中文文本纠错
常见错误原因及类型
语音识别(ASR AutomaticSpeechRecognition):谐音(眼镜->眼睛)、混淆音(流浪->牛郎)、方言
形近字:OCR|五笔|手写|拼音(伍拾元->伍抬元,高粱->高梁)
拼音全拼:shanghai->上海
拼音缩写:sh->上海
拼音错误:咳数(ke shu)—> ke sou
字词顺序颠倒
字词补全
语法错误
口语化:呃嗯啊
分析场景错误类型很重要,比如在某比赛中常见错误可以归为4类:多词、缺词、错词、词序
一般流程
错误识别
生成纠正候选(召回率的保证):近音字、近形字
评价纠正候选(排序选择最可能的候选,当比原句优秀时才做纠错):计算句子概率
统计语言模型(Statistical Language Model)
文本为w1w2w3w4w5w6...wn的概率为:
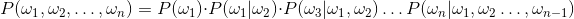
Ngram
由于上面的概率公式参数复杂,对其进行简化,做了一个假设:假设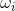 出现的概率只前面N-1个词相关
出现的概率只前面N-1个词相关
将P(wt|w1w2w3w4...wt-1)简化为P(wn|wt-n...wt-1)
pycorrector
安装:pip3 install pycorrector
第一次import这个包,约需要4分钟自动下载模型
import pycorrector
corrected_sent, detail = pycorrector.correct('少先队员因该为老人让坐')
print(corrected_sent, detail) # 少先队员应该为老人让座 [['因该', '应该', 4, 6], ['坐', '座', 10, 11]]
idx_errors = pycorrector.detect('少先队员因该为老人让坐')
print(idx_errors) # [['因该', 4, 6, 'word'], ['坐', 10, 11, 'char']]LSTM+CRF序列标注模型(本质是实体识别,可定位可分类错误类型,不可纠正)
阿里巴巴Alibaba at IJCNLP-2017 Task 1: Embedding Grammatical Features into LSTMs for Chinese Grammatical Error Diagnosis Task
Chinese Grammatical Error Diagnosis using Statistical and Prior Knowledge driven Features with Probabilistic Ensemble Enhancement
可以定位错误位置及类别,不能纠错。BIO标注,B表示错误的开始,I 表示错误的内部,O表示错误的外部,S代表用词错误这一语法错误类别。
本质上是把命名实体识别(Named Entity Recognition,NER)技术迁移过来了,学术上NER所涉及的命名实体一般包括3大类(实体类,时间类,数字类)和7小类(人名、地名、组织机构名、时间、日期、货币、百分比)。
标注需求:标注错误位置及类型

推荐阅读:https://blog.csdn.net/ltochange/article/details/83477976
seq2seq(本质是机器翻译)
标注需求:标注(错误句子-正确句子)样本对
问题:误纠率高
bert(mask)
利用mask位置的上下文来预测当前位置最合适的字,即在每个位置做N类预测。假设容错阈值参数为5,则在Top5中有原来的字,就认为该位置不是错字不纠错。
缺陷:缺乏约束条件,易误纠。如今天识别成金天,但bert不知道该纠成今天还是明天。
优化方法:
1、增加约束条件,缩小预测范围
2、使用类似领域的模型,在此基础上微调(迁移)
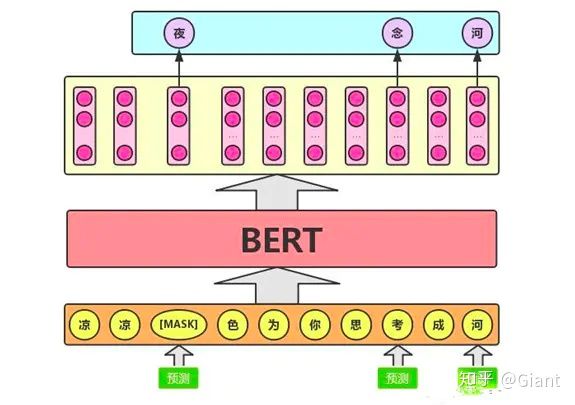
https://zhuanlan.zhihu.com/p/144995580
爱奇艺FASPell
encoder(基于波尔图进行错误检测+错误纠正,预测每个位置的topN)+decoder(基于笔画相似性和拼音相似性对候选进行排序)
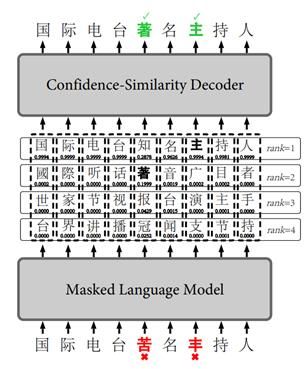
为形成对垂直领域更强对拟合度,不采用bert的随机mask,而是人工mask。
用字符串表征一个字的笔画,如下图每一列分别描述了一个字的编码、字符、发音(声母韵母声调,包含汉语、粤语、日语、韩语、越南语,多音字用‘,’分开,当某个语言没有某个字的发音时用null占位)、笔画(字的结构+每一笔,![]() 是左右结构的意思)
是左右结构的意思)

代码库:https://github.com/iqiyi/FASPell
具体相似性的计算见代码库中的脚本char_sim.py,大致流程为
1、计算lanugages或ids编码的编辑距离
2、归一化,编辑距离/两个字符最大的字符发音或笔画编码长度,这时计算的是差异性
3、相似性=1-差异性,对拼音相似性来说需要计算几种语音相似性的平均值
4、对发音和笔画相似性加权求和,得到整体相似性
这个方法擅长应对拼音、手写、ocr引入的具体某个字符错误,不能解决多字少字的问题(需要seq2seq)。
四角编码(4-5位编码描述字形)
根据汉字左上、右上、左下、右下的四个角的笔形,转化为4-5位的阿拉伯数字编码
缺陷:由于编码空间较小,有些差异性很大的汉字,拥有同样或类似的编码,如量、日编码均为6010。
字符结构
有多种划分粒度,注意不同库的区别
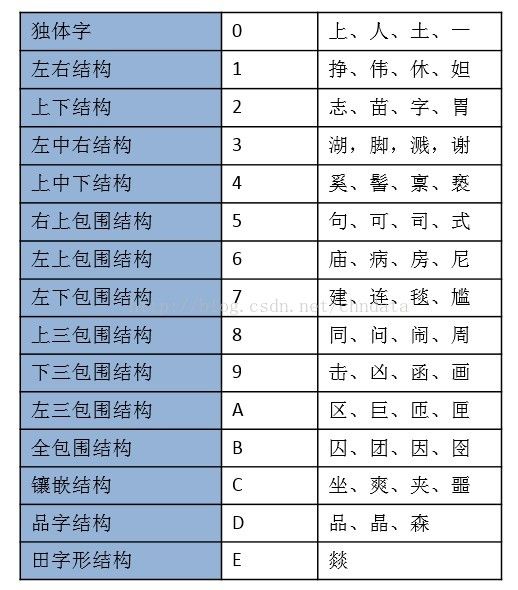
OCR纠错可利用的信息:
1、单个字符的置信度
2、笔画相似性
3、如为固定样式的票据、表格,可使用固定字段关键词表
4、语言模型
5、分词
6、领域词表
nlp多种应用的汇总
https://github.com/fighting41love/funNLP
4位或5位4角码、结构、发音、笔画 库
https://github.com/contr4l/SimilarCharacter