【transformer】ViT
目录
- 概述
- 细节
-
- 结构
- patch embedding
- encoder
- MLP head
- 实验
- 简单实现
概述
ViT直接将transformer用于分类任务,给出的最佳模型在ImageNet1K上能够达到88.55%的准确率,说明了transformer同样适用于计算机视觉相关的任务。
但是要是想复现的话,难度是很大的,因为ViT的最佳模型是在google自己的JFT-18K(303million)上预训练的,而这个数据集是不公开的,开源的最大的数据集貌似是ImageNet-21K(14million),另一方面,transformer庞大的参数量也不是一般显卡吃得消的。
细节
结构
主要分为以下的几个部分,首先是patch embedding、添加class-token、positional encoding,中间的transformer encoder部分以及最后的MLP head。

patch embedding
序列化操作:
这个操作是为了将图片转换成sequence。一个直观的思路就是,对于一个HxWxC的图片,将每个像素作为一个vector,那么就会得到长度为一个HxW的sequence,但是这样的话,长度就有点大了。因此,一个新的做法就是,对于一个HxWxC的图片,选取N个patch或者说是N个小图,得到长度为N的sequence。假设patch的长度是p,那么 N = H ∗ W p ∗ p N=\frac{H*W}{p*p} N=p∗pH∗W,每个vector中元素的个数就是 p ∗ p ∗ C p*p*C p∗p∗C,整个sequence就是 N ∗ ( p ∗ p ∗ C ) N * (p*p*C) N∗(p∗p∗C),然后还要做一个映射操作,将维度映射到我们想要的数值,也就是 N ∗ e m b e d d i m N * embed_dim N∗embeddim。
以上是思路,但是在实际实现中,这个操作其实是通过卷积操作实现的,我们设置kernel_size和stride就是我们的patch_size,out_channels就是embed_dim。
class-token:
class-token就是encoder最左边的那个输入,他是我们额外附加的一个token。再说这个之前,以往我们做分类的话,一般是最后接一个全局平均池化操作,将尺寸降到1x1,然后再接一个Linear层做分类。这个做法是蛮cv的,而class-token就是nlp的做法了。class-token对应的输出是经过transformer的,对于整个sequence有一个很好把控的一个输出,我们对他进行监督,达到分类的效果。
positional encoding:
这个点使用NLP的思路比较好理解。如果没有字符的位置的话,对于self-attention操作而言,"我爱你"和"你爱我"这两个句子对应的输出是相同的,因此我们需要添加了位置信息,而添加的方式就是add。毕竟这个信息也是token的,同时也不需要,所以不需要concat。至于位置信息从哪来?可以手工指定,也可以让网络自己学习,一般倾向于后者。
encoder
每个encoder块主要包含四个部分,MSA(多头注意力)、LN(层归一化)、MLP(多层感知机或者说是transformer中写的前馈神经网络),另外还有一个贯穿始终的残差连接。
MSA:链接,链接中self-attention这节中有讲到的,其实就是中间的qkv多几份,最后对应的输出取个平均作为真正的输出。
LN:BN是针对所有的样本,对某一个特征图计算均值和方差,然后然后对这个特征图神经元做归一化。LN是对某一个样本,计算该样本所有特征图的均值和方差,然后对这个样本做归一化。在cv中常用BN,但是NLP中常用LN,当然也能用BN代替,虽然细细说来能说出很多不同,但是其实差不多。
MLP:一个简单的前馈神经网络,核心就是两个全连接层,一个全连接层将将维度扩张若干倍数,另一个线性层将维度变回来,把它当做黑箱的话,其实输入输出shape是一样的。值得注意的话,激活函数用的是GELU,而不是RELU,还是那句话,细细说来能说出很多不同,但是其实差不多。

MLP head
ViT中说MLP是由一个全连层 + Tanh激活 + 全连接层组成。但实际使用起来一层全连接层直接做分类即可。
实验
ViT更需要预训练:
ViT的参数量比较大,所以,ViT模型相较于CNN网络更加需要大数据集的预训练。作者在多个数据集上进行预训练,比较其与CNN模型的性能。在数据量较小时,无论是在ImageNet还是JFT数据集,BiT(以ResNet为骨干的CNN模型)准确率相对更高,但是当数据集量增大到一定程度时,ViT模型略优于CNN模型。所以,ViT模型更需要大数据集进行预训练,以提高模型的表征。
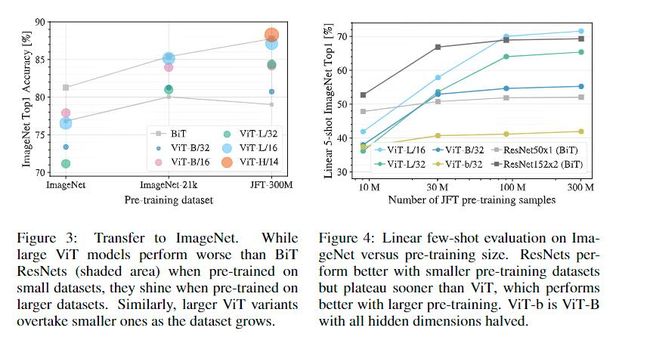
ViT模型更容易泛化到下游任务
对于CNN网络,即使有预训练权重,当使用这个网络泛化到其他下游任务时,也需要训练较长时间才能达到较好的结果。但是,对于ViT模型来说,当拥有ViT的预训练权重时,只需要训练几个epoch既可以拥有很好的性能。如下图所示,训练7个epoch时,ViT类的模型就有一个比较好的效果了。

简单实现
主干部分:
import paddle
import paddle.nn as nn
from attention import Attention
class Mlp(nn.Layer):
def __init__(self,embed_dim,mlp_ratio=4.0,dropout=0.):
super(Mlp, self).__init__()
self.conv1=nn.Linear(embed_dim,int(mlp_ratio*embed_dim))
self.conv2=nn.Linear(int(mlp_ratio*embed_dim),embed_dim)
self.act=nn.GELU()
self.dropout=nn.Dropout(dropout)
def forward(self,x):
x=self.conv1(x)
x=self.act(x)
x=self.dropout(x)
x = self.conv2(x)
x = self.act(x)
x = self.dropout(x)
return x
class PatchEmbedding(nn.Layer):
# img_size是图片大小
# patch_size是patch的大小
# in_channels是图片的通道数
# embed是将patch vector映射到的维度
# dropout一般给0 所以写不写其实一样
def __init__(self,
img_size=224,
patch_size=16,
in_channels=3,
embed_dim=768,
dropout=0.):
super(PatchEmbedding, self).__init__()
self.embed_dim=embed_dim
n_patches=(img_size//patch_size)*(img_size//patch_size)
self.patch_embed=nn.Conv2D(in_channels=in_channels,
out_channels=embed_dim,
kernel_size=patch_size,
stride=patch_size,
bias_attr=False)
self.dropout=nn.Dropout(dropout)
# class token 除了来自图片的visual token之外额外添加一个相同形状的token
# 这个token用于分类
# shape是1*embed_dim好理解的 因为visual token的形状也是这样的 但是前面的batch-size? 显然不知道 暂时先设置为1
self.class_token=paddle.create_parameter(
shape=[1,1,embed_dim],
dtype='float32',
default_initializer=nn.initializer.Constant(0.)
)
# position embedding 给每一个token添加位置信息
# +1是因为包括class_token 给他也加上主要是为了方便
# shape是(n_patches+1)*embed_dim好理解的 前面的batch-size? 显然不知道 暂时先设置为1
self.position_embedding = paddle.create_parameter(
shape=[1,n_patches+1 , embed_dim],
dtype='float32',
default_initializer=nn.initializer.TruncatedNormal(std=.02)
)
def forward(self,x):
# x:[N,C,H,W]
class_token=self.class_token.expand([x.shape[0],1,self.embed_dim]) # 将batch-size这一维加上
# expand操作是将tensor按照指定shape进行拓展
x=self.patch_embed(x) # x:[N,embed_dim,H',W'] H'*W'就是划分出的patch的个数
x=x.flatten(2) # x:[N,embed_dim,H'*W']
x=x.transpose([0,2,1]) # x:[N,H'*W',embed_dim] 或者说是 x:[N,num_patches,embed_dim]
x=paddle.concat([class_token,x],axis=1) # 将cls_token加上去
x=x+self.position_embedding
x=self.dropout(x)
return x
class EncoderLayer(nn.Layer):
def __init__(self,embed_dim=768,num_heads=4,qkv_bias=True,mlp_ratio=4.0,dropout=0.):
super(EncoderLayer, self).__init__()
self.attn_norm=nn.LayerNorm(embed_dim)
self.attn=Attention(embed_dim,num_heads,qkv_bias)
self.mlp_norm=nn.LayerNorm(embed_dim)
self.mlp=Mlp(embed_dim,mlp_ratio)
def forward(self,x):
h=x
x=self.attn_norm(x)
x=self.attn(x)
x=x+h
h=x
x=self.mlp_norm(x)
x=self.mlp(x)
x=x+h
return x
class Encoder(nn.Layer):
def __init__(self,embed_dim,depth):
super(Encoder, self).__init__()
layer_list=[]
for i in range(depth):
encoder_layer=EncoderLayer()
layer_list.append(encoder_layer)
self.layers=nn.LayerList(layer_list)
self.norm=nn.LayerNorm(embed_dim)
def forward(self,x):
for layer in self.layers:
x=layer(x)
x=self.norm(x)
return x
class VisualTransformer(nn.Layer):
def __init__(self,
image_size=224,
patch_size=16,
in_channels=3,
num_classes=1000,
embed_dim=768,
depth=3,
num_heads=8,
mlp_ratio=4,
qkv_bias=True,
dropout=0.,
attention_dropout=0.,
droppath=0.):
super(VisualTransformer, self).__init__()
self.patch_embedding = PatchEmbedding(image_size, patch_size, in_channels, embed_dim)
self.encoder=Encoder(embed_dim,depth)
self.classifier=nn.Linear(embed_dim,num_classes)
def forward(self,x):
# x:[N,C,H,W]
x=self.patch_embedding(x) # x:[N,embed_dim,h',w']
x=self.encoder(x)
x=self.classifier(x[:,0])
return x
def main():
model=VisualTransformer()
paddle.summary(model,(4,3,224,224))
if __name__ == '__main__':
main()
attention部分:
import paddle
import paddle.nn as nn
class Attention(nn.Layer):
def __init__(self,embed_dim,num_heads,qkv_bias=False,qk_scale=None,dropout=0.,attention_dropout=0.):
super(Attention, self).__init__()
self.num_heads=num_heads
self.embed_dim=embed_dim
# 一般不扩大dim 而是对dim的分割
self.head_dim=int(embed_dim/num_heads)
# 防止前面除不尽 所以在写一个 而不是直接用embed_dim,他一个一个直观理解就是所有head加起来有多少dim
self.all_head_dim=self.head_dim*num_heads
# Linear层其实只对最后一维做 所以我们想要处理的 要放到最后去 需要多次的transpose
# 所以这一层的weights就是我们讲理论时候的 W^q,w^k,W^v们
self.qkv=nn.Linear(in_features=embed_dim,
out_features=self.all_head_dim*3) # *3是因为qkv三个
self.scale=self.head_dim**-0.5 if qk_scale is None else qk_scale
self.softmax=nn.Softmax() # 沿着最后一个维度做softmax -1 也是默认参数
self.proj=nn.Linear(self.all_head_dim,embed_dim)
self.dropout=nn.Dropout(dropout)
self.attention_dropout=nn.Dropout(attention_dropout)
def transpose_multi_head(self,x):
# x:[B,num_patches,all_head_dim]
new_shape=x.shape[:-1]+[self.num_heads,self.head_dim]
x=x.reshape(new_shape)
# x:[B,num_patches,num_heads,head_dim]
x=x.transpose([0,2,1,3])
# x:[B,num_heads,num_patches,head_dim]
return x
def forward(self,x):
# x:[B,num_patches,embed_dim]
B,N,_=x.shape
qkv=self.qkv(x).chunk(3,-1)
# qkv是[[B,num_patches,all_head_dim],[B,num_patches,all_head_dim],[B,num_patches,all_head_dim]]
q,k,v=map(self.transpose_multi_head,qkv)
# q,k,v:[B,num_heads,num_patches,head_dim]
atten=paddle.matmul(q,k,transpose_y=True) #做矩阵乘法 相当于是q和k的转置相乘 最后一个维度的head_dim消掉了 api设计就是这样的
atten=self.scale*atten
atten=self.softmax(atten)
atten=self.attention_dropout(atten)
# atten:[B,num_heads,num_patches,num_patches] 就是attention-score的metric了
out=paddle.matmul(atten,v) # 乘完之后变回来了 [B,num_heads,num_patches,head_dim]
out=out.transpose([0,2,1,3])# 变为 [B,num_patches,num_heads,head_dim]了
out=out.reshape([B,N,-1]) # [B,num_patches,all_head_dim]了
out=self.proj(out)
out=self.dropout(out)
return out
def main():
# model=Attention(embed_dim=96,num_heads=4,qkv_bias=False,qk_scale=None)
# # (8,16,96) batch-size是8 num_patches是16 embed_dim是96
# paddle.summary(model,(8,16,96))
print(paddle.nn.functional.softmax(paddle.to_tensor([1.,20.,400.])))
print(paddle.nn.functional.softmax(paddle.to_tensor([0.001,0.02,0.4])))
if __name__ == '__main__':
main()