Rec-Hub组队学习(1)
Task 4
ESMM(阿里cvr基于多任务预估训练框架ESMM)
不同的目标由于业务逻辑,有显式的依赖关系,例如曝光→点击→转化。用户必然是在商品曝光界面中,先点击了商品,才有可能购买转化。阿里提出了ESMM(Entire Space Multi-Task Model)网络,显式建模具有依赖关系的任务联合训练。该模型虽然为多任务学习模型,但本质上是以CVR为主任务,引入CTR和CTCVR作为辅助任务,解决CVR预估的挑战。
背景与动机
传统的CVR预估问题存在着两个主要的问题:样本选择偏差和稀疏数据。下图的白色背景是曝光数据,灰色背景是点击行为数据,黑色背景是购买行为数据。传统CVR预估使用的训练样本仅为灰色和黑色的数据。
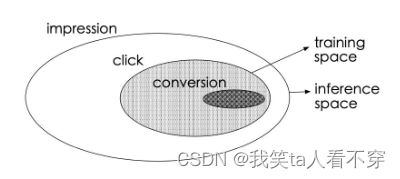
这会导致两个问题:
- 样本选择偏差(sample selection bias,SSB):如图所示,CVR模型的正负样本集合={点击后未转化的负样本+点击后转化的正样本},但是线上预测的时候是样本一旦曝光,就需要预测出CVR和CTR以排序,样本集合={曝光的样本}。构建的训练样本集相当于是从一个与真实分布不一致的分布中采样得到的,这一定程度上违背了机器学习中训练数据和测试数据独立同分布的假设。
- 训练数据稀疏(data sparsity,DS):点击样本只占整个曝光样本的很小一部分,而转化样本又只占点击样本的很小一部分。如果只用点击后的数据训练CVR模型,可用的样本将极其稀疏。
解决方案
阿里妈妈团队提出ESMM,借鉴多任务学习的思路,引入两个辅助任务CTR、CTCVR(已点击然后转化),同时消除以上两个问题。
三个预测任务如下:
- pCTR:p(click=1 | impression);
- pCVR: p(conversion=1 | click=1,impression);
- pCTCVR: p(conversion=1, click=1 | impression) = p(click=1 | impression) * p(conversion=1 | click=1, impression);
注意:其中只有CTR和CVR的label都同时为1时,CTCVR的label才是正样本1。如果出现CTR=0,CVR=1的样本,则为不合法样本,需删除。 pCTCVR是指,当用户已经点击的前提下,用户会购买的概率;pCVR是指如果用户点击了,会购买的概率。
三个任务之间的关系为:

其中x表示曝光,y表示点击,z表示转化。针对这三个任务,设计了如图所示的模型结构:

如图,主任务和辅助任务共享特征,不同任务输出层使用不同的网络,将cvr的预测值*ctr的预测值作为ctcvr任务的预测值,利用ctcvr和ctr的label构造损失函数:

该架构具有两大特点,分别给出上述两个问题的解决方案:
-
帮助CVR模型在完整样本空间建模(即曝光空间X)。

从公式中可以看出,pCVR 可以由pCTR 和pCTCVR推导出。从原理上来说,相当于分别单独训练两个模型拟合出pCTR 和pCTCVR,再通过pCTCVR 除以pCTR 得到最终的拟合目标pCVR 。在训练过程中,模型只需要预测pCTCVR和pCTR,利用两种相加组成的联合loss更新参数。pCVR 只是一个中间变量。而pCTCVR和pCTR的数据是在完整样本空间中提取的,从而相当于pCVR也是在整个曝光样本空间中建模。
- 提供特征表达的迁移学习(embedding层共享)。CVR和CTR任务的两个子网络共享embedding层,网络的embedding层把大规模稀疏的输入数据映射到低维的表示向量,该层的参数占了整个网络参数的绝大部分,需要大量的训练样本才能充分学习得到。由于CTR任务的训练样本量要大大超过CVR任务的训练样本量,ESMM模型中特征表示共享的机制能够使得CVR子任务也能够从只有展现没有点击的样本中学习,从而能够极大地有利于缓解训练数据稀疏性问题。
模型训练完成后,可以同时预测cvr、ctr、ctcvr三个指标,线上根据实际需求进行融合或者只采用此模型得到的cvr预估值。
总结与展望
-
能不能将乘法换成除法? 即分别训练CTR和CTCVR模型,两者相除得到pCVR。论文提供了消融实验的结果,表中的DIVISION模型,比起BASE模型直接建模CTCVRR和CVR,有显著提高,但低于ESMM。原因是pCTR 通常很小,除以一个很小的浮点数容易引起数值不稳定问题。

-
网络结构优化,Tower模型更换?两个塔不一致? 原论文中的子任务独立的Tower网络是纯MLP模型,事实上业界在使用过程中一般会采用更为先进的模型(例如DeepFM、DIN等),两个塔也完全可以根据自身特点设置不一样的模型。这也是ESMM框架的优势,子网络可以任意替换,非常容易与其他学习模型集成。
-
比loss直接相加更好的方式? 原论文是将两个loss直接相加,还可以引入动态加权的学习机制。
-
更长的序列依赖建模? 有些业务的依赖关系不止有曝光-点击-转化三层,后续的改进模型提出了更深层次的任务依赖关系建模。
阿里的ESMM2: 在点击到购买之前,用户还有可能产生加入购物车(Cart)、加入心愿单(Wish)等行为。

相较于直接学习 click->buy (稀疏度约2.6%),可以通过Action路径将目标分解,以Cart为例:click->cart (稀疏 度为10%),cart->buy(稀疏度为12%),通过分解路径,建立多任务学习模型来分步求解CVR模型,缓解稀疏问题,该模型同样也引入了特征共享机制。
美团的AITM:信用卡业务中,用户转化通常是一个曝光->点击->申请->核卡->激活的过程,具有5层的链路。

美团提出了一种自适应信息迁移多任务(**Adaptive Information Transfer Multi-task,AITM**)框架,该框架通过自适应信息迁移(AIT)模块对用户多步转化之间的序列依赖进行建模。AIT模块可以自适应地学习在不同的转化阶段需要迁移什么和迁移多少信息。
总结:
ESMM首创了利用用户行为序列数据在完整样本空间建模,并提出利用学习CTR和CTCVR的辅助任务,迂回学习CVR,避免了传统CVR模型经常遭遇的样本选择偏差和训练数据稀疏的问题,取得了显著的效果。
MMOE是2018年谷歌提出的,全称是Multi-gate Mixture-of-Experts, 对于多个优化任务,引入了多个专家进行不同的决策和组合,最终完成多目标的预测。解决的是硬共享里面如果多个任务相似性不是很强,底层的embedding学习反而相互影响,最终都学不好的痛点。
本篇文章首先是先了解下Hard-parameter sharing以及存在的问题,然后引出MMOE,对理论部分进行整理,最后是参考deepctr简单复现。
背景与动机
推荐系统中,即使同一个场景,常常也不只有一个业务目标。 在Youtube的视频推荐中,推荐排序任务不仅需要考虑到用户点击率,完播率,也需要考虑到一些满意度指标,例如,对视频是否喜欢,用户观看后对视频的评分;在淘宝的信息流商品推荐中,需要考虑到点击率,也需要考虑转化率;而在一些内容场景中,需要考虑到点击和互动、关注、停留时长等指标。
模型中,如果采用一个网络同时完成多个任务,就可以把这样的网络模型称为多任务模型, 这种模型能在不同任务之间学习共性以及差异性,能够提高建模的质量以及效率。 常见的多任务模型的设计范式大致可以分为三大类:
-
hard parameter sharing 方法: 这是非常经典的一种方式,底层是共享的隐藏层,学习各个任务的共同模式,上层用一些特定的全连接层学习特定任务模式。
这种方法目前用的也有,比如美团的猜你喜欢,知乎推荐的Ranking等, 这种方法最大的优势是Task越多, 单任务更加不可能过拟合,即可以减少任务之间过拟合的风险。 但是劣势也非常明显,就是底层强制的shared layers难以学习到适用于所有任务的有效表达。 **尤其是任务之间存在冲突的时候**。MMOE中给出了实验结论,当两个任务相关性没那么好(比如排序中的点击率与互动,点击与停留时长),此时这种结果会遭受训练困境,毕竟所有任务底层用的是同一组参数。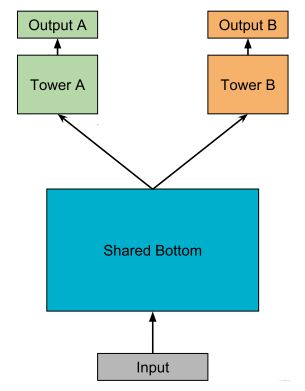
-
soft parameter sharing: 硬的不行,那就来软的,这个范式对应的结果从
MOE->MMOE->PLE等。 即底层不是使用共享的一个shared bottom,而是有多个tower, 称为多个专家,然后往往再有一个gating networks在多任务学习时,给不同的tower分配不同的权重,那么这样对于不同的任务,可以允许使用底层不同的专家组合去进行预测,相较于上面所有任务共享底层,这个方式显得更加灵活 -
任务序列依赖关系建模:这种适合于不同任务之间有一定的序列依赖关系。比如电商场景里面的ctr和cvr,其中cvr这个行为只有在点击之后才会发生。所以这种依赖关系如果能加以利用,可以解决任务预估中的样本选择偏差(SSB)和数据稀疏性(DS)问题
-
样本选择偏差: 后一阶段的模型基于上一阶段采样后的样本子集训练,但最终在全样本空间进行推理,带来严重泛化性问题Copy to clipboardErrorCopied -
样本稀疏: 后一阶段的模型训练样本远小于前一阶段任务
ESSM是一种较为通用的任务序列依赖关系建模的方法,除此之外,阿里的DBMTL,ESSM2等工作都属于这一个范式。 这个范式可能后面会进行整理,本篇文章不过多赘述。
-
通过上面的描述,能大体上对多任务模型方面的几种常用建模范式有了解,然后也知道了hard parameter sharing存在的一些问题,即不能很好的权衡特定任务的目标与任务之间的冲突关系。而这也就是MMOE模型提出的一个动机所在了, 那么下面的关键就是MMOE模型是怎么建模任务之间的关系的,又是怎么能使得特定任务与任务关系保持平衡的?
Multi-Task
-
场景:精排(多任务学习)
-
模型:ESMM、MMOE
-
数据:Ali-CCP数据集
-
学习目标
- 学会使用torch-rechub训练一个ESMM模型
- 学会基于torch-rechub训练一个MMOE模型
-
学习材料:
-
多任务模型介绍:FunRec
-
Ali-CCP数据集官网:数据集-阿里云天池
-
-
注意事项:本教程模型部分的超参数并未调优,欢迎小伙伴在学完教程后参与调参和在全量数据上进行测评工作
#使用pandas加载数据
import pandas as pd
data_path = '' #数据存放文件夹
df_train = pd.read_csv(data_path + 'ali_ccp_train_sample.csv') #加载训练集
df_val = pd.read_csv(data_path + 'ali_ccp_val_sample.csv') #加载验证集
df_test = pd.read_csv(data_path + 'ali_ccp_test_sample.csv') #加载测试集
print("train : val : test = %d %d %d" % (len(df_train), len(df_val), len(df_test)))
#查看数据,其中'click'、'purchase'为标签列,'D'开头为dense特征列,其余为sparse特征,各特征列的含义参考官网描述
print(df_train.head(5)) 使用torch-rechub训练ESMM模型
数据预处理
在数据预处理过程通常需要:
- 对稀疏分类特征进行Lable Encode
- 对于数值特征进行分桶或者归一化
由于本教程中的采样数据以及全量数据已经进行预处理,因此加载数据集可以直接使用。
本次的多任务模型的任务是预测点击和购买标签,是推荐系统中典型的CTR和CVR预测任务。
train_idx, val_idx = df_train.shape[0], df_train.shape[0] + df_val.shape[0]
data = pd.concat([df_train, df_val, df_test], axis=0)
#task 1 (as cvr): main task, purchase prediction
#task 2(as ctr): auxiliary task, click prediction
data.rename(columns={'purchase': 'cvr_label', 'click': 'ctr_label'}, inplace=True)
data["ctcvr_label"] = data['cvr_label'] * data['ctr_label']定义模型
定义一个模型需要指定模型结构参数,需要哪些参数可查看对应模型的定义部分。 对于ESMM而言,主要参数如下:
- user_features指用户侧的特征,只能传入sparse类型(论文中需要分别对user和item侧的特征进行sum_pooling操作)
- item_features指用item侧的特征,只能传入sparse类型
- cvr_params指定CVR Tower中MLP层的参数
- ctr_params指定CTR Tower中MLP层的参数
from torch_rechub.models.multi_task import ESMM
from torch_rechub.basic.features import DenseFeature, SparseFeature
col_names = data.columns.values.tolist()
dense_cols = ['D109_14', 'D110_14', 'D127_14', 'D150_14', 'D508', 'D509', 'D702', 'D853']
sparse_cols = [col for col in col_names if col not in dense_cols and col not in ['cvr_label', 'ctr_label']]
print("sparse cols:%d dense cols:%d" % (len(sparse_cols), len(dense_cols)))
label_cols = ['cvr_label', 'ctr_label', "ctcvr_label"] #the order of 3 labels must fixed as this
used_cols = sparse_cols #ESMM only for sparse features in origin paper
item_cols = ['129', '205', '206', '207', '210', '216'] #assumption features split for user and item
user_cols = [col for col in used_cols if col not in item_cols]
user_features = [SparseFeature(col, data[col].max() + 1, embed_dim=16) for col in user_cols]
item_features = [SparseFeature(col, data[col].max() + 1, embed_dim=16) for col in item_cols]
model = ESMM(user_features, item_features, cvr_params={"dims": [16, 8]}, ctr_params={"dims": [16, 8]})构建dataloader
构建dataloader通常由
- 构建输入字典(字典的键为定义模型时采用的特征名,值为对应特征的数据)
- 通过字典构建相应的dataset和dataloader
from torch_rechub.utils.data import DataGenerator
x_train, y_train = {name: data[name].values[:train_idx] for name in used_cols}, data[label_cols].values[:train_idx]
x_val, y_val = {name: data[name].values[train_idx:val_idx] for name in used_cols}, data[label_cols].values[train_idx:val_idx]
x_test, y_test = {name: data[name].values[val_idx:] for name in used_cols}, data[label_cols].values[val_idx:]
dg = DataGenerator(x_train, y_train)
train_dataloader, val_dataloader, test_dataloader = dg.generate_dataloader(x_val=x_val, y_val=y_val,
x_test=x_test, y_test=y_test, batch_size=1024)训练模型及测试
-
训练模型通过相应的trainer进行,对于多任务的MTLTrainer需要设置任务的类型、优化器的超参数和优化策略等。
-
完成模型训练后对测试集进行测试
import torch
import os
from torch_rechub.trainers import MTLTrainer
device = 'cuda' if torch.cuda.is_available() else 'cpu'
learning_rate = 1e-3
epoch = 1 #10
weight_decay = 1e-5
save_dir = '../examples/ranking/data/ali-ccp/saved'
if not os.path.exists(save_dir):
os.makedirs(save_dir)
task_types = ["classification", "classification"] #CTR与CVR均为二分类任务
mtl_trainer = MTLTrainer(model, task_types=task_types,
optimizer_params={"lr": learning_rate, "weight_decay": weight_decay},
n_epoch=epoch, earlystop_patience=1, device=device, model_path=save_dir)
mtl_trainer.fit(train_dataloader, val_dataloader)
auc = mtl_trainer.evaluate(mtl_trainer.model, test_dataloader)
print(f'test auc: {auc}')
MMOE模型的理论及论文细节
MMOE模型结构图如下。
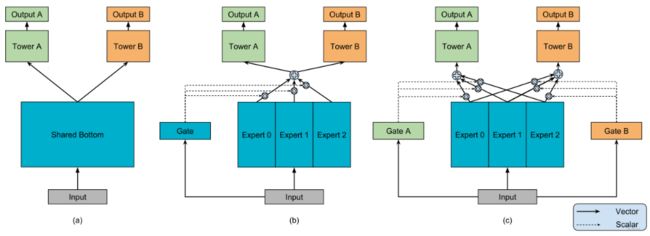
这其实是一个演进的过程,首先hard parameter sharing这个就不用过多描述了, 下面主要是看MOE模型以及MMOE模型。
混合专家模型
我们知道共享的这种模型结构,会遭受任务之间冲突而导致可能无法很好的收敛,从而无法学习到任务之间的共同模式。这个结构也可以看成是多个任务共用了一个专家。
先抛开任务关系, 我们发现一个专家在多任务学习上的表达能力很有限,于是乎,尝试引入多个专家,这就慢慢的演化出了混合专家模型。 公式表达如下:

这里的yy表示的是多个专家的汇总输出,接下来这个东西要过特定的任务塔去得到特定任务的输出。 这里还加了一个门控网络机制,就是一个注意力网络, 来学习各个专家的重要性权重\sum_{i=1}^{n} g(x)_{i}=1∑i=1ng(x)i=1。f_i(x)fi(x)就是每个专家的输出, 而g(x)_ig(x)i就是每个专家对应的权重。 虽然感觉这个东西,无非就是在单个专家的基础上多引入了几个全连接网络,然后又给这几个全连接网络加权,但是在我看来,这里面至少蕴含了好几个厉害的思路:
- 模型集成思想: 这个东西很像bagging的思路,即训练多个模型进行决策,这个决策的有效性显然要比单独一个模型来的靠谱一点,不管是从泛化能力,表达能力,学习能力上,应该都强于一个模型
- 注意力思想: 为了增加灵活性, 为不同的模型还学习了重要性权重,这可能考虑到了在学习任务的共性模式上, 不同的模型学习的模式不同,那么聚合的时候,显然不能按照相同的重要度聚合,所以为各个专家学习权重,默认了不同专家的决策地位不一样。这个思想目前不过也非常普遍了。
- multi-head机制: 从另一个角度看, 多个专家其实代表了多个不同head, 而不同的head代表了不同的非线性空间,之所以说表达能力增强了,是因为把输入特征映射到了不同的空间中去学习任务之间的共性模式。可以理解成从多个角度去捕捉任务之间的共性特征模式。
MOE使用了多个混合专家增加了各种表达能力,但是, 一个门控并不是很灵活,因为这所有的任务,最终只能选定一组专家组合,即这个专家组合是在多个任务上综合衡量的结果,并没有针对性了。 如果这些任务都比较相似,那就相当于用这一组专家组合确实可以应对这多个任务,学习到多个相似任务的共性。 但如果任务之间差的很大,这种单门控控制的方式就不行了,因为此时底层的多个专家学习到的特征模式相差可能会很大,毕竟任务不同,而单门控机制选择专家组合的时候,肯定是选择出那些有利于大多数任务的专家, 而对于某些特殊任务,可能学习的一塌糊涂。
所以,这种方式的缺口很明显,这样,也更能理解为啥提出多门控控制的专家混合模型了。
MMOE结构
Multi-gate Mixture-of-Experts(MMOE)的魅力就在于在OMOE的基础上,对于每个任务都会涉及一个门控网络,这样,对于每个特定的任务,都能有一组对应的专家组合去进行预测。更关键的时候,参数量还不会增加太多。公式如下:.![]() 这里的kk表示任务的个数。 每个门控网络是一个注意力网络:
这里的kk表示任务的个数。 每个门控网络是一个注意力网络:

![]() 表示权重矩阵, n是专家的个数, d是特征的维度。
表示权重矩阵, n是专家的个数, d是特征的维度。
上面的公式这里不用过多解释。
这个改造看似很简单,只是在OMOE上额外多加了几个门控网络,但是却起到了杠杆般的效果,我这里分享下我的理解。
- 首先,就刚才分析的OMOE的问题,在专家组合选取上单门控会产生限制,此时如果多个任务产生了冲突,这种结构就无法进行很好的权衡。 而MMOE就不一样了。MMOE是针对每个任务都单独有个门控选择专家组合,那么即使任务冲突了,也能根据不同的门控进行调整,选择出对当前任务有帮助的专家组合。所以,我觉得单门控做到了针对所有任务在专家选择上的解耦,而多门控做到了针对各个任务在专家组合选择上的解耦。
- 多门控机制能够建模任务之间的关系了。如果各个任务都冲突, 那么此时有多门控的帮助, 此时让每个任务独享一个专家,如果任务之间能聚成几个相似的类,那么这几类之间应该对应的不同的专家组合,那么门控机制也可以选择出来。如果所有任务都相似,那这几个门控网络学习到的权重也会相似,所以这种机制把任务的无关,部分相关和全相关进行了一种统一。
- 灵活的参数共享, 这个我们可以和hard模式或者是针对每个任务单独建模的模型对比,对于hard模式,所有任务共享底层参数,而每个任务单独建模,是所有任务单独有一套参数,算是共享和不共享的两个极端,对于都共享的极端,害怕任务冲突,而对于一点都不共享的极端,无法利用迁移学习的优势,模型之间没法互享信息,互为补充,容易遭受过拟合的困境,另外还会增加计算量和参数量。 而MMOE处于两者的中间,既兼顾了如果有相似任务,那就参数共享,模式共享,互为补充,如果没有相似任务,那就独立学习,互不影响。 又把这两种极端给进行了统一。
- 训练时能快速收敛,这是因为相似的任务对于特定的专家组合训练都会产生贡献,这样进行一轮epoch,相当于单独任务训练时的多轮epoch。
OK, 到这里就把MMOE的故事整理完了,模型结构本身并不是很复杂,非常符合"大道至简"原理,简单且实用。
那么, 为什么多任务学习为什么是有效的呢? 这里整理一个看到比较不错的答案:
多任务学习有效的原因是引入了归纳偏置,两个效果:
- 互相促进: 可以把多任务模型之间的关系看作是互相先验知识,也称为归纳迁移,有了对模型的先验假设,可以更好提升模型的效果。解决数据稀疏性其实本身也是迁移学习的一个特性,多任务学习中也同样会体现
- 泛化作用:不同模型学到的表征不同,可能A模型学到的是B模型所没有学好的,B模型也有其自身的特点,而这一点很可能A学不好,这样一来模型健壮性更强
使用torch-rechub训练MMOE模型
训练MMOE模型的流程与ESMM模型十分相似
需要注意的是MMOE模型同时支持dense和sparse特征作为输入,以及支持分类和回归任务混合
from torch_rechub.models.multi_task import MMOE
# 定义模型
used_cols = sparse_cols + dense_cols
features = [SparseFeature(col, data[col].max()+1, embed_dim=4)for col in sparse_cols] \
+ [DenseFeature(col) for col in dense_cols]
model = MMOE(features, task_types, 8, expert_params={"dims": [16]}, tower_params_list=[{"dims": [8]}, {"dims": [8]}])
#构建dataloader
label_cols = ['cvr_label', 'ctr_label']
x_train, y_train = {name: data[name].values[:train_idx] for name in used_cols}, data[label_cols].values[:train_idx]
x_val, y_val = {name: data[name].values[train_idx:val_idx] for name in used_cols}, data[label_cols].values[train_idx:val_idx]
x_test, y_test = {name: data[name].values[val_idx:] for name in used_cols}, data[label_cols].values[val_idx:]
dg = DataGenerator(x_train, y_train)
train_dataloader, val_dataloader, test_dataloader = dg.generate_dataloader(x_val=x_val, y_val=y_val,
x_test=x_test, y_test=y_test, batch_size=1024)
#训练模型及评估
mtl_trainer = MTLTrainer(model, task_types=task_types, optimizer_params={"lr": learning_rate, "weight_decay": weight_decay}, n_epoch=epoch, earlystop_patience=30, device=device, model_path=save_dir)
mtl_trainer.fit(train_dataloader, val_dataloader)
auc = mtl_trainer.evaluate(mtl_trainer.model, test_dataloader)
Task3
双塔召回模型
双塔模型在推荐领域中是一个十分经典的模型,无论是在召回还是粗排阶段,都会是首选。这主要是得益于双塔模型结构,使得能够在线预估时满足低延时的要求。但也是因为其模型结构的问题,使得无法考虑到user和item特之间的特征交叉,使得影响模型最终效果,因此很多工作尝试调整经典双塔模型结构,在保持在线预估低延时的同时,保证双塔两侧之间有效的信息交叉。下面针对于经典双塔模型以及一些改进版本进行介绍。
经典双塔模型
DSSM(Deep Structured Semantic Model)是由微软研究院于CIKM在2013年提出的一篇工作,该模型主要用来解决NLP领域语义相似度任务 ,利用深度神经网络将文本表示为低维度的向量,用来提升搜索场景下文档和query匹配的问题。DSSM 模型的原理主要是:通过用户搜索行为中query 和 doc 的日志数据,通过深度学习网络将query和doc映射到到共同维度的语义空间中,通过最大化query和doc语义向量之 间的余弦相似度,从而训练得到隐含语义模型,即 query 侧特征的 embedding 和 doc 侧特征的 embedding,进而可以获取语句的低维 语义向量表达 sentence embedding,可以预测两句话的语义相似度。模型结构如下所示:

而在推荐系统中,最为关键的问题是如何做好用户与item的匹配问题,因此对于推荐系统中DSSM模型的则是为 user 和 item 分别构建独立的子网络塔式结构,利用user和item的曝光或点击日期进行训练,最终得到user侧的embedding和item侧的embedding。因此在推荐系统中,常见的模型结构如下所示

从模型结构上来看,主要包括两个部分:user侧塔和item侧塔,对于每个塔分别是一个DNN结构。通过两侧的特征输入,通过DNN模块到user和item的embedding,然后计算两者之间的相似度(常用內积或者余弦值,下面会说这两种方式的联系和区别),因此对于user和item两侧最终得到的embedding维度需要保持一致,即最后一层全连接层隐藏单元个数相同。
在召回模型中,将这种检索行为视为多类分类问题,类似于YouTubeDNN模型。将物料库中所有的item视为一个类别,因此损失函数需要计算每个类的概率值:


以上就是推荐系统中经典的双塔模型,之所以在实际应用中非常常见,是因为在海量的候选数据进行召回的场景下,速度很快,效果说不上极端好,但一般而言效果也够用了。之所以双塔模型在服务时速度很快,是因为模型结构简单(两侧没有特征交叉),但这也带来了问题,双塔的结构无法考虑两侧特征之间的交互信息,在一定程度上牺牲掉模型的部分精准性。例如在精排模型中,来自user侧和item侧的特征会在第一层NLP层就可以做细粒度的特征交互,而对于双塔模型,user侧和item侧的特征只会在最后的內积计算时发生,这就导致很多有用的信息在经过DNN结构时就已经被其他特征所模糊了,因此双塔结构由于其结构问题先天就会存在这样的问题。下面针对这个问题来看看一下现有模型的解决思路。
SENet 双塔模型
SENet由Momenta在2017年提出,当时是一种应用于图像处理的新型网络结构。后来张俊林大佬将SENet引入了精排模型FiBiNET中,其作用是为了将大量长尾的低频特征抛弃,弱化不靠谱低频特征embedding的负面影响,强化高频特征的重要作用。那SENet结构到底是怎么样的呢,为什么可以起到特征筛选的作用?
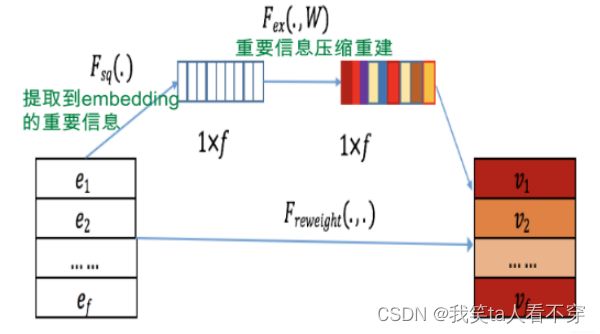
上图可以看出SENET主要分为三个步骤Squeeze, Excitation, Re-weight:
-
Squeeze阶段:我们对每个特征的Embedding向量进行数据压缩与信息汇总,即在Embedding维度计算均值:

其中k表示Embedding的维度,Squeeze阶段是将每个特征的Squeeze转换成单一的数值。



从上图可以发现,具体地是将双塔中的user塔和Item侧塔的特征输入部分加上一个SENet模块,通过SENet网络,动态地学习这些特征的重要性,通过小权重抑制噪音或者无效低频特征,通过大权重放大重要特征影响的目的。
之所以SENet双塔模型是有效的呢?张俊林老师的解释是:双塔模型的问题在于User侧特征和Item侧特征交互太晚,在高层交互,会造成细节信息,也就是具体特征信息的损失,影响两侧特征交叉的效果。而SENet模块在最底层就进行了特征的过滤,使得很多无效低频特征即使被过滤掉,这样更多有用的信息被保留到了双塔的最高层,使得两侧的交叉效果很好;同时由于SENet模块选择出更加重要的信息,使得User侧和Item侧特征之间的交互表达方面增强了DNN双塔的能力。
因此SENet双塔模型主要是从特征选择的角度,提高了两侧特征交叉的有效性,减少了噪音对有效信息的干扰,进而提高了双塔模型的效果。此外,除了这样的方式,还可以通过增加通道的方式来增强两侧的信息交互。即对于user和item两侧不仅仅使用一个DNN结构,而是可以通过不同结构(如FM,DCN等)来建模user和item的自身特征交叉,例如下图所示:
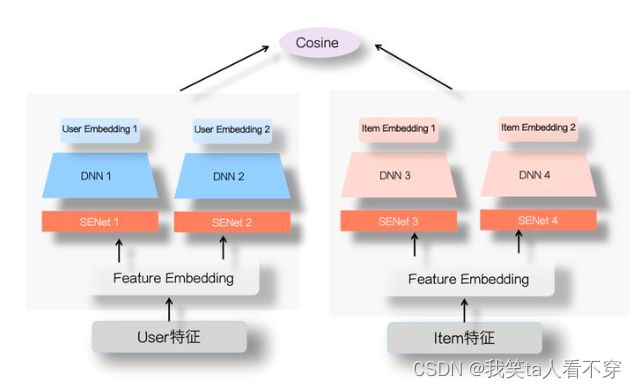
这样对于user和item侧会得到多个embedding,类似于多兴趣的概念。通过得到的多个user和item的embedding,然后分别计算余弦值再相加(两侧的Embedding维度需要对齐),进而增加了双塔两侧的信息交互。而这种方法在腾讯进行过尝试,他们提出的“并联”双塔就是按照这样的思路,感兴趣的可以了解一下。
多目标双塔模型
现如今多任务学习在实际的应用场景也十分的常见,主要是因为实际场景中业务复杂,往往有很多的衡量指标,例如点击,评论,收藏,关注,转发等。在多任务学习中,往往会针对不同的任务使用一个独有的tower,然后优化不同任务损失。那么针对双塔模型应该如何构建多任务学习框架呢?

如上图所示,在user侧和item侧分别通过多个通道(DNN结构)为每个任务得到一个user embedding和item embedding,然后针对不同的目标分别计算user 和 item 的相似度,并计算各个目标的损失,最后的优化目标可以是多个任务损失之和,或者使用多任务学习中的动态损失权重。
这种模型结构,可以针对多目标进行联合建模,通过多任务学习的结构,一方面可以利用不同任务之间的信息共享,为一些稀疏特征提供其他任务中的迁移信息,另一方面可以在召回时,直接使用一个模型得到多个目标预测,解决了多个模型维护困难的问题。也就是说,在线上通过这一个模型就可以同时得到多个指标,例如视频场景,一个模型就可以直接得到点赞,品论,转发等目标的预测值,进而通过这些值计算分数获得最终的Top-K召回结果。
双塔模型细节:参考:FunRec
实战练习
Torch-Rechub Tutorial:Matching
- 场景:召回
- 模型:DSSM、YouTubeDNN
-
数据:MovieLens-1M
-
本教程包括以下内容:
- 在MovieLens-1M数据集上数据集训练一个DSSM召回模型
- 在MovieLens-1M数据集上数据集训练一个YouTubeDNN召回模型
-
在阅读本教程前,希望你对YouTubeDNN和DSSM有一个初步的了解,大概了解数据在模型中是如何流动的,否则直接怼代码可能一脸懵逼。模型介绍:YouTubeDNN DSSM
- 本教程是对
examples/matching/run_ml_dssm.py和examples/matching/run_ml_youtube_dnn.py两个文件的更详细的解释,代码基本与两个文件一致。 - 本框架还在开发阶段,可能还有一些bug。如果你在复现后,发现指标明显高于当前,欢迎与我们交流。
import torch
import pandas as pd
import numpy as np
import os
pd.set_option('display.max_rows',500)
pd.set_option('display.max_columns',500)
pd.set_option('display.width',1000)
torch.manual_seed(2022)
file_path = 'ml-1m_sample.csv'
data = pd.read_csv(file_path)
print(data.head())特征预处理
在本DSSM模型中,我们使用两种类别的特征,分别是稀疏特征(SparseFeature)和序列特征(SequenceFeature)。
-
对于稀疏特征,是一个离散的、有限的值(例如用户ID,一般会先进行LabelEncoding操作转化为连续整数值),模型将其输入到Embedding层,输出一个Embedding向量。
-
对于序列特征,每一个样本是一个List[SparseFeature](一般是观看历史、搜索历史等),对于这种特征,默认对于每一个元素取Embedding后平均,输出一个Embedding向量。此外,除了平均,还有拼接,最值等方式,可以在pooling参数中指定。
-
框架还支持稠密特征(DenseFeature),即一个连续的特征值(例如概率),这种类型一般需归一化处理。但是本样例中未使用。
以上三类特征的定义在torch_rechub/basic/features.py
# 处理genres特征,取出其第一个作为标签
data["cate_id"] = data["genres"].apply(lambda x: x.split("|")[0])
# 指定用户列和物品列的名字、离散和稠密特征,适配框架的接口
user_col, item_col = "user_id", "movie_id"
sparse_features = ['user_id', 'movie_id', 'gender', 'age', 'occupation', 'zip', "cate_id"]
dense_features = []
save_dir = 'saved/'
if not os.path.exists(save_dir):
os.makedirs(save_dir)
# 对SparseFeature进行LabelEncoding
from sklearn.preprocessing import LabelEncoder
print(data[sparse_features].head())
feature_max_idx = {}
for feature in sparse_features:
lbe = LabelEncoder()
data[feature] = lbe.fit_transform(data[feature]) + 1
feature_max_idx[feature] = data[feature].max() + 1
if feature == user_col:
user_map = {encode_id + 1: raw_id for encode_id, raw_id in enumerate(lbe.classes_)} #encode user id: raw user id
if feature == item_col:
item_map = {encode_id + 1: raw_id for encode_id, raw_id in enumerate(lbe.classes_)} #encode item id: raw item id
np.save(save_dir+"raw_id_maps.npy", (user_map, item_map)) # evaluation时会用到
print('LabelEncoding后:')
print(data[sparse_features].head())用户塔与物品塔
在DSSM中,分为用户塔和物品塔,每一个塔的输出是用户/物品的特征拼接后经过MLP(多层感知机)得到的。 下面我们来定义物品塔和用户塔都有哪些特征:
# 定义两个塔对应哪些特征
user_cols = ["user_id", "gender", "age", "occupation", "zip"]
item_cols = ['movie_id', "cate_id"]
# 从data中取出相应的数据
user_profile = data[user_cols].drop_duplicates('user_id')
item_profile = data[item_cols].drop_duplicates('movie_id')
print(user_profile.head())
print(item_profile.head())序列特征的处理
本数据集中的序列特征为观看历史,根据timestamp来生成,具体在generate_seq_feature_match函数中实现。参数含义如下:
mode表示样本的训练方式(0 - point wise, 1 - pair wise, 2 - list wise)neg_ratio表示每个正样本对应的负样本数量,min_item限制每个用户最少的样本量,小于此值将会被抛弃,当做冷启动用户处理(框架中还未添加冷启动的处理,这里直接抛弃)sample_method表示负采样方法。
关于参数
mode的一点小说明:在模型实现过程中,框架只考虑了论文中提出的样本的训练方式,用其他方式可能会报错。例如:DSSM中采用point wise的方式,即mode=0,如果传入别的mode,不保证能正确运行,但是论文中对应的训练方式是能保证正确运行的。
from torch_rechub.utils.match import generate_seq_feature_match, gen_model_input
df_train, df_test = generate_seq_feature_match(data,
user_col,
item_col,
time_col="timestamp",
item_attribute_cols=[],
sample_method=1,
mode=0,
neg_ratio=3,
min_item=0)
print(df_train.head())
x_train = gen_model_input(df_train, user_profile, user_col, item_profile, item_col, seq_max_len=50)
y_train = x_train["label"]
x_test = gen_model_input(df_test, user_profile, user_col, item_profile, item_col, seq_max_len=50)
y_test = x_test["label"]
print({k: v[:3] for k, v in x_train.items()})
#定义特征类型
from torch_rechub.basic.features import SparseFeature, SequenceFeature
user_features = [
SparseFeature(feature_name, vocab_size=feature_max_idx[feature_name], embed_dim=16) for feature_name in user_cols
]
user_features += [
SequenceFeature("hist_movie_id",
vocab_size=feature_max_idx["movie_id"],
embed_dim=16,
pooling="mean",
shared_with="movie_id")
]
item_features = [
SparseFeature(feature_name, vocab_size=feature_max_idx[feature_name], embed_dim=16) for feature_name in item_cols
]
print(user_features)
print(item_features)
# 将dataframe转为dict
from torch_rechub.utils.data import df_to_dict
all_item = df_to_dict(item_profile)
test_user = x_test
print({k: v[:3] for k, v in all_item.items()})
print({k: v[0] for k, v in test_user.items()})训练模型
-
根据之前的x_train字典和y_train等数据生成训练用的Dataloader(train_dl)、测试用的Dataloader(test_dl, item_dl)。
-
定义一个双塔DSSM模型,
user_features表示用户塔有哪些特征,user_params表示用户塔的MLP的各层维度和激活函数。(Note:在这个样例中激活函数的选取对最终结果影响很大,调试时不要修改激活函数的参数) - 定义一个召回训练器MatchTrainer,进行模型的训练。
from torch_rechub.models.matching import DSSM
from torch_rechub.trainers import MatchTrainer
from torch_rechub.utils.data import MatchDataGenerator
# 根据之前处理的数据拿到Dataloader
dg = MatchDataGenerator(x=x_train, y=y_train)
train_dl, test_dl, item_dl = dg.generate_dataloader(test_user, all_item, batch_size=256)
# 定义模型
model = DSSM(user_features,
item_features,
temperature=0.02,
user_params={
"dims": [256, 128, 64],
"activation": 'prelu', # important!!
},
item_params={
"dims": [256, 128, 64],
"activation": 'prelu', # important!!
})
# 模型训练器
trainer = MatchTrainer(model,
mode=0, # 同上面的mode,需保持一致
optimizer_params={
"lr": 1e-4,
"weight_decay": 1e-6
},
n_epoch=1,
device='cpu',
model_path=save_dir)
# 开始训练
trainer.fit(train_dl)向量化召回 评估
- 使用trainer获取测试集中每个user的embedding和数据集中所有物品的embedding集合
- 用annoy构建物品embedding索引,对每个用户向量进行ANN(Approximate Nearest Neighbors)召回K个物品
- 查看topk评估指标,一般看recall、precision、hit
import collections
import numpy as np
import pandas as pd
from torch_rechub.utils.match import Annoy
from torch_rechub.basic.metric import topk_metrics
def match_evaluation(user_embedding, item_embedding, test_user, all_item, user_col='user_id', item_col='movie_id',
raw_id_maps="./raw_id_maps.npy", topk=10):
print("evaluate embedding matching on test data")
annoy = Annoy(n_trees=10)
annoy.fit(item_embedding)
#for each user of test dataset, get ann search topk result
print("matching for topk")
user_map, item_map = np.load(raw_id_maps, allow_pickle=True)
match_res = collections.defaultdict(dict) # user id -> predicted item ids
for user_id, user_emb in zip(test_user[user_col], user_embedding):
items_idx, items_scores = annoy.query(v=user_emb, n=topk) #the index of topk match items
match_res[user_map[user_id]] = np.vectorize(item_map.get)(all_item[item_col][items_idx])
#get ground truth
print("generate ground truth")
data = pd.DataFrame({user_col: test_user[user_col], item_col: test_user[item_col]})
data[user_col] = data[user_col].map(user_map)
data[item_col] = data[item_col].map(item_map)
user_pos_item = data.groupby(user_col).agg(list).reset_index()
ground_truth = dict(zip(user_pos_item[user_col], user_pos_item[item_col])) # user id -> ground truth
print("compute topk metrics")
out = topk_metrics(y_true=ground_truth, y_pred=match_res, topKs=[topk])
return out
user_embedding = trainer.inference_embedding(model=model, mode="user", data_loader=test_dl, model_path=save_dir)
item_embedding = trainer.inference_embedding(model=model, mode="item", data_loader=item_dl, model_path=save_dir)
match_evaluation(user_embedding, item_embedding, test_user, all_item, topk=10, raw_id_maps=save_dir+"raw_id_maps.npy")
YouTubeNN召回
YouTubeDNN模型是2016年的一篇文章,虽然离着现在有些久远, 但这篇文章无疑是工业界论文的典范, 完全是从工业界的角度去思考如何去做好一个推荐系统,并且处处是YouTube工程师留给我们的宝贵经验, 由于这两天用到了这个模型,今天也正好重温了下这篇文章,所以借着这个机会也整理出来吧, 王喆老师都称这篇文章是"神文", 可见其不一般处。
今天读完之后, 给我的最大感觉,首先是从工程的角度去剖析了整个推荐系统,讲到了推荐系统中最重要的两大模块: 召回和排序, 这篇论文对初学者非常友好,之前的论文模型是看不到这么全面的系统的,总有一种管中规豹的感觉,看不到全局,容易着相。 其次就是这篇文章给出了很多优化推荐系统中的工程性经验, 不管是召回还是排序上,都有很多的套路或者trick,比如召回方面的"example age", "负采样","非对称消费,防止泄露",排序方面的特征工程,加权逻辑回归等, 这些东西至今也都非常的实用,所以这也是这篇文章厉害的地方。
本篇文章依然是以paper为主线, 先剖析paper里面的每个细节,当然我这里也参考了其他大佬写的文章,王喆老师的几篇文章写的都很好,链接我也放在了下面,建议也看看。然后就是如何用YouTubeDNN模型,代码复现部分,由于时间比较短,自己先不复现了,调deepmatch的包跑起来,然后在新闻推荐数据集上进行了一些实验, 尝试了论文里面讲述的一些方法,这里主要是把deepmatch的YouTubeDNN模型怎么使用,以及我整个实验过程的所思所想给整理下, 因为这个模型结构本质上并不是很复杂(三四层的全连接网络),就不自己在实现一遍啦, 一些工程经验或者思想,我觉得才是这篇文章的精华部分。
引言与推荐系统的漏斗范式
引言部分
本篇论文是工程性论文(之前的DIN也是偏工程实践的论文), 行文风格上以实际应用为主, 我们知道YouTube是全球性的视频网站, 所以这篇文章主要讲述了YouTube视频推荐系统的基本架构以及细节,以及各种处理tricks。
在Introduction部分, 作者首先说了在工业上的YouTube视频推荐系统主要面临的三大挑战:
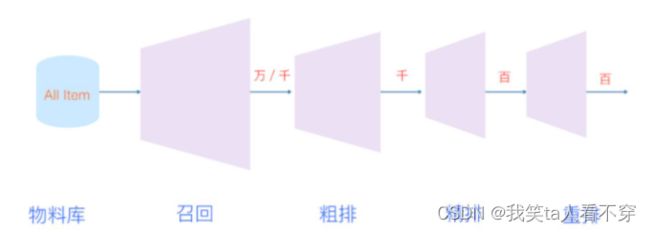
- Scale(规模): 视频数量非常庞大,大规模数据下需要分布式学习算法以及高效的线上服务系统,文中体现这一点的是召回模型线下训练的时候,采用了负采样的思路,线上服务的时候,采用了hash映射,然后近邻检索的方式来满足实时性的需求, 这个之前我整理过faiss包和annoy包的使用, 感兴趣的可以看看。 其实,再拔高一层,我们推荐系统的整体架构呈漏斗范式,也是为了保证能从大规模情景下实时推荐。
- Freshness(新鲜度): YouTube上的视频是一个动态的, 用户实时上传,且实时访问, 那么这时候, 最新的视频往往就容易博得用户的眼球, 用户一般都比较喜欢看比较新的视频, 而不管是不是真和用户相关(这个感觉和新闻比较类似呀), 这时候,就需要模型有建模新上传内容以及用户最新发生的行为能力。 为了让模型学习到用户对新视频有偏好, 后面策略里面加了一个"example age"作为体现。我们说的"探索与利用"中的探索,其实也是对新鲜度的把握。
- Noise(噪声): 由于数据的稀疏和不可见的其他原因, 数据里面的噪声非常之多,这时候,就需要让这个推荐系统变得鲁棒,怎么鲁棒呢? 这个涉及到召回和排序两块,召回上需要考虑更多实际因素,比如非对称消费特性,高活用户因素,时间因素,序列因素等,并采取了相应的措施, 而排序上做更加细致的特征工程, 尽量的刻画出用户兴趣以及视频的特征 优化训练目标,使用加权的逻辑回归等。而召回和排序模型上,都采用了深度神经网络,通过特征的相互交叉,有了更强大的建模能力, 相比于之前用的MF(矩阵分解), 建模能力上有了很大的提升, 这些都有助于帮助减少噪声, 使得推荐结果更加准确。
所以从文章整体逻辑上看, 后面的各个细节,其实都是围绕着挑战展开的,找到当前推荐面临的问题,就得想办法解决问题,所以这篇文章的行文逻辑也是非常清晰的。
知道了挑战, 那么下面就看看YouTubeDNN的整体推荐系统架构。
整个推荐架构图如下, 这个算是比较原始的漏斗结构了:

这篇文章之所以写的好, 是给了我们一个看推荐系统的宏观视角, 这个系统主要是两大部分组成: 召回和排序。召回的目的是根据用户部分特征,从海量物品库,快速找到小部分用户潜在感兴趣的物品交给精排,重点强调快,精排主要是融入更多特征,使用复杂模型,来做个性化推荐,强调准。
而对于这两块的具体描述, 论文里面也给出了解释, 我这里简单基于我目前的理解扩展下主流方法:
召回侧
召回侧模型的输入一般是用户的点击历史, 因为我们认为这些历史能更好的代表用户的兴趣, 另外还有一些人口统计学特征,比如性别,年龄,地域等, 都可以作为召回侧模型的输入。 而最终模型的输出,就是与该用户相关的一个候选视频集合, 量级的话一般是几百。
召回侧, 目前根据我的理解,大致上有两大类召回方式,一类是策略规则,一类是监督模型+embedding,其中策略规则,往往和真实场景有关,比如热度,历史重定向等等,不同的场景会有不同的召回方式,这种属于"特异性"知识。
后面的模型+embedding思路是一种"普适"方法,我上面图里面梳理出了目前给用户和物品打embedding的主流方法, 这些方法大致成几个系列,比如FM系列(FM,FFM等), 用户行为序列,基于图和知识图谱系列,经典双塔系列等,这些方法看似很多很复杂,其实本质上还是给用户或者是物品打embedding而已,只不过考虑的角度方式不同。 这里的YouTubeDNN召回模型,也是这里的一种方式而已。
精排侧
召回那边对于每个用户, 给出了几百个比较相关的候选视频, 把几百万的规模降到了几百, 当然,召回那边利用的特征信息有限,并不能很好的刻画用户和视频特点,所以, 在精排侧,主要是想利用更多的用户,视频特征,刻画特点更加准确些,从这几百个里面选出几个或者十几个推荐给用户。 而涉及到准, 主要的发力点一般有三个:特征工程, 模型设计以及训练方法。 这三个发力点文章几乎都有所涉及, 除了模式设计有点审时度势之外,特征工程以及训练方法的处理上非常漂亮,具体的后面再整理。
精排侧,这一块的大致发展趋势,从ctr预估到多目标, 而模型演化上,从人工特征工程到特征工程自动化。主要是三大块, CTR预估主要分为了传统的LR,FM大家族,以及后面自动特征交叉的DNN家族,而多目标优化,目前是很多大公司的研究现状,更是未来的一大发展趋势,如何能让模型在各个目标上面的学习都能"游刃有余"是一件非常具有挑战的事情,毕竟不同的目标可能会互相冲突,互相影响,所以这里的研究热点又可以拆分成网络结构演化以及loss设计优化等, 而网络结构演化中,又可以再一次细分。 当然这每个模型或者技术几乎都有对应paper,我们依然可以通过读paper的方式,把这些关键技术学习到。
这两阶段的方法, 就能保证我们从大规模视频库中实时推荐, 又能保证个性化,吸引用户。 当然,随着时间的发展, 可能数据量非常非常大了, 此时召回结果规模精排依然无法处理,所以现在一般还会在召回和精排之间,加一个粗排进一步筛选作为过渡, 而随着场景越来越复杂, 精排产生的结果也不是直接给到用户,而是会再后面加一个重排后处理下,这篇paper里面其实也简单的提了下这种思想,在排序那块会整理到。 所以如今的漏斗, 也变得长了些。
论文里面还提到了对模型的评估方面, 线下评估的时候,主要是采用一些常用的评估指标(精确率,召回率, 排序损失或者auc这种), 但是最终看算法和模型的有效性, 是通过A/B实验, 在A/B实验中会观察用户真实行为,比如点击率, 观看时长, 留存率这种, 这些才是我们终极目标, 而有时候, A/B实验的结果和线下我们用的这些指标并不总是相关, 这也是推荐系统这个场景的复杂性。 我们往往也会用一些策略,比如修改模型的优化目标,损失函数这种, 让线下的这个目标尽量的和A/B衡量的这种指标相关性大一些。 当然,这块又是属于业务场景问题了,不在整理范畴之中。 但2016年,竟然就提出了这种方式, 所以我觉得,作为小白的我们, 想了解工业上的推荐系统, 这篇paper是不二之选。
OK, 从宏观的大视角看完了漏斗型的推荐架构,我们就详细看看YouTube视频推荐架构里面召回和排序模块的模型到底长啥样子? 为啥要设计成这个样子? 为了应对实际中出现的挑战,又有哪些策略?
YouTubeDNN的召回模型细节剖析
...先挖个坑 内容太多了下次补上
在MovieLens-1M数据集上数据集训练一个YouTubeDNN模型
YoutubeDNN论文链接
YouTubeDNN模型虽然叫单塔模型,但也是以双塔模型的思想去构建的,所以不管是模型还是其他都很相似。 下面给出了YouTubeDNN的代码,与DSSM不同的代码会用序号+中文的方式标注,例如# [0]训练方式改为List wise,大家可以感受一下二者的区别。
import os
import numpy as np
import pandas as pd
import torch
from sklearn.preprocessing import LabelEncoder
from torch_rechub.models.matching import YoutubeDNN
from torch_rechub.trainers import MatchTrainer
from torch_rechub.basic.features import SparseFeature, SequenceFeature
from torch_rechub.utils.match import generate_seq_feature_match, gen_model_input
from torch_rechub.utils.data import df_to_dict, MatchDataGenerator
torch.manual_seed(2022)
data = pd.read_csv(file_path)
data["cate_id"] = data["genres"].apply(lambda x: x.split("|")[0])
sparse_features = ['user_id', 'movie_id', 'gender', 'age', 'occupation', 'zip', "cate_id"]
user_col, item_col = "user_id", "movie_id"
feature_max_idx = {}
for feature in sparse_features:
lbe = LabelEncoder()
data[feature] = lbe.fit_transform(data[feature]) + 1
feature_max_idx[feature] = data[feature].max() + 1
if feature == user_col:
user_map = {encode_id + 1: raw_id for encode_id, raw_id in enumerate(lbe.classes_)} #encode user id: raw user id
if feature == item_col:
item_map = {encode_id + 1: raw_id for encode_id, raw_id in enumerate(lbe.classes_)} #encode item id: raw item id
np.save(save_dir+"raw_id_maps.npy", (user_map, item_map))
user_cols = ["user_id", "gender", "age", "occupation", "zip"]
item_cols = ["movie_id", "cate_id"]
user_profile = data[user_cols].drop_duplicates('user_id')
item_profile = data[item_cols].drop_duplicates('movie_id')
#Note: mode=2 means list-wise negative sample generate, saved in last col "neg_items"
df_train, df_test = generate_seq_feature_match(data,
user_col,
item_col,
time_col="timestamp",
item_attribute_cols=[],
sample_method=1,
mode=2, # [0]训练方式改为List wise
neg_ratio=3,
min_item=0)
x_train = gen_model_input(df_train, user_profile, user_col, item_profile, item_col, seq_max_len=50)
y_train = np.array([0] * df_train.shape[0]) # [1]训练集所有样本的label都取0。因为一个样本的组成是(pos, neg1, neg2, ...),视为一个多分类任务,正样本的位置永远是0
x_test = gen_model_input(df_test, user_profile, user_col, item_profile, item_col, seq_max_len=50)
user_cols = ['user_id', 'gender', 'age', 'occupation', 'zip']
user_features = [SparseFeature(name, vocab_size=feature_max_idx[name], embed_dim=16) for name in user_cols]
user_features += [
SequenceFeature("hist_movie_id",
vocab_size=feature_max_idx["movie_id"],
embed_dim=16,
pooling="mean",
shared_with="movie_id")
]
item_features = [SparseFeature('movie_id', vocab_size=feature_max_idx['movie_id'], embed_dim=16)] # [2]物品的特征只有itemID,即movie_id一个
neg_item_feature = [
SequenceFeature('neg_items',
vocab_size=feature_max_idx['movie_id'],
embed_dim=16,
pooling="concat",
shared_with="movie_id")
] # [3] 多了一个neg item feature,会传入到模型中,在item tower中会用到
all_item = df_to_dict(item_profile)
test_user = x_test
dg = MatchDataGenerator(x=x_train, y=y_train)
train_dl, test_dl, item_dl = dg.generate_dataloader(test_user, all_item, batch_size=256)
model = YoutubeDNN(user_features, item_features, neg_item_feature, user_params={"dims": [128, 64, 16]}, temperature=0.02) # [4] MLP的最后一层需保持与item embedding一致
#mode=1 means pair-wise learning
trainer = MatchTrainer(model,
mode=2,
optimizer_params={
"lr": 1e-4,
"weight_decay": 1e-6
},
n_epoch=1, #5
device='cpu',
model_path=save_dir)
trainer.fit(train_dl)
print("inference embedding")
user_embedding = trainer.inference_embedding(model=model, mode="user", data_loader=test_dl, model_path=save_dir)
item_embedding = trainer.inference_embedding(model=model, mode="item", data_loader=item_dl, model_path=save_dir)
match_evaluation(user_embedding, item_embedding, test_user, all_item, topk=10, raw_id_maps="saved/raw_id_maps.npy")
Task 2
DIN 模型的动机:传统的神经网络模型根本没有考虑之前用户历史行为商品具体是什么,究竟用户历史行为中的哪个会对当前的点击预测带来积极的作用。 而实际上,对于用户点不点击当前的商品广告,很大程度上是依赖于他的历史行为的,王喆老师举了个例子
![]()
为更加 表达出用户这广泛多样的兴趣, 我们应该考虑到用户的历史行为商品与当前商品广告的一个关联性,如果用户历史商品中很多与当前商品关联,那么说明该商品可能符合用户的品味,就把该广告推荐给他。而一谈到关联性的话, 我们就容易想到“注意力”的思想了, 所以为了更好的从用户的历史行为中学习到与当前商品广告的关联性,学习到用户的兴趣变化, 作者把注意力引入到了模型,设计了一个"local activation unit"结构。
特征
工业上的CTR预测数据集一般都是multi-group categorial form的形式,就是类别型特征最为常见,这种数据集一般长这样:

Base模型
这里的base 模型,就是上面提到过的Embedding&MLP的形式, 这个之所以要介绍,就是因为DIN网络的基准也是他,只不过在这个的基础上添加了一个新结构(注意力网络)来学习当前候选广告与用户历史行为特征的相关性,从而动态捕捉用户的兴趣。
基准模型的结构相对比较简单,我们前面也一直用这个基准, 分为三大模块:Embedding layer,Pooling & Concat layer和MLP, 结构如下:

Embedding layer:这个层的作用是把高维稀疏的输入转成低维稠密向量, 每个离散特征下面都会对应着一个embedding词典, 维度是D\times KD×K, 这里的DD表示的是隐向量的维度, 而KK表示的是当前离散特征的唯一取值个数, 这里为了好理解,这里举个例子说明,就比如上面的weekday特征:
假设某个用户的weekday特征就是周五,化成one-hot编码的时候,就是[0,0,0,0,1,0,0]表示,这里如果再假设隐向量维度是D, 那么这个特征对应的embedding词典是一个D\times7D×7的一个矩阵(每一列代表一个embedding,7列正好7个embedding向量,对应周一到周日),那么该用户这个one-hot向量经过embedding层之后会得到一个D\times1D×1的向量,也就是周五对应的那个embedding,怎么算的,其实就是embedding矩阵* [0,0,0,0,1,0,0]^Tembedding矩阵∗[0,0,0,0,1,0,0]T 。其实也就是直接把embedding矩阵中one-hot向量为1的那个位置的embedding向量拿出来。 这样就得到了稀疏特征的稠密向量了。其他离散特征也是同理,只不过上面那个multi-hot编码的那个,会得到一个embedding向量的列表,因为他开始的那个multi-hot向量不止有一个是1,这样乘以embedding矩阵,就会得到一个列表了。通过这个层,上面的输入特征都可以拿到相应的稠密embedding向量了。
pooling layer and Concat layer: pooling层的作用是将用户的历史行为embedding这个最终变成一个定长的向量,因为每个用户历史购买的商品数是不一样的, 也就是每个用户multi-hot中1的个数不一致,这样经过embedding层,得到的用户历史行为embedding的个数不一样多,也就是上面的embedding列表t_iti不一样长, 那么这样的话,每个用户的历史行为特征拼起来就不一样长了。 而后面如果加全连接网络的话,我们知道,他需要定长的特征输入。 所以往往用一个pooling layer先把用户历史行为embedding变成固定长度(统一长度),所以有了这个公式:
e_i=pooling(e_{i1}, e_{i2}, ...e_{ik})ei=pooling(ei1,ei2,...eik)
这里的e_{ij}eij是用户历史行为的那些embedding。e_iei就变成了定长的向量, 这里的ii表示第ii个历史特征组(是历史行为,比如历史的商品id,历史的商品类别id等), 这里的kk表示对应历史特种组里面用户购买过的商品数量,也就是历史embedding的数量,看上面图里面的user behaviors系列,就是那个过程了。 Concat layer层的作用就是拼接了,就是把这所有的特征embedding向量,如果再有连续特征的话也算上,从特征维度拼接整合,作为MLP的输入。
MLP:这个就是普通的全连接,用了学习特征之间的各种交互。
Loss: 由于这里是点击率预测任务, 二分类的问题,所以这里的损失函数用的负的log对数似然:
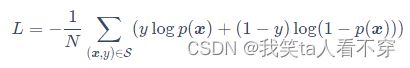
这就是base 模型的全貌, 这里应该能看出这种模型的问题, 通过上面的图也能看出来, 用户的历史行为特征和当前的候选广告特征在全都拼起来给神经网络之前,是一点交互的过程都没有, 而拼起来之后给神经网络,虽然是有了交互了,但是原来的一些信息,比如,每个历史商品的信息会丢失了一部分,因为这个与当前候选广告商品交互的是池化后的历史特征embedding, 这个embedding是综合了所有的历史商品信息, 这个通过我们前面的分析,对于预测当前广告点击率,并不是所有历史商品都有用,综合所有的商品信息反而会增加一些噪声性的信息,可以联想上面举得那个键盘鼠标的例子,如果加上了各种洗面奶,衣服啥的反而会起到反作用。其次就是这样综合起来,已经没法再看出到底用户历史行为中的哪个商品与当前商品比较相关,也就是丢失了历史行为中各个商品对当前预测的重要性程度。最后一点就是如果所有用户浏览过的历史行为商品,最后都通过embedding和pooling转换成了固定长度的embedding,这样会限制模型学习用户的多样化兴趣。
那么改进这个问题的思路有哪些呢? 第一个就是加大embedding的维度,增加之前各个商品的表达能力,这样即使综合起来,embedding的表达能力也会加强, 能够蕴涵用户的兴趣信息,但是这个在大规模的真实推荐场景计算量超级大,不可取。 另外一个思路就是在当前候选广告和用户的历史行为之间引入注意力的机制,这样在预测当前广告是否点击的时候,让模型更关注于与当前广告相关的那些用户历史产品,也就是说与当前商品更加相关的历史行为更能促进用户的点击行为。 作者这里又举了之前的一个例子:
想象一下,当一个年轻母亲访问电子商务网站时,她发现展示的新手袋很可爱,就点击它。让我们来分析一下点击行为的驱动力。
展示的广告通过软搜索这位年轻母亲的历史行为,发现她最近曾浏览过类似的商品,如大手提袋和皮包,从而击中了她的相关兴趣
第二个思路就是DIN的改进之处了。DIN通过给定一个候选广告,然后去注意与该广告相关的局部兴趣的表示来模拟此过程。 DIN不会通过使用同一向量来表达所有用户的不同兴趣,而是通过考虑历史行为的相关性来自适应地计算用户兴趣的表示向量(对于给的广告)。 该表示向量随不同广告而变化。下面看一下DIN模型。
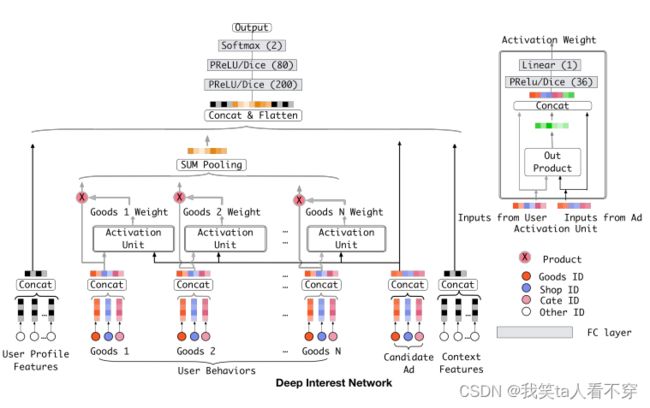
Torch-Rechub Tutorial: DeepFM
- 场景:精排(CTR预测)
- 模型:DeepFM
-
数据:Criteo广告数据集
该数据集是Criteo Labs发布的在线广告数据集。 它包含数百万个展示广告的点击反馈记录,该数据可作为点击率(CTR)预测的基准。 数据集具有40个特征,第一列是标签,其中值1表示已点击广告,而值0表示未点击广告。 其他特征包含13个dense特征和26个sparse特征。
import numpy as np
import pandas as pd
import torch
from torch_rechub.models.ranking import WideDeep, DeepFM, DCN
from torch_rechub.trainers import CTRTrainer
from torch_rechub.basic.features import DenseFeature, SparseFeature
from torch_rechub.utils.data import DataGenerator
from tqdm import tqdm
from sklearn.preprocessing import MinMaxScaler, LabelEncoder
torch.manual_seed(2022) #固定随机种子
data_path = 'criteo_sample.csv'
data = pd.read_csv(data_path)
#data = pd.read_csv(data_path, compression="gzip") #if the raw_data is .gz file
data.head()特征工程
- Dense特征:又称数值型特征,例如薪资、年龄。 本教程中对Dense特征进行两种操作:
- MinMaxScaler归一化,使其取值在[0,1]之间
- 将其离散化成新的Sparse特征
- Sparse特征:又称类别型特征,例如性别、学历。本教程中对Sparse特征直接进行LabelEncoder编码操作,将原始的类别字符串映射为数值,在模型中将为每一种取值生成Embedding向量。
dense_cols= [f for f in data.columns.tolist() if f[0] == "I"] #以I开头的特征名为dense特征
sparse_cols = [f for f in data.columns.tolist() if f[0] == "C"] #以C开头的特征名为sparse特征
data[dense_cols] = data[dense_cols].fillna(0) #填充空缺值
data[sparse_cols] = data[sparse_cols].fillna('-996')
#criteo比赛冠军分享的一种离散化思路,不用纠结其原理,大家也可以试试别的离散化手段
def convert_numeric_feature(val):
v = int(val)
if v > 2:
return int(np.log(v)**2)
else:
return v - 2
for col in tqdm(dense_cols): #将离散化dense特征列设置为新的sparse特征列
sparse_cols.append(col + "_sparse")
data[col + "_sparse"] = data[col].apply(lambda x: convert_numeric_feature(x))
scaler = MinMaxScaler() #对dense特征列归一化
data[dense_cols] = scaler.fit_transform(data[dense_cols])
for col in tqdm(sparse_cols): #sparse特征编码
lbe = LabelEncoder()
data[col] = lbe.fit_transform(data[col])
#重点:将每个特征定义为torch-rechub所支持的特征基类,dense特征只需指定特征名,sparse特征需指定特征名、特征取值个数(vocab_size)、embedding维度(embed_dim)
dense_features = [DenseFeature(feature_name) for feature_name in dense_cols]
sparse_features = [SparseFeature(feature_name, vocab_size=data[feature_name].nunique(), embed_dim=16) for feature_name in sparse_cols]
y = data["label"]
del data["label"]
x = data
训练模型
训练一个DeepFM模型,只需要指定DeepFM的模型结构参数,学习率等训练参数。 对于DeepFM而言,主要参数如下:
- deep_features指用deep模块训练的特征(兼容dense和sparse),
- fm_features指用fm模块训练的特征,只能传入sparse类型
- mlp_params指定deep模块中,MLP层的参数
# 构建模型输入所需要的dataloader,区分验证集、测试集,指定batch大小
#split_ratio=[0.7,0.1] 指的是训练集占比70%,验证集占比10%,剩下的全部为测试集
dg = DataGenerator(x, y)
train_dataloader, val_dataloader, test_dataloader = dg.generate_dataloader(split_ratio=[0.7, 0.1], batch_size=256, num_workers=8)
from torch_rechub.models.ranking import DeepFM
from torch_rechub.trainers import CTRTrainer
#定义模型
model = DeepFM(
deep_features=dense_features+sparse_features,
fm_features=sparse_features,
mlp_params={"dims": [256, 128], "dropout": 0.2, "activation": "relu"},
)
# 模型训练,需要学习率、设备等一般的参数,此外我们还支持earlystoping策略,及时发现过拟合
ctr_trainer = CTRTrainer(
model,
optimizer_params={"lr": 1e-4, "weight_decay": 1e-5},
n_epoch=1,
earlystop_patience=3,
device='cpu', #如果有gpu,可设置成cuda:0
model_path='./', #模型存储路径
)
ctr_trainer.fit(train_dataloader, val_dataloader)
# 查看在测试集上的性能
auc = ctr_trainer.evaluate(ctr_trainer.model, test_dataloader)
print(f'test auc: {auc}')
使用其他的排序模型训练Criteo
#定义相应的模型,用同样的方式训练
model = WideDeep(wide_features=dense_features, deep_features=sparse_features, mlp_params={"dims": [256, 128], "dropout": 0.2, "activation": "relu"})
model = DCN(features=dense_features + sparse_features, n_cross_layers=3, mlp_params={"dims": [256, 128]})从调包到自定义自己的模型
恭喜朋友成功运行了DeepFM模型,并得到了CTR推荐的结果。 接下来我们考虑如何实现自己的DeepFM模型。 由于FM,MLP,LR,Embedding等基础模块被许多推荐模型共用,因此torch_rechub也帮我们集成好了这些小模块。我们在basic.layers中import即可。
from torch_rechub.basic.layers import FM, MLP, LR, EmbeddingLayer
class MyDeepFM(torch.nn.Module):
# Deep和FM为两部分,分别处理不同的特征,因此传入的参数要有两种特征,由此我们得到参数deep_features,fm_features
# 此外神经网络类的模型中,基本组成原件为MLP多层感知机,多层感知机的参数也需要传进来,即为mlp_params
def __init__(self, deep_features, fm_features, mlp_params):
super().__init__()
self.deep_features = deep_features
self.fm_features = fm_features
self.deep_dims = sum([fea.embed_dim for fea in deep_features])
self.fm_dims = sum([fea.embed_dim for fea in fm_features])
# LR建模一阶特征交互
self.linear = LR(self.fm_dims)
# FM建模二阶特征交互
self.fm = FM(reduce_sum=True)
# 对特征做嵌入表征
self.embedding = EmbeddingLayer(deep_features + fm_features)
self.mlp = MLP(self.deep_dims, **mlp_params)
def forward(self, x):
input_deep = self.embedding(x, self.deep_features, squeeze_dim=True) #[batch_size, deep_dims]
input_fm = self.embedding(x, self.fm_features, squeeze_dim=False) #[batch_size, num_fields, embed_dim]
y_linear = self.linear(input_fm.flatten(start_dim=1))
y_fm = self.fm(input_fm)
y_deep = self.mlp(input_deep) #[batch_size, 1]
# 最终的预测值为一阶特征交互,二阶特征交互,以及深层模型的组合
y = y_linear + y_fm + y_deep
# 利用sigmoid来将预测得分规整到0,1区间内
return torch.sigmoid(y.squeeze(1))同样的,可以使用torch-rechub提供的trainer进行模型训练和模型评估
model = MyDeepFM(
deep_features=dense_features+sparse_features,
fm_features=sparse_features,
mlp_params={"dims": [256, 128], "dropout": 0.2, "activation": "relu"},
)
# 模型训练,需要学习率、设备等一般的参数,此外我们还支持earlystoping策略,及时发现过拟合
ctr_trainer = CTRTrainer(
model,
optimizer_params={"lr": 1e-4, "weight_decay": 1e-5},
n_epoch=1,
earlystop_patience=3,
device='cpu',
model_path='./',
)
ctr_trainer.fit(train_dataloader, val_dataloader)
# 查看在测试集上的性能
auc = ctr_trainer.evaluate(ctr_trainer.model, test_dataloader)
print(f'test auc: {auc}')
Torch-Rechub Tutorial: DIN
Task 1
首先我们使用的数据集为:amazon_electronics_sample.csv
主要包含4个特征:user_id(用户id), item_id(点击商品id),cate_id(点击商品类别id),time(时间序列)
读取数据以及特征工程,Sparse 类别 Dense 数值型
Sequence特征:序列特征,比如用户历史点击item_id序列、历史商铺序列等,序列特征如何抽取,是我们在DIN中学习的一个重点,也是DIN主要创新点之一。
import torch
import torch_rechub
import pandas as pd
import tqdm
import sklearn
torch.manual_seed(2022)
file_path = 'amazon_electronics_sample.csv'#'amazon_electronic_datasets.csv'
data = pd.read_csv(file_path)
data.head()
# 构建用户的历史行为序列特征,内置函数create_seq_features只需要指定数据,
# 和需要生成序列的特征,drop_short是选择舍弃行为序列较短的用户
from torch_rechub.utils.data import create_seq_features
train, val, test = create_seq_features(data, seq_feature_col=['item_id', 'cate_id'], drop_short=0)
from torch_rechub.basic.features import DenseFeature, SequenceFeature, SparseFeature
n_users, n_items, n_cates = data['user_id'].max(), data['item_id'].max(), data['cate_id'].max()
features = [SparseFeature("target_item", vocab_size=n_items + 2, embed_dim=8),
SparseFeature('target_cate', vocab_size=n_cates + 2, embed_dim=8),
SparseFeature('user_id', vocab_size=n_users + 2, embed_dim=8)]
target_features = features
# 对于序列特征,除了需要和类别特征一样处理意外,item序列和候选item应该属于同一个空间,我们希望模
# 型共享它们的embedding,所以可以通过shared_with参数指定
history_features = [
SequenceFeature('history_item', vocab_size=n_items+2, embed_dim=8, pooling='concat', shared_with='target_item'),
SequenceFeature('history_cate', vocab_size=n_items+2, embed_dim=8, pooling='concat', shared_with='target_cate'),
]out:

[,
,
] 这里的vocab_size=n_items+2 经过网上查询,是需要为OOV(词表外的)标记和padding(填充)添加+2。
这里的embed_dim=8是一个经验参数。
from torch_rechub.utils.data import df_to_dict, DataGenerator
# 指定 label 生成模型输入
train = df_to_dict(train)
val = df_to_dict(val)
test = df_to_dict(test)
train_y, val_y, test_y = train['label'], val['label'], test['label']
del train["label"]
del val["label"]
del test["label"]
train_x, val_x, test_x = train, val, test
# 最后查看一次输入模型的数据格式
train_xout:
{'user_id': array([1, 1]),
'history_item': array([[2, 3, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0],
[2, 3, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0]]),
'history_cate': array([[2, 4, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0],# 构建dataloader 指定模型读取数据的方式, 和区分验证集测试集,指定batch_size
dg = DataGenerator(train_x, train_y)
train_dataloader, val_dataloader, test_dataloader = dg.generate_dataloader(x_val=val_x, y_val=val_y, x_test=test_x, y_test=test_y, batch_size=16)
from torch_rechub.models.ranking import DIN
from torch_rechub.trainers import CTRTrainer
# 定义模型,模型的参数需要我们之前的feature类,用于构建模型的输入层,mlp指定模型后续DNN的结构,attention_mlp指定attention层的结构
model = DIN(features=features, history_features=history_features, target_features=target_features, mlp_params={"dims": [256, 128]}, attention_mlp_params={"dims": [256, 128]})
# 模型训练,需要学习率、设备等一般的参数,此外我们还支持earlystoping策略,及时发现过拟合
ctr_trainer = CTRTrainer(model, optimizer_params={"lr": 1e-3, "weight_decay": 1e-3}, n_epoch=3, earlystop_patience=4, device='cpu', model_path='./')
ctr_trainer.fit(train_dataloader, val_dataloader)
# 查看在测试集上的性能
auc = ctr_trainer.evaluate(ctr_trainer.model, test_dataloader)
print(f'test auc: {auc}')out:

该内容学习参考自:
torch-rechub/DIN.ipynb at main · datawhalechina/torch-rechub · GitHub https://github.com/datawhalechina/torch-rechub/blob/main/tutorials/DIN.ipynb
https://github.com/datawhalechina/torch-rechub/blob/main/tutorials/DIN.ipynb