论文阅读 Frustum PointNets for 3D Object Detection from RGB-D Data
Frustum PointNets for 3D Object Detection from RGB-D Data
Abstract
本文研究了室内和室外场景中基于RGB-D数据的三维目标检测,以前的方法专注于图像或3D体素信息(3D voxels),通常忽视了3D的自然特征和3D数据的不变性,因此我们通过RGB-D扫描直接对原始点云进行操作。关键问题是如何有效地定位大规模场景中的点云中的物体,我们的方法是利用成熟的2D物体探测和先进的3D深度学习来进行物体定位。
1. Introduction
本文我们研究了最重要的三维感知任务–3D物体检测,它将物体类别分类,并从三维传感器数据估计面向三维物体的三维边界框(oriented 3D bounding boxes )。
现在大多数工作都是通过投影将三维点云转化为图像或通过量化转化为体积网格(volumetric grids),然后应用到卷积网络里。最近不少论文提出直接处理点云,而不需要将它们转换成其他格式,例如PointNet。
但我们目前还不清楚PointNet这种架构如何用于3D对象检测,为了实现这一目标,我们必须解决一个关键的问题:如何有效地得到三维物体在三维空间中的可能位置,模仿图像检测中的做法,通过滑动窗口或3D区域建议网络(3D region proposal networks)可以直接枚举候选3D框。然而,3D搜索的计算复杂度通常会随着分辨率的增大而增大,对于大型场景或自动驾驶等实时应用来说,其成本过高。
因此,本文我们遵循降维原则来减小搜索空间:利用成熟的二维物体检测器。首先,我们通过从图像检测器中得到二维边界盒来提取物体的三维边界截体(3D bounding frustum)。接着在每个三维截锥体裁剪的三维空间内,使用两种PointNet的变体连续地进行三维对象实例分割和模态三维边界框回归(amodal 3D bounding box regression)。分割网络预测感兴趣对象的3D掩码(即实例分割)同时回归网络估计模态三维边界框(即使只有部分可见也要覆盖整个对象)。
与之前的方法相比,我们的方法以3D为中心,因为我们将深度图提升到3D点云,并使用3D工具处理它们。这种以3D为中心的视图可以以更有效的方式探索3D数据的新功能:首先,我们在3D坐标上应用一些转换,将点云对齐到一系列更受约束和规范的框架中。使三维学习更容易。第二,在三维空间学习可以更好地利用三维空间的几何和拓扑结构。
本文的主要贡献
• We propose a novel framework for RGB-D data based 3D object detection called Frustum PointNets.
• We show how we can train 3D object detectors under our framework and achieve state-of-the-art performance on standard 3D object detection benchmarks.
• We provide extensive quantitative evaluations to validate our design choices as well as rich qualitative results for understanding the strengths and limitations of our method.
2. Related Work
略过
3. Problem Definition
给定RGB-D数据作为输入,我们的目标是对3D空间中的对象进行分类和定位。从激光雷达获得的深度数据,在RGB摄像机坐标中表示为点云。投影矩阵也是已知的,因此我们可以从2D图像区域得到一个3D截锥,每个对象由一个类(k个预定义类中的一个)和一个模态3D边界框表示,模态框限定整个对象。三维方框由其大小h, w, l,中心点坐标cx, cy, cz和方向θ, φ, ψ组成
4. 3D Detection with Frustum PointNets
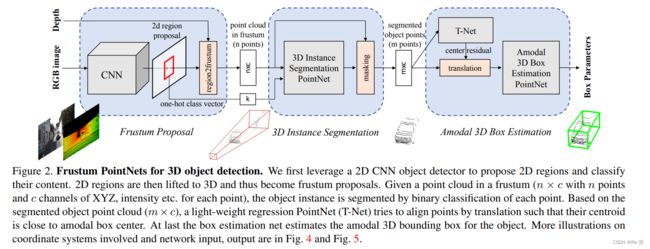
我们的三维物体检测系统由三个模块组成:
- frustum proposal
- 3D instance segmentation
- 3D amodal bounding box estimation
4.1 Frustum Proposal
我们利用二维物体检测器提出二维物体区域以及RGB图像对物体的分类。使用已知的摄像机投影矩阵,可以将2D边界框提升到一个截锥,该截锥为对象定义了一个3D搜索空间,然后我们收集截锥内的所有点,形成截锥点云。由于锥头可能朝向许多不同的方向,这导致点云的位置变化很大。因此,我们通过将截锥旋转到一个中心视图,使截锥的中心轴正交于图像平面,从而将截锥归一化。
我们在ImageNet数据集和COCO数据集上预训练模型权重,并在KITTI 2D对象检测数据集上进一步微调。
4.2 3D Instance Segmentation
给定一个二维图像区域(和它对应的三维截体),可以使用几种方法来获得物体的三维位置:一个直接的解决方案是使用2D的CNN从深度图中直接返回三维物体位置,然而,这个问题并不容易解决,因为遮挡物和背景杂波在自然场景中很常见。由于物体在物理空间中是自然分离的,因此在三维点云中分割要比在图像分割更加自然和容易。考虑到这一点,我们在三维点云中分割实例,而不是在二维图像或深度图中。与Mask-RCNN通过图像区域内像素的二值分类实现实例分割相似,我们使用基于pointnet的网络在截锥点云上实现三维实例分割。
通过对三维实例的分割,可以实现基于残差的三维定位。也就是说,我们预测的是局部坐标系下的三维中心,而不是回归出物体与传感器的绝对位置。
3D Instance Segmentation PointNet
该网络在截锥体中选取一个点云,并预测每个点的概率得分,表明该点属于感兴趣的对象的可能性。注意,每个截锥体只包含一个感兴趣的对象。其他点可以是不相关区域(如地面、植被)的点,也可以是遮挡或位于感兴趣对象后面的其他实例。类似于二维实例分割中的情况,根据截锥体的位置,一个截锥体中的对象点可能会变得混乱。因此,我们的分割PointNet学习了遮挡和杂波模式,以及识别特定类别对象的几何形状。
在多类检测情况下,我们还利用2D检测器的语义信息来更好地分割实例。例如,如果我们知道感兴趣的物体是一个行人,那么分割网络就可以利用这一点来找到看起来像人的几何图形。具体来说,在我们的架构中,我们将语义类别编码为一个热点类向量(预定义的k个类别的k维),并将一个热点向量连接到中间输出的点云特征上。
在获得这些分割的对象点之后,我们进一步规范化其坐标以增强算法的平移不变性。在我们的实现中,我们通过用质心减去XYZ值来将点云转换为局部坐标。
4.3 Amodal 3D Box Estimation
给定被分割的物体点,该模块通过box regression PointNet和经过预处理的transformer network来估计物体的模态三维边界框。
Learning-based 3D Alignment by T-Net
即使我们已经根据它们的质心位置对分割的物体点进行了对齐,我们发现掩模坐标系(mask coordinate frame)的原点可能仍然距离模态框中心(amodal box center)相当远。因此,我们使用一个轻量级回归PointNet (T-Net)来估计整个物体的真正中心,然后转换坐标,使预测的中心成为原点。
Amodal 3D Box Estimation PointNet
网络架构类似于目标分类,但输出不再是对象类的分数,而是三维边界框的参数。我们通过它的中心(cx, cy, cz),大小(h, w, l)和航向角θ(沿上轴)参数化一个3D包围框。我们采用一种“残差”方法来估计框的中心。估计网络预测的中心残差与T-Net之前的中心残差和被掩盖点的质心相结合来得到绝对中心。
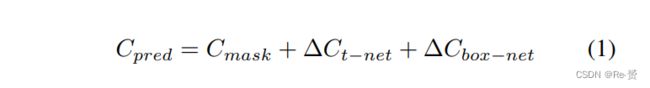
接着通过Box Estimation输出的最终bounding box的维度为3+4xNS+2xNH。其中3代表中心点的残差回归,是接在T-Net回归之后的;NS代表不同size的archor个数,每一个archor有四个维度;NH代表不同朝向的archor,每一个archor有两个参数,分别为置信度和朝向角。
4.4 Training with Multi-task Losses
我们同时优化了涉及的三个网

Corner Loss for Joint Optimization of Box Parameters
虽然我们的3D包围盒参数化是紧凑和完整的,但学习并没有针对最终的3D框精度进行优化——中心、大小和航向有单独的损失项,可能会导致比如:中心和尺寸被准确地预测了,但航向角是错误的。因此,所有三个术语(中心、大小、标题)应该联合优化,以获得最佳的3D框估计,为了解决这个问题,我们提出了一种新的正则化损失:
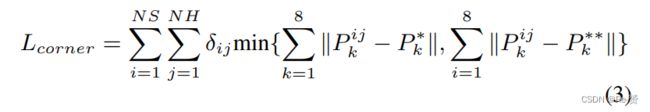
5. Experiments
略过