基于Pytorch的深度学习--土堆视频笔记
目录
一、两个重要函数
二、pytorch中读取数据涉及到两个类
三、启动jupyter notebook
四、安装tensorboard
实现tensorboard
add_scalar()
add_image()
五、Transforms
class ToTensor
class ToPILImage
class Normalize
class Compose
class RandmCrop
六、torchvision中的数据集(Dataset)
七、Dataloader
八、神经网络nn
卷积层(Convolution)
池化层(Poolling)
nn.MaxPool2d
非线性激活(Non-linear activation)
ReLU
Sigmoid
批归一化(Normalization)
Recurrent层
Transformer层
线性层(Linear)
Drop out层
Embedding层
Sequential
九、构建网络,可视化
十、损失函数和反向传播
L1Loss()
MSELoss
CrossEntropyLoss 交叉熵
十一、VGG16
十二、模型的保存与加载
保存模型(方式一)
加载模型(方式一)
保存模型(方式二)
加载模型(方式二)
pytorch类似于一个工具箱
一、两个重要函数
1、dir() 打开,看见里面有什么
import torch
dir(torch)
dir(torch.cuda)
dir(torch.cuda.is_available)
2、help() 类似于说明书
help(torch.cuda.is_available)
二、pytorch中读取数据涉及到两个类
Dataset:提供一种方式去获取数据及其label
如何获取每一个数据及其label
告诉我们总共有多少数据


Dataset?? 和 help(Dataset) 都是查看Dataset的解释文档,其中,Dataset?? 更清晰
数据集中的图片信息

数据集列表

Dataset代码练习
from torch.utils.data import Dataset
from PIL import Image
import os
class MyData(Dataset):
def __init__(self,root_dir,label_dir):
self.root_dir = root_dir
self.label_dir = label_dir
self.path = os.path.join(self.root_dir,self.label_dir)
self.img_list = os.listdir(self.path)
def __getitem__(self, idx):
img_name = self.img_list[idx]
path = os.path.join(self.path,img_name)
img = Image.open(path)
label = self.label_dir
return img,label
def __len__(self):
return len(self.img_list)
root_dir = "dataset/train"
ants_label_dir = "ants_image"
bees_label_dir = "bees_image"
ants_dataset = MyData(root_dir,ants_label_dir)
bees_dataset = MyData(root_dir,bees_label_dir)
train_dataset = ants_dataset + bees_dataset
img1,label1 = train_dataset[0]
img1.show()小补充:ctrl + / 添加注释
Dataloader:为后面的网络提供不同的数据形式
三、启动jupyter notebook

conda prompt(anaconda3)-->conda activate pytorch-->jupyter notebook


运行:shift + 回车 或者 导航框中的运行
Python文件 / Python控制台 / Jupyter 的区别
①Python文件
Python文件的块是所有行的代码。
优点:通用,传播方便,适用于大型项目
缺点:需要重头运行
②Python控制台
测试单行代码的作用(小区域的调试)
优点:显示每个变量的属性
缺点:不利于代码阅读(尤其是代码出错的情况下)
③Jupyter(小项目或者调试)
优点:利于代码的阅读及修改
缺点:环境需要配置
pip install opencv-python
四、安装tensorboard
terminal中 pip install tensorboard
实现tensorboard
add_scalar()
add_scalar(tag , scalar_value , global_value)
tag:图表名 scalar_value:y轴 global_value:x轴
add_scalar("图表名","y轴","x轴")
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter("logs")
# y = x
for i in range(100):
writer.add_scalar("y=x",i,i)
writer.close()SummaryWriter是异步工作的,会更新,可能有点慢
在终端输入:
tensorboard --logdir=logs(logdir = 事件文件所在文件夹名)
或者可以更改端口 tensorboard --logdir=logs --port=6007
tensorboard中浅色线表示 未经过平滑处理的曲线,默认的平滑参数为0.6,0为不进行平滑处理,1为最平滑
add_image()
引
# 打印类型 type()
img_path = "dataset/train/ants_image/0013035.jpg"
from PIL import Image
img = Image.open(img_path)
print(type(img)) #add_image("名称",img_tensor,step,dataformats="HWC")
img_tensor可以是torch.Tensor或numpy.array或String/Blobname类型
利用OpenCV读取图片,获得numpy型图片数据
利用numpy.array(),对PIL图片进行转换
常用来观察训练结果
from torch.utils.tensorboard import SummaryWriter
from PIL import Image
import numpy as np
writer = SummaryWriter("../event_log")
image_path = "../dataset/train/bees_image/17209602_fe5a5a746f.jpg"
img_PIL = Image.open(image_path)
img_array = np.array(img_PIL)
writer.add_image("bees",img_array,1,dataformats="HWC")
writer.close()
五、Transforms
常用做图片转换

需要注意的一点是PILImage对象size属性返回的是w, h,而resize的参数顺序是h, w。
一定要搞清楚输入输出的类型 type(XXX)
from torchvision import transforms from PIL import Image
img_path = "../dataset/train/ants_image/6240338_93729615ec.jpg" img_PIL = Image.open(img_path) print(type(img_PIL)) ##1、transforms该如何使用 #先创建一个具体的ToTensor对象 tensor_trans = transforms.ToTensor() #输入图片,输出tensor类型的结果 tensor_img = tensor_trans(img_PIL) print(type(tensor_img)) #
class ToTensor
在tensorboard中显示
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
from PIL import Image
#python-->tensor数据类型
#通过transforms去看两个问题
#1、transforms该如何使用
#2、为什么需要使用Tensor数据类型
img_path = "../dataset/train/ants_image/6240338_93729615ec.jpg"
img_PIL = Image.open(img_path)
writer = SummaryWriter("../logs")
# print(type(img_PIL)) #
#1、transforms该如何使用
#先创建一个具体的ToTensor对象
tensor_trans = transforms.ToTensor()
#输入图片,输出tensor类型的结果
tensor_img = tensor_trans(img_PIL) #内置函数call使得可以采用这种写法
# print(type(tensor_img)) #
writer.add_image("tensor_img",tensor_img)
writer.close()
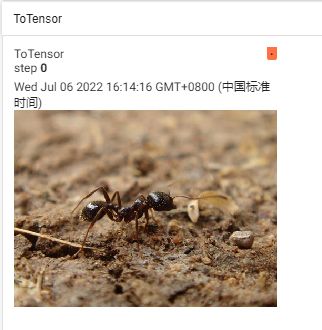
class ToPILImage
tensor-->PIL / ndarray
class Normalize
将一个tensor image归一划:平均值,标准差
# Normalize
trans_norm = transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5])
img_norm = trans_norm(img_tensor)
writer.add_image("Nomalize",img_norm)

class Compose
Compose()中的参数需要是一个列表,列表元素全为transforms型
将多个步骤整合到一起;
如下:PIL-->PIL-->tensor
trans_size_2 = transforms.Resize(512) trans_compose = transforms.Compose([trans_size_2,trans_totensor]) img_resize_2 = trans_compose(img_PIL)
class RandomCrop
随机裁剪
RandomCrop()
一个参数:裁剪成正方形
两个参数:裁剪成H * W的长方形
trans_rondom = transforms.RandomCrop((100,300))
trans_compose_2 = transforms.Compose([trans_rondom,trans_totensor])
for i in range(10):
img_crop = trans_compose_2(img_PIL)
writer.add_image("RandomCropHW",img_crop,i)
六、torchvision中的数据集(Dataset)
root为数据集存放路径
train=True 表示为训练集 False表示为测试集
download=True表示需要从官网下载 False表示不需要
以cifar10数据集为例:
import torchvision from torch.utils.tensorboard import SummaryWriter
dataset_transforms = torchvision.transforms.Compose([ torchvision.transforms.ToTensor() ]) train_set = torchvision.datasets.CIFAR10(root="./dataset",train=True,transform=dataset_transforms,download=True) test_set = torchvision.datasets.CIFAR10(root="./dataset",train=False,transform=dataset_transforms,download=True)
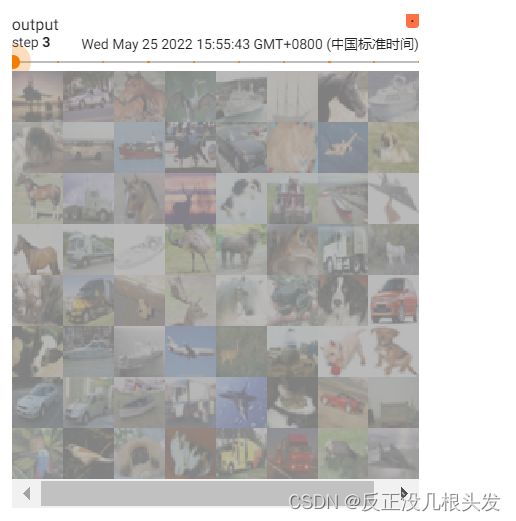
在tensorboard中显示图片
writer = SummaryWriter("p10")
for i in range(10):
img,target = train_set[i]
writer.add_image("test_set", img, i)
writer.close()
七、Dataloader
import torchvision from torch.utils.data import DataLoader from torch.utils.tensorboard import SummaryWriter
定义 测试数据集 和 dataloader
# 测试数据集
test_data = torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor())
# 加载器
test_loader = DataLoader(test_data,batch_size=64,shuffle=True,num_workers=0,drop_last=True)
在tensorboad中进行可视化
writer = SummaryWriter("dataloader")
step = 0
for epoch in range(2):
for data in test_loader:
imgs,targets = data
# print(imgs.shape)
# print(targets)
writer.add_images("Epoch_shuffer:{}".format(epoch),imgs,step)
step += 1
writer.close()
八、神经网络nn
neural network
卷积层(Convolution)
前向:两次卷积,两次非线性
def forward(self, x): x = F.relu(self.conv1(x)) x-->卷积-->非线性-->x return F.relu(self.conv2(x)) x-->卷积-->非线性-->返回
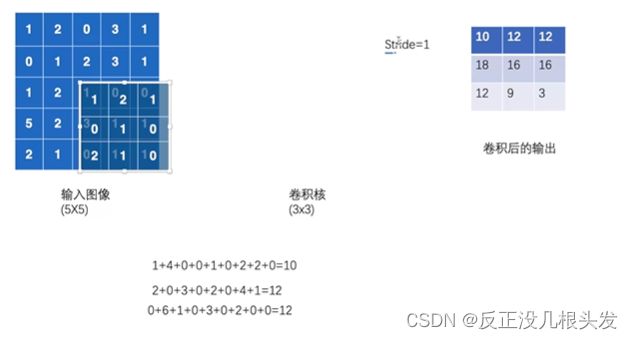
- 卷积核:相当于weight
- 基本卷积层的实质:out = bias + weight *input

- 纠正:上图(卷积后的输出,左下角12改为13)
- padding:对输入进行填充,默认为0,填充时在tensor数据四周填充
- 关于Conv2d的细节:Conv2d — PyTorch 1.12 documentation
out_channel:卷积后的输出 也是卷积核的个数
卷积之前

卷积之后

官方文档看看
池化层(Poolling)
nn.MaxPool2d:最大池化(下采样)
nn.MaxUnPool2d:最大池化(上采样)
nn.AvgPool2d:平均池化
nn.MaxPool2d
最大池化(下采样)
ceil_model = True 保留(继续取)
ceil_model = False 不保留(不取)

尺寸:

最大池化之前

最大池化后的图片像打了马赛克

非线性激活(Non-linear activation)
ReLU
ReLU — PyTorch 1.11.0 documentation
小于0,经过ReLU()后变成0
大于0,经过ReLU()后保持原值
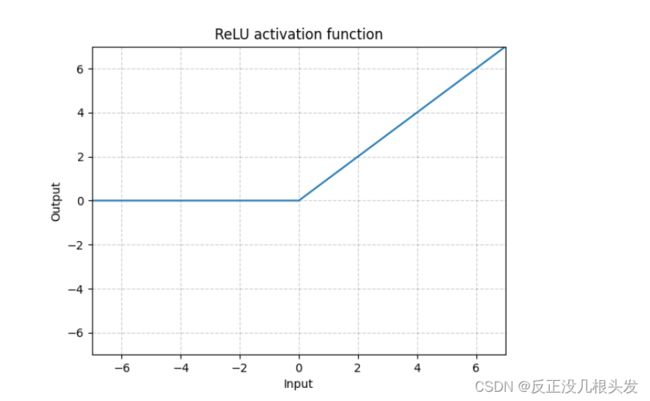
inplace 替换,对原结果的替换
inplace = True input也变
inplace = =False input不变(默认,常用,这样可以保证原值保留)
Sigmoid
Sigmoid — PyTorch 1.11.0 documentation


输入图像

输出图像
非线性变换的主要目的:在神经网络中引入非线性特征,非线性越多,才能训练出符合各种曲线、特征的模型。(使模型有更好地泛化能力)
批归一化(Normalization)
Recurrent层
常用于文字识别
一种特定的网络结构
Transformer层
线性层(Linear)
官方文档:
Linear — PyTorch 1.11.0 documentation

Drop out层
防止过拟合
按概率p把input变成0
Embedding层
自然语言处理
Distance function
计算两个值得误差
Sequential
方便,代码简洁
class Oy(nn.Module): def __init__(self): super(Oy,self).__init__() self.model1 = Sequential( Conv2d(3,32,5,padding=2), MaxPool2d(2), Conv2d(32,32,5,padding=2), MaxPool2d(2), Conv2d(32,64,5,padding=2), MaxPool2d(2), Flatten(), Linear(1024,64), Linear(64,10) ) def forward(self,x): x = self.model1(x) return x
九、构建网络,可视化
writer.add_graph(oy,input)

十、损失函数和反向传播
loss(越小越好):
1、计算实际输出和目标之间的差距
2、为我们更新输出提供一定的依据(反向传播),grad
L1Loss()
差值的绝对值的和的均值
计算公式:

也可以求:差值的绝对值的和,修改redution = "sum"即可

MSELoss
计算公式:平方差 (xi-yi)2

CrossEntropyLoss 交叉熵
训练分类问题,这个问题有c个类别
计算公式:

十一、VGG16
vgg16_false = torchvision.models.vgg16(pretrained=False) vgg16_true = torchvision.models.vgg16(pretrained=True)
False表示未训练
True表示已训练
在现有网络中添加模型
vgg16_true.classifier.add_module("add_linear",nn.Linear(1000,10))
修改
vgg16_false.classifier[6] = nn.Linear(4096,10)
十二、模型的保存与加载
定义一个模型vgg16
import torch import torchvision vgg16 = torchvision.models.vgg16(pretrained=False)
保存模型(方式一)
保存网络模型及其参数
# 保存方式一:模型结构 + 模型参数 torch.save(vgg16,"vgg16_method1.pth")

加载模型(方式一)
(对应上述方式一)
# 方式一 --> 保存方式一,加载模型
model = torch.load("vgg16_method1.pth")
print(model)

保存模型(方式二)
vgg16.state_dict():把网络模型保存成python中的字典形式
#保存方式二:模型参数(官方推荐) torch.save(vgg16.state_dict(),"vgg16_method2.pth")
加载模型(方式二)
vgg16.load_state_dict()
vgg16 = torchvision.models.vgg16(pretrained=False)
vgg16.load_state_dict(torch.load("vgg16_method2.pth"))
# model = torch.load("vgg16_method2.pth") # 加载的是字典形式的数据
print(vgg16)