音乐,烹饪等。摘要平均 2 到 3 句话。

Palaskar et al., 2019[5]在ACL19上提出了基础的多模态摘要模型用于教学型视频摘要任务,如图8。其模型包括了视频编码器,文本编码器与解码器。视频编码器采用的是 ResNext-101 3D 模型,可以识别 400 种人类的行为动作。文本编码器为基于 RNN 的编码器。在得到两种模态数据的隐层表示之后,结合层次化注意力机制生成最终摘要。实验证明融合文本与视频的模型可以取得最优的效果。
5. 多模态新闻摘要
本小节介绍多模态新闻摘要任务。
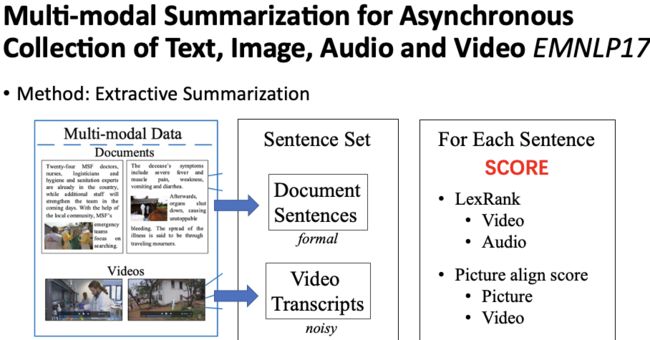
Li et al., 2017[6] 提出了一种抽取式多模态摘要的方法。抽取式摘要的目的是从句子集合中选取一个子集合作为最终摘要。那么对于多模态的输入来讲,这个句子集合分为两个部分。一个是文档句子,另一个是视频的 transcripts,共同作为句子集合,如图9。抽取式方法的核心是给每个句子一个打分。最简单的我们可以使用 TextRank,LexRank 这些基于相似度的方法给每个句子一个打分。但是现在引入了多模态的信息,因此我们可以利用这些多模态的信息进行改进。
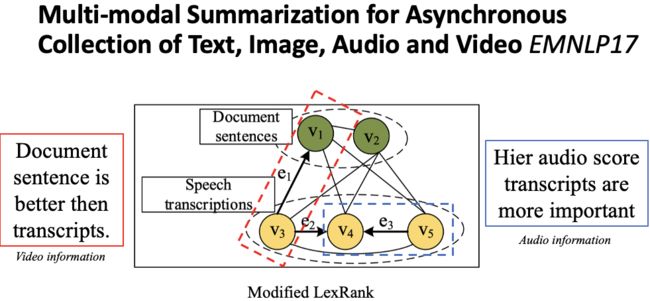
作者在 LexRank 的基础上,融入视频特征和音频特征,将 LexRank 算法中的一些无向边修改为有向边,如图10。对于视频特征,作者认为当一个文档中的句子和一个 transcript 句子相似度高的时候,倾向于选择文档中的句子,因为文档句子更加的规整干净,而 transcript 噪音比较多,因此在计算相似度的时候是有方向性的。例如当 v1 和 v3 相似度高的时候,将权重从 transcript 传向文档句子,通过这种方式使得文档句子得分更高。对于音频特征,作者认为 transcript 句子都有与其对应的音频特征,例如:声学置信度,音频,音量。当一个 transcript 句子音频得分较高时,更应该被选择。因此当两个相邻的 transcript 句子音频得分一个高一个低的时候,会由得分低的句子把相似度权重传递给音频得分高的句子。通过融入视频特征与音频特征,每一个句子都会有一个得分。

作者的另一个假设是文档如果提供了图片,那么这个图片包含的应该是比较有用的信息,因此和图片对齐的句子得分应该高一些。如图11,当一个图片描述 “进口冻虾”时,右上角句子更应该被选做最终摘要句。除了文档中的图片以外,还会从视频中抽取一些关键 frame,简单来讲就是每个场景一个图片。利用图片和关键视频 frame,使用一个外部工具对齐图片和句子。最终每一个句子都可以得到对齐的得分。通过结合改进的 LexRank 得分与图文匹配得分进行最终的摘要句子选取。

Li et al., 2018[7] 提出了多模态句子摘要任务,输入句子和一张图片,输出一个句子摘要,如图12,并构建了任务数据集,作者利用现有 Gigaword 英文数据集去网上检索了每个句子对应的top5 的相关图片,然后又人工选取了其中最合适的一张。最终得到 train,valid, test 的划分分别是 62000,2000,2000。由于图片并非原来数据集自带,因此通过外部得到的图片也可能引入一定的噪音。
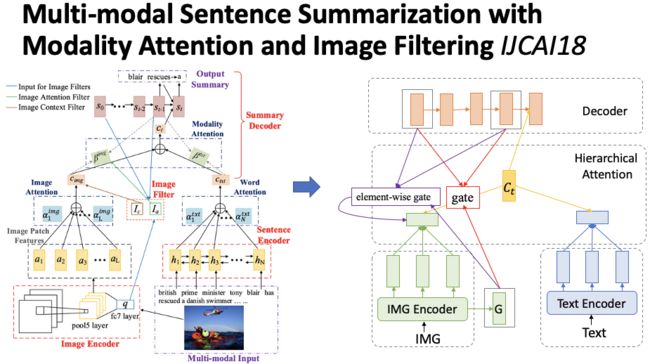
作者提出模型的重点也主要关注如何过滤图片噪音信息。模型核心包括了三个部分,如图13,句子编码器,图片编码器和解码器。句子编码器是一个双向 GRU,图片编码器是 VGG,分别会得到一个序列的隐层表示。在解码的时候,根据层次化注意力机制融合两个模态的注意力向量,最终生成摘要。这属于模型的基本部分。除此以外,为了过滤图片噪音信息,作者还提出了两种过滤机制:(1)第一种作用在图片注意力向量的权重上,相当于一个门,通过图片全局表示,解码器的初始状态与解码器的当前状态计算得到 0 到 1 之间的数值,进一步更新权重。(2)第二种作用在图片注意力向量上,利用上述三个部分计算得到一个向量,向量中的每一个部分都是 0 到 1 之间的数值,利用该门控向量过滤图片信息。最终实验发现第一种方式效果更佳。
6. 多模态输入多模态输出摘要
本节介绍多模态输入多模态输出(Multimodal Summarization with Multimodal Output,MSMO)的相关工作。
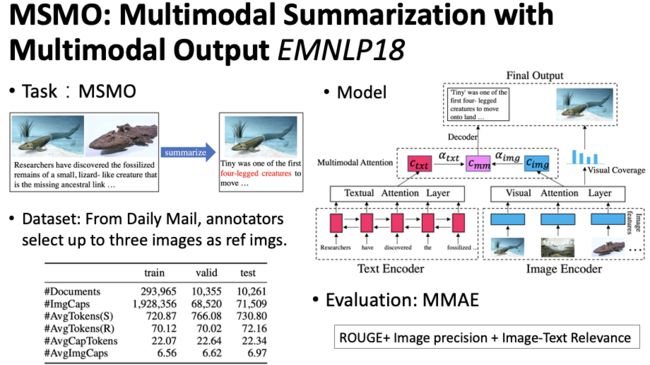
这篇工作是张家俊老师组发表在 EMNLP18 的工作 Zhu et al., 2018[8],作者提出了一个新的多模态摘要任务,输入是多模态的,输出也是多模态的。具体为:输入文本以及几张相关的图片,输出对应的摘要,同时从输入图片中选取一张最重要的图片,如图14。作者提出的模型基础架构与之前类似,包括文本编码器,图片编码器,解码器以及层次化注意力机制。因为该任务的特点在于需要从输入图片中选择一个最重要的图片,作者设计了一种 Visual Coverage 机制来实现,这部分下面会详细介绍。同时作者为了衡量最终的摘要效果,提出了一个考虑多种模态的衡量指标 MMAE,ROUGE 针对文本,image precision 是指选择的图片是否在标准图片中,取值为 0 或 1。image-textrelevance 是指利用外部工具计算最终摘要与选择图片的匹配得分,最后使用逻辑斯蒂回归组合三种得分。为了完成该任务,作者构建了相关数据集,利用现有 Daily Mail 数据集,得到原始对应的相关图片,并使用人工选择至多三张图片作为标准图片。

如图15,展示了 Visual Coverage 机制的一个简单示例。在解码的每一步,会产生一个针对不同图片的注意力分布。当生成全部文本时,将之前所有步的注意力得分进行累加,选择累计得分最高的图片作为最终选择图片。

基于上面的工作,Zhu et al., 2020[9] 认为之前的摘要模型仅仅利用文本标注进行训练,忽略了图片标注的利用。这篇工作除了利用摘要生成时候的文本损失,还利用图片选择的分类损失,如图16。具体来讲,在得到每一个图片的全局表示之后,与解码器的最后一个隐层状态进行相似度计算,然后归一化概率选择图片。但是目前的数据集具有多个图片标准标注,没有唯一的图片标注,因此为了在训练时提供图片监督信号,作者提出了两种构建唯一标注图片标注的方式:(1)ROUGE-ranking,对于每一个图片有一个与之对应的描述(caption),利用该描述与标准文本摘要计算 ROUGE 得分,最终选择 ROUGE 得分最高的描述对应的图片作为唯一标准标注图片;(2)Order-ranking,根据数据集中的图片顺序选择第一个。
7. 多模态会议摘要
本小节介绍多模态会议摘要的相关工作。Improving Productivity Through NLP, Microsoft 指出职员需要花费 37% 的工作时间用于参加会议,每个会议平均会陈述 5000 个词语。如此频繁的会议和冗长的内容给职员造成了极大的负担,因此会议摘要可以帮助快速的总结会议决策信息,提问信息,任务信息等核心内容,缓解职员压力,提高工作效率。但是仅仅利用会议文本信息是不够的,多模态信息,例如视频、音频可以提供更加充足和全方面的信息,例如有人加入了会议,离开了会议;通过一些动作,语音语调,面部表情,识别讨论是否有情绪,是否有争论等等。因此多模态会议摘要逐渐得到了人们的关注。

Erol et al., 2003[10]提出利用多模态特征来定位会议中的重要内容。如图17,一共从三个模态建立特征。音频方面,有两个特征,一个是单位时间窗口内,声音方向的变换次数以及声音幅度。视觉方面,是两个相邻的 frame 的亮度变化。文本方面是 TF-IDF 特征。通过结合上述三种模态的特征来最终定位关键内容。
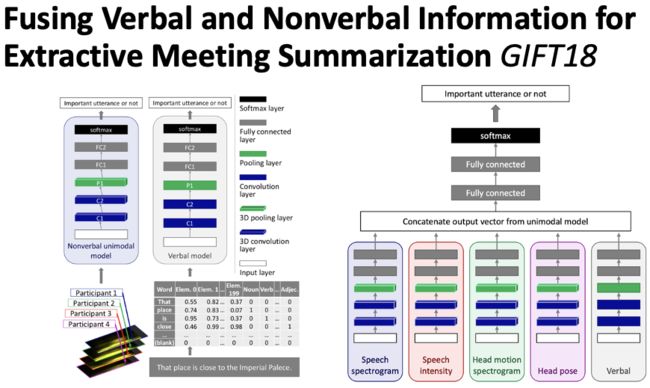
Nihei et al., 2018[11] 使用神经网络来完成抽取式会议摘要任务。融合视频信息,动作信息,声音信息以及文本信息来定位会议关键内容,如图18。

Li et al., 2019[12] 提出在生成式会议摘要中融入多模态特征 Visual Focus Of Attention (VFOA)。作者认为,当一个参与者在发表言论的时候,如果其他人都关注该说话人,那么表示该说话人当前陈述的句子比较重要。因此,对于会议中的一句话,会对应四位参与者的视频,每个视频是由一组frame 组成的。每个 frame 会对应一个五维度的特征,如图19,将该特征输入到神经网络中,预测该视频 frame 中参与者目前正在关注的目标(在数据集中有标准标注)。训练好以后,对于会议中的一句话,将四位参与者的对应视频信息输入到网络中得到输出,进行拼接,得到该句子的 VFOA 特征向量。在解码会议摘要时,会利用到该视觉特征向量进行解码。
8. 总结
本文从任务分类的角度,简单介绍了多模态摘要的相关工作。尽管多模态摘要已经取得了一定的进展,但是依旧存在以下几个关键点值得认真思考:
(1)现有模型结构简单。现有模型架构基本为序列到序列模型结合层次化注意力机制,不同的工作会依据任务特点进行一定的改进。为了更有效的融合多模态信息,发挥模态信息的交互互补作用,在目前架构的基础上,应该思考更加合适的架构。
(2)不同模态信息交互较少。现有工作模态融合的核心在于层次化注意力机制,除此以外,不同模态信息缺少显式的交互方式,无法充分的发挥模态信息之间的互补关系。
(3)依赖于人工先验知识。通常来讲,需要人为预先选择不同类型的预训练特征抽取模型进行特征提取,这一过程依赖于很强的人工判断来预先决定有效的特征,需要一定的领域专业知识。
(4)数据隐私性考虑少。多模态数据在提供更丰富信息的同时,也给数据保密带来了一定的挑战。例如多模态会议数据,其中的声纹特征与脸部特征都是非常重要的个人隐私信息。因此在实际落地中需要充分考虑数据隐私性问题。
(5)单一文本输出缺少多样性。现有工作已经开始尝试多模态输入多模态输出,当输出摘要包含多种模态时,可以满足更广泛人群的需求。例如对于语言不熟悉时,可以通过视频和图片快速了解重要内容。在未来多模态摘要输出也将成为一个重要的研究关注点。
总体而言,在多模态火热发展的大背景下,多模态摘要作为其中的一个分支既具有多模态学习的共性问题,也具有摘要任务自身的个性问题,该任务在近几年开始蓬勃发展,在未来也会成为一个重要的研究方向。
参考资料
[1]
Jindřich Libovický and Jindřich Helcl. Attention strategies for multi-source sequence-to-sequence learning. ACL 2017. https://www.aclweb.org/anthology/P17-2031
[2]Yansen Wang, Ying Shen, Zhun Liu, P. P. Liang, Amir Zadeh, and Louis-Philippe Morency. Words can shift: Dynamically adjusting word representations using nonverbal behaviors. AAAI 2019.
[3]Gen Li, N. Duan, Yuejian Fang, Daxin Jiang, and M. Zhou. Unicoder-vl: A universal encoder forvision and language by cross-modal pre-training. AAAI 2020.
[4]R. Sanabria, Ozan Caglayan, Shruti Palaskar, Desmond Elliott, Loïc Barrault, Lucia Specia,and F. Metze. How2: A large-scale dataset for multimodal language understanding. NeurIPS 2018.
[5]Shruti Palaskar, Jindřich Libovický, Spandana Gella, and F. Metze. Multimodal abstractive summarization for how2 videos. ACL 2019.
[6]Haoran Li, Junnan Zhu, C. Ma, Jiajun Zhang, and C. Zong. Multi-modal summarization forasynchronous collection of text, image, audio and video. 2017.
[7]Haoran Li, Junnan Zhu, Tianshang Liu, Jiajun Zhang, and C. Zong. Multi-modal sentence summarization with modality attention and image filtering. IJCAI 2018.
[8]Junnan Zhu, Haoran Li, Tianshang Liu, Y. Zhou, Jiajun Zhang, and C. Zong. Msmo: Multimodal summarization with multimodal output. EMNLP 2018.
[9]Junnan Zhu, Yin qing Zhou, Jiajun Zhang, Haoran Li, Chengqing Zong, and Changliang Li. Multimodal summarization with guidance of multimodal reference. AAAI 2020.
[10]B. Erol, Dar-Shyang Lee, and J. Hull. Multimodal summarization of meeting recordings. ICME 2003.
[11]Fumio Nihei, Yukiko I. Nakano, and Yutaka Takase. Fusing verbal and nonverbal information forextractive meeting summarization. GIFT 2018.
[12]Manling Li, L. Zhang, H. Ji, and R. Radke. Keep meeting summaries on topic: Abstractive multimodal meeting summarization. ACL 2019.
本期责任编辑:李忠阳
本期编辑:顾宇轩
下载一:中文版!学习TensorFlow、PyTorch、机器学习、深度学习和数据结构五件套!



后台回复【五件套】
下载二:南大模式识别PPT

后台回复【南大模式识别】
说个正事哈
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方“深度学习自然语言处理”,进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心 。
。
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
推荐两个专辑给大家:
专辑 | 李宏毅人类语言处理2020笔记
专辑 | NLP论文解读
专辑 | 情感分析
整理不易,还望给个在看!